引言
最近帝国理工(Imperial College London)新出了实时单目稠密SLAM,从demo中可以看到有如下几个特性: 首先是可实时运行,虽然部分mapping的几何一致性有待加强,但是毕竟能实时单目稠密三维重建,可以说是是相当impressed了。 其次是鲁棒性比较强,虽然重定位、回环这些都是老生常谈的功能了,但是作者通过遮挡镜头以及zoom in/out的方式来测试,都能够很好的handle这些特殊情况。 而本作从某种程度上,更是开启了SLAM的新范式,不再进行2D的匹配而是直接通过3D匹配,也就是所谓的“two-view 3D reconstruction and matching prior”来实现SLAM。 最后作者应该是打算开源代码的,后续开源了进行测试一下,而本博文先对论文其及相关的基础工作DUSt3R和MASt3R进行阅读。
DUSt3R: Geometric 3D Vision Made Easy
CVPR2024DUSt3R project website (有互动插件)
DUSt3R理论解读
DUSt3R其实就是实现从2D图像到3D点云的转换,但是它不需要任何相机校准或视点姿势的先验信息,就可完成任意图像的密集或无约束3D重建。
传统的三维重建基本都是基于MVS(Multi-view stereo reconstruction)的原理,它的第一步就是估算相机的内参与外参(pose)。此外,这个过程包含了特征点的tracking与matching、sfm,BA优化等一系列步骤,每一步都可能存在误差并将noise传递到下一步,最终导致重建的不准确。同时也使得SLAM系统额外的庞大。
而DUSt3R(Dense and Unconstrained Stereo 3D Reconstruction)则是提供新的范式,它不需要相机的内参与外参,只需要输入双目图像,就可以输出对应的3D点云。
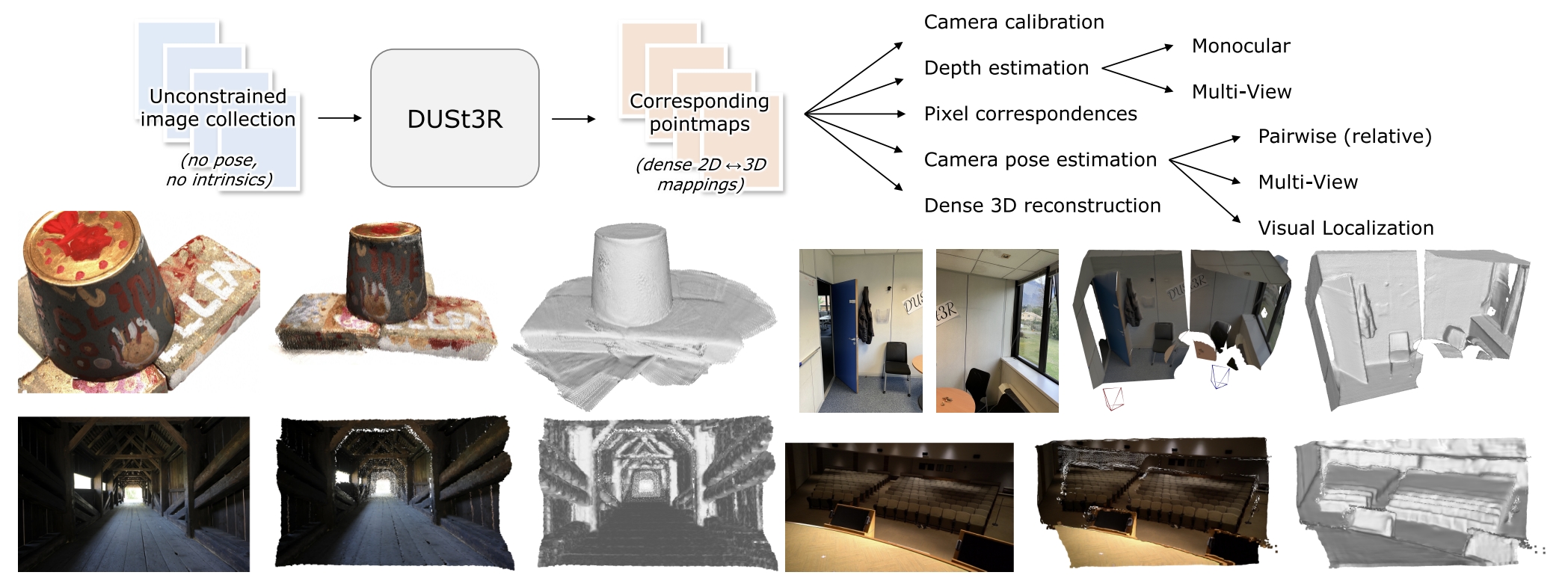
作者将成对的重建pairwise reconstruction)问题转换为点图(pointmaps)的回归,进而不再需要相机的投影模型。而当场景中有多于两张照片时,DUSt3R通过相应的global alignment strategy来将所有的点图对齐,进而生成最终的3D model 以及深度信息。
所谓的“global alignment strategy”其实是参考BA的思想,通过在3D空间直接优化相机的pose以及场景的几何结构。
图下方从左到右分别为图像-彩色点云-渲染的3D模型(rendered with shading)


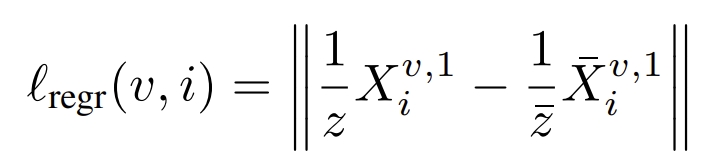

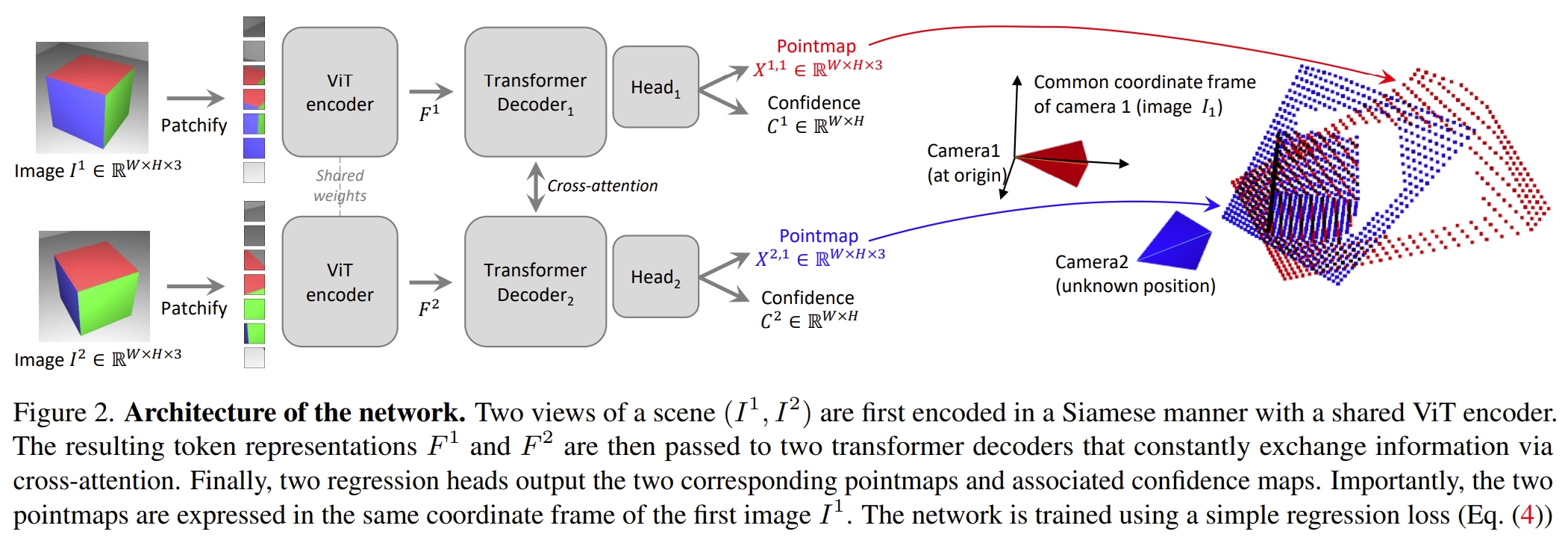
个人更直观一些的理解就是:DUSt3R是一种learning-based的3D reconstruction,但是跟NeRF、3DGS这些不一样,它不需要相机的内参以及pose只需要图像输入即可。
PS:当然NeRF或3DGS也有不需要pose先验的工作,也就是Full-SLAM的工作,但是还是额外设计成SLAM的架构,如PTAM等估算位姿,但是DUSt3R完全就没有估算位姿这一个过程,因此更加直观的说就是一个网络(同时封装了场景的几何结构、2D与3D点之间的关系,2个viewpoint之间的关系),仅输入图像就实现三维重建(associate the 2D pixel with 3D shapes)。
通过实用一个简单的regression loss,采用带label(合成的、sfm生成的、其他传感器提供的)的8个大型公开数据集来训练模型(目前作者开源的github中包含的数据如下图)。

实验显示,DUSt3R在单目/多视图深度估计以及相对位姿估计三个任务上,均取得SOTA。
DUSt3R实验测试
按照github的安装步骤
DUSt3R Github也可参考My Comment on DUSt3R



Grounding Image Matching in 3D with MASt3R
ECCV2025MASt3R project website
MASt3R理论解读
MASt3R (Matching And Stereo 3D Reconstruction)跟DUSt3R都是来自于NAVER LABS Euro团队的作品。在有了前作DUSt3R之后,作者开始探索从3D的角度来实现图像匹配(dense correspondences),
“aim at producing a list of pairwise correspondences (matches), given two images”(其实在DUSt3R的附加功能中,也已经有这个function的了,属于by-product)
也可拓展成camera calibration, camera pose estimation, 3D reconstruction 等任务。
图像匹配(Image Matching)是3D视觉中所有性能最佳的算法和pipeline的核心组件。然而,虽然匹配从根本上来说是一个3D问题(与相机姿态和场景几何结构有内在联系),但是通常匹配都被视为一个2D问题。
本文使用 DUSt3R(一种基于 Transformers 的最新且强大的 3D 重建框架)将匹配作为 3D 任务。
DUSt3R方法基于点图回归(pointmaps regression),在具有极端视点变换的情况下,仍然可以实现良好的匹配效果,但精度有限。而本文的目标则是是提高匹配的能力,同时保持其鲁棒性。
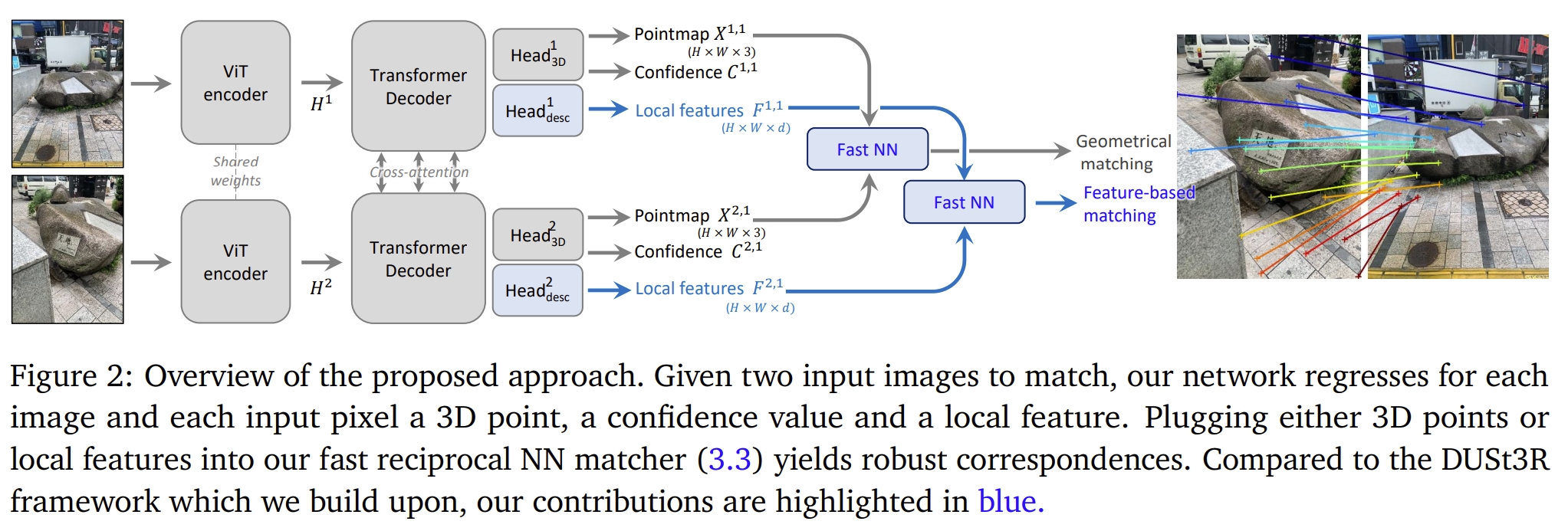
作者采用“new head”(应该是在DUSt3R前额外加一个network)来输出稠密的local features,并且添加matching loss来进行训练,进而提升DUSt3R的性能。
并且,作者引入了一种快速相互匹配方案(a fast reciprocal matching scheme),该方案不仅可以将匹配速度提高几个数量级,而且还具有理论保证以及提升效果。



传统的图像匹配方法主要分为三步:
但是,基于关键点的方法通过减少对关键点包问题的匹配,丢弃了对应任务的全局几何上下文。 这使得它们在重复模式或低纹理区域的情况下特别容易出错,这实际上对于局部描述符来说是不适定的。 解决这个问题的一种方法是在配对步骤中引入全局优化策略,通常利用一些学习到的匹配先验知识(例如SuperGlue等learning-based 方法)。 但是还是得依赖于关键点的检测,如果关键点及其描述符没有编码足够的信息,那么仅仅在匹配期间利用全局上下文可能为时已晚。
因此,另一个方向是考虑密集整体匹配(dense holistic matching),也就是完全避免关键点,并一次匹配整个图像。例如基于cross-attention的LoFTR等等,这些方法将图像视为一个整体,生成的稠密的匹配(dense correspondences),并且对于重复模式和低纹理区域也是鲁棒的。
但是这些方法也都是基于2D的匹配。即使像LoFTR这么好的方法,在Map-free localization benchmark上的精度也不高。作者认为这是因为这些方法都将匹配问题视为图像平面上的2D问题。但是实际上,匹配任务的制定本质上是一个 3D 问题:所谓的匹配,要对应的像素是观察的相同的3D点的像素。
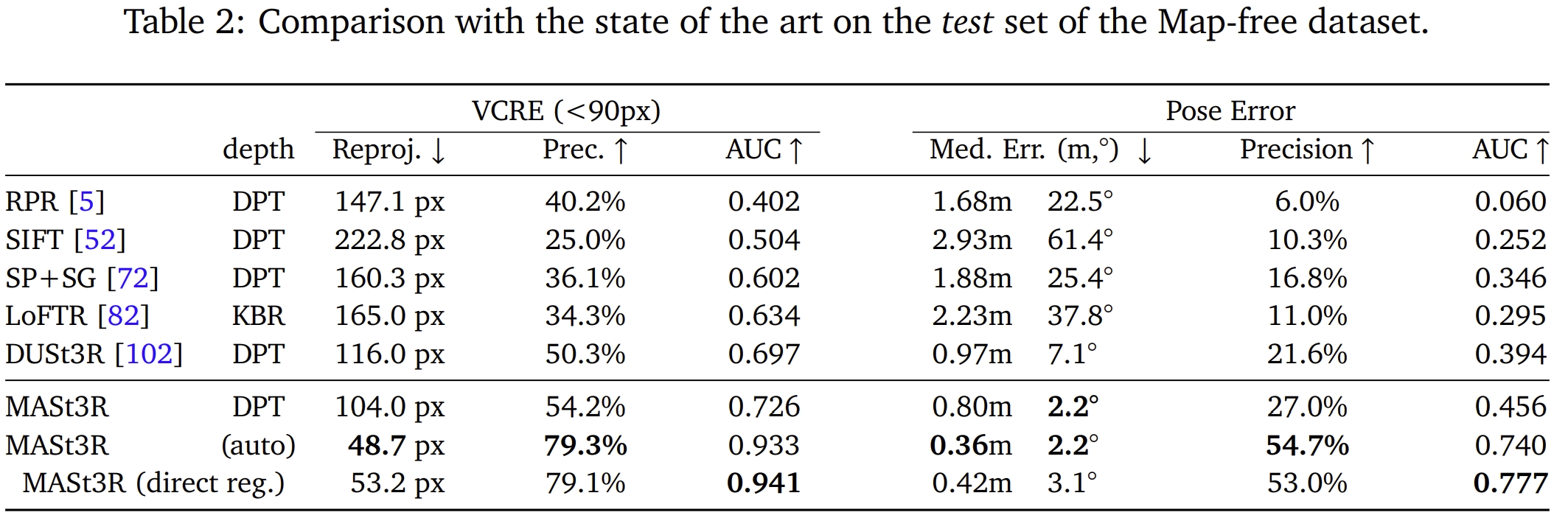
采用的评价指标为“Virtual Correspondence Reprojection Error (VCRE) and camera pose accuracy”
MASt3R实验测试
按照github的安装步骤
MASt3R Github也可参考My Comment on MASt3R
测试匹配效果(跟作者给出的效果差不多,注意要避免有其他进程还在运行会影响匹配的效果 kill -9 PID)


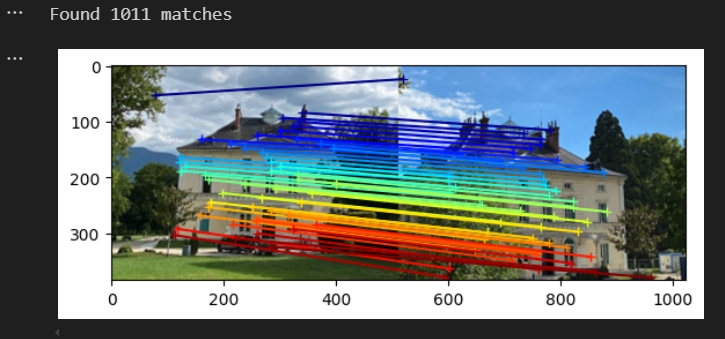
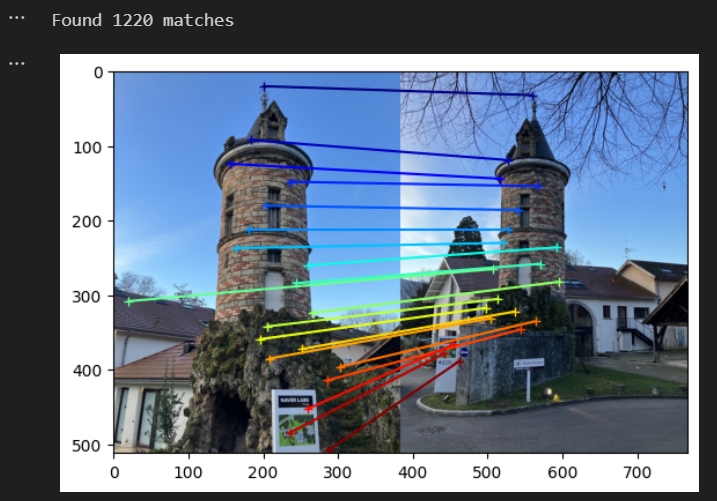
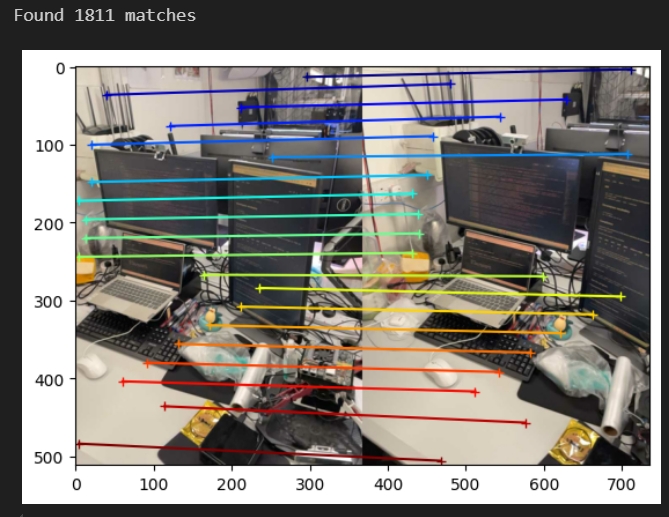

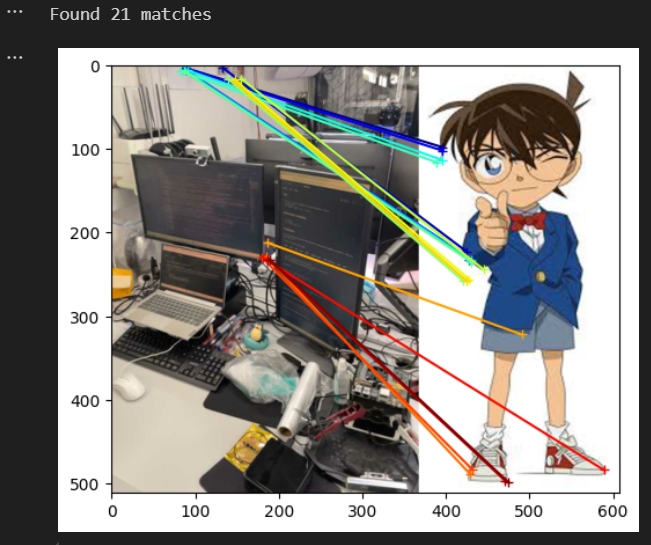
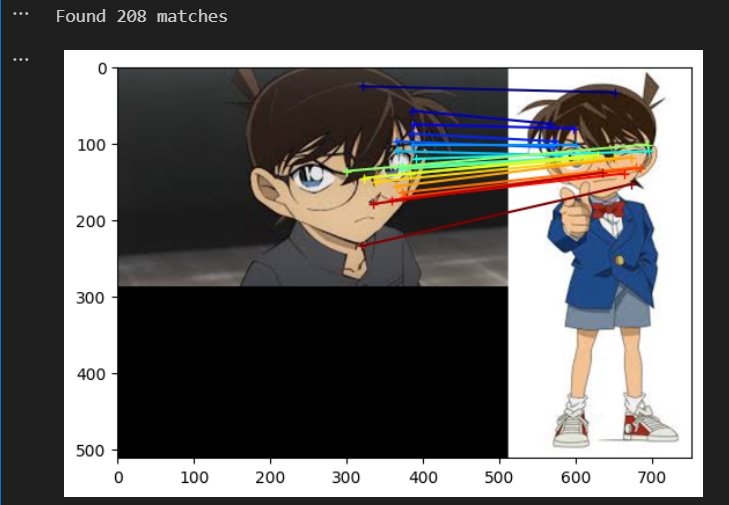
DUSt3R测试匹配的效果代码
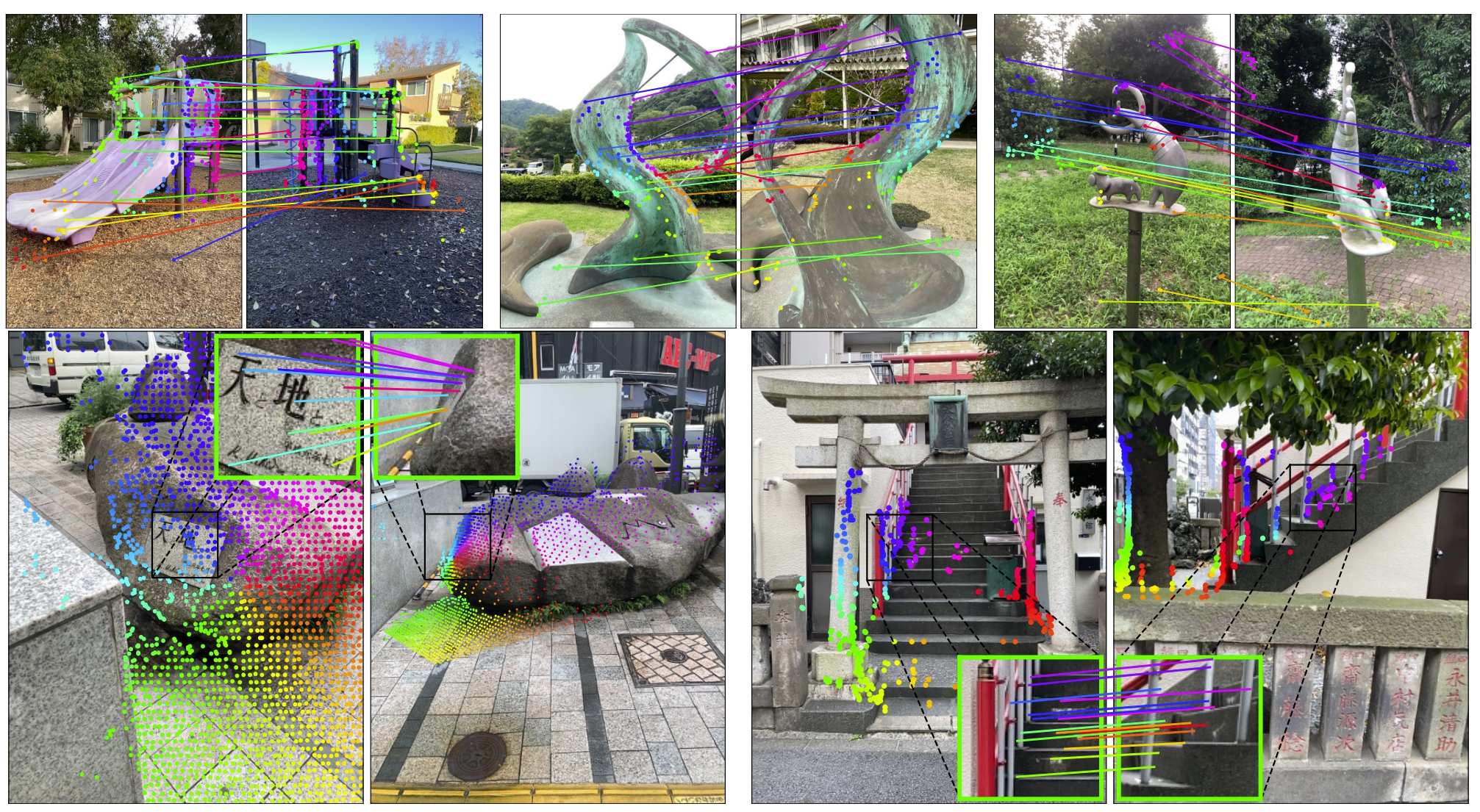
MASt3R可视化效果如下:
MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors
理论解读
在MASt3R提供的a two-view 3D reconstruction and matching prior基础上,作者通过引入有效的pointmap matching, camera tracking and local fusion, graph construction and loop closure, 以及second-order global optimisation,提出了MASt3R-SLAM,一个实时的单目稠密SLAM系统(可以实现15FPS的定位及稠密三维重建)。
同时,MASt3R原本就不依赖于camera的model,那么就可以实现reconstructing scenes with generic, time-varying camera models(也就是demo中zoom in zoom out的情况下的稳定三维重建).当然要达到在多个benchmark上的SOTA performance,还是需要“已知的标定参数”,但是这一点也不难,只是做相机标定而已~
PS:其实MASt3R的by-product或者MASt3R-sfm都可以实现定位的功能,加上原本的mapping就已经是一个full-SLAM的,但是都是离线式的。对于SLAM系统来说需要增量式接受数据以及实时,因此这也就是MASt3R-SLAM的意义所在。实时性以及一些列高效的处理(low-latency matching, careful map maintenance, and efficient methods for large-scale optimisation)
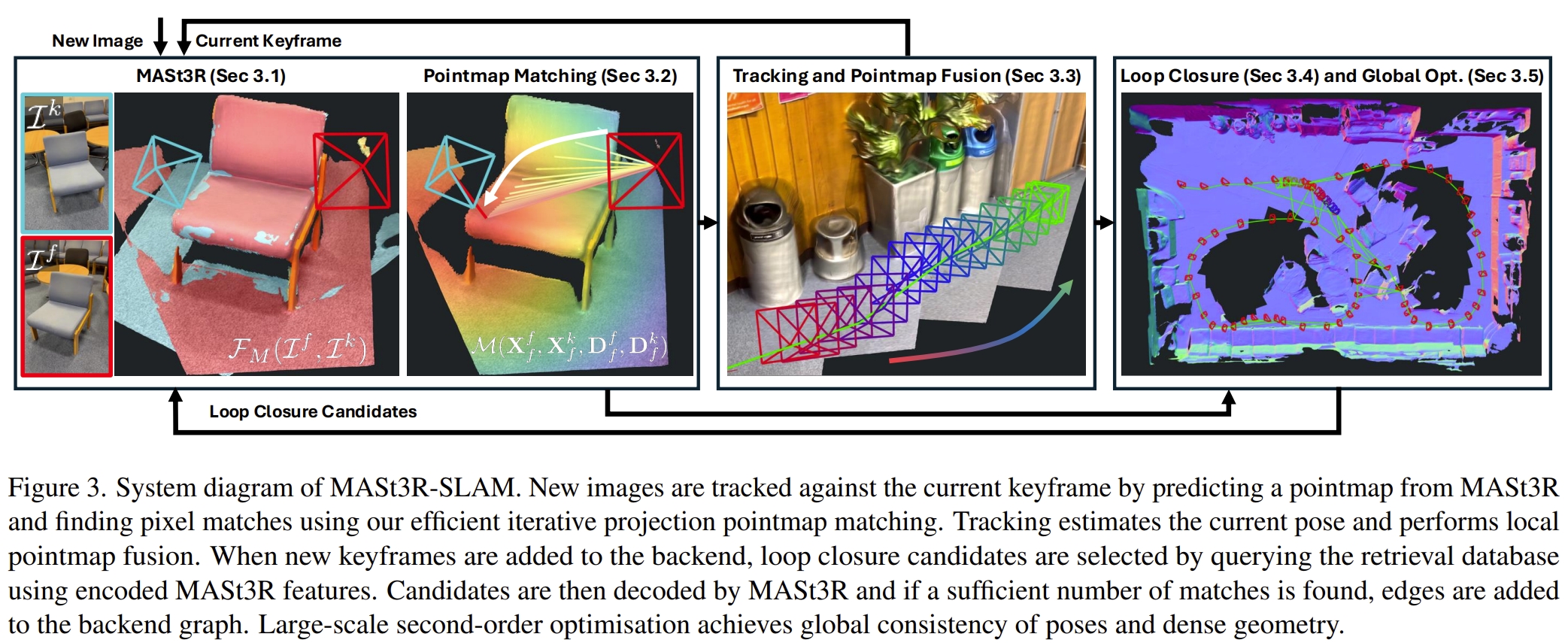
而通过 Levenberg-Marquard算法来计算大概10代左右就可以收敛。


接下来看看benchmark下的效果(our*就是未知内参矫正的)
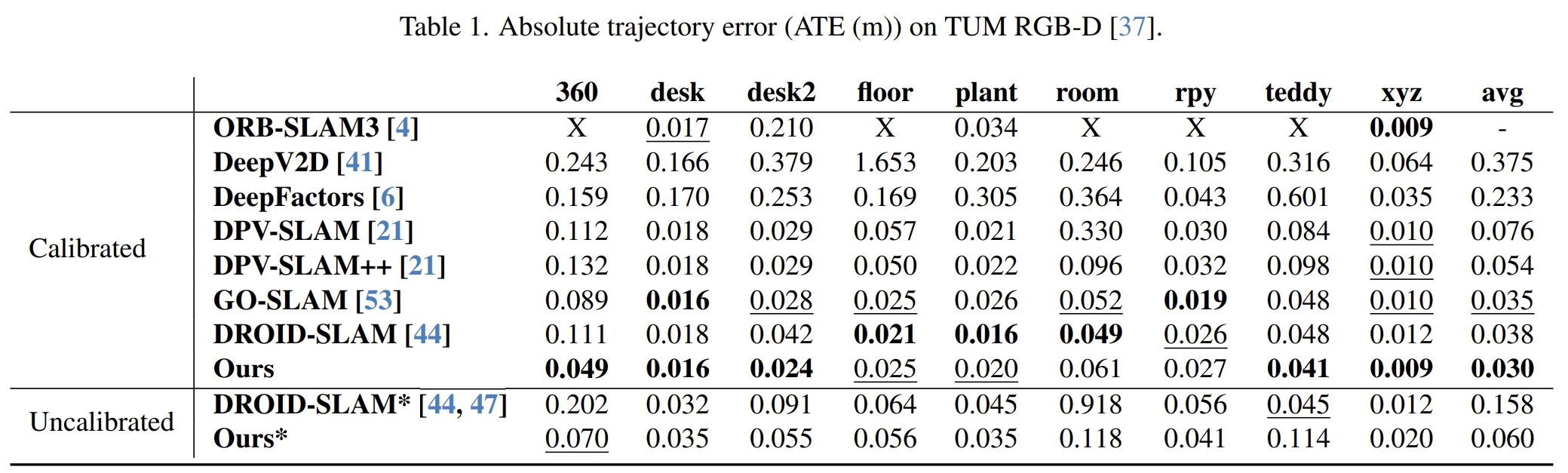
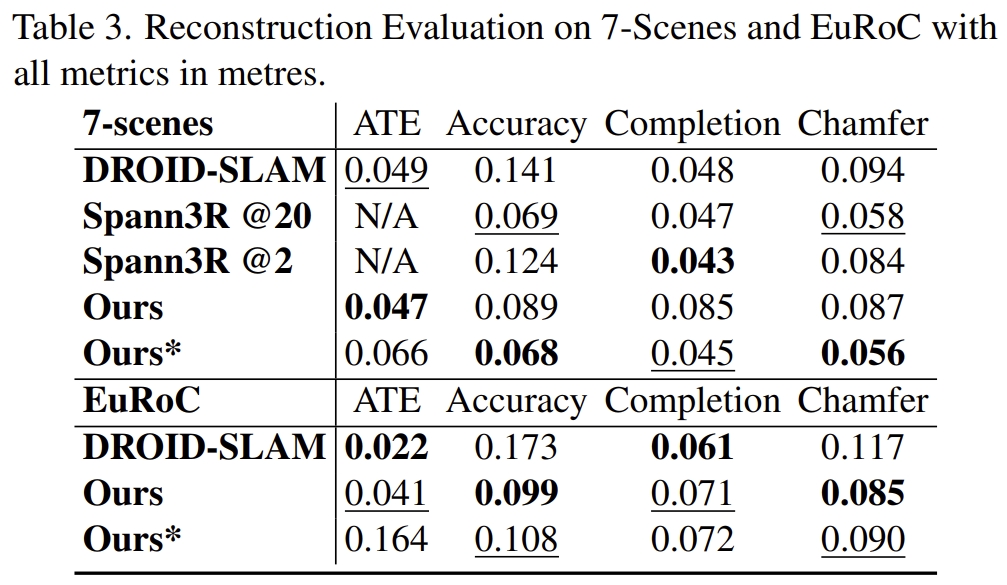
实验测试
测试记录请见:link