前言
Geoffery Hinton 也曾经说过“AI 质疑者一错再错,未来还会继续被打脸”。而最近,我确实深深感受到了自己被打脸了🫢,因为原本也是认为AI是一个噱头而已。 在18~19年的时候,我在中科院的MML待了一年多,当时主要的topic是deep learning in super resolution。当时我接触的项目、阅读的所谓"三大"顶会的论文给我的感觉是虽然performance一直在刷,但好像并不能实用(虽然现在大部分的paper也都是如此)。而后来,我开始从事event-based vision的工作,也是大量的deep learning-based 的方法,一般我看到用learning-based的方法arvix论文都会直接跳过😂。 但随着我在robotic领域的研究,特别是event-based SLAM在传统方法上遇到了瓶颈转而用learning-based framework取得重大进展,以及特斯拉的FSD end-to-end 的vision-to-autonomous driving的突破,我开始重新思考AI的价值。 而回过头来发现之前在learning领域的积累几乎全部忘光光了,为此以本博客作为一个学习的笔记,重新复习以及学习一下AI的基础知识。Machine Learning
Supervised Learning
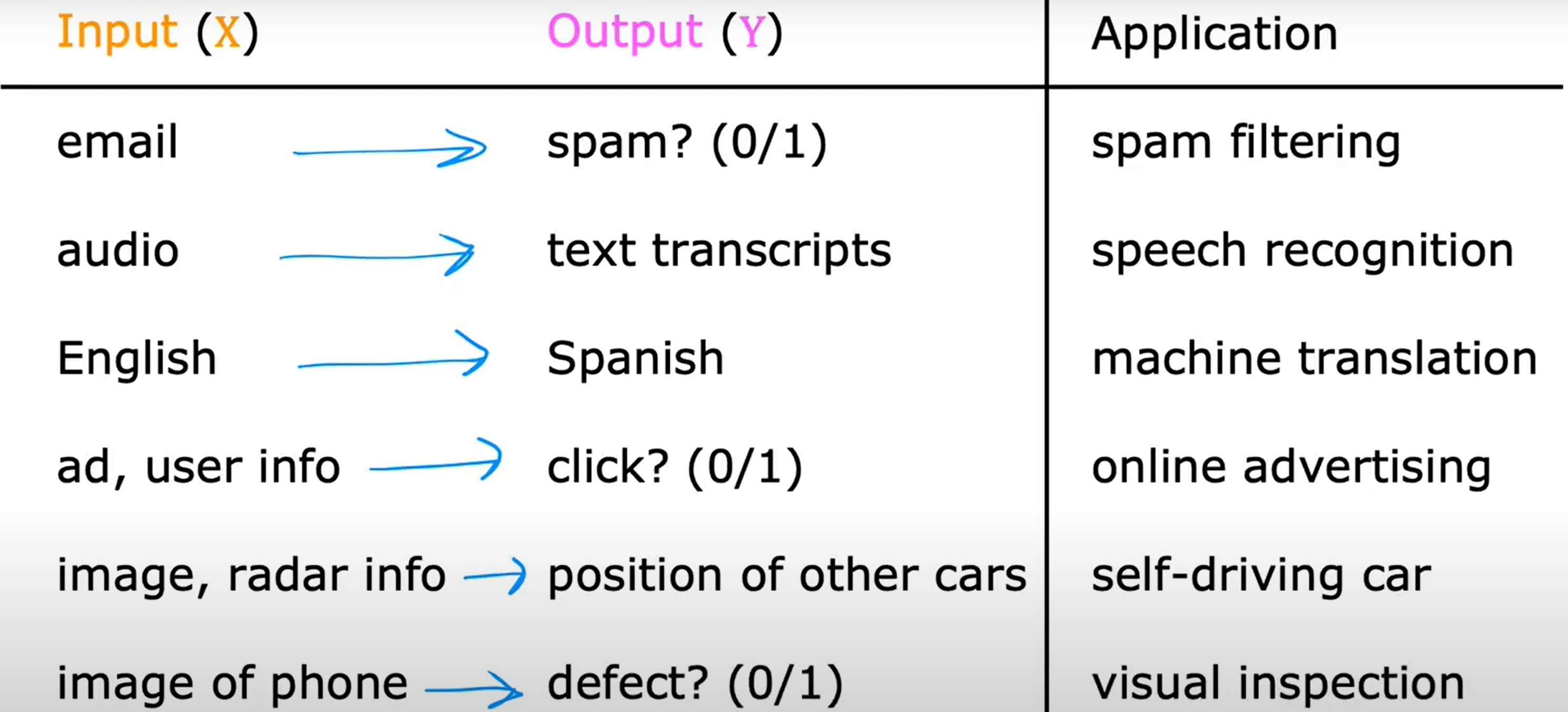
一些经典的Supervised Learning的例子,如下图。简单而言就是给定一些数据,然后给定一些label,然后让机器学习这个数据和label之间的关系,然后预测未知数据的label。
Supervised Learning可以分为两类:Classification和Regression。Classification是预测数据的label是离散的(分类),而Regression是预测数据的label是连续的(回归,拟合曲线,预测数值)。
回归一般是预测数字,可能有无穷多个值,而分类是预测类别,一般是有限个值。
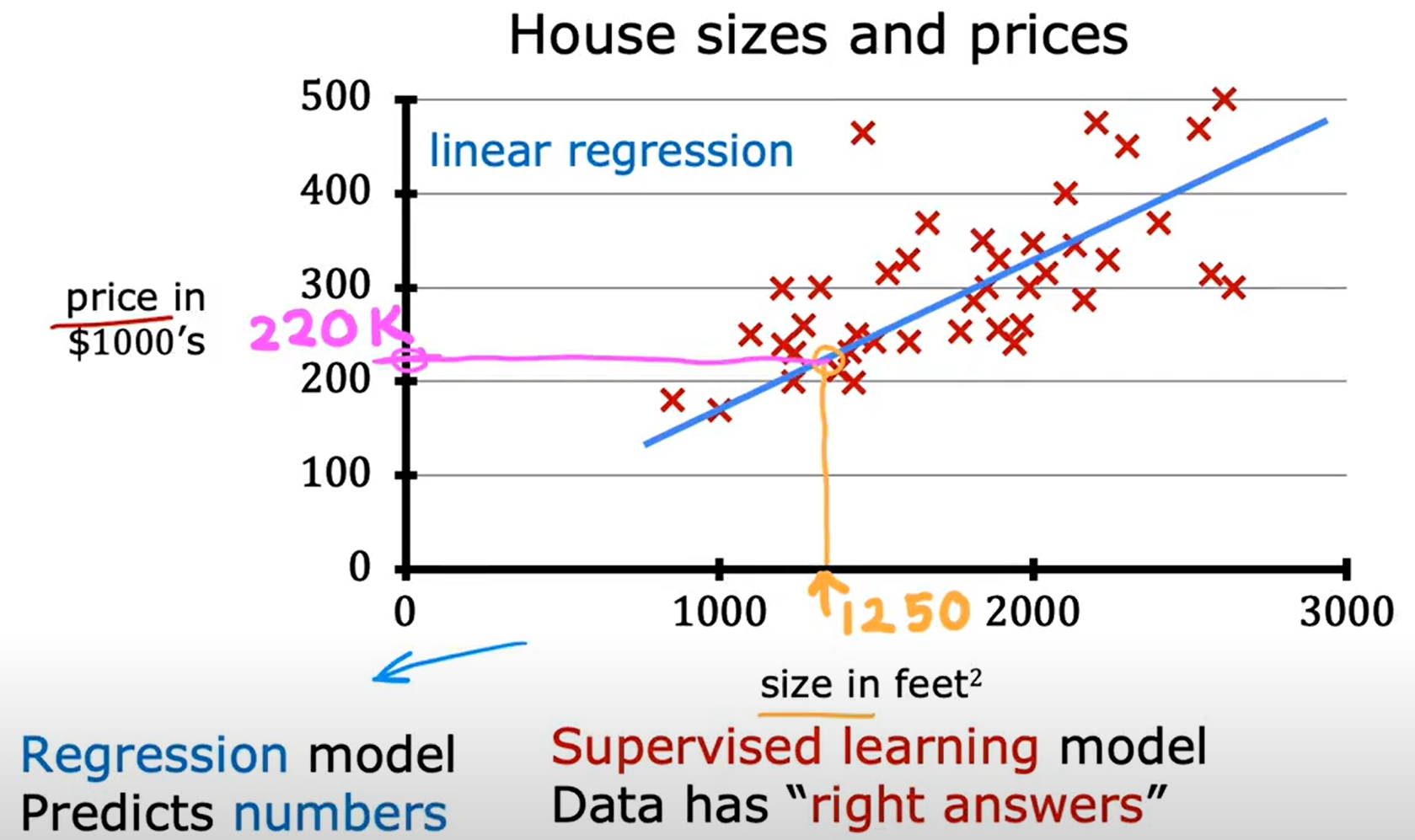
Linear Regression Model (线性回归模型)
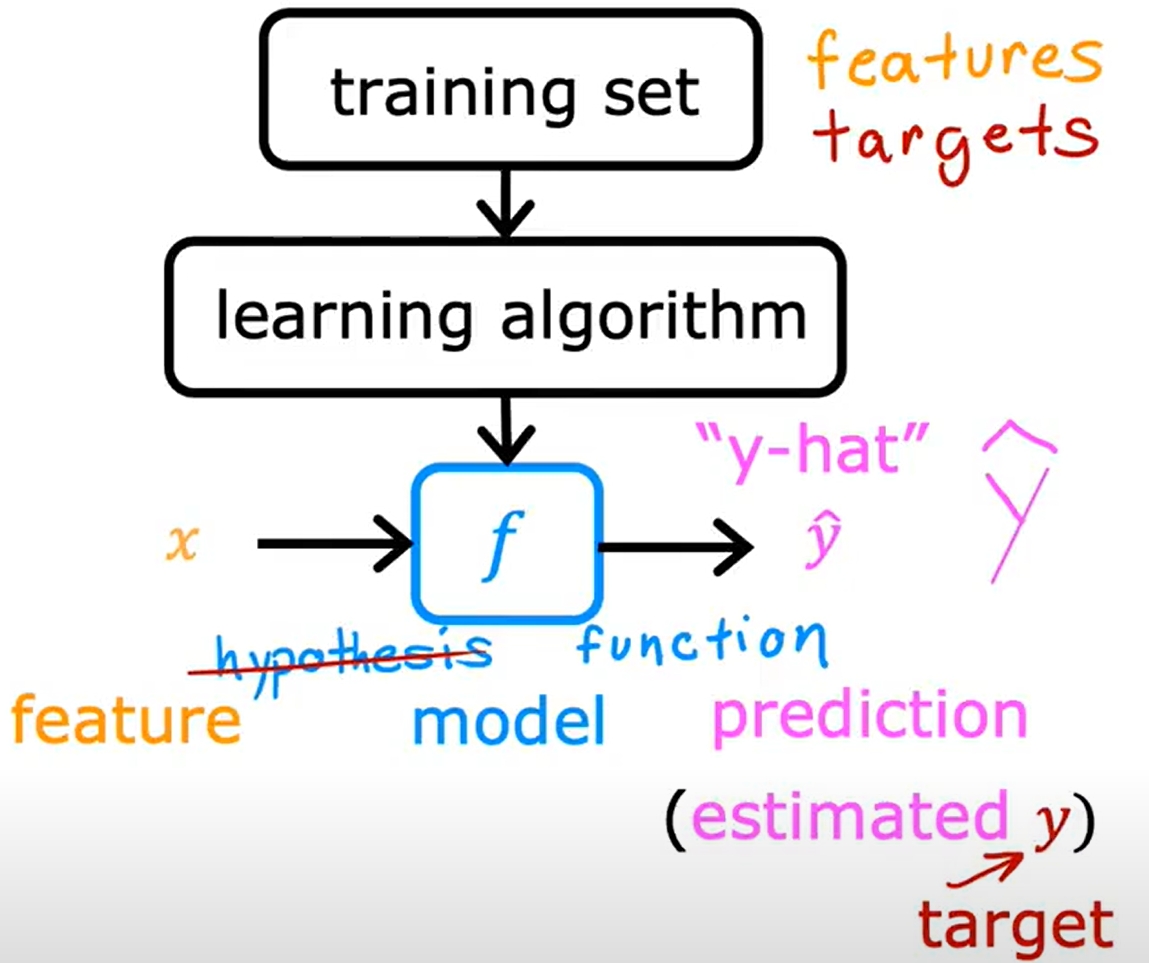
接下来通过实现一个线性回归模型来预测房价,来更好地理解Supervised Learning的基本原理。
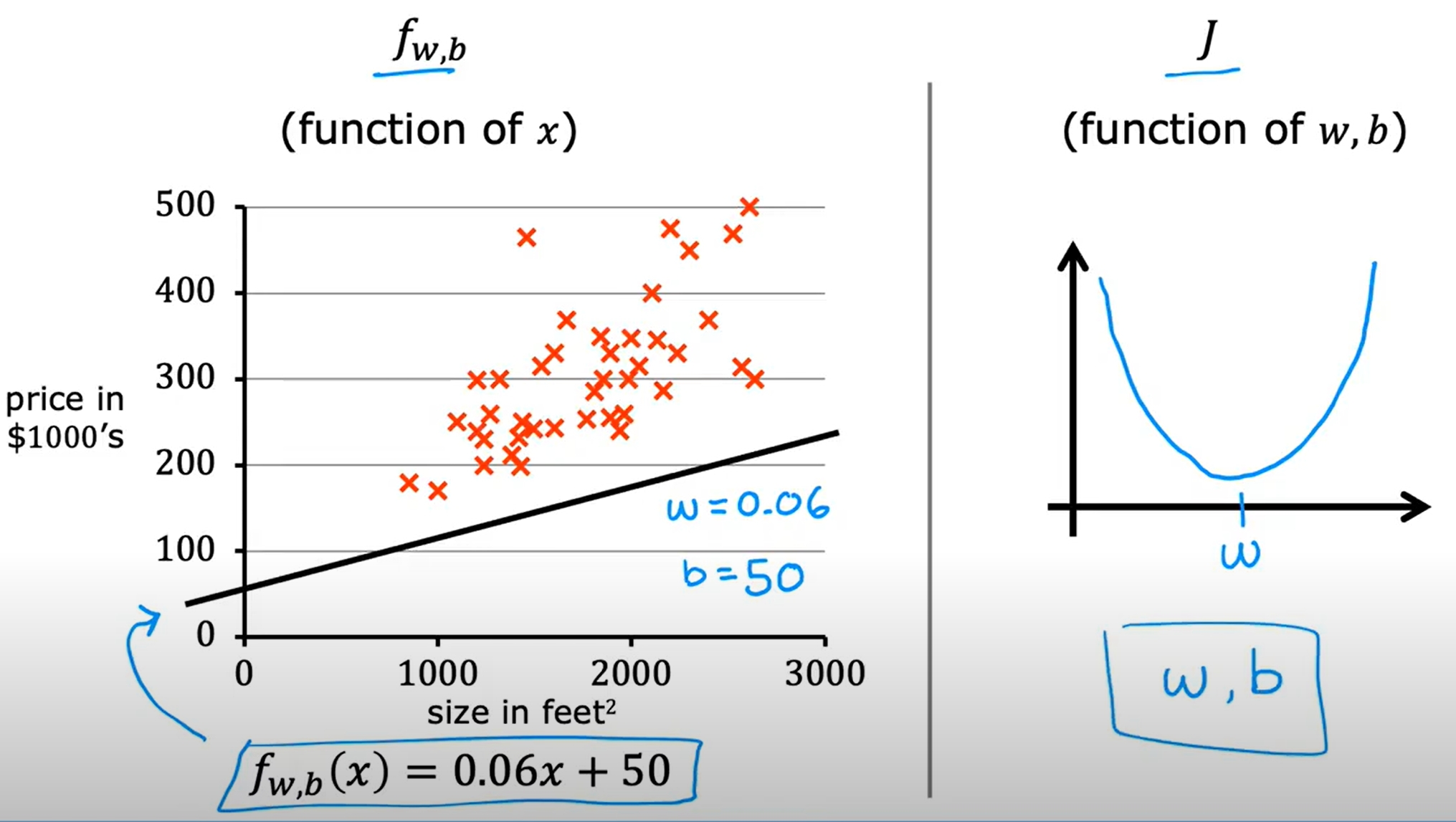
f(x)=wx+b
不同的w与b有不同的表现,如下图
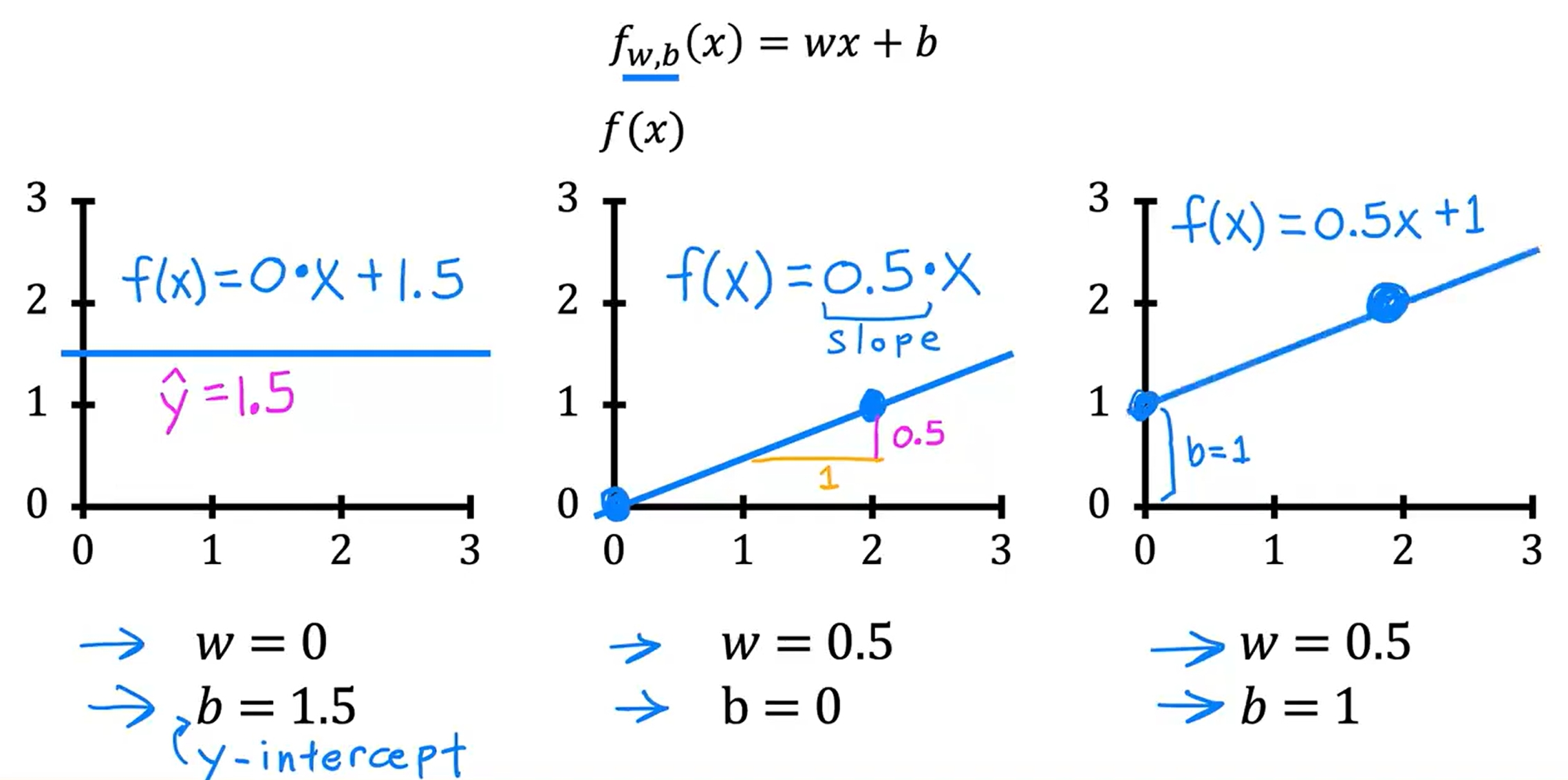

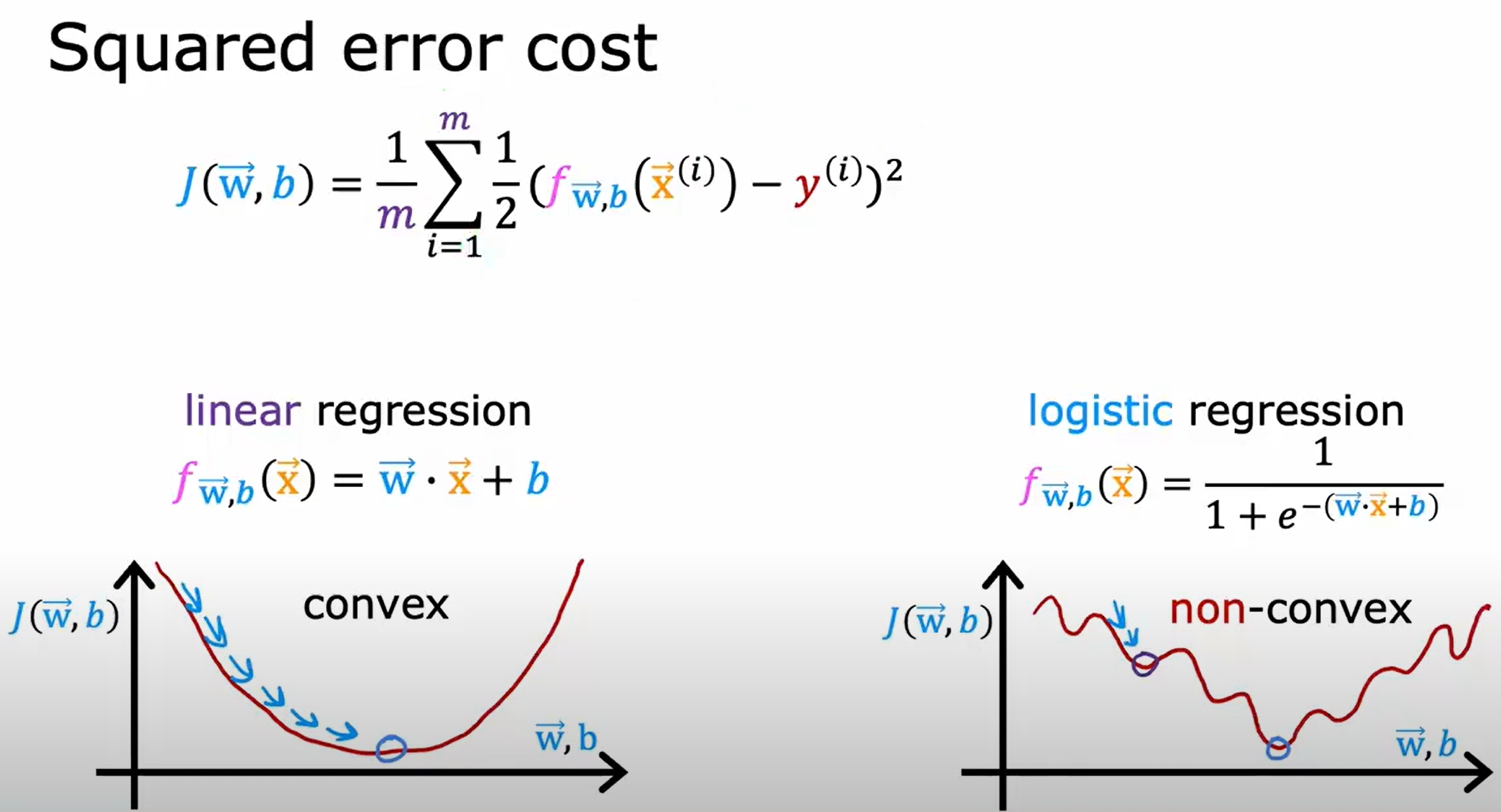
Cost Function的直观理解
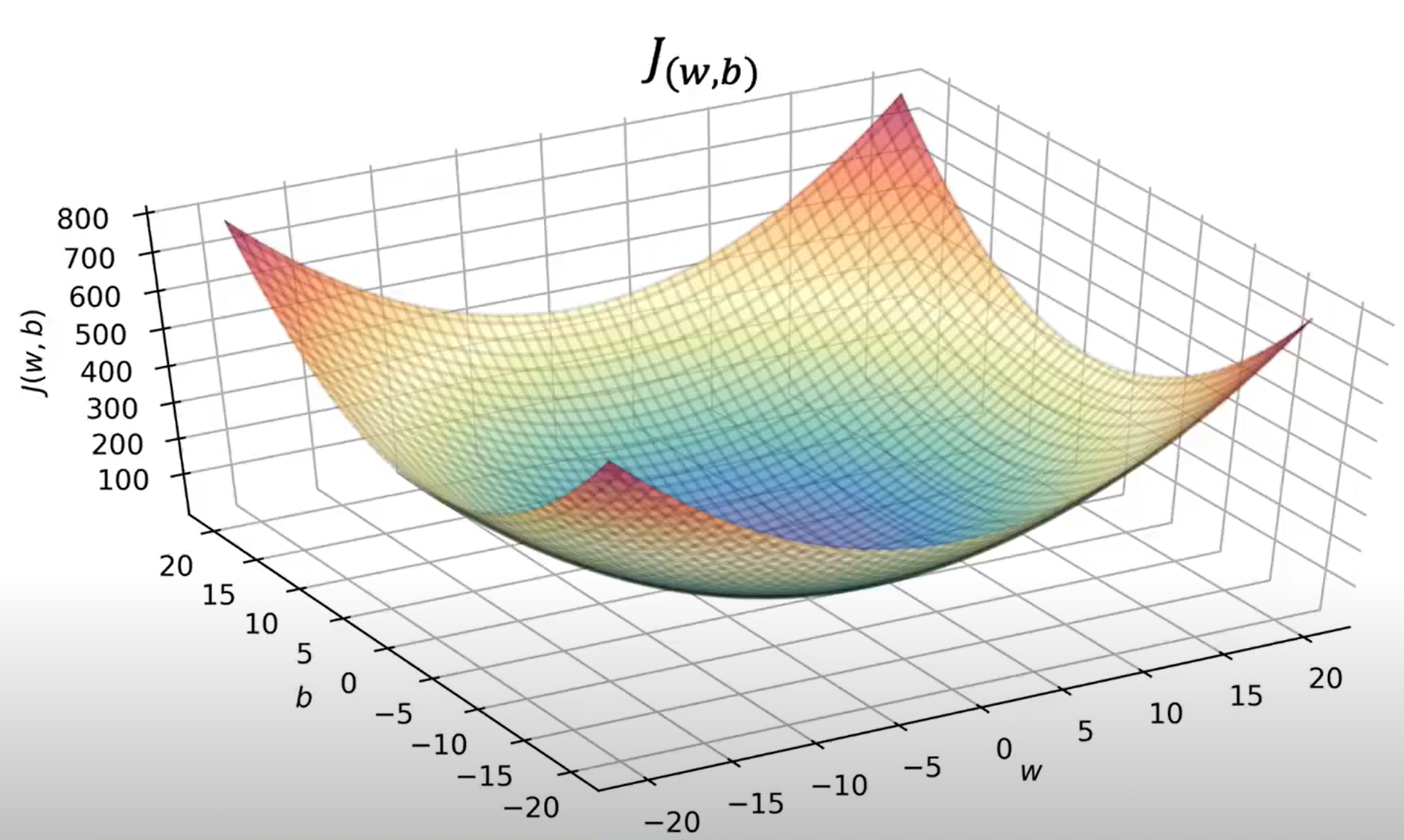
对于只有一个w参数的时候,cost function的图像如下,可以看到cost function是一个凸函数,只有一个最小值点。
gradient descent(梯度下降)
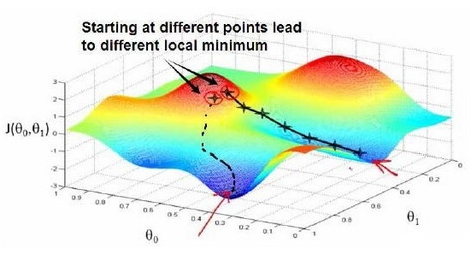
梯度下降是一个用来求函数最小值的算法。在机器学习中,我们使用梯度下降来最小化cost function。梯度下降的基本思想是:从一个随机的w和b开始,然后不断迭代更新w和b,使得cost function最小化。公式化表达如下:


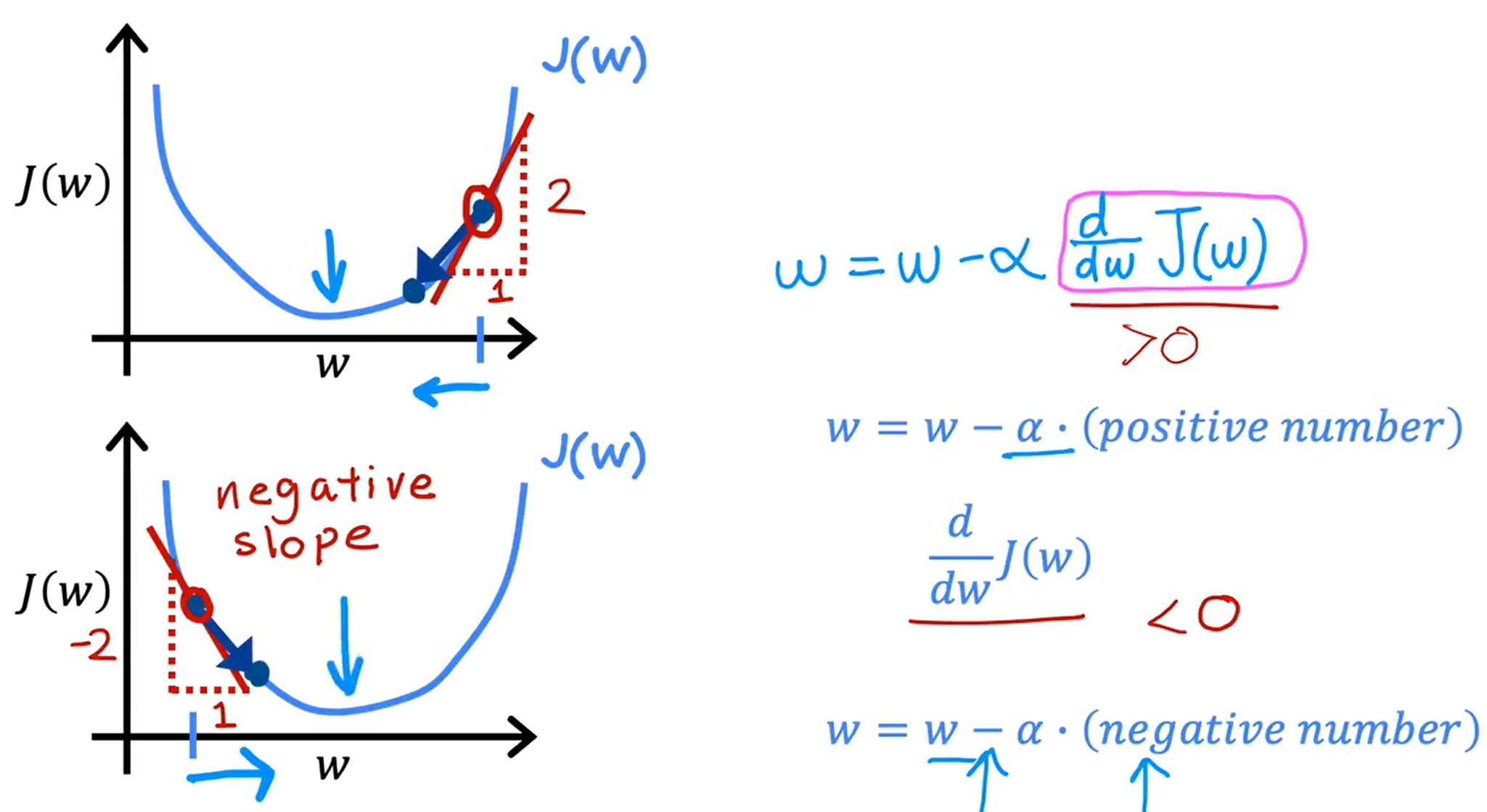
对于固定的学习率,会伴随着Derivative变小,update step也变小,最终到达local minimum。
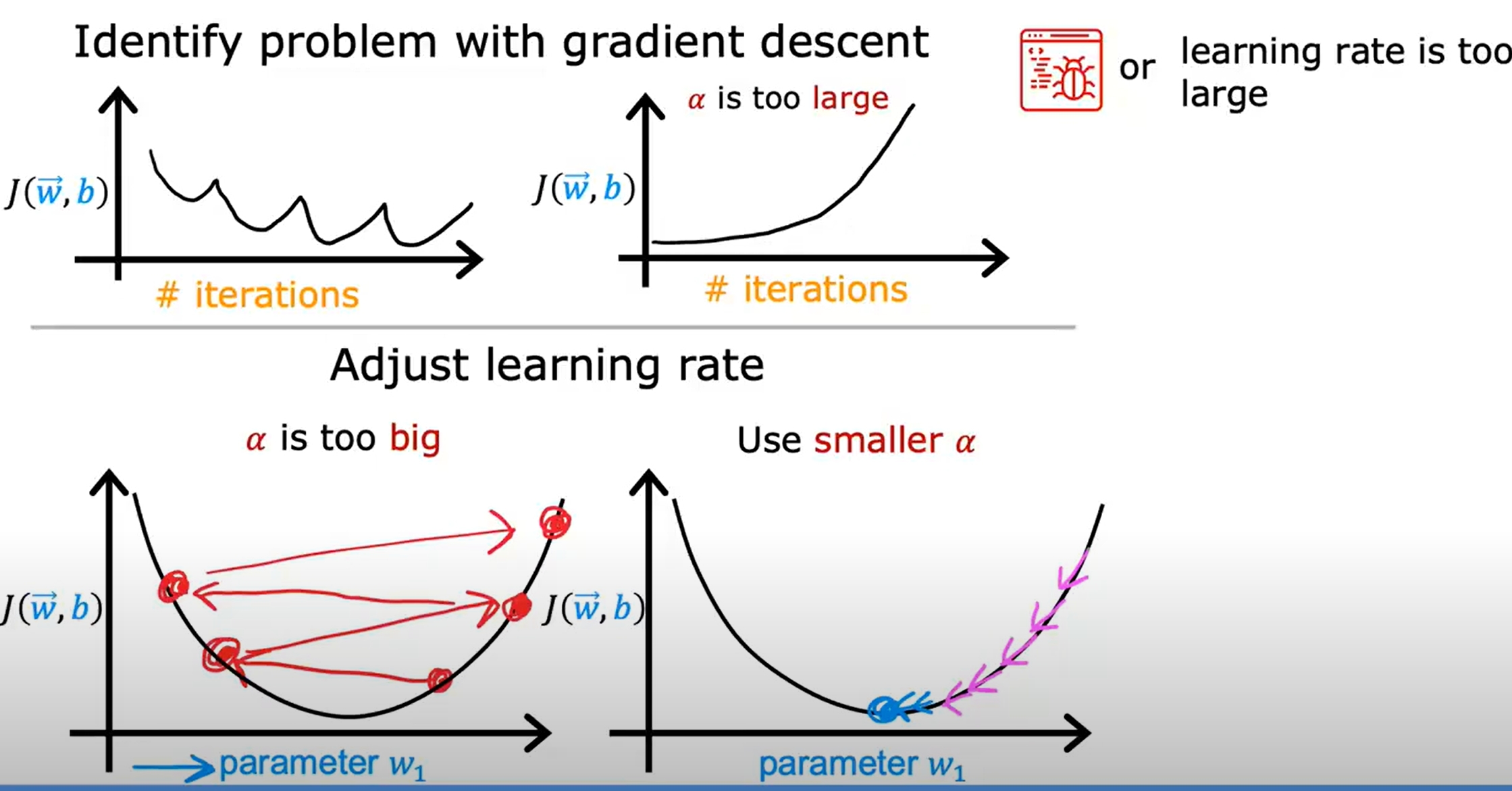
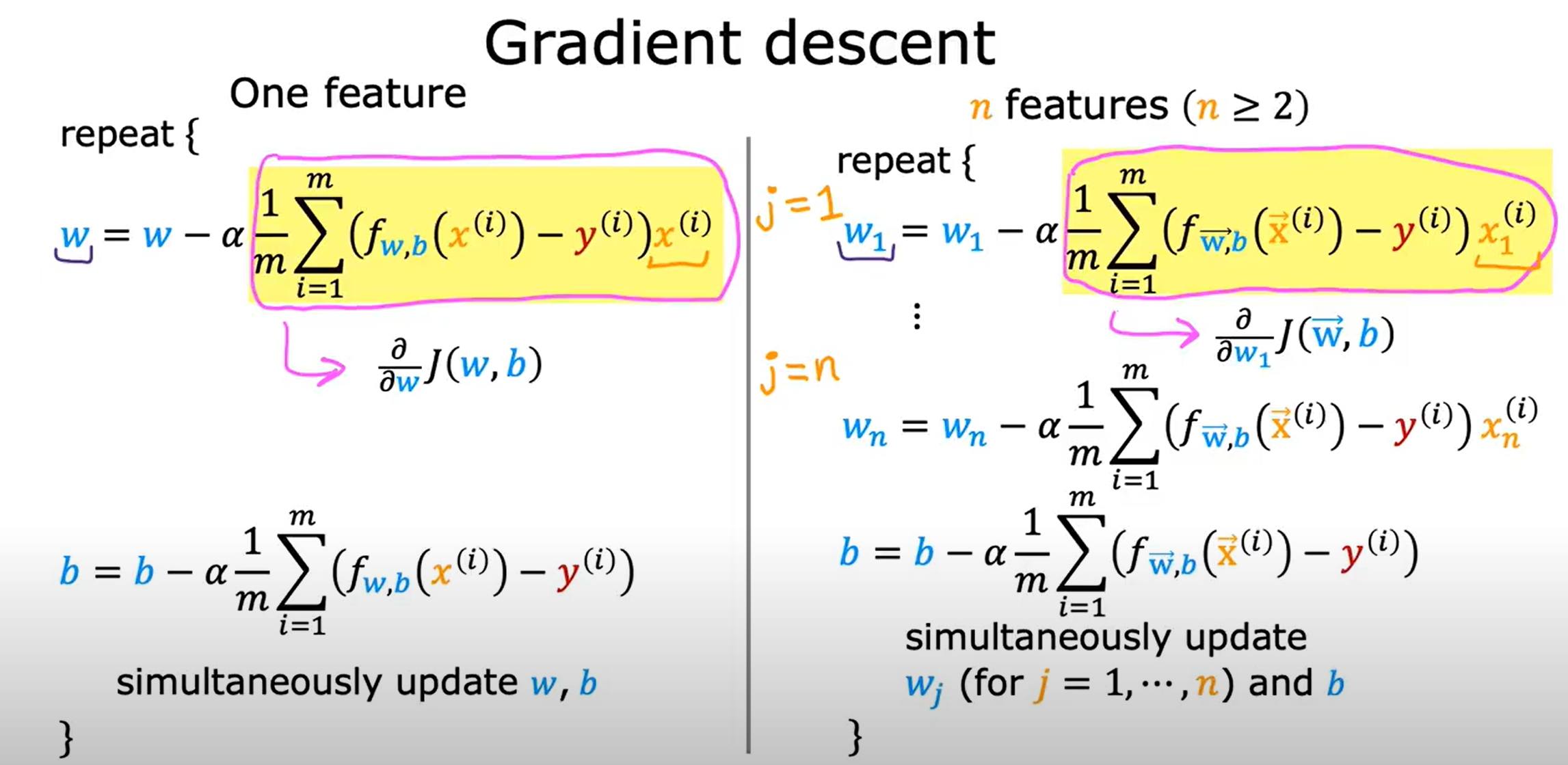
Gradient Descent for Linear Regression

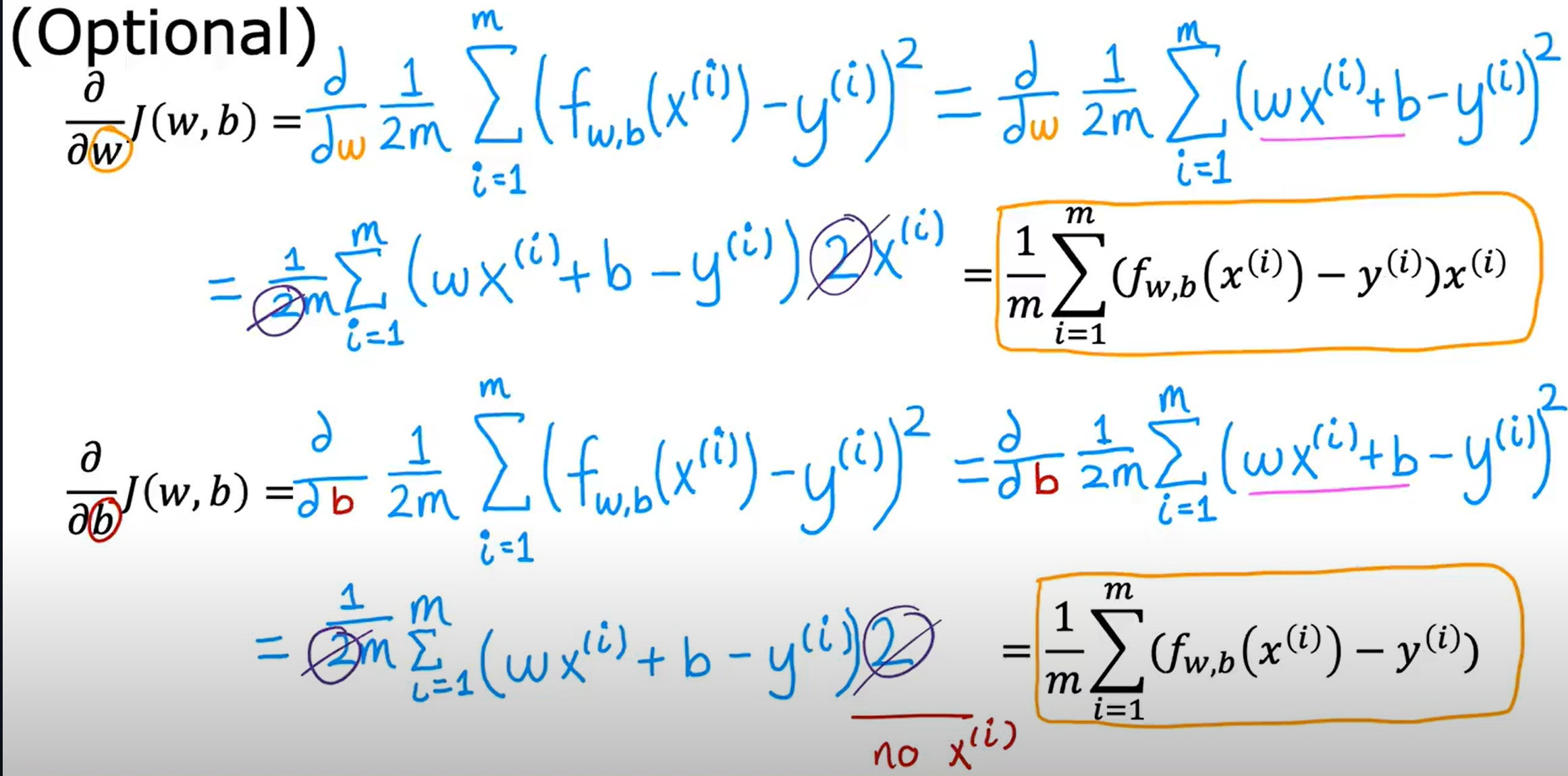
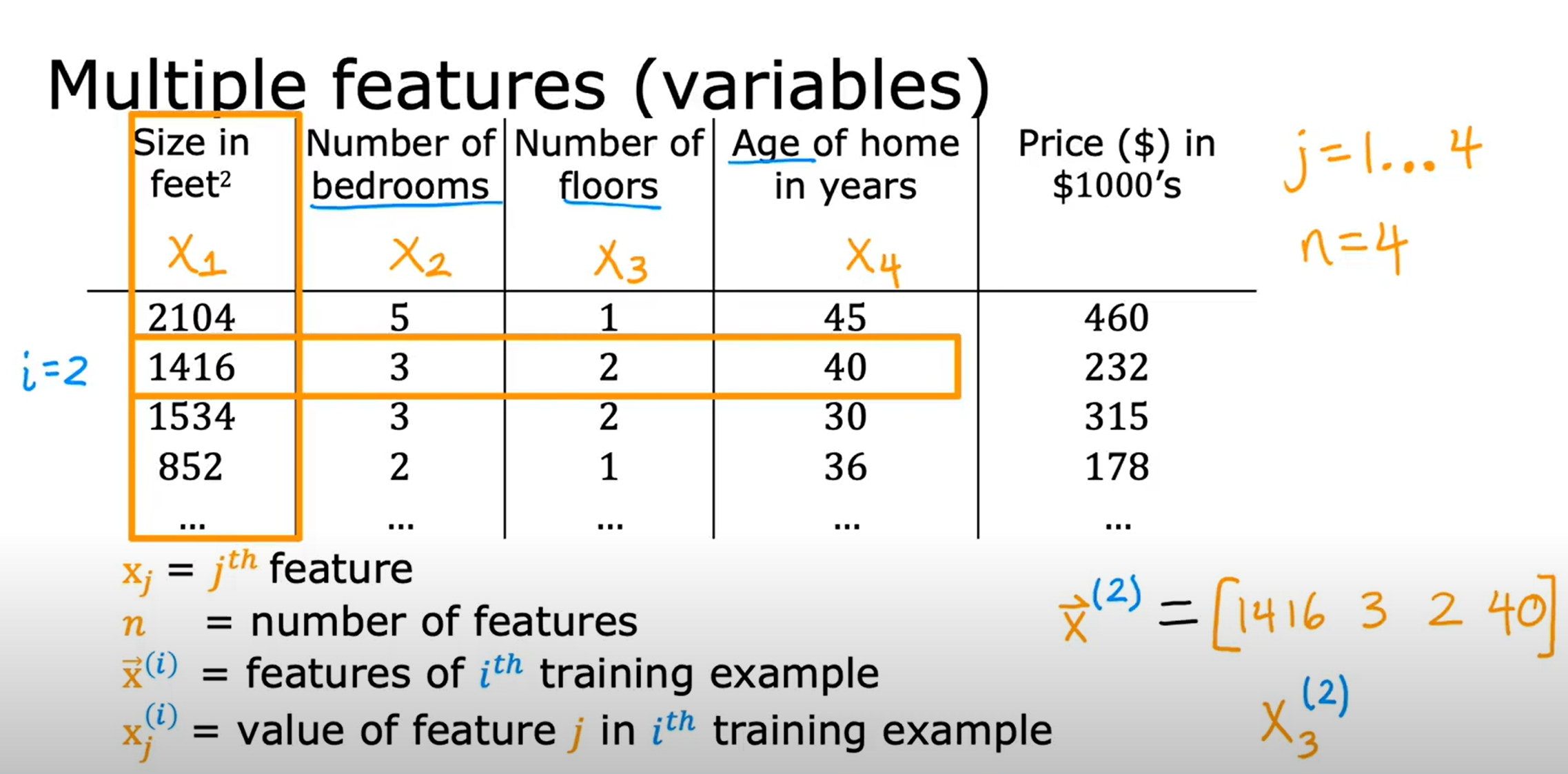
多变量线性回归(Linear Regression with Multiple Variables)
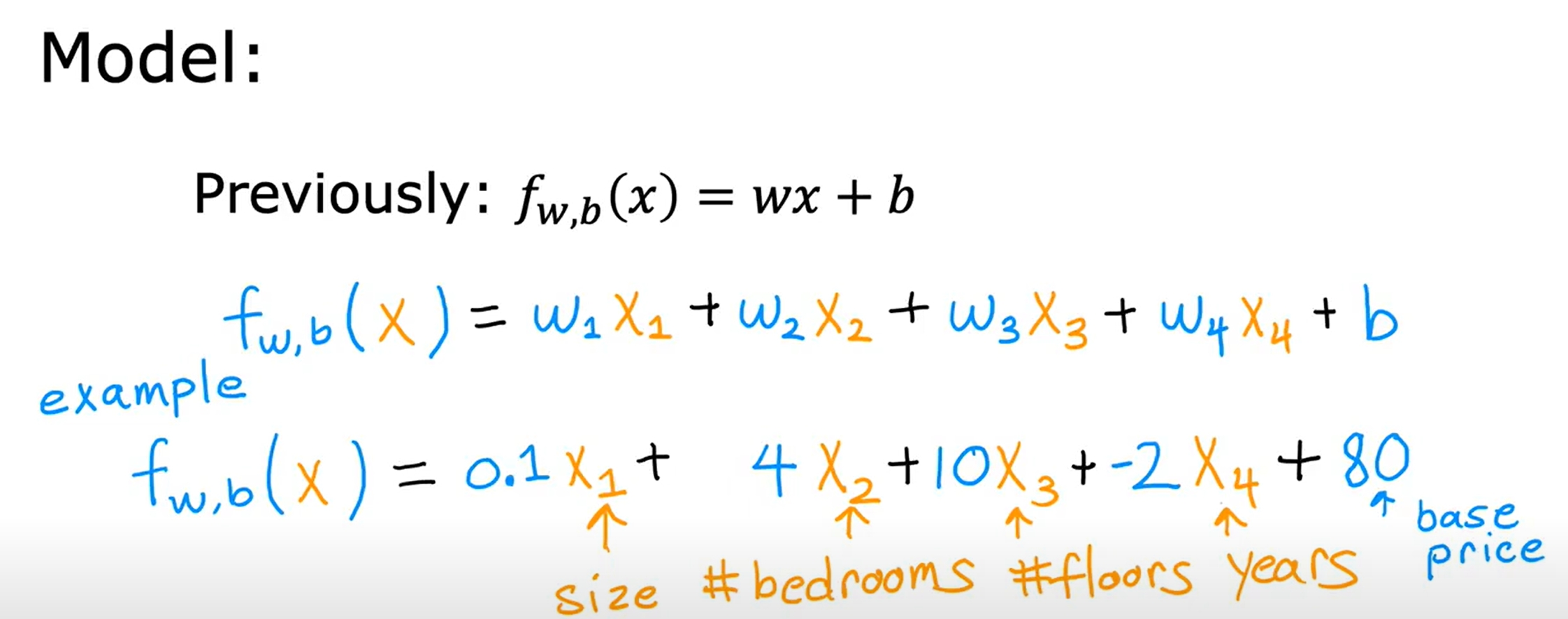
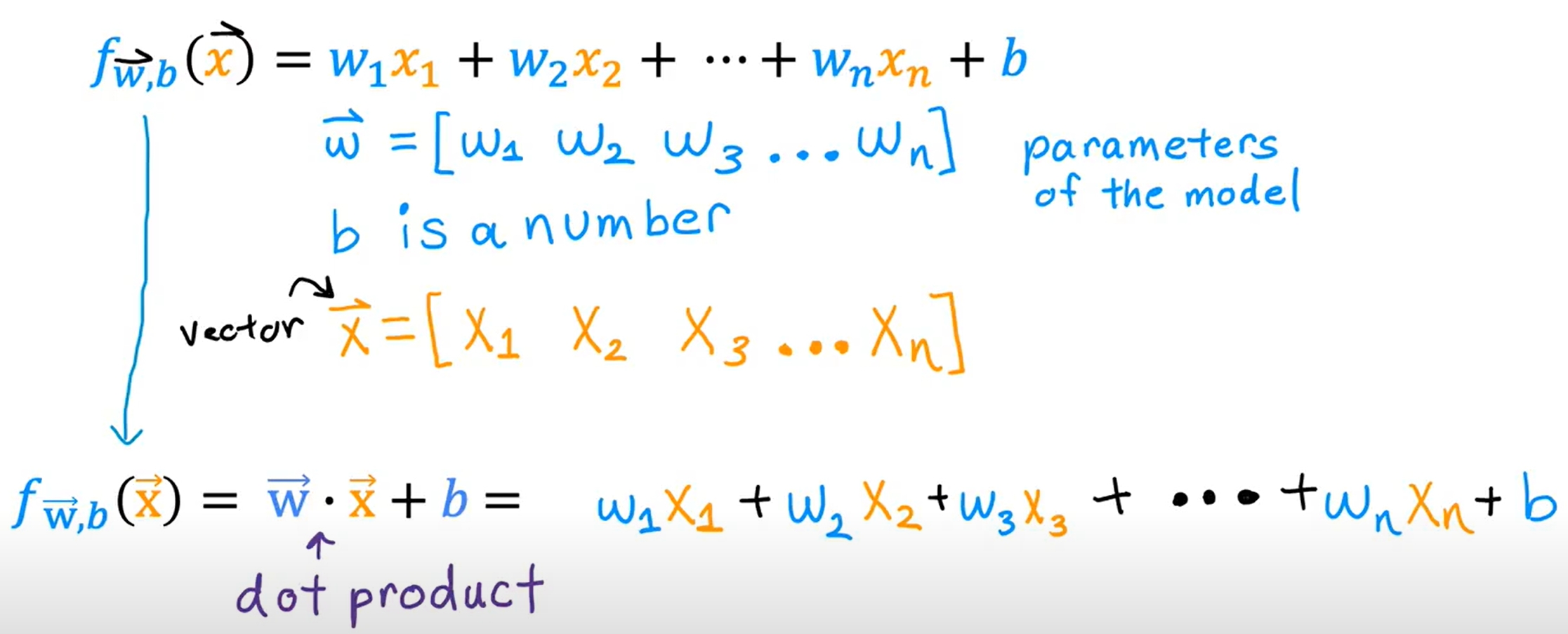
Vectorization(向量化) for Coding

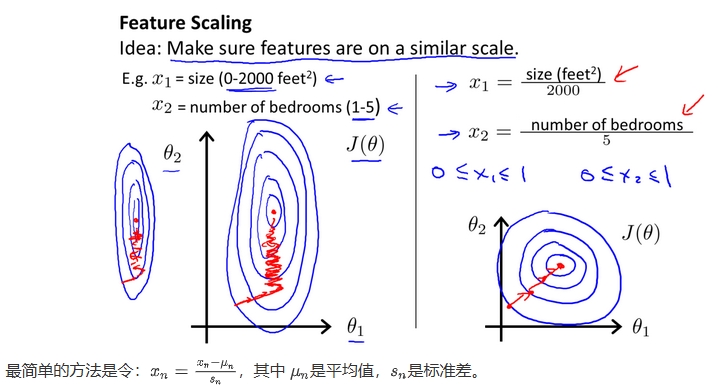
Feature Scaling(特征缩放)
在我们面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。
解决的方法是尝试将所有特征的尺度都尽量缩放到-1到1之间。
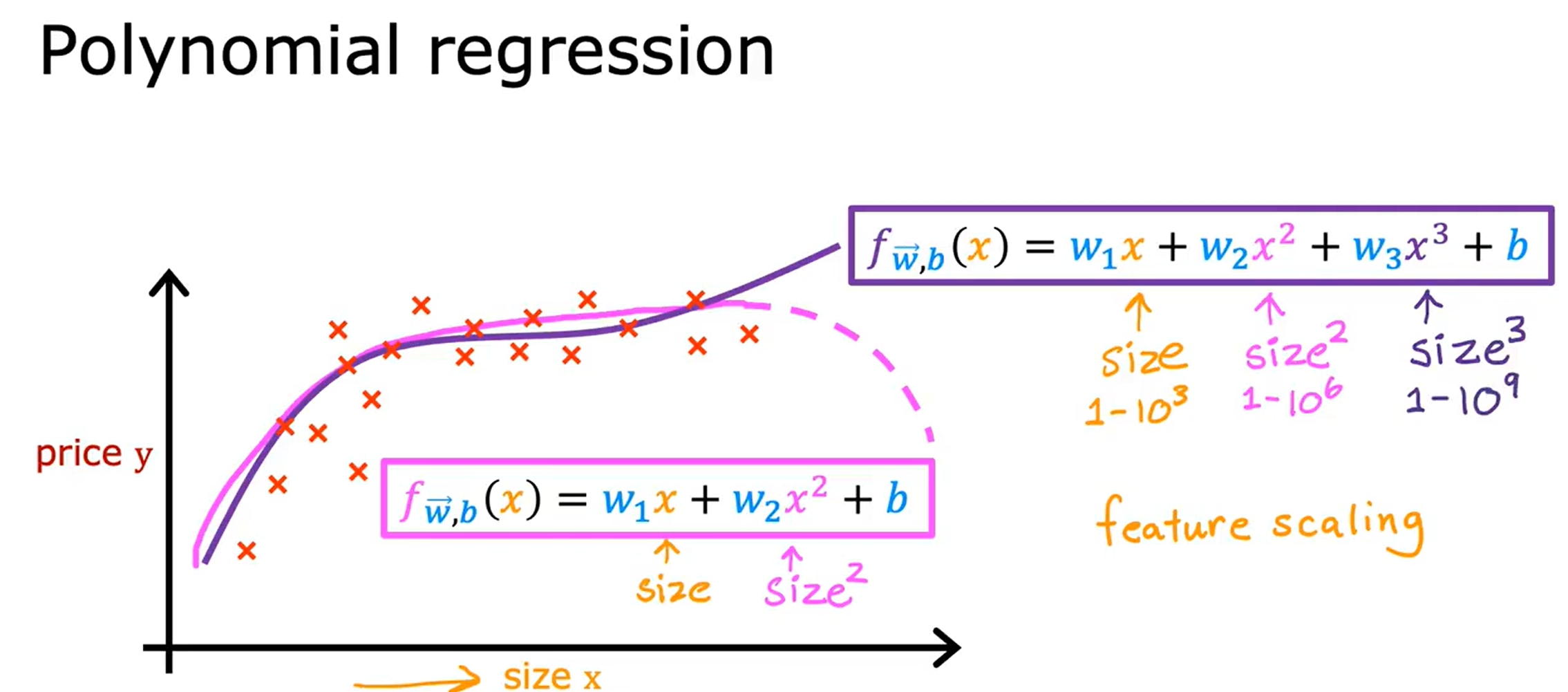
Polynomial Regression(多项式回归)
有时候,线性回归并不能很好地拟合数据,这时候可以考虑多项式回归。
线性回归代码实现
Logistic Regression(逻辑回归)
上一节的线性回归是用来预测连续值的(回归问题),而逻辑回归是用来预测离散值的,也就是分类问题(Classification)。
而分类问题又可以分为二分类(Binary Classification)和多分类(Multiclass Classification)。
而逻辑回归函数表达如下图所示

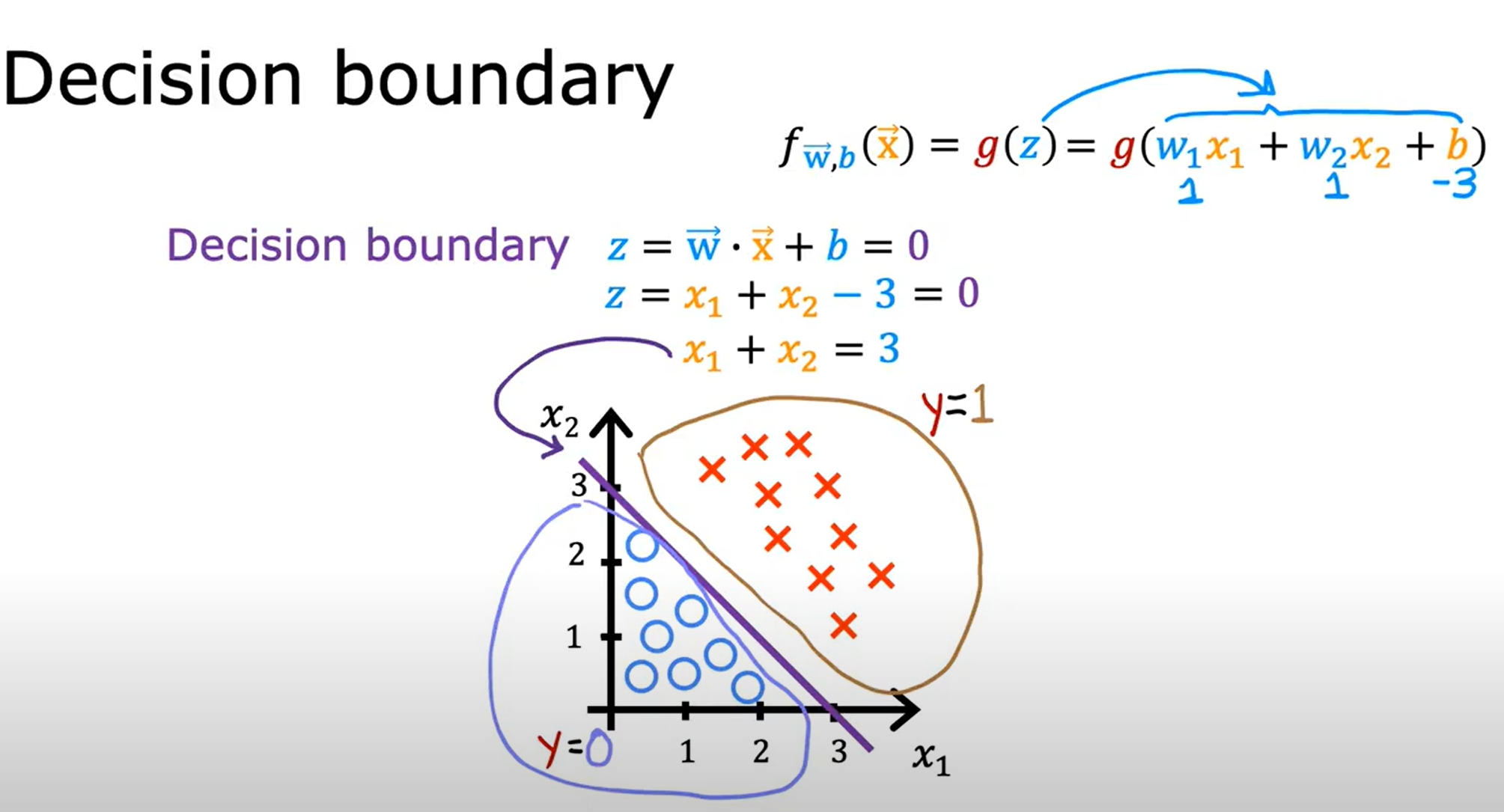
Decision Boundary(决策边界)

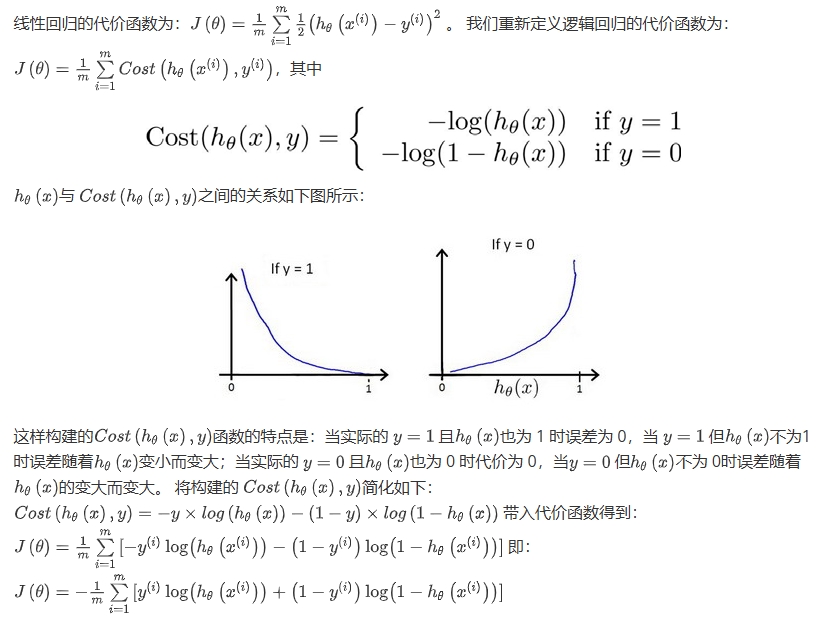
逻辑回归的cost function
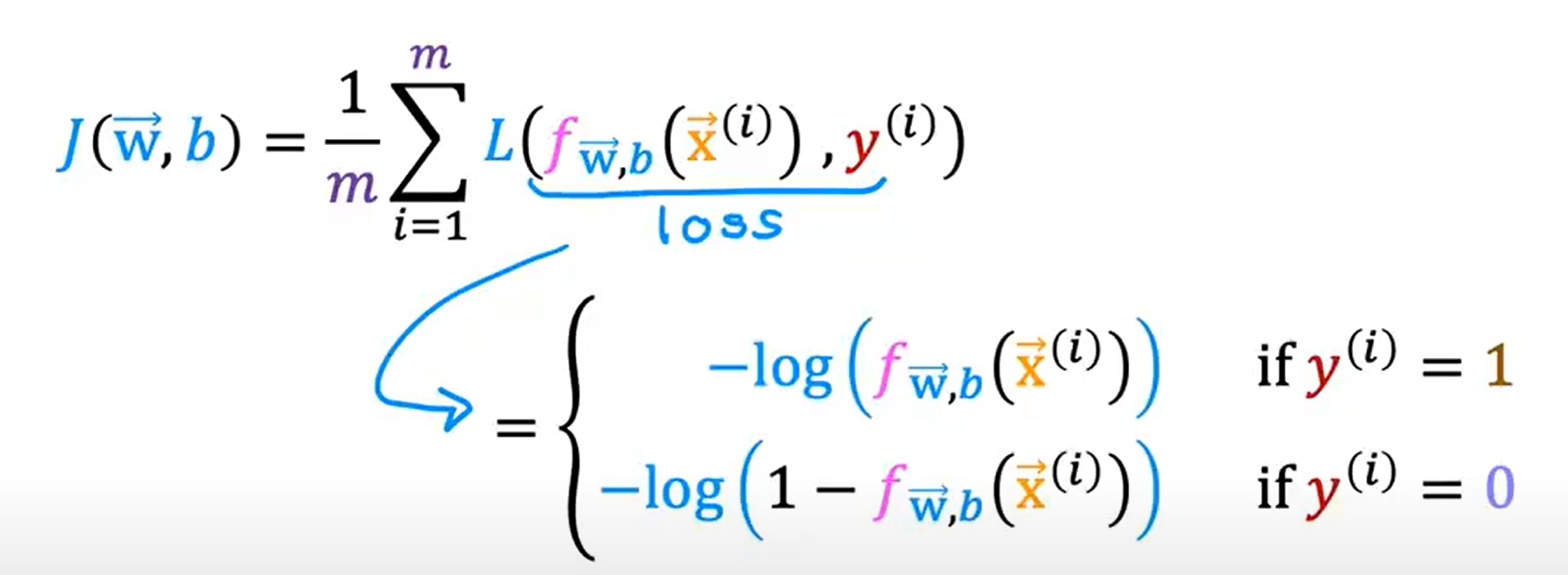
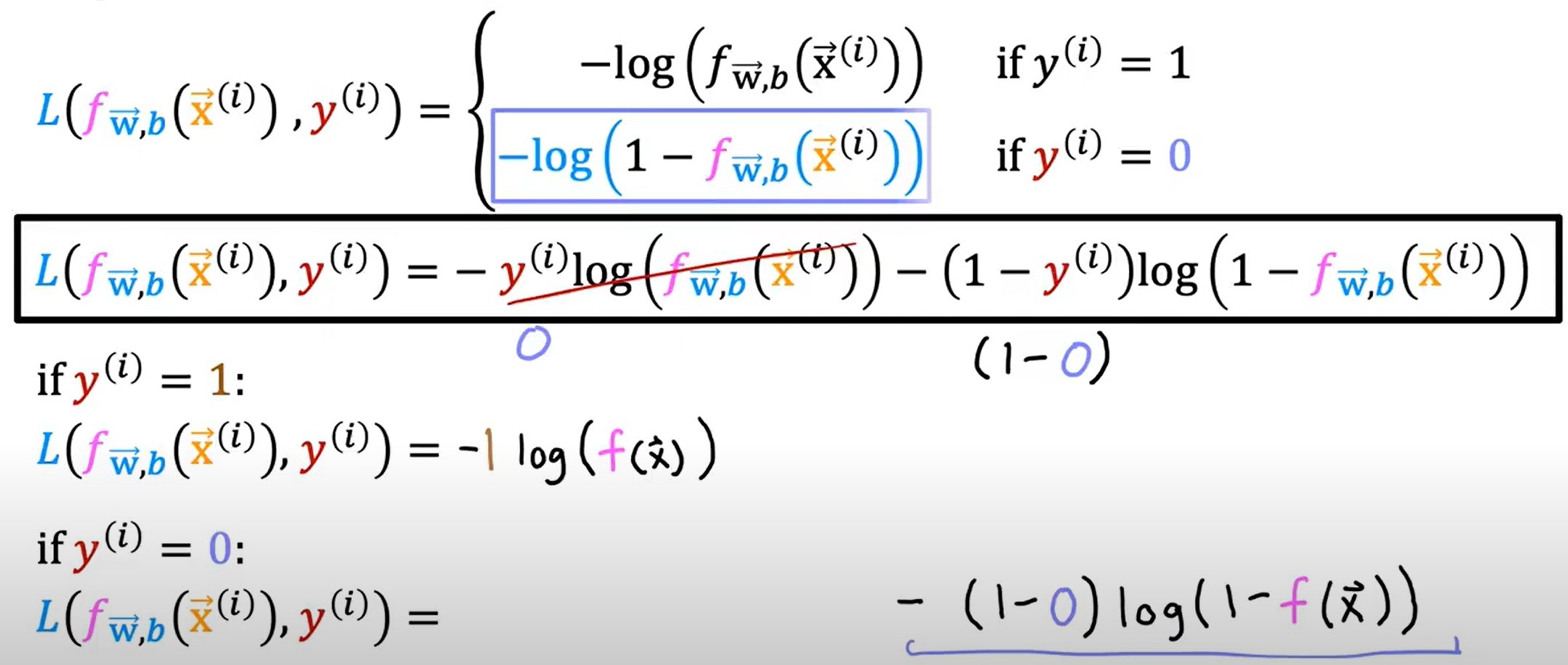
Training Logistic Regression with Gradient Descent


但注意函数f也是不一样的!
逻辑回归代码实现
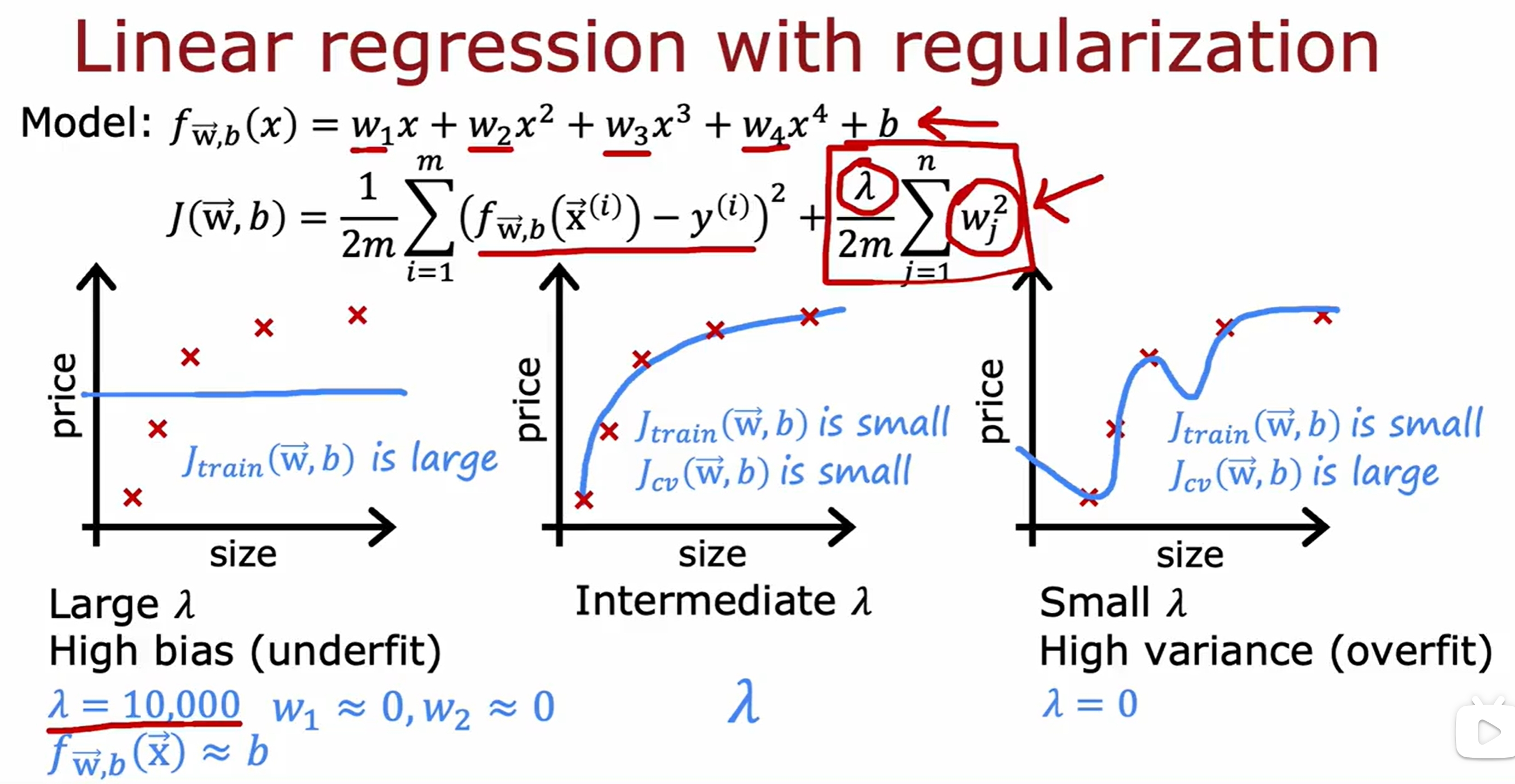
过拟合与正则化(Overfitting and Regularization)
欠拟合与过拟合是机器学习中常见的问题,欠拟合是模型过于简单,无法很好地拟合数据,而过拟合是模型过于复杂,过度拟合了训练数据,导致在测试数据上表现不佳。
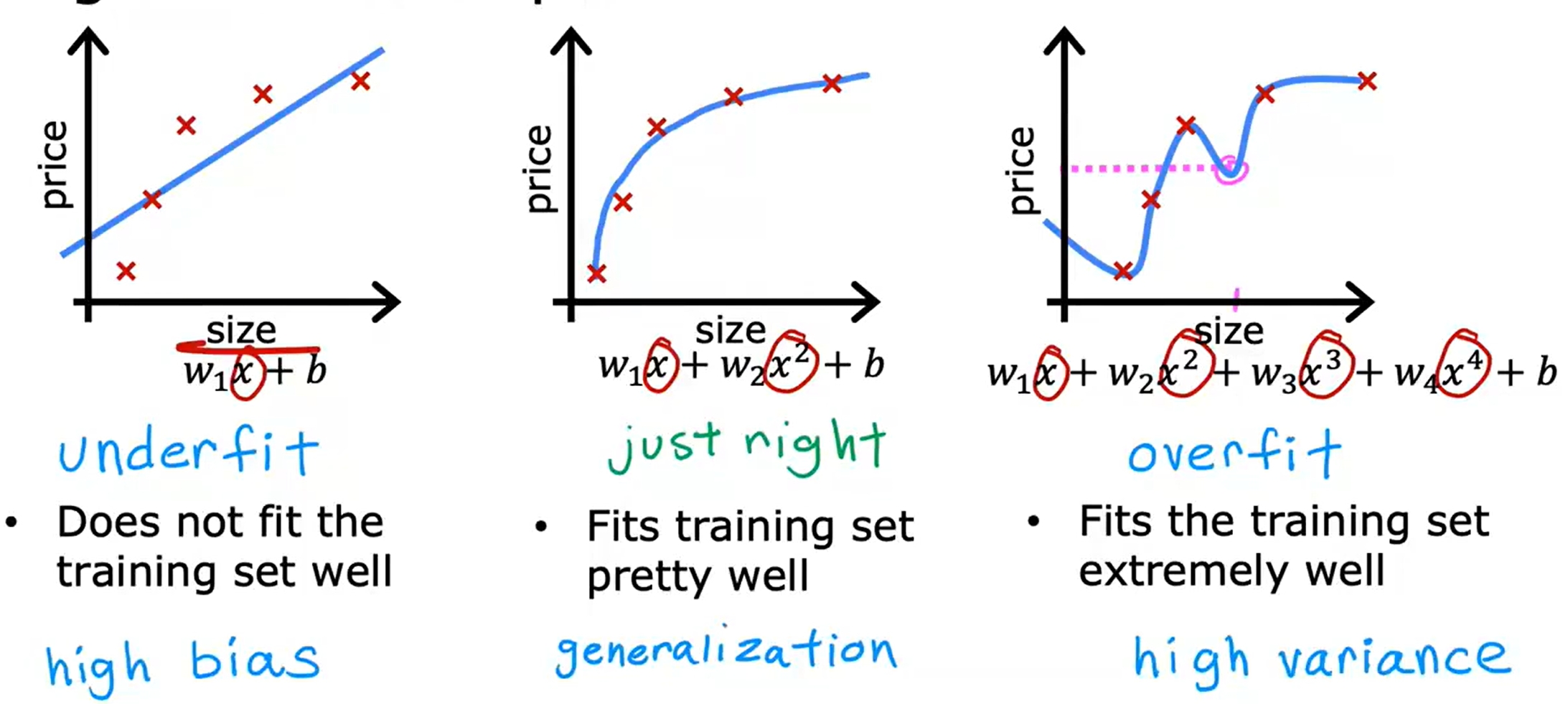
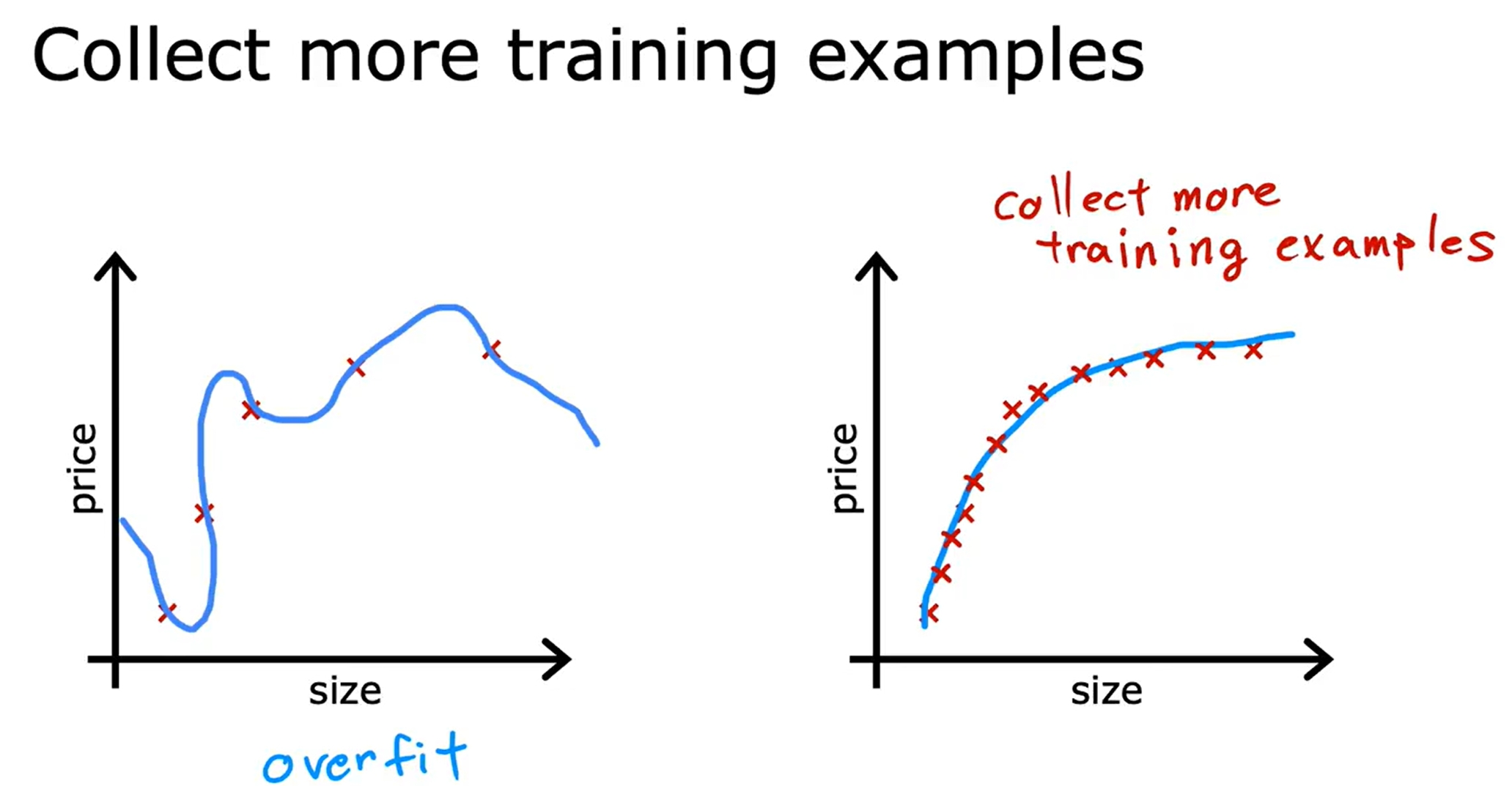
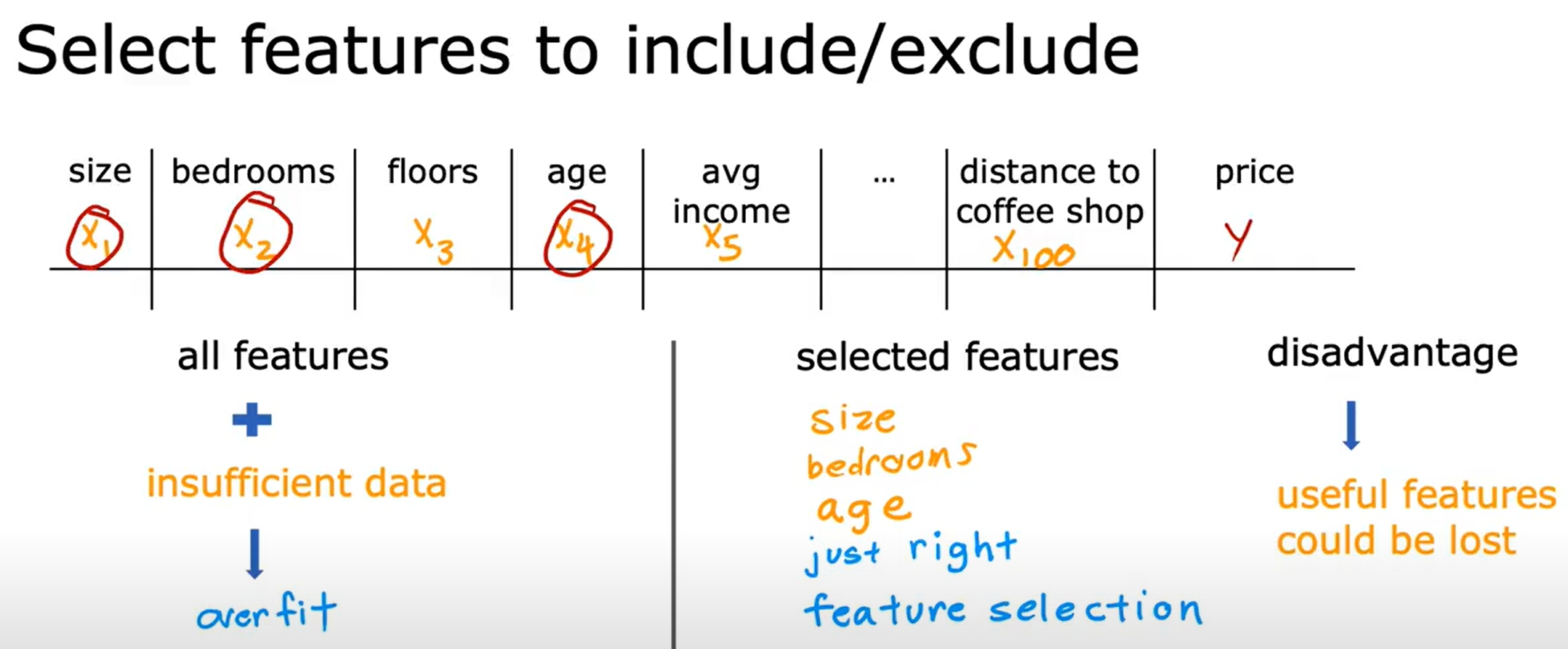
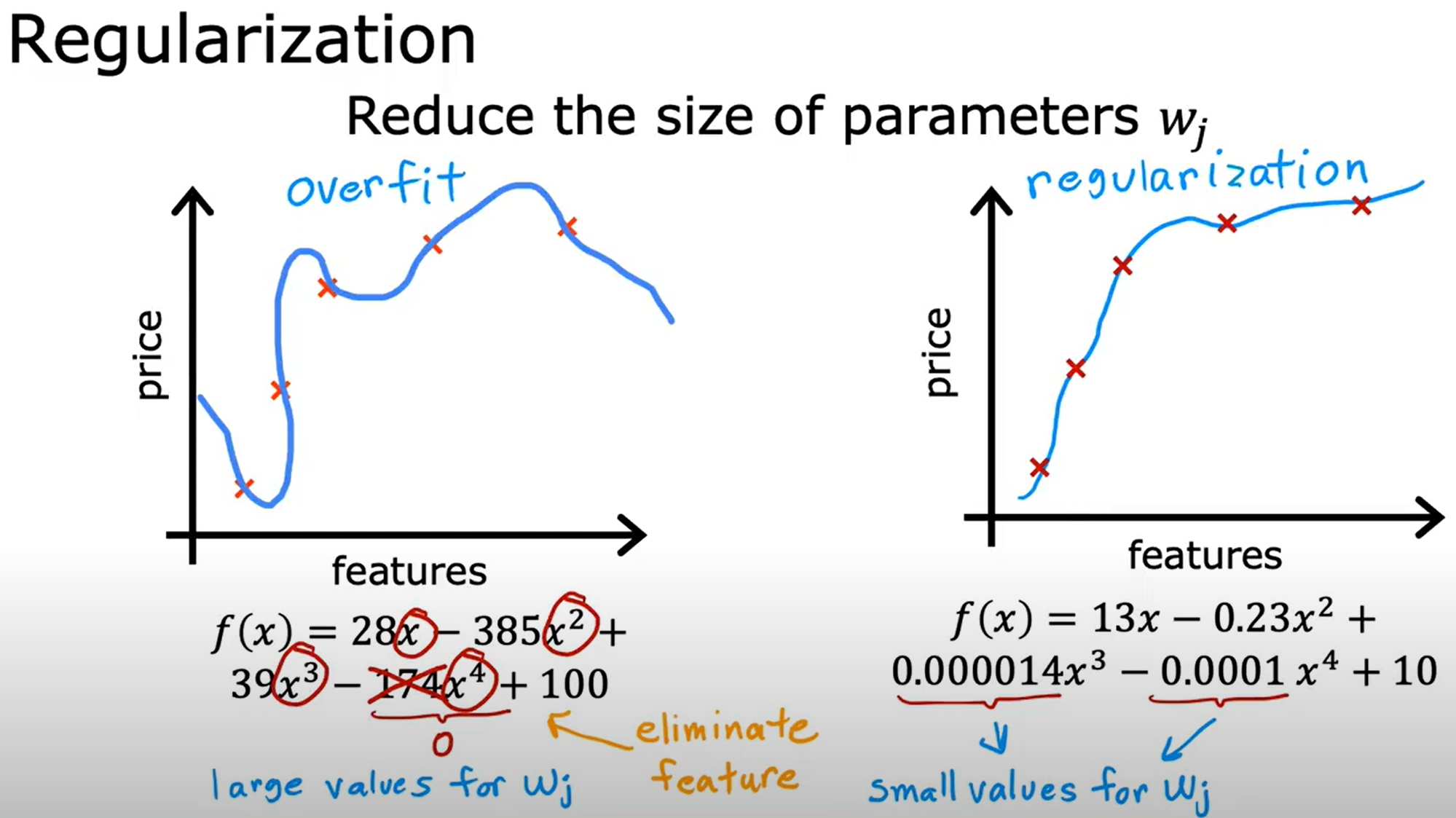
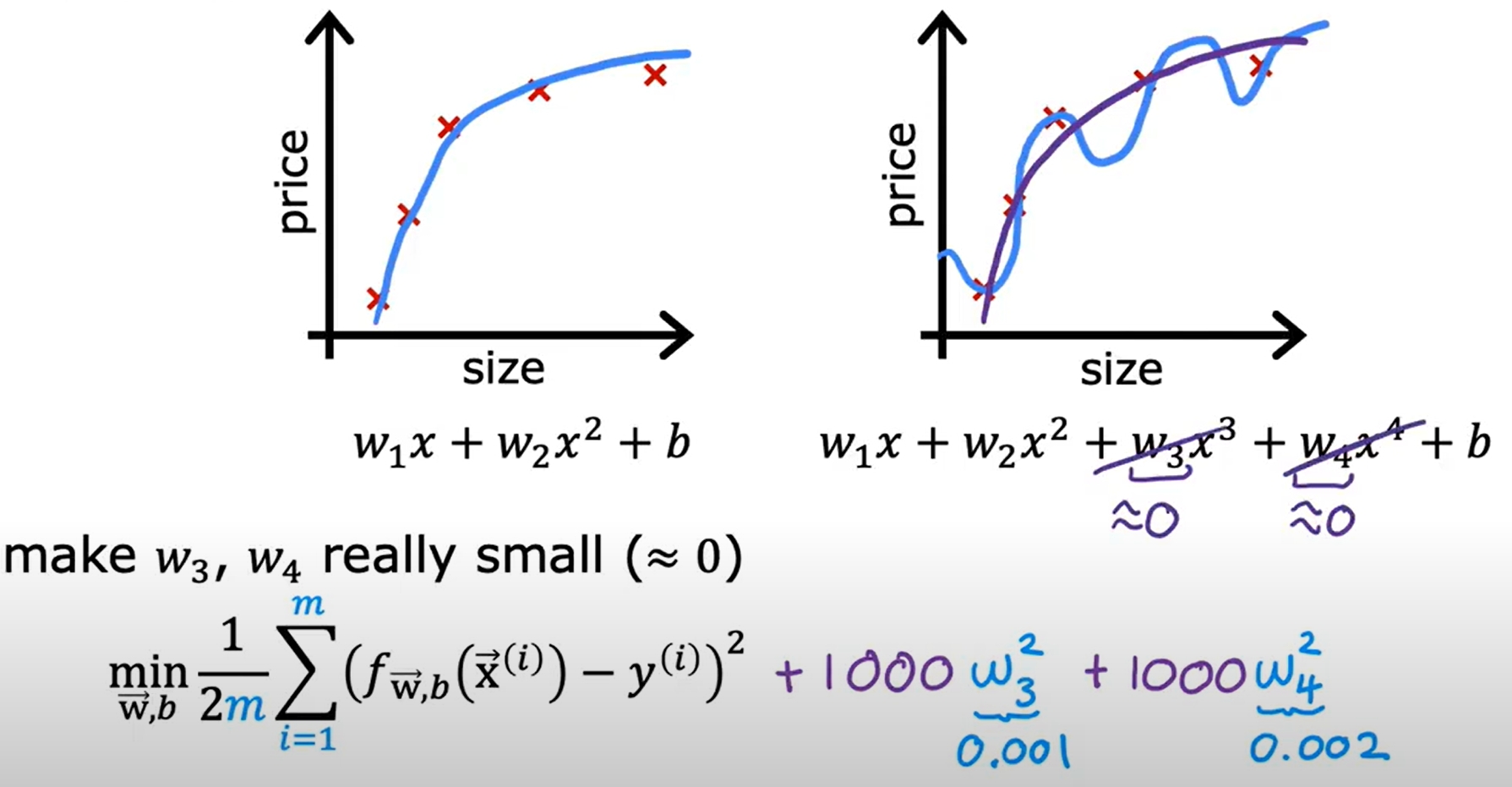

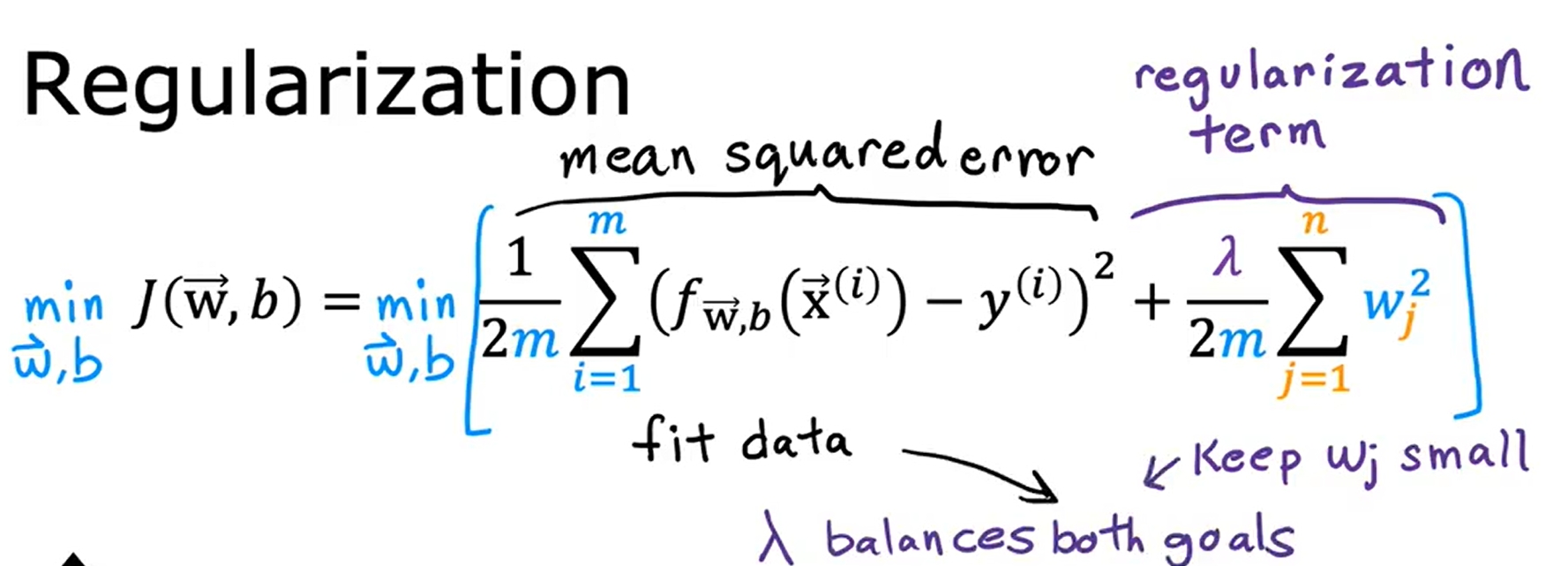
而正则化参数则是平衡拟合数据(overfit)以及减少权重(underfit)的作用。


Neural Network
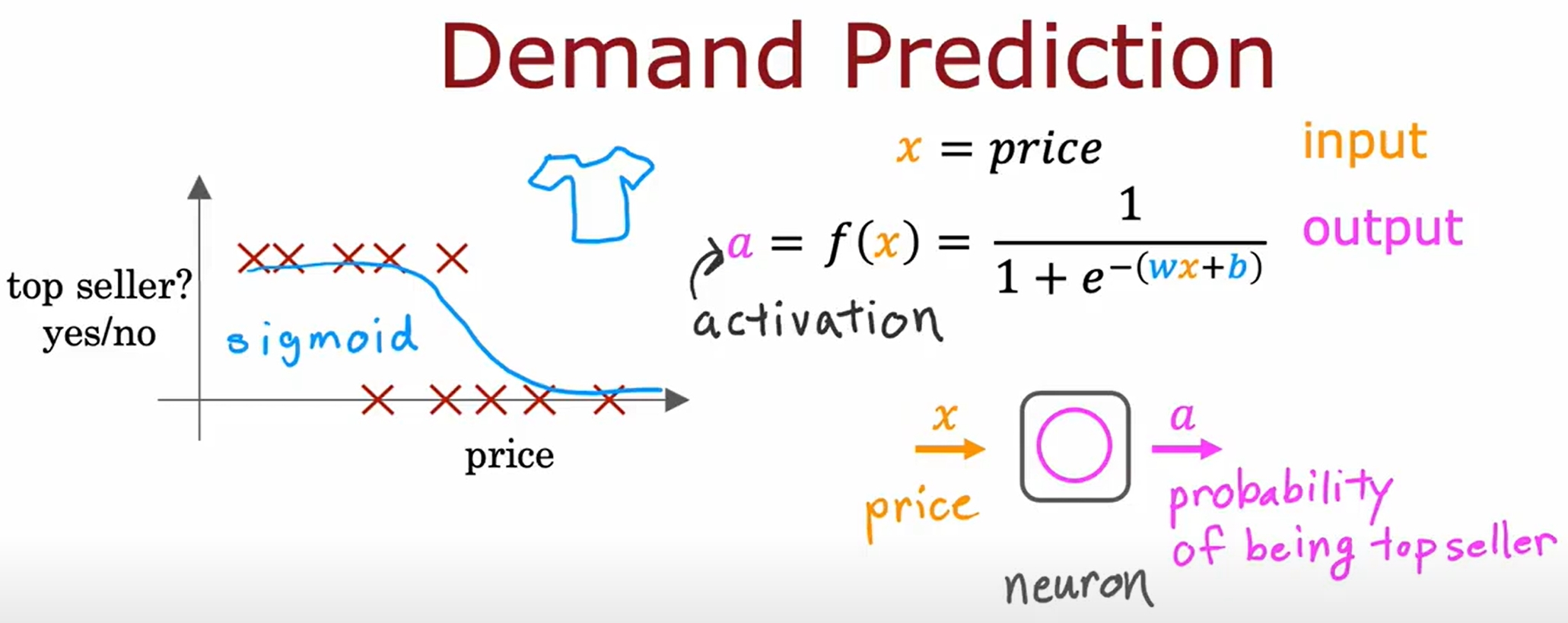
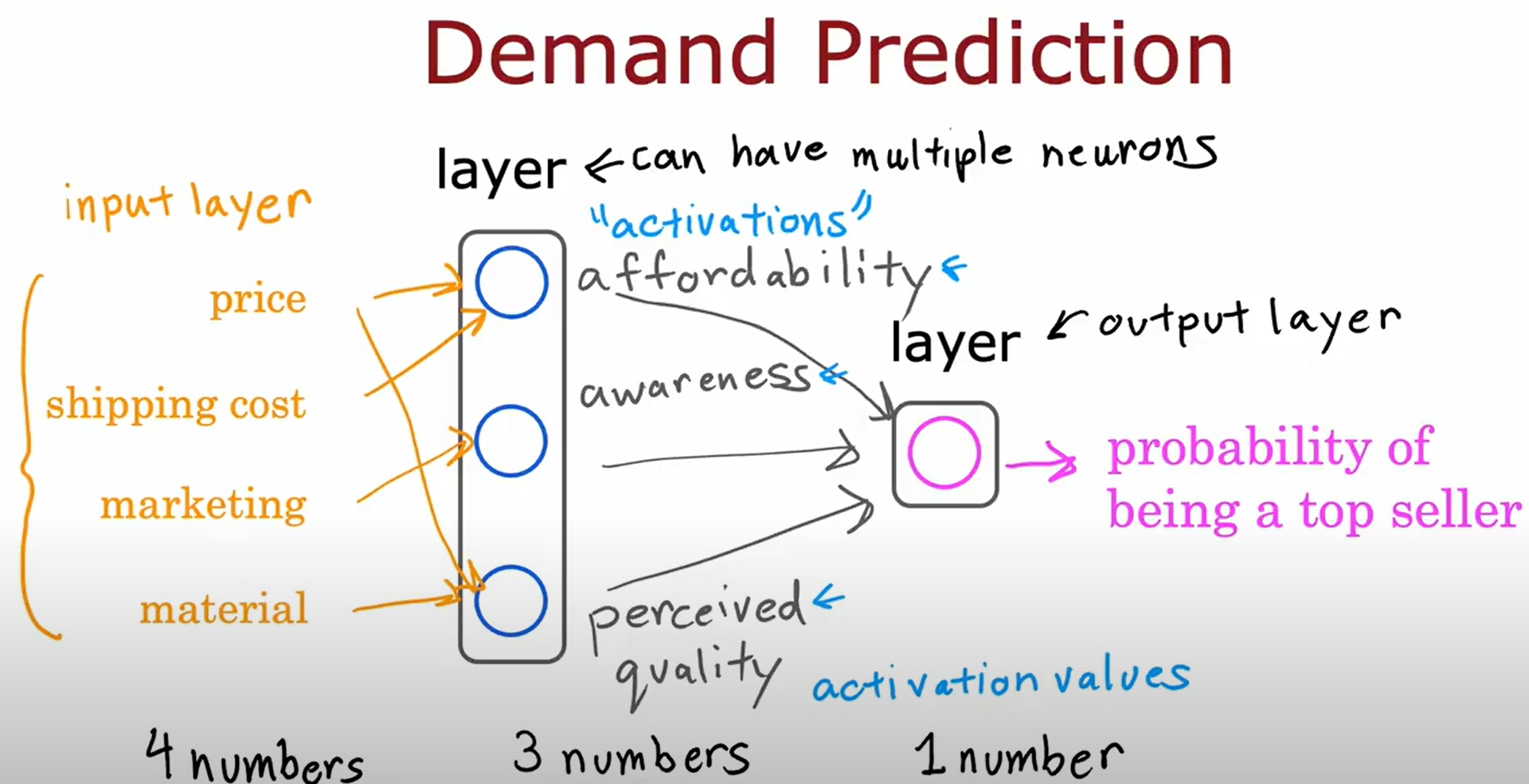
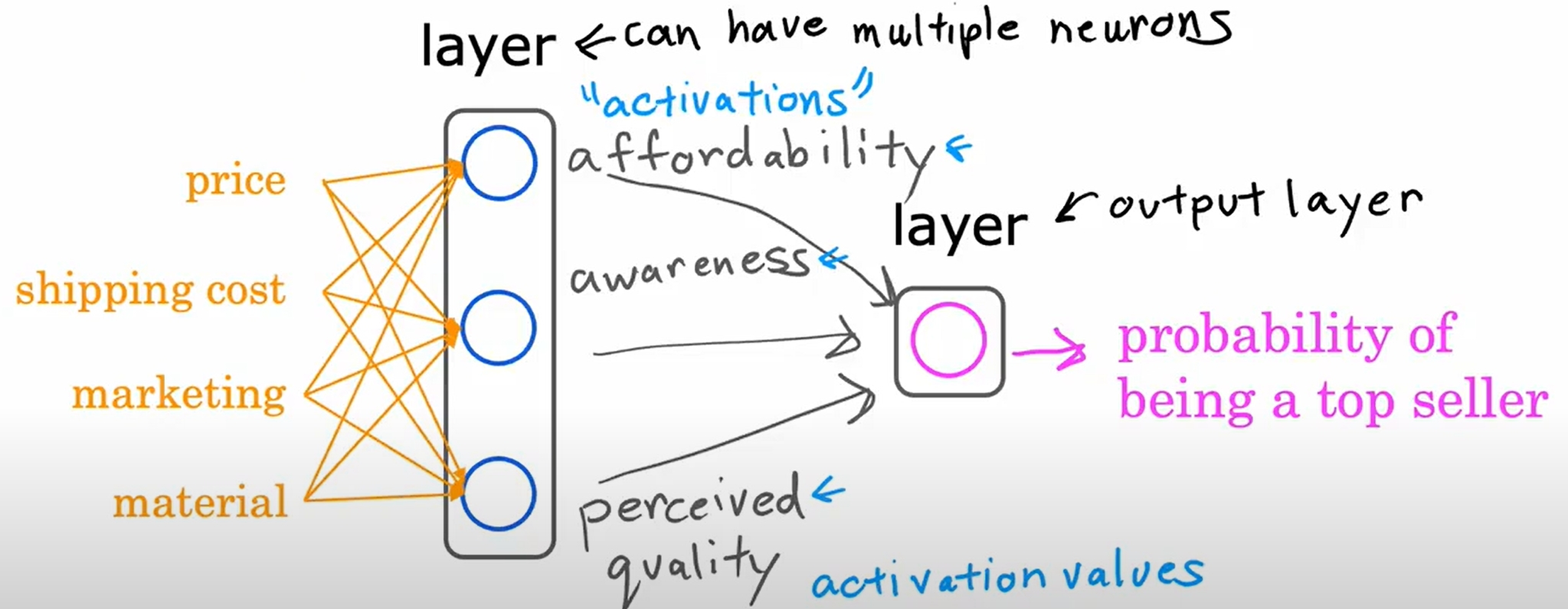
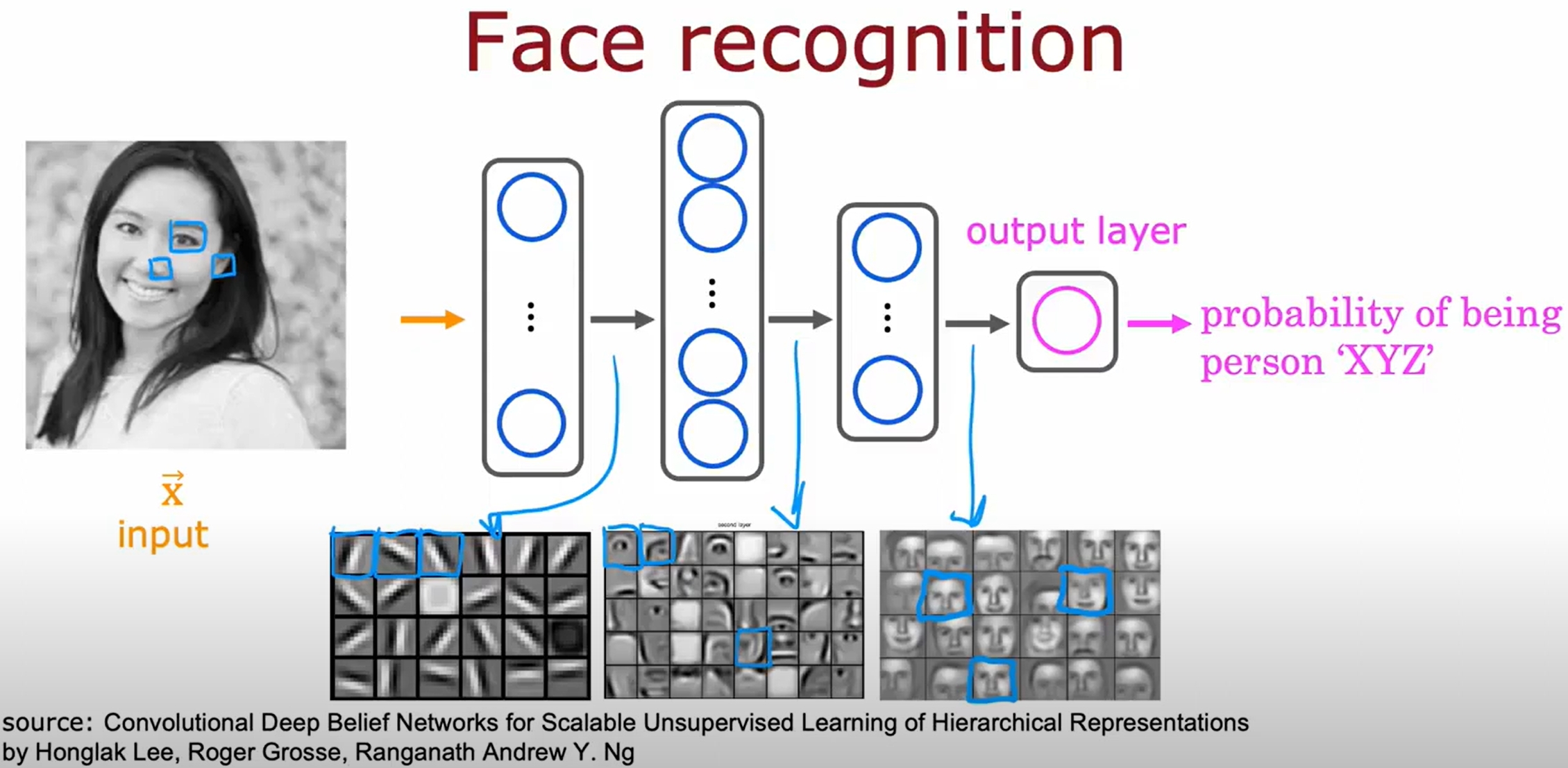
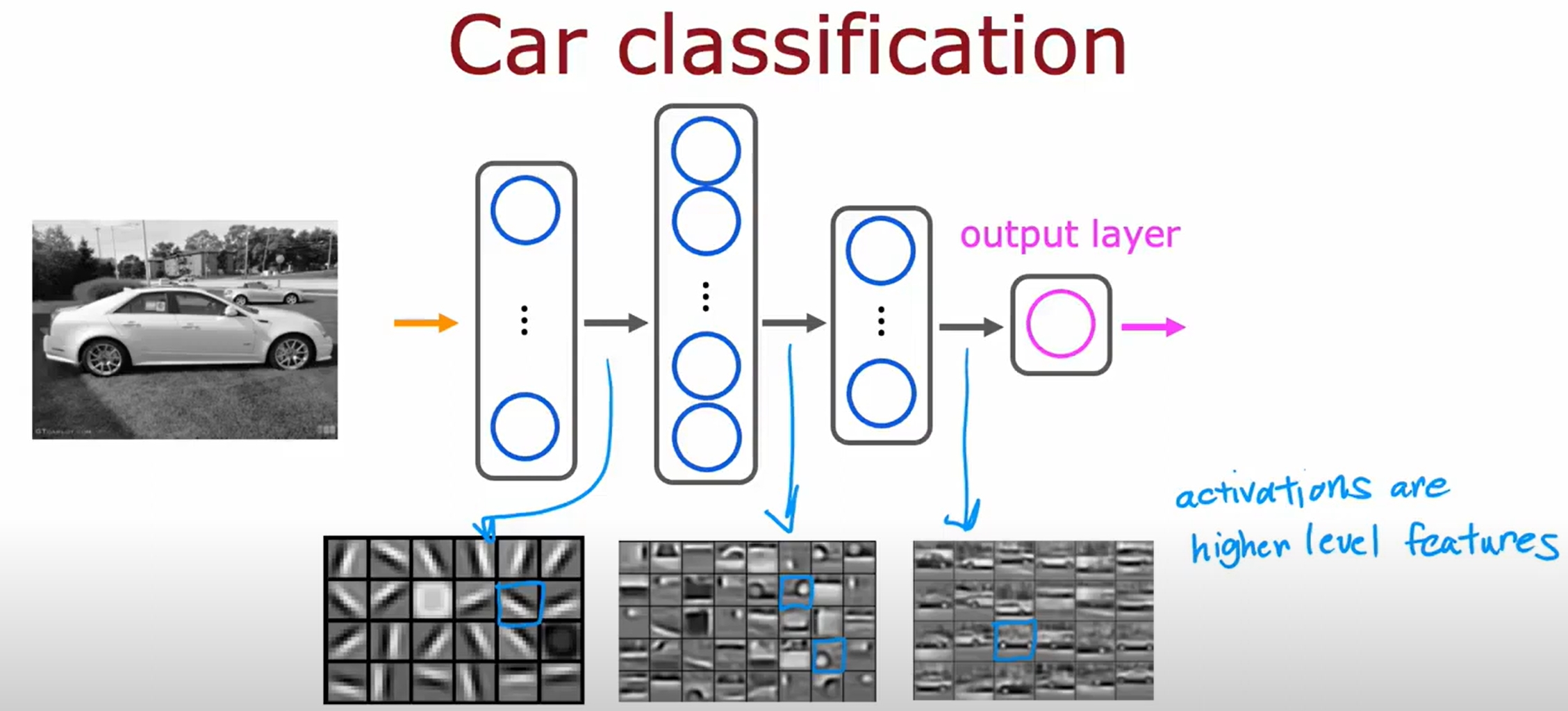
numpy与tensorflow的数据转换
numpy中表达矩阵:



基于tensorflow的神经网络代码实现
一个简单的基于numpy实现的神经网络代码如下:



基于python实现神经网络单层前向传播


向量化实现神经网络
首先是向量化代替循环,如下图所示:


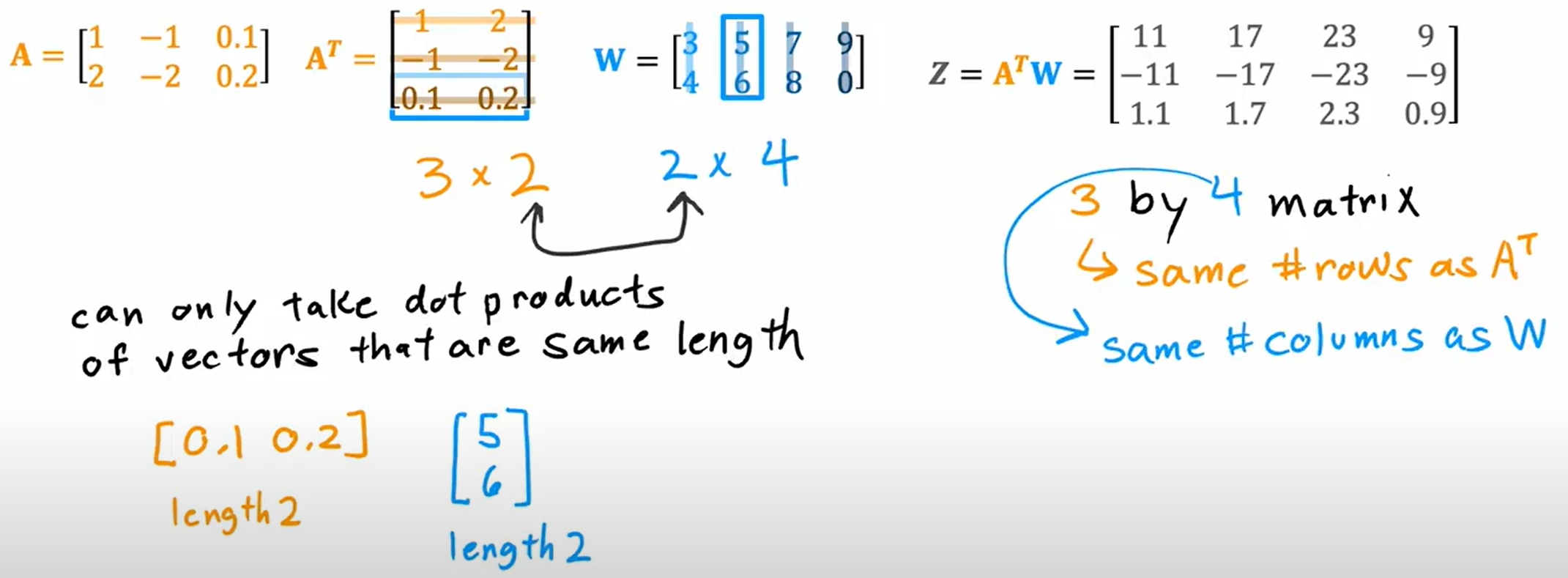

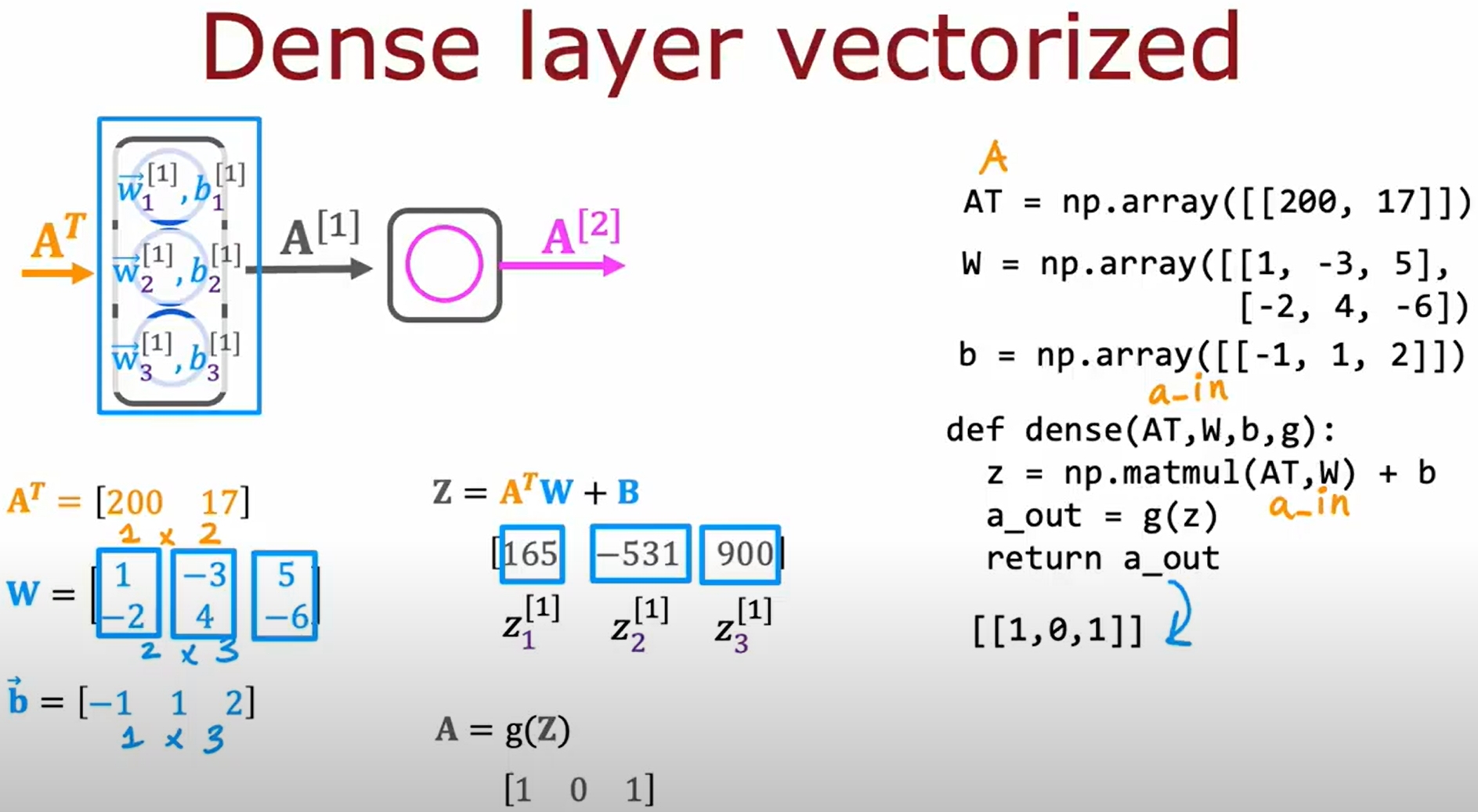
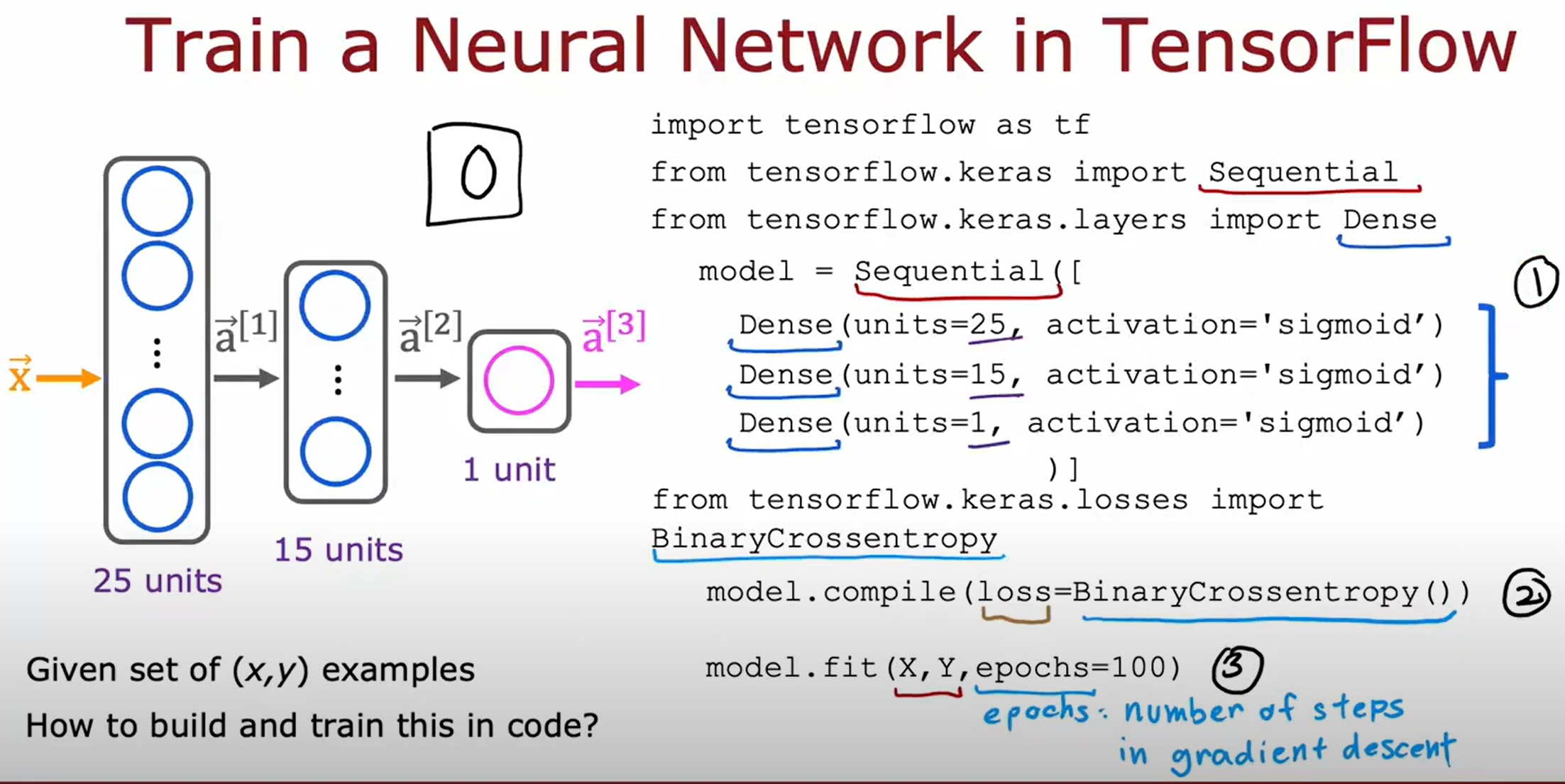
神经网络的训练
代码实现是非常直接的:



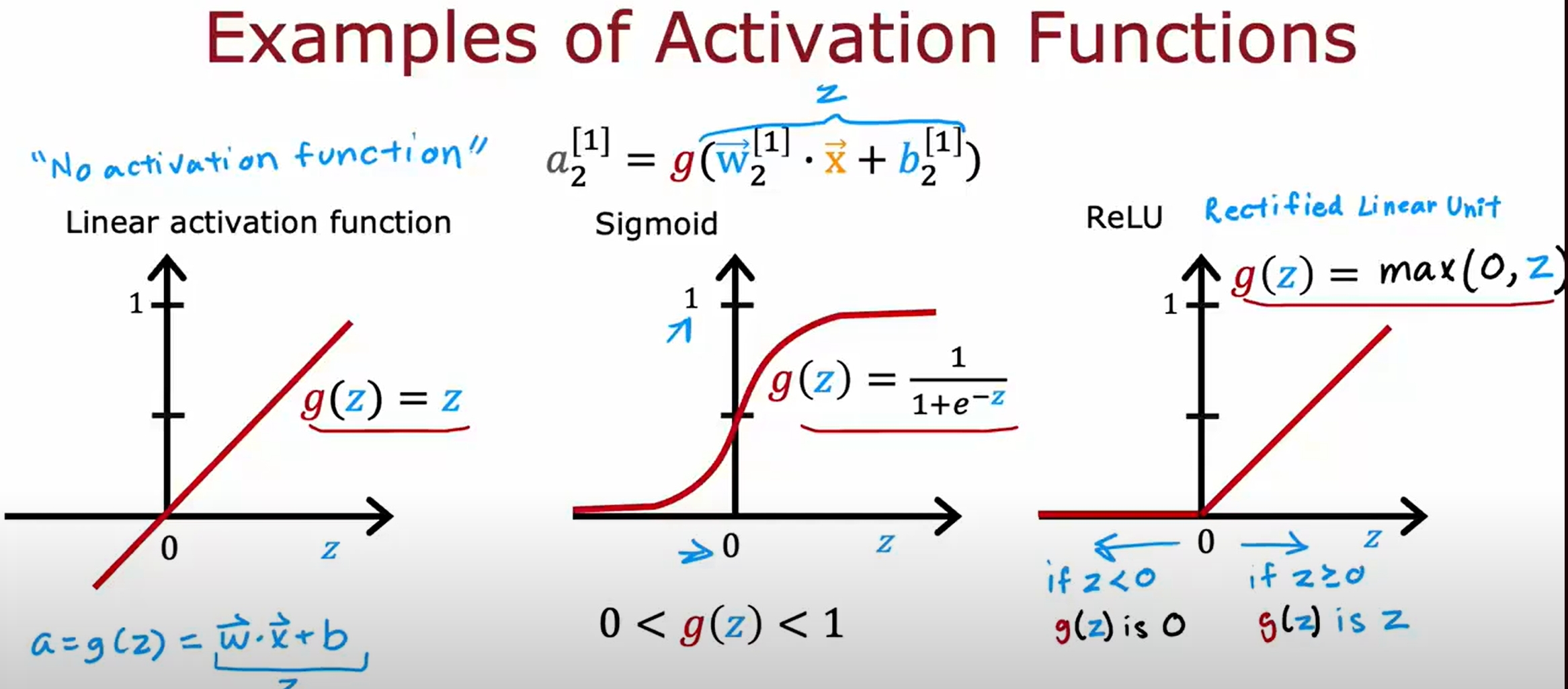
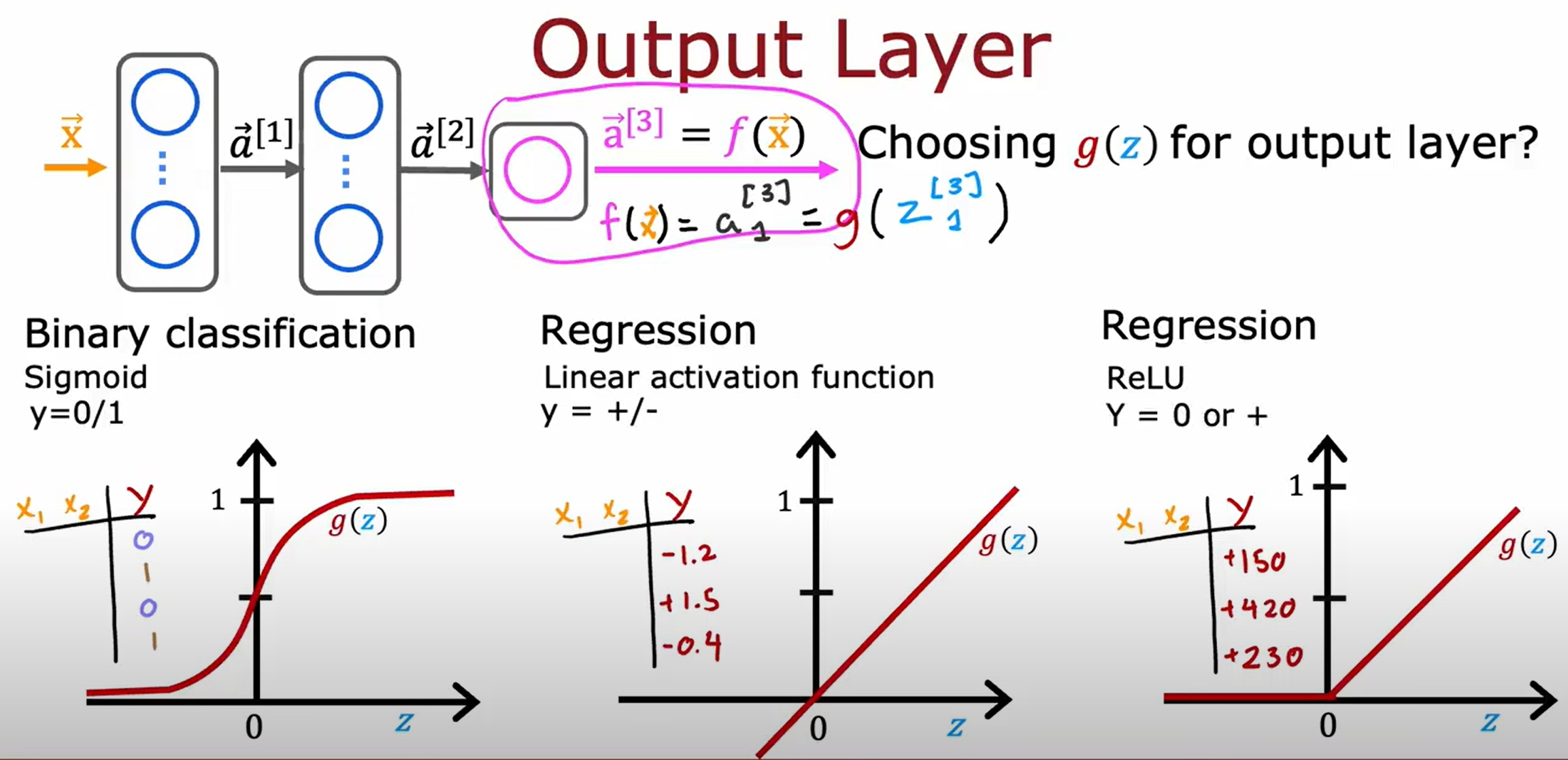
激活函数的选择
之所以要激活函数,是因为线性函数的叠加还是线性函数,而激活函数可以使得神经网络可以拟合非线性函数。(无激活函数的神经网络本质上就相当于线性回归了)
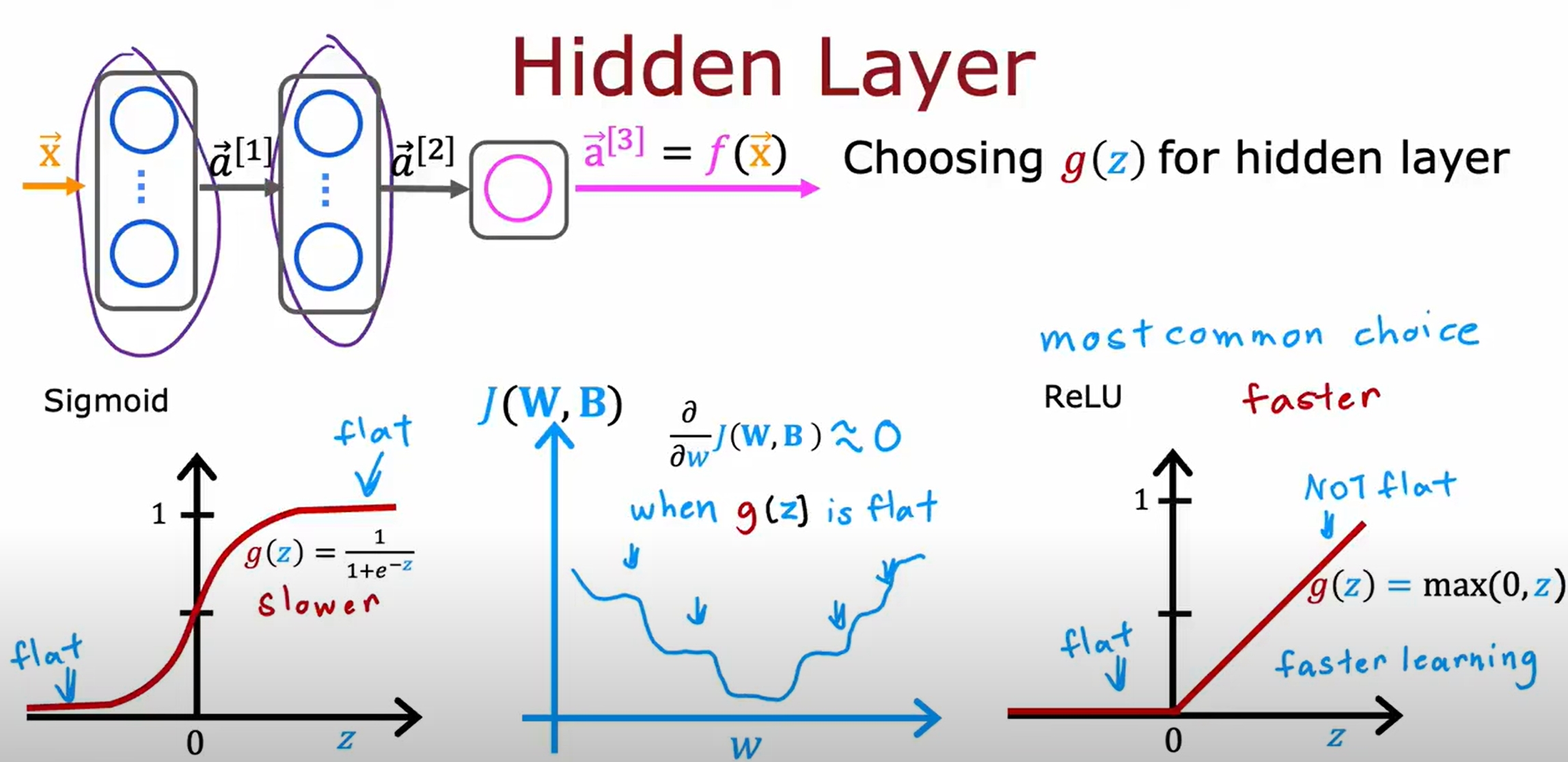
Sigmoid VS ReLU:

基于NN的系列实验代码
实验测试代码请见:
Multiclass Classification
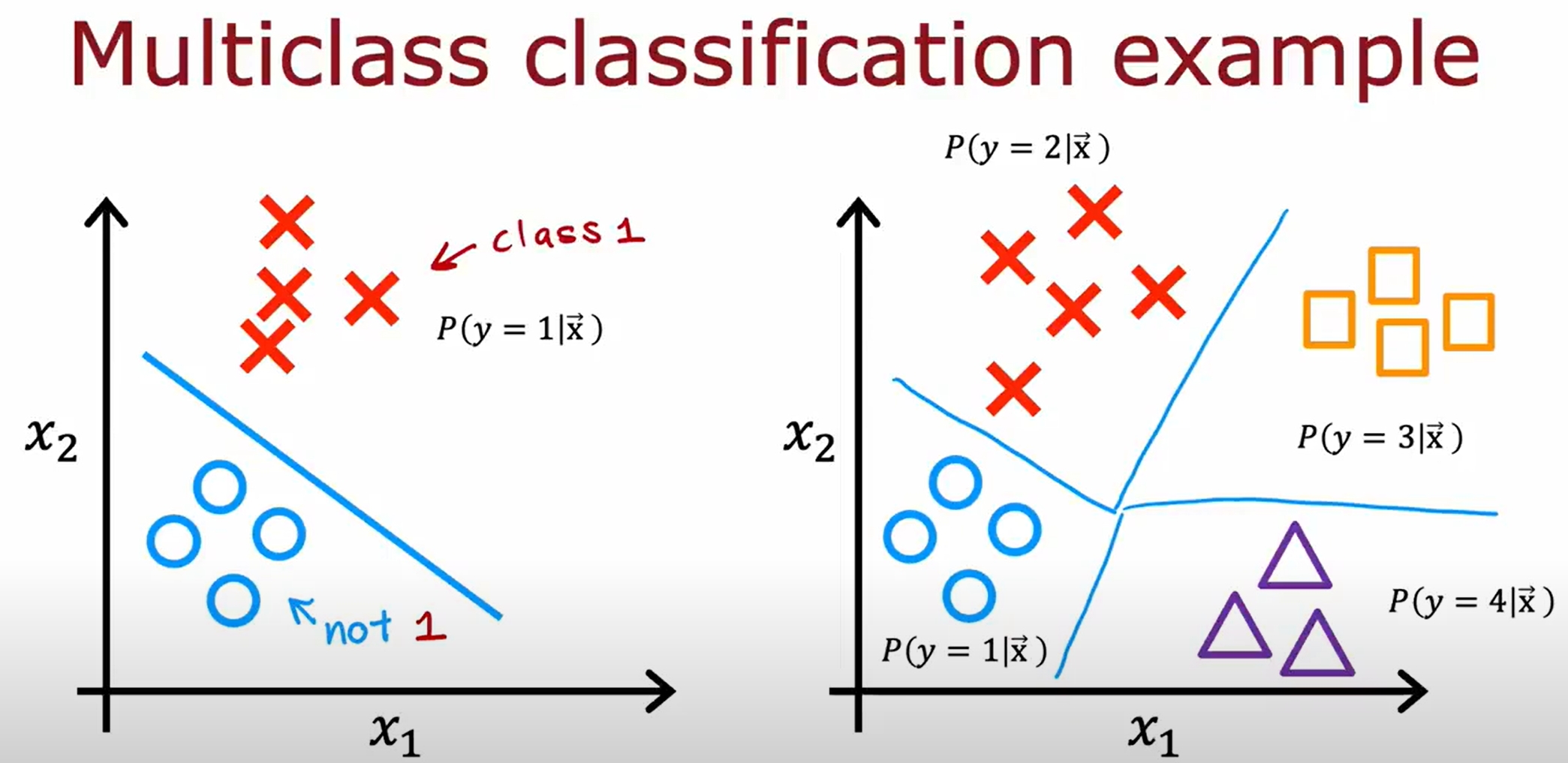
Softmax Regression

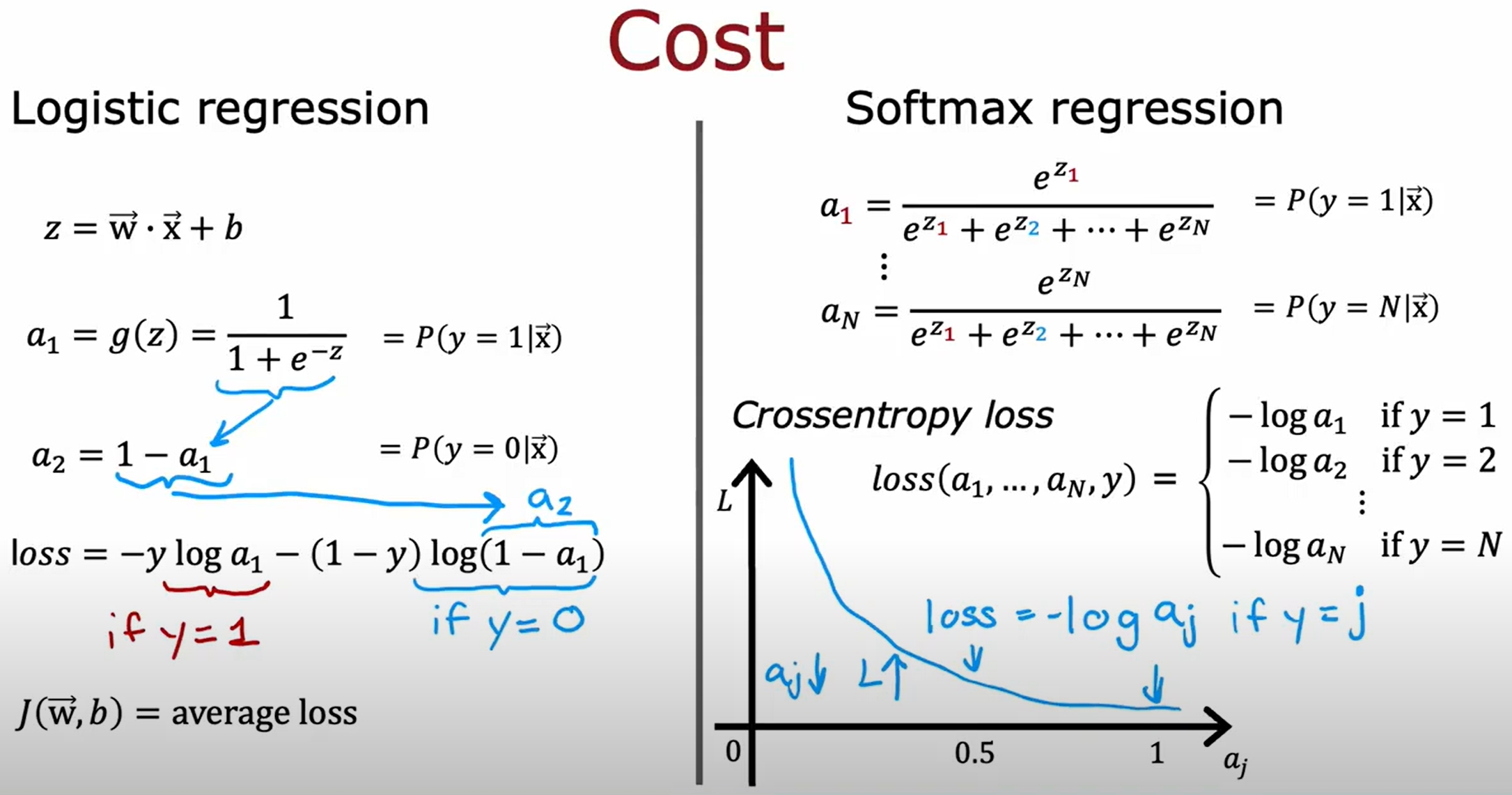
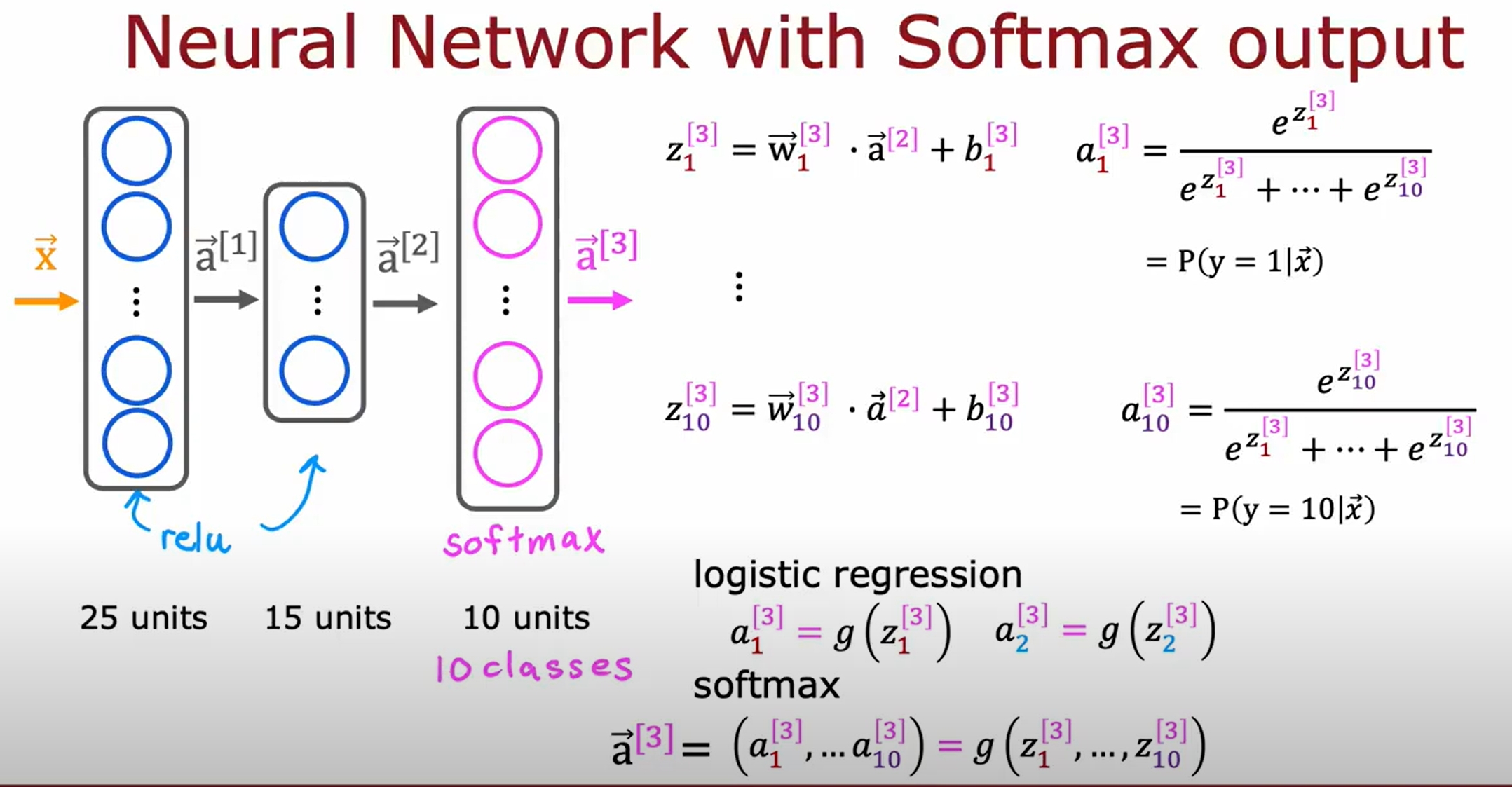
Neural Network with Softmax output
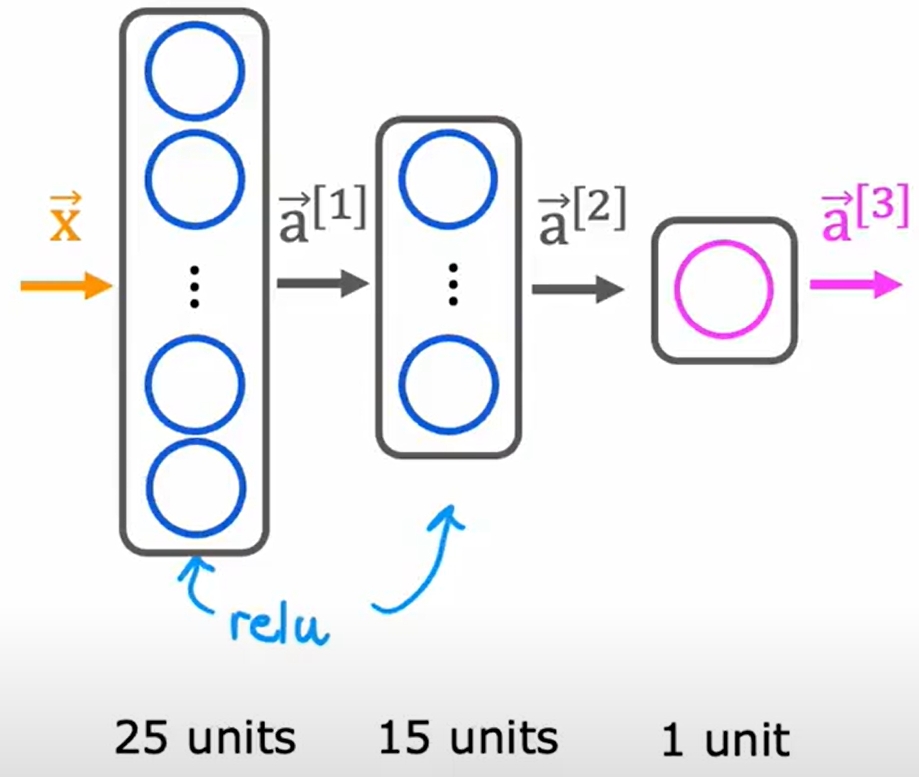
将Softmax Regression作为神经网络的输出层,如下图所示。进而可以实现多分类问题。




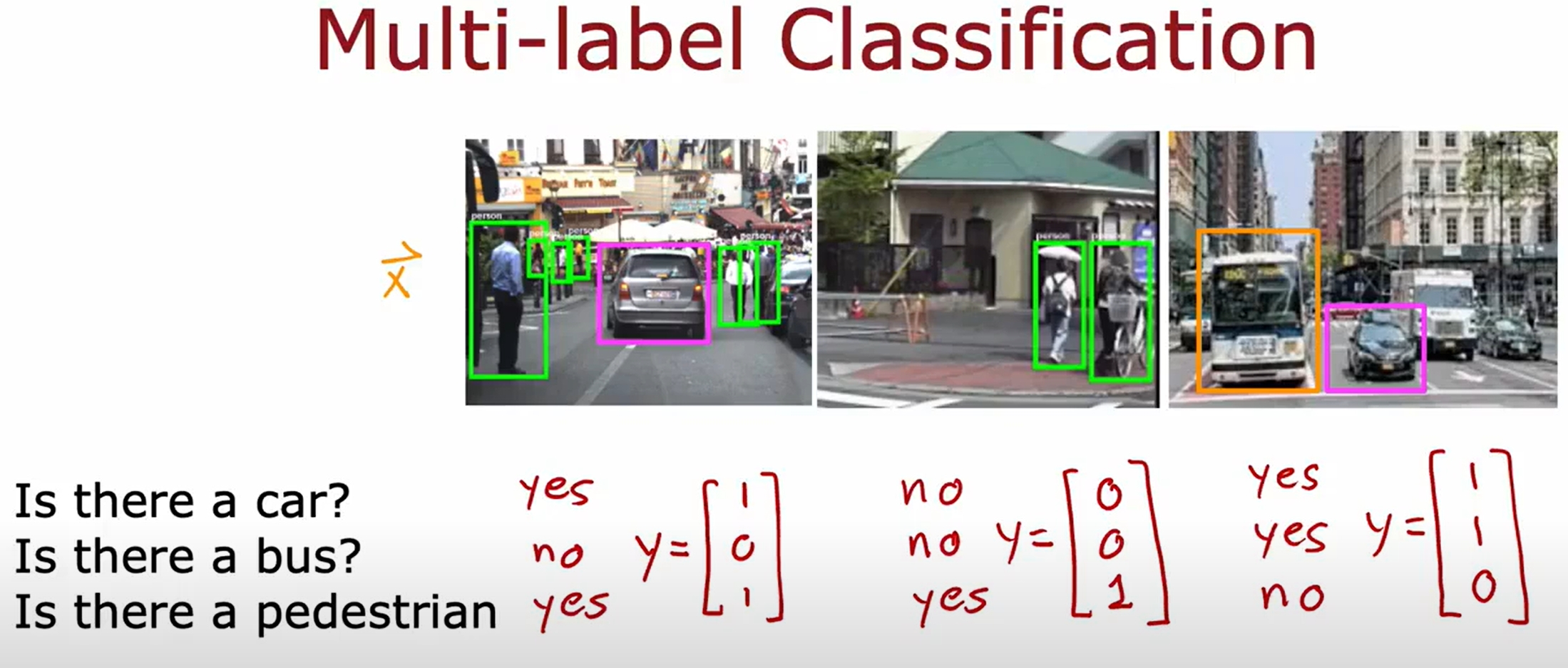
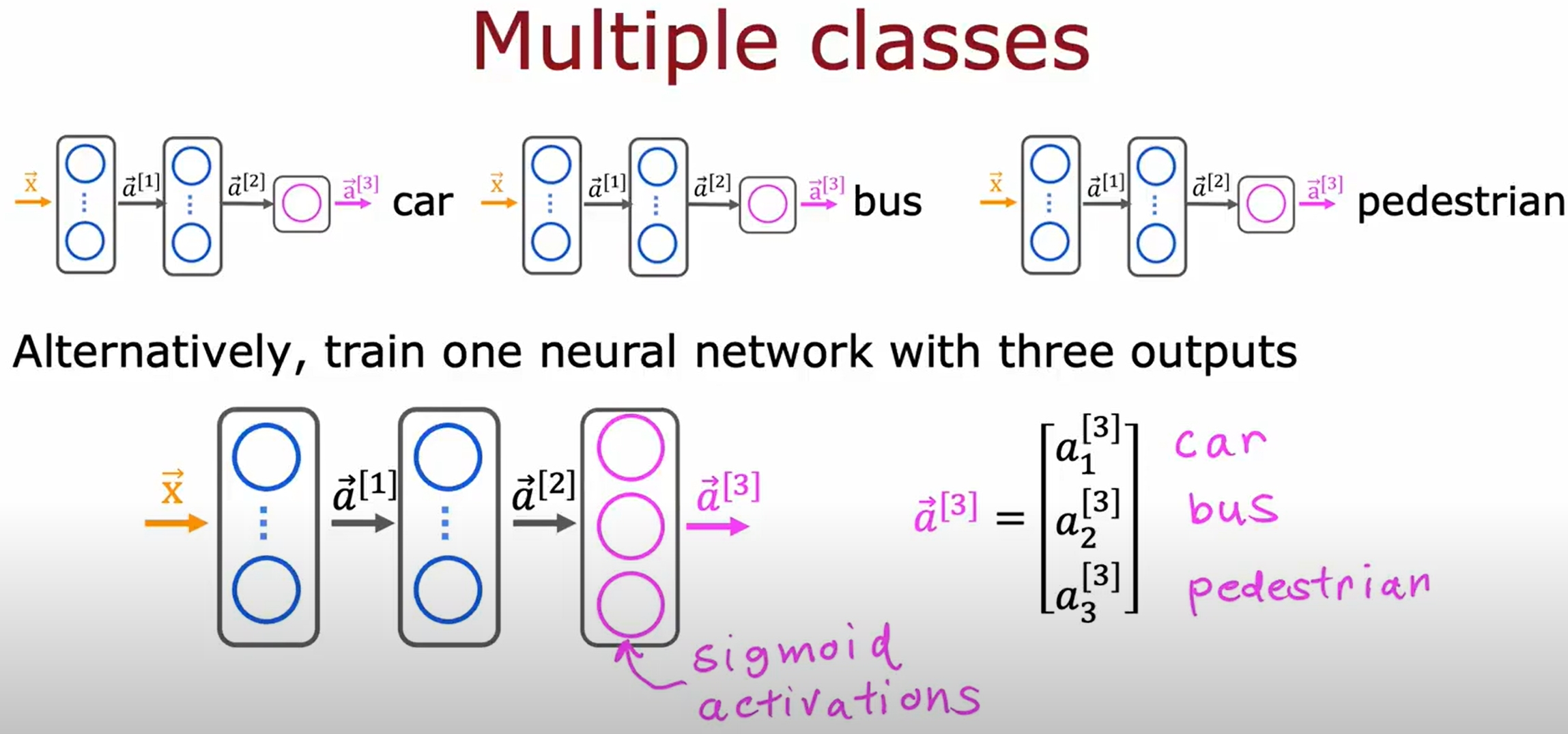
Multi-label Classification
此类问题应该指的是一个样本可以有多个标签,而不是多分类问题。如下所示,一张图片的输入对应多个label:
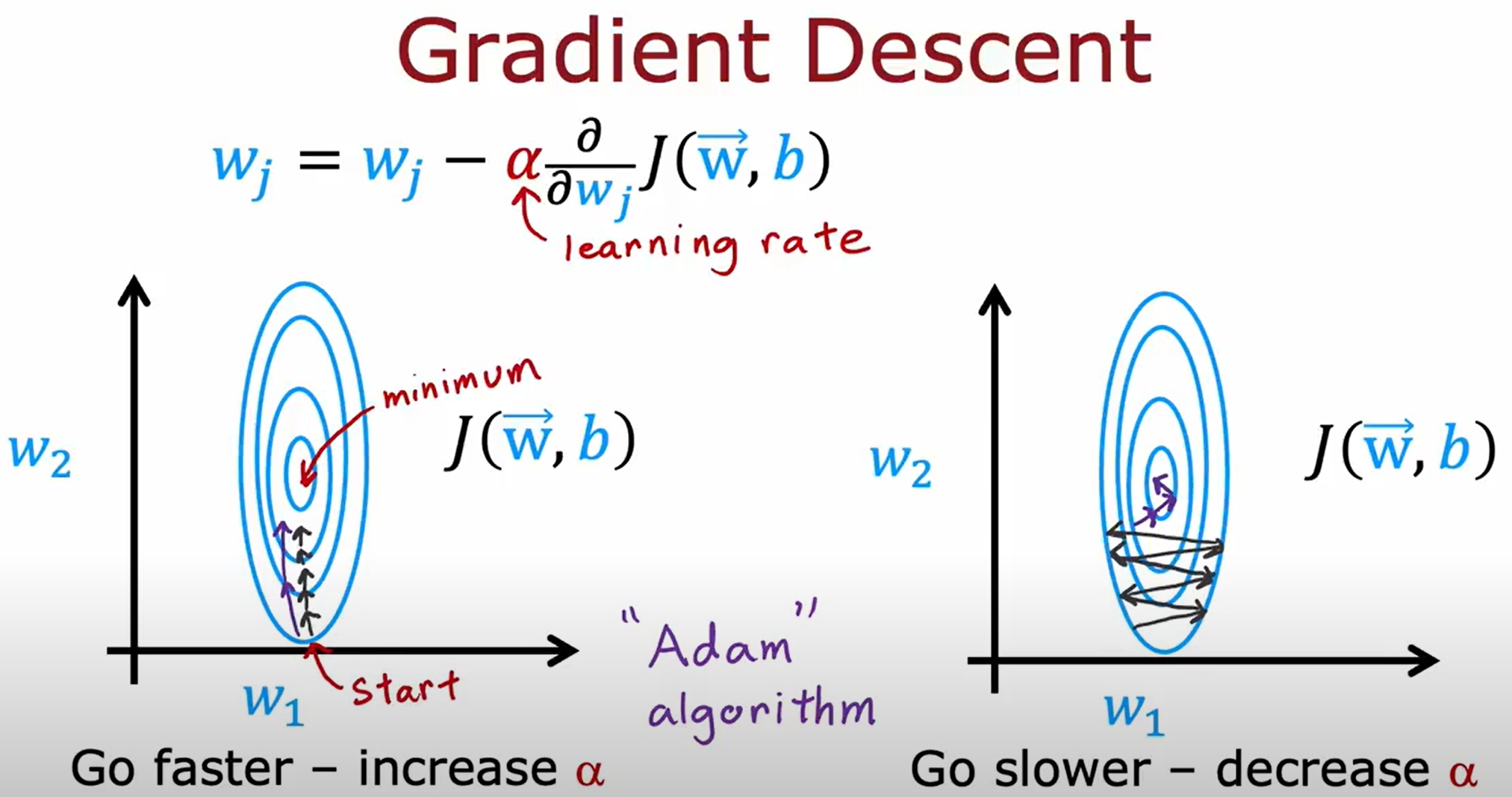
比梯度下降更好的优化方法(Adam Algorithm)
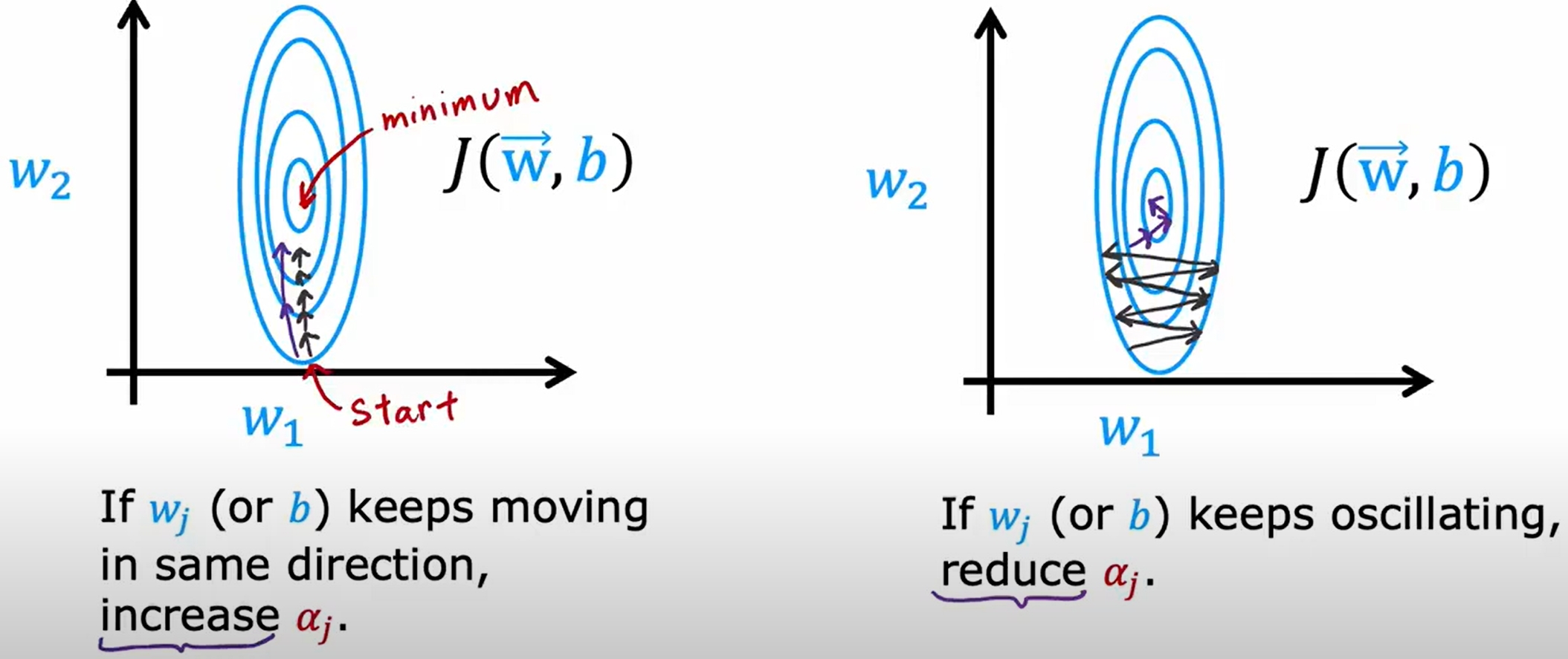
首先再次回忆一下基本的梯度下降法,而所谓的Adam Algorithm就是对梯度下降法的改进,就是自适应的调节学习率


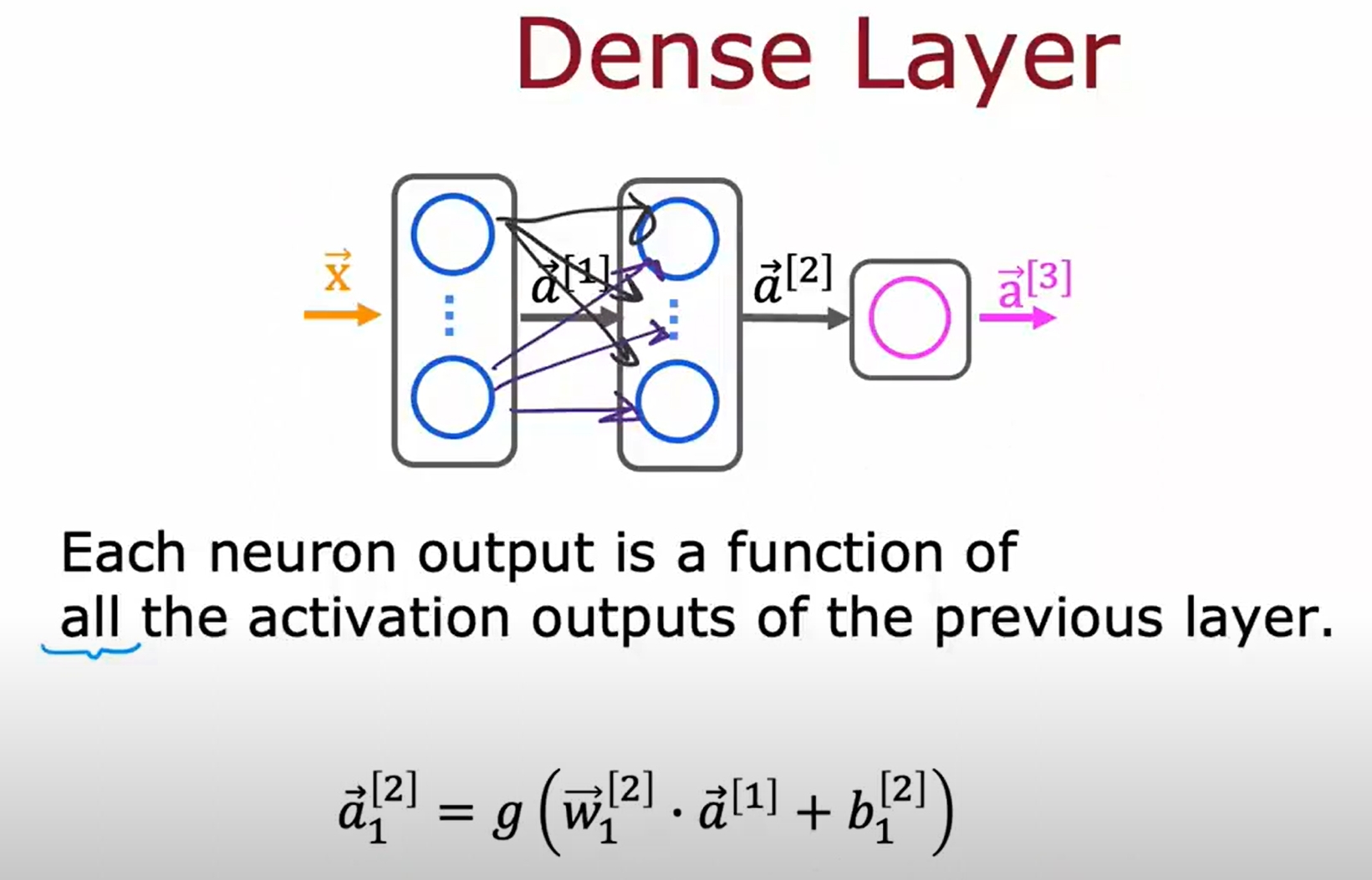
其他不同的网络层类型
之前介绍的一直都是dense layer:

基于NN实现手写数字识别(多分类问题)
Debugging a learning algorithm
对于一个算法,如果发现它的表现不好,那么可以采用的debug的方法有:

评估模型的方法
当模型存在过拟合的情况,如果是简单的函数,可以通过画图可视化,但是如果有多个输入的feature,很难通过图例来直观感受学习到的函数对数据的拟合情况





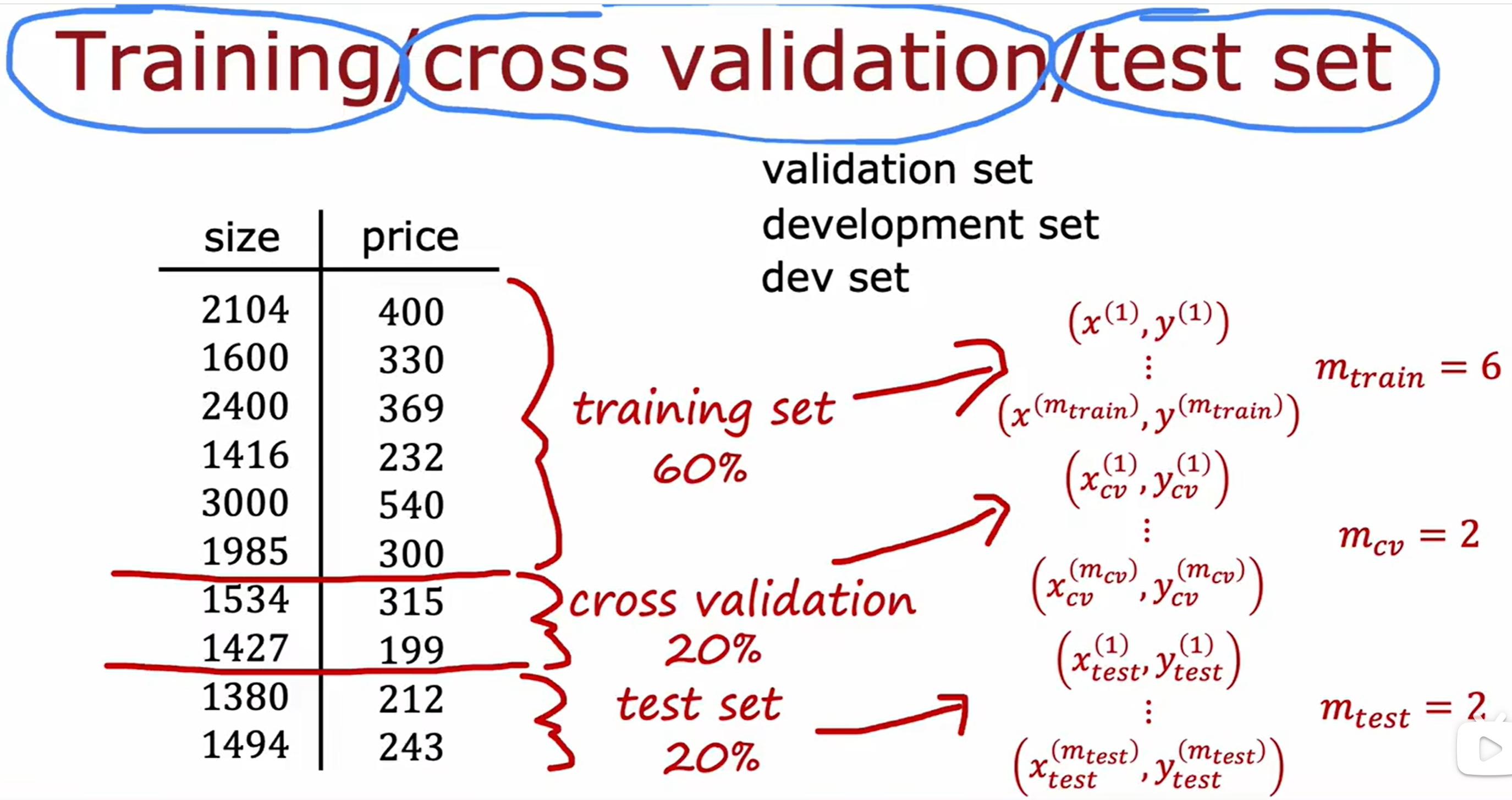
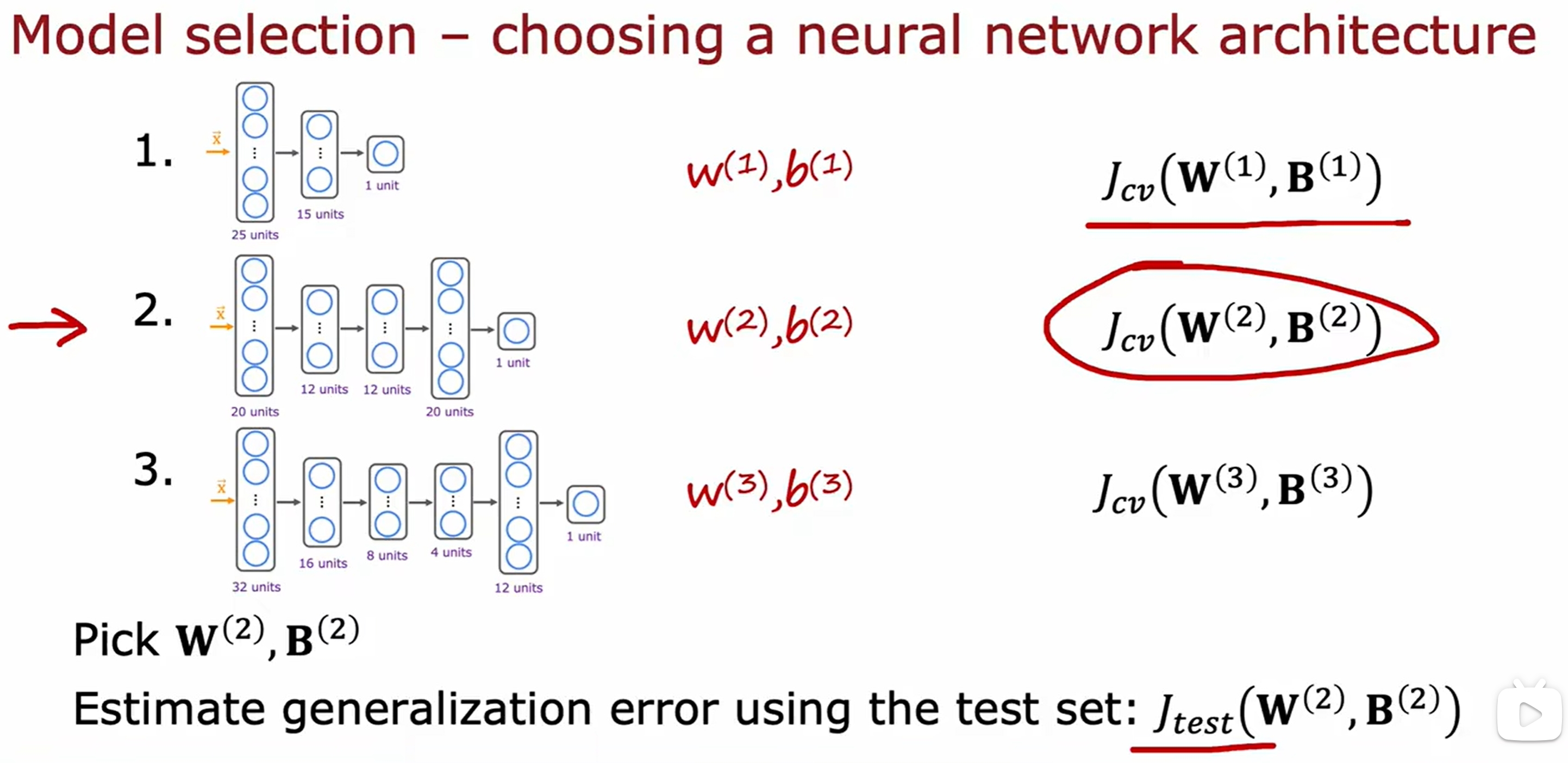
模型的选择以及交叉验证集(cross validation)
直接的方式就是穷举几个模型,然后选择最好的:



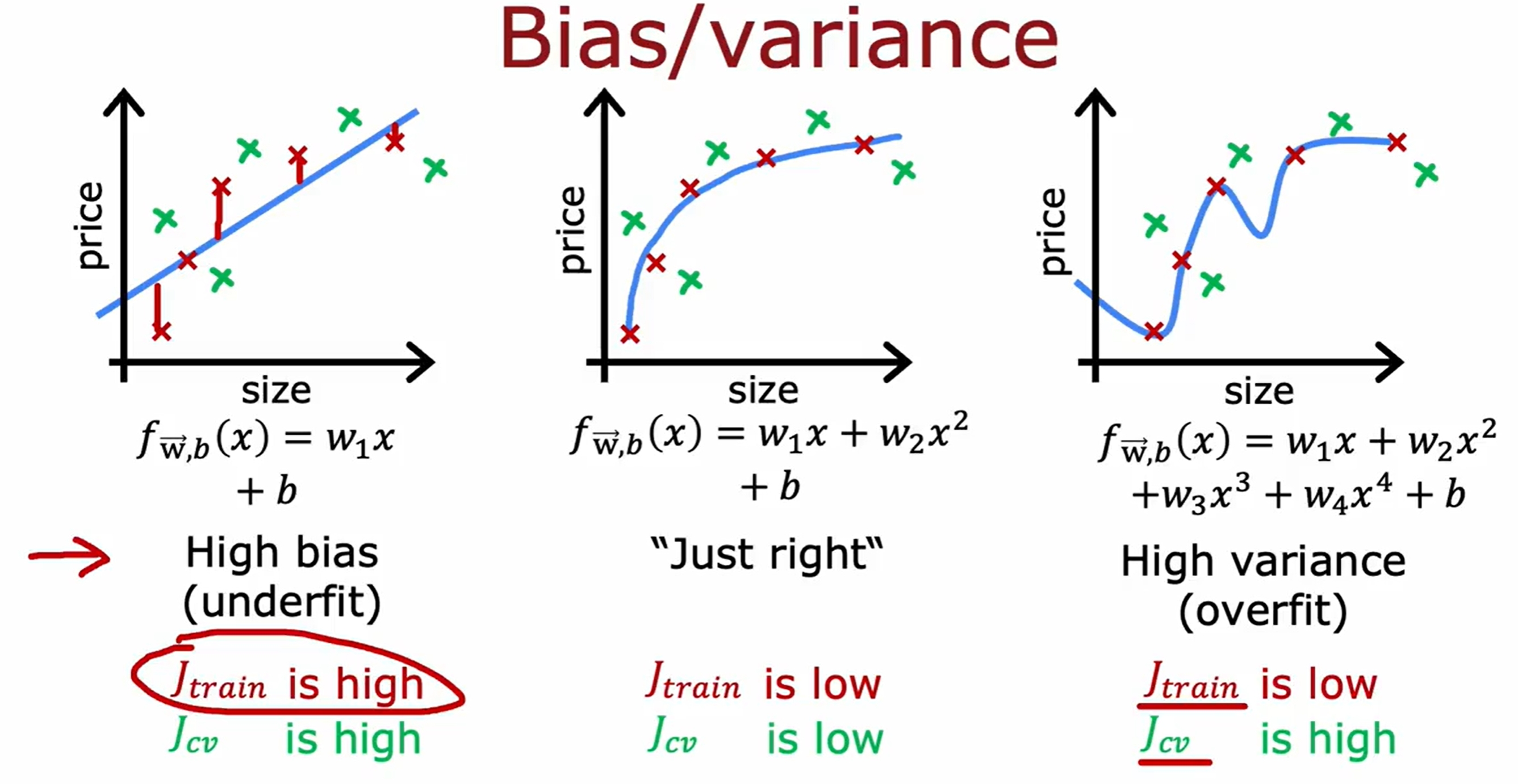
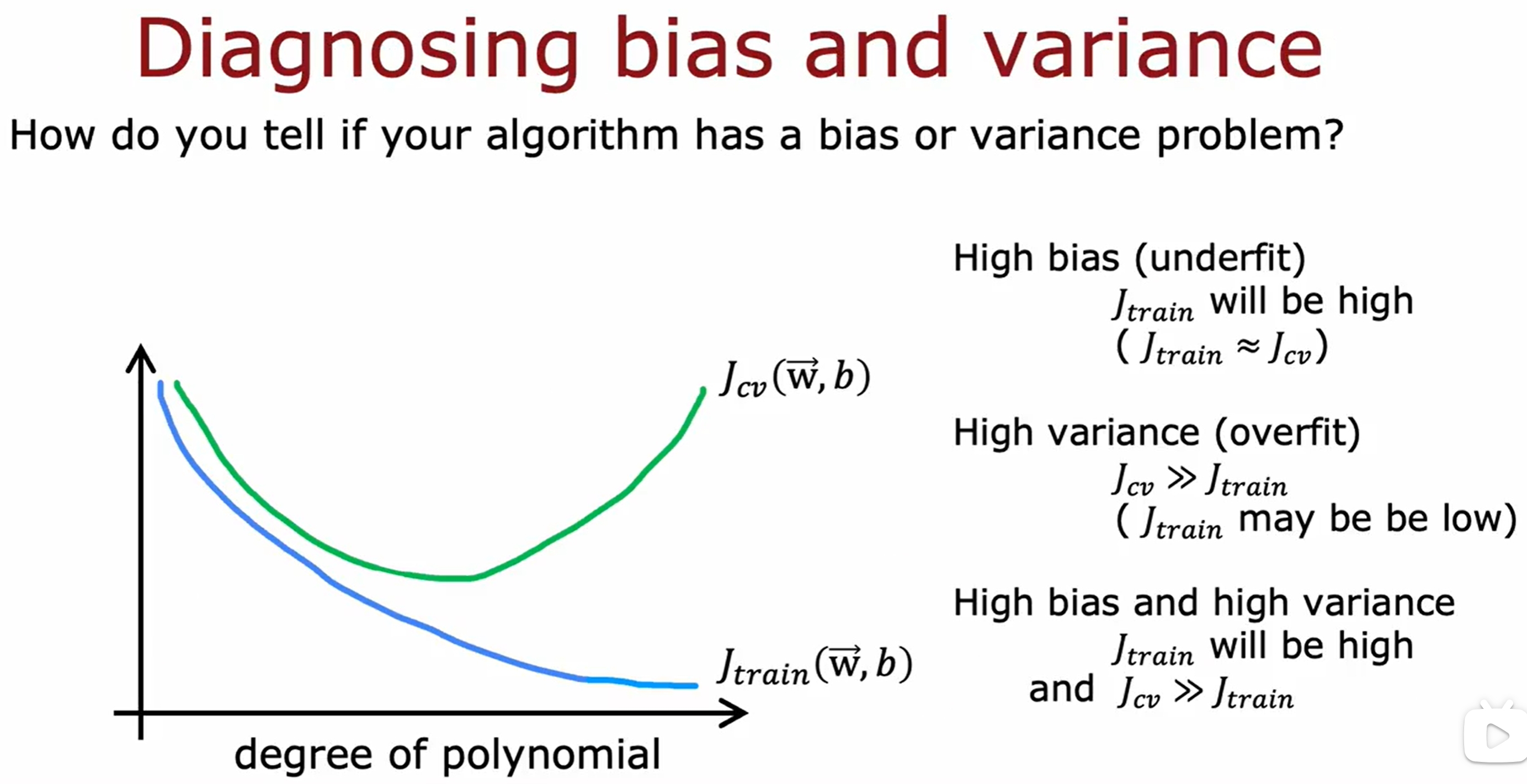
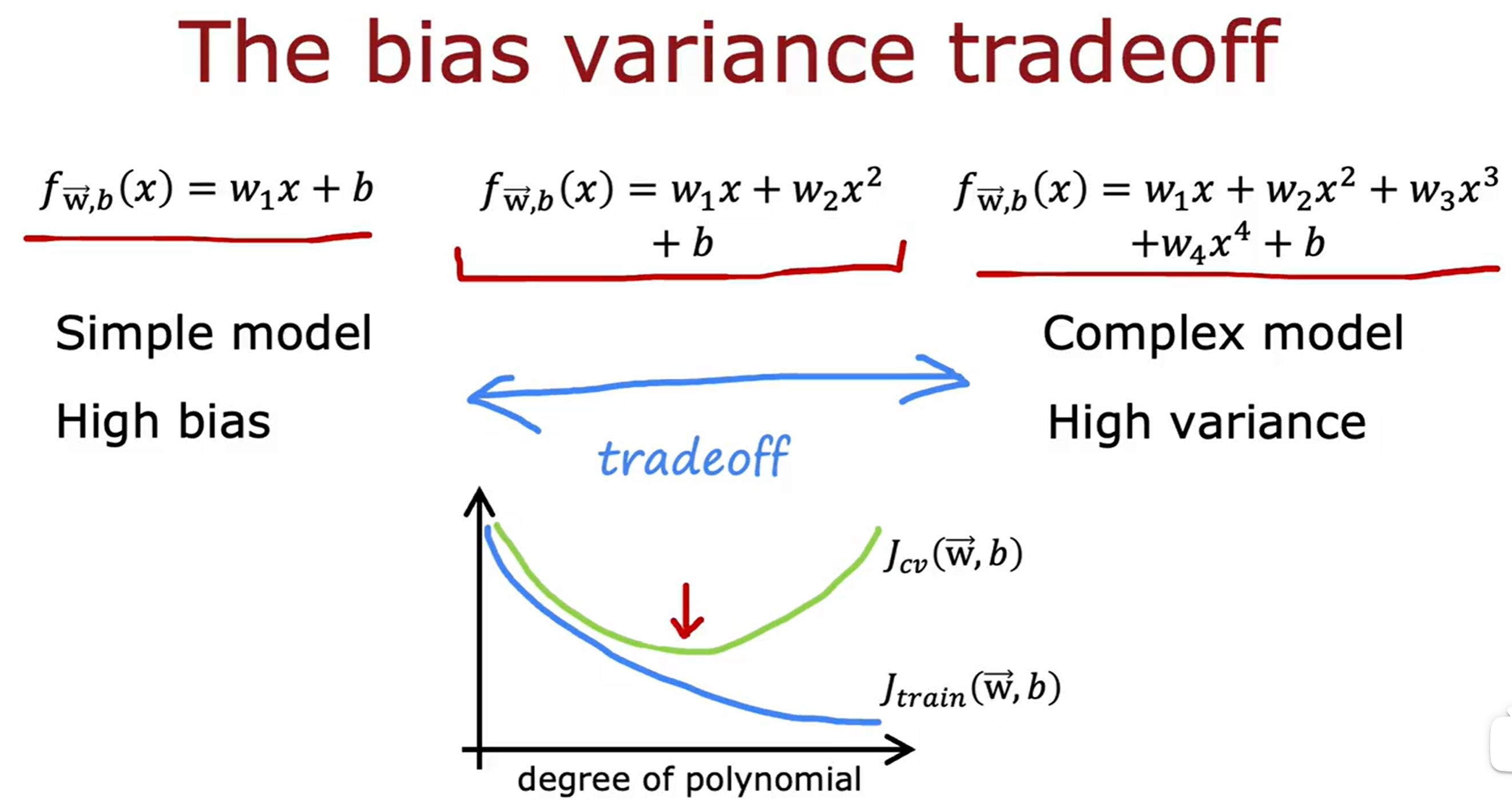
Bias and Variance
实际上感觉就是衡量是否过拟合和欠拟合的:
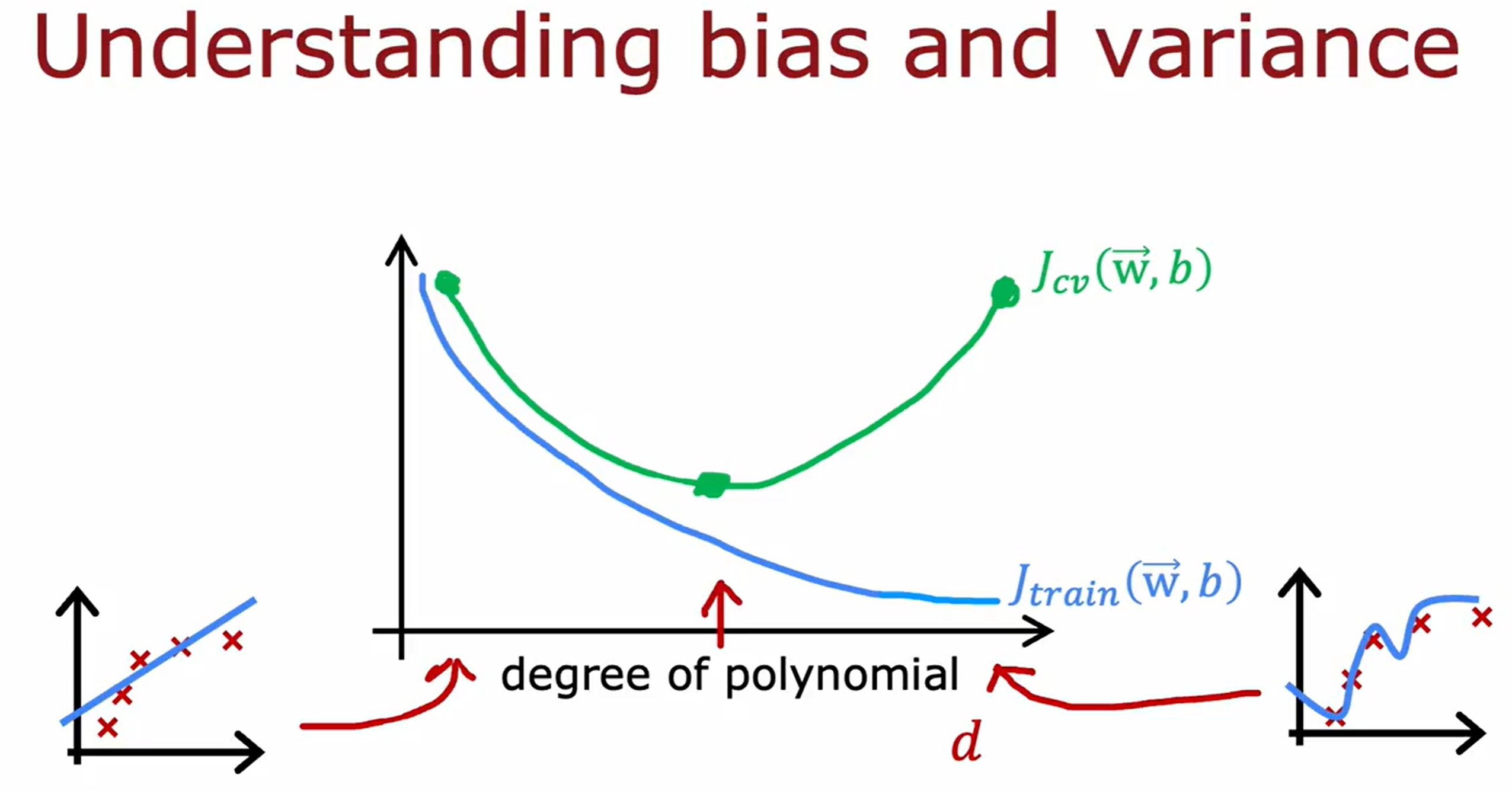

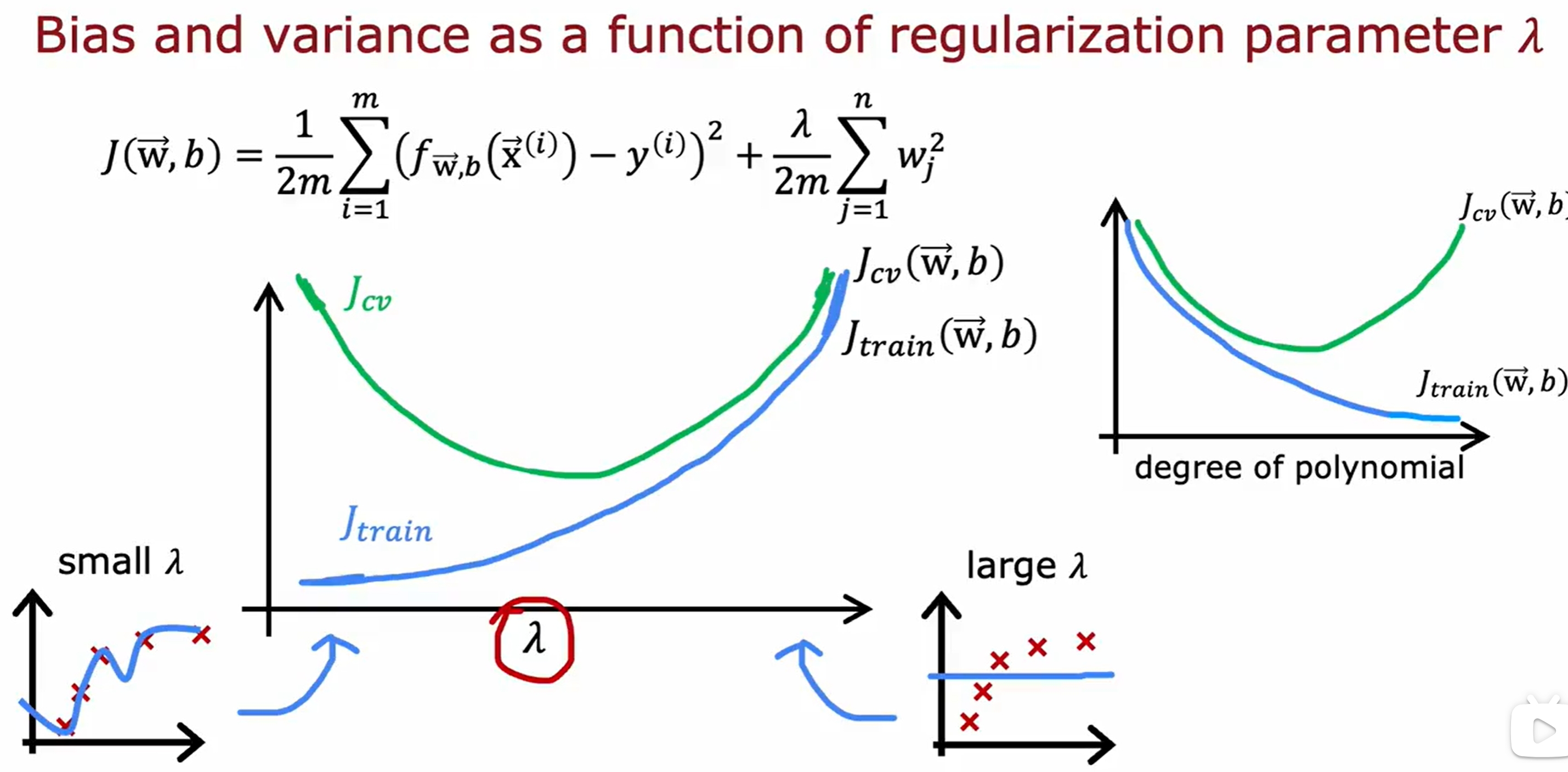
Learning Curves(学习曲线)
随着训练集的增加,训练集和交叉验证集的error的变化如下:
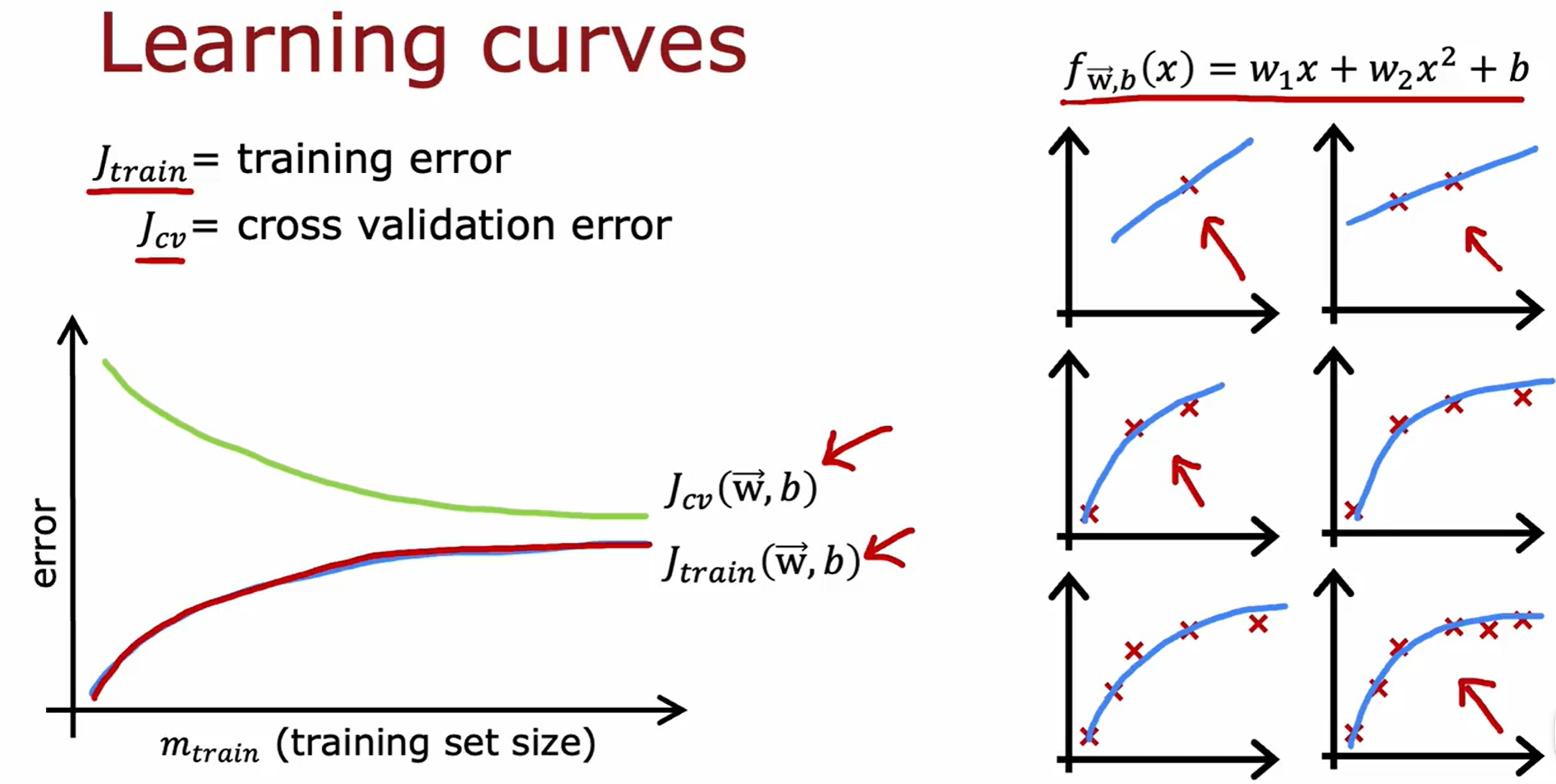
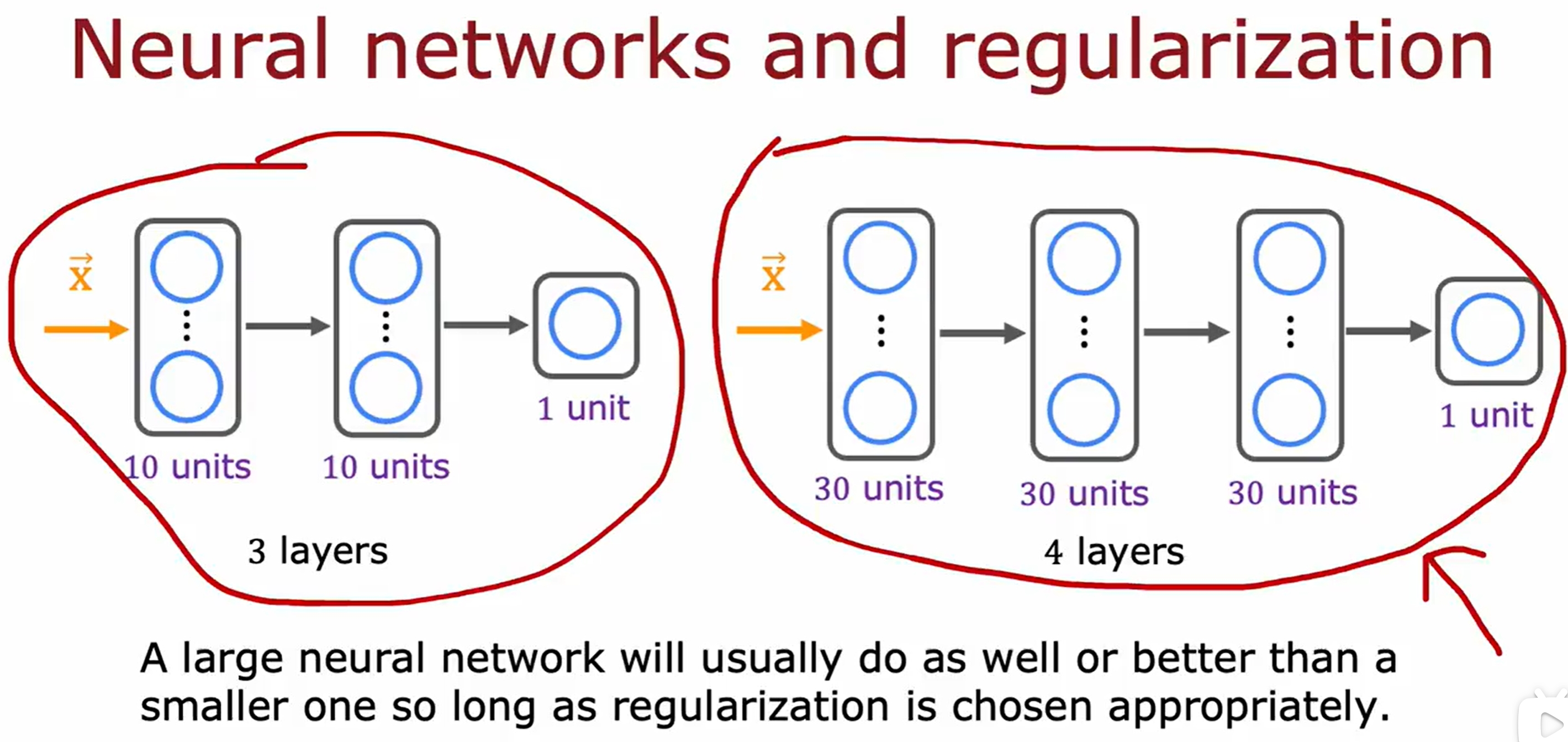
注意更多的训练集只是对过拟合的模型有效的,对于欠拟合的模型是没有用的。因此虽然learning是数据驱动的,但是也是需要模型足够的强,大数据才有用!
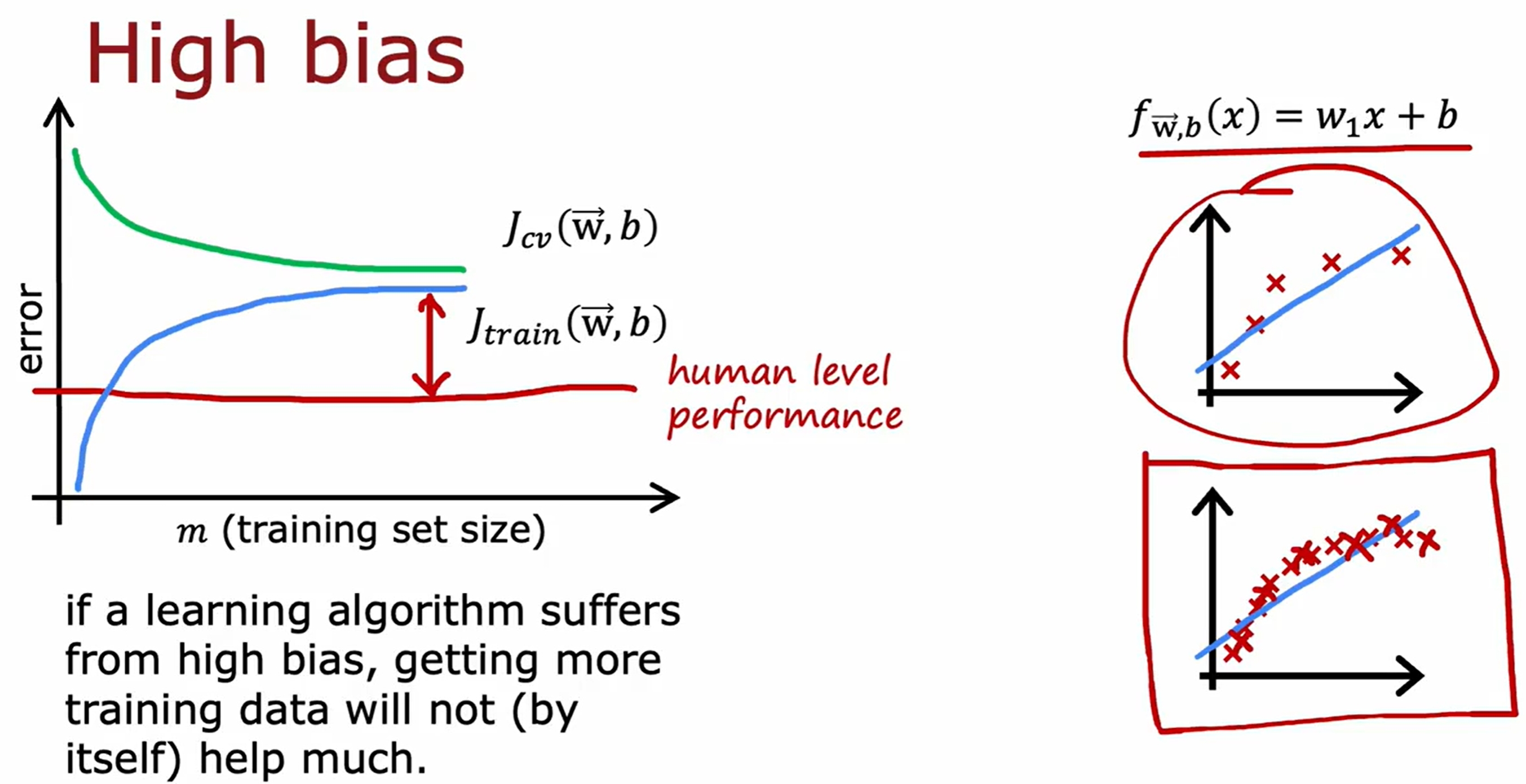
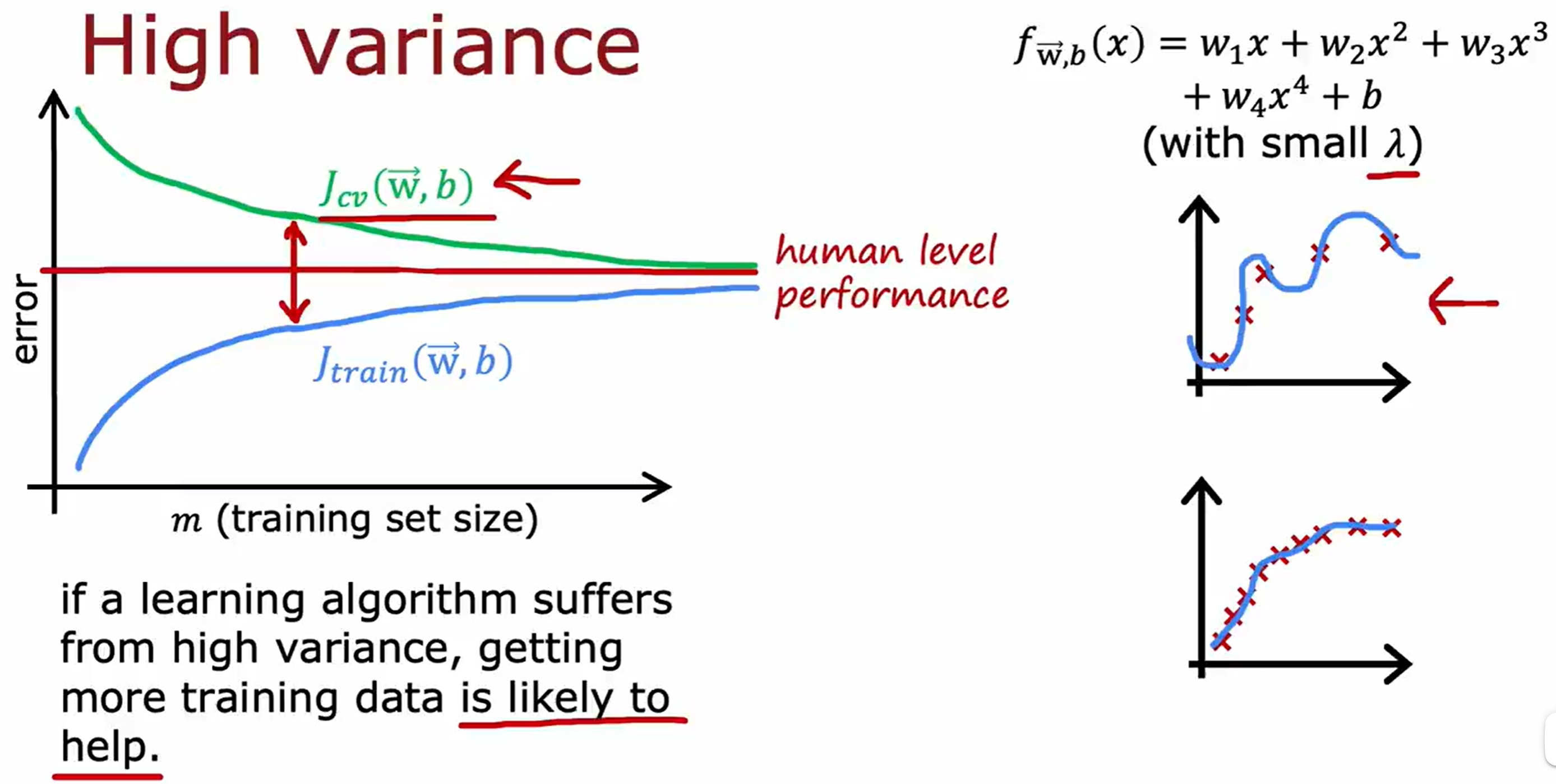
基于神经网络的bias与variance分析
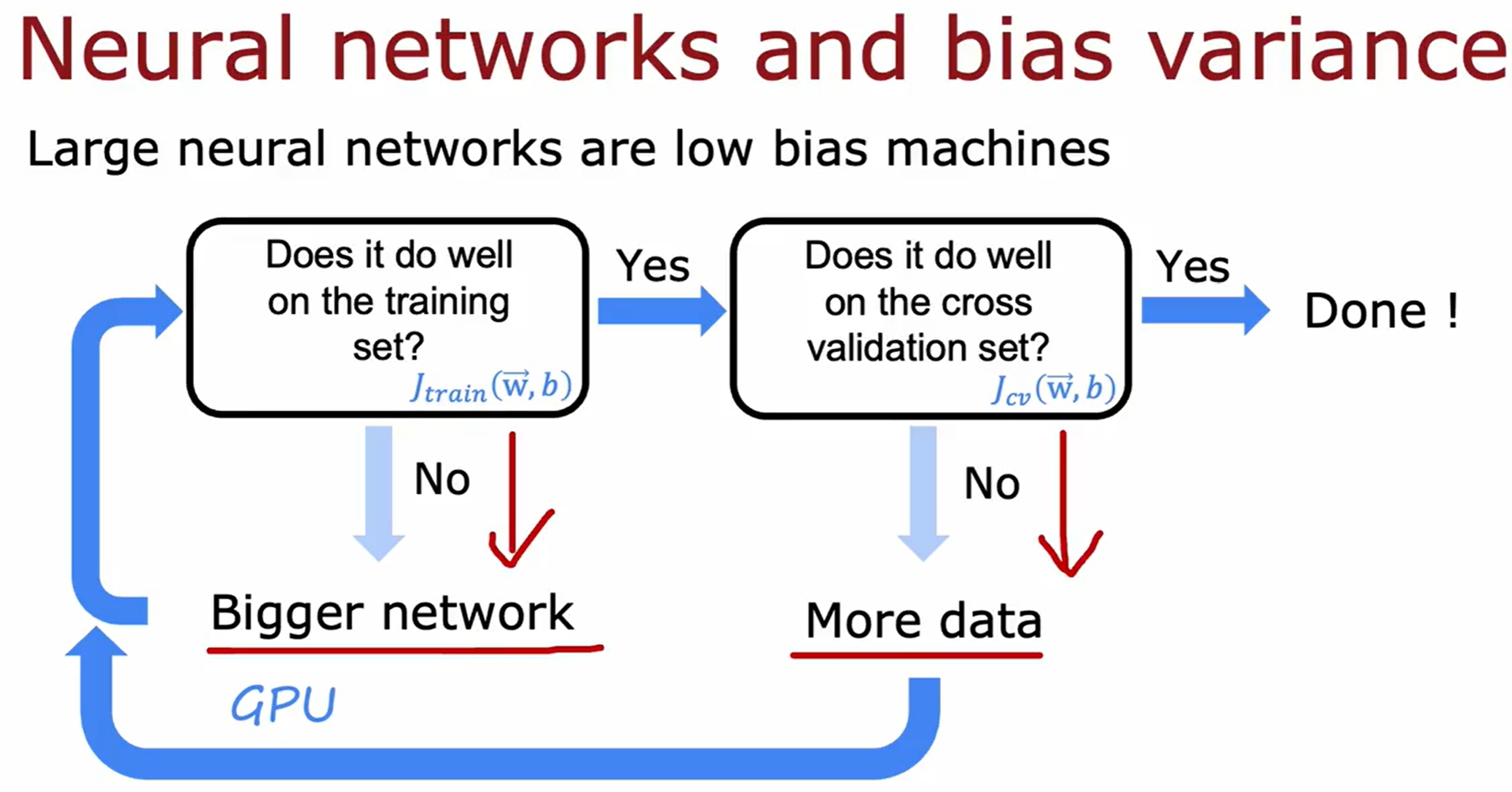
前面都是基于线性回归的,此处看看基于神经网络的debugging,但本质上其实是一样的~

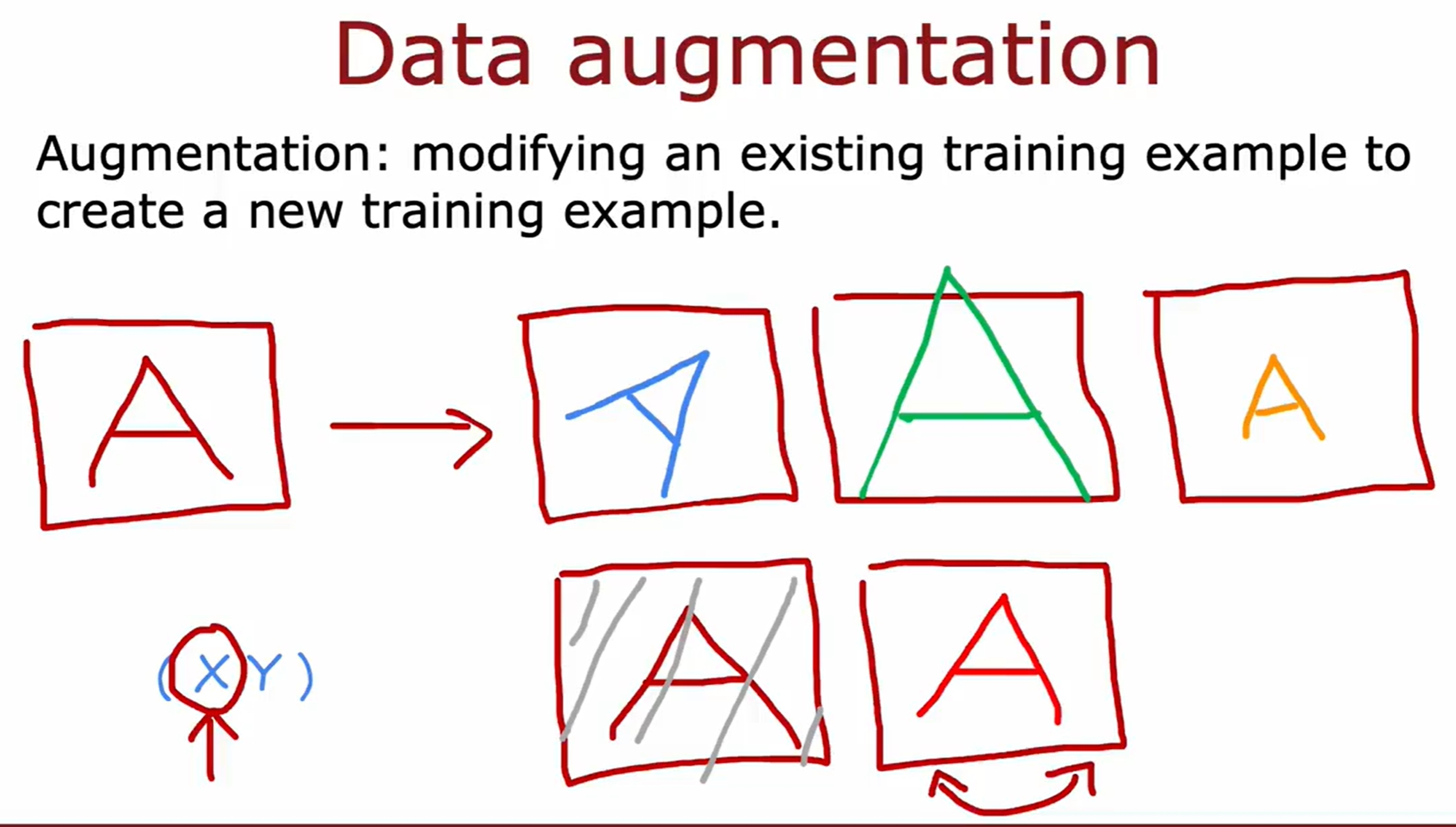
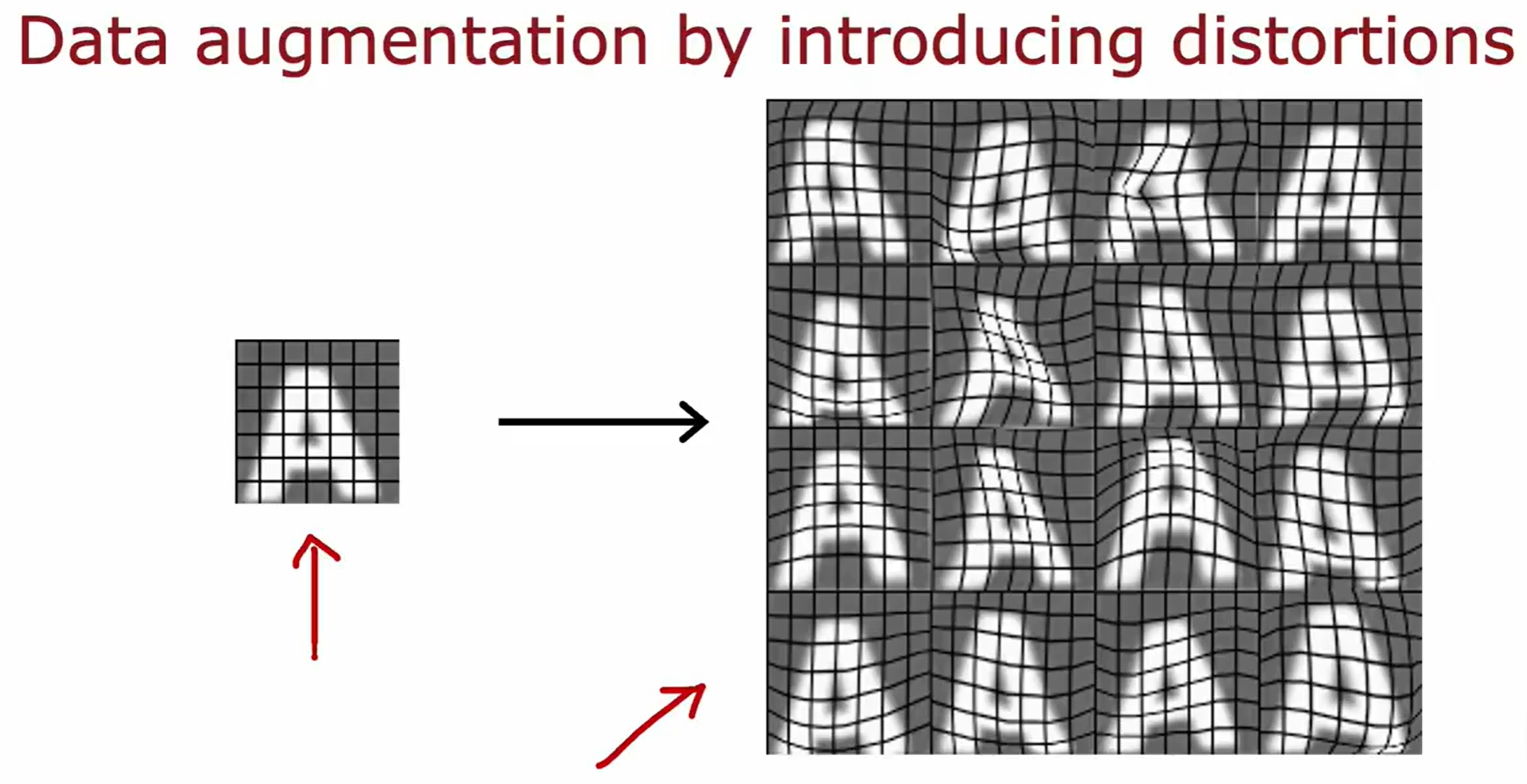
数据增广(data augmentation)

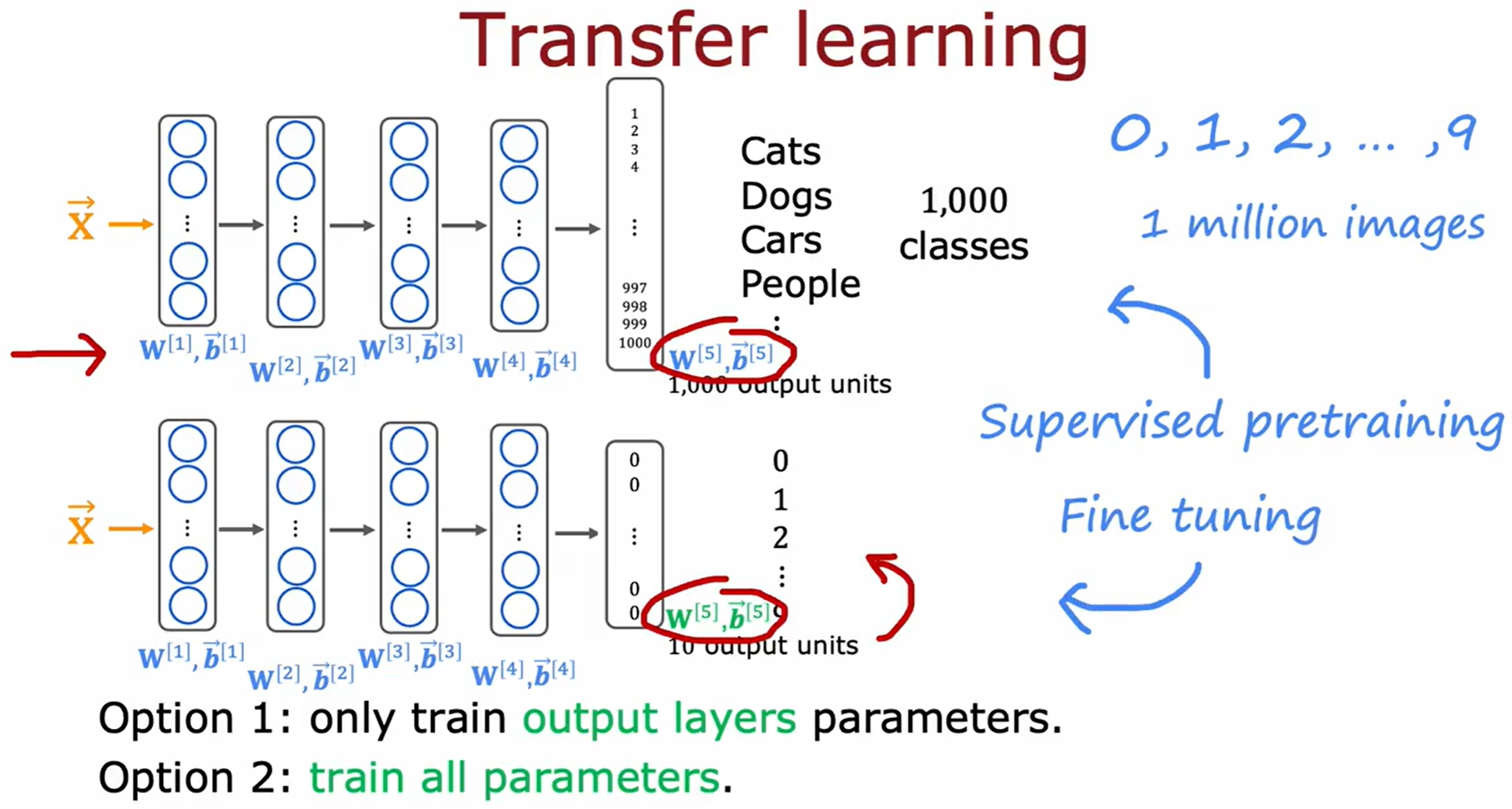
迁移学习(transfer learning)
所谓的迁移学习就是将一个模型的参数作为另一个模型的初始参数(或fixed大部分,仅改变某些参数),然后再进行训练。这样可以加速模型的训练,提升模型的性能。
换句话说也就是利用别的task中的数据(训练好的模型),如下图所示:
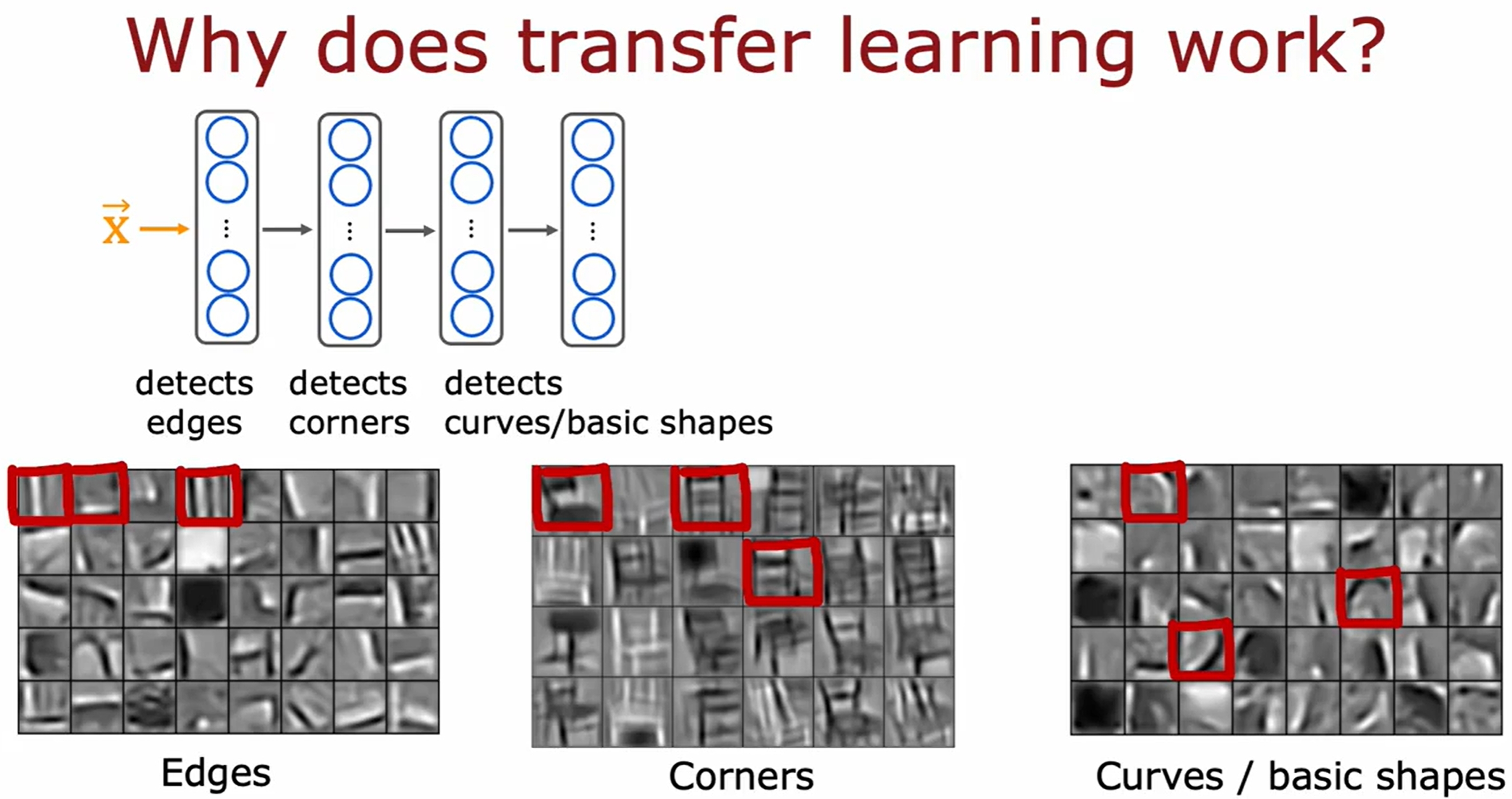
提升模型性能的总结及系列实验

Unsupervised Learning
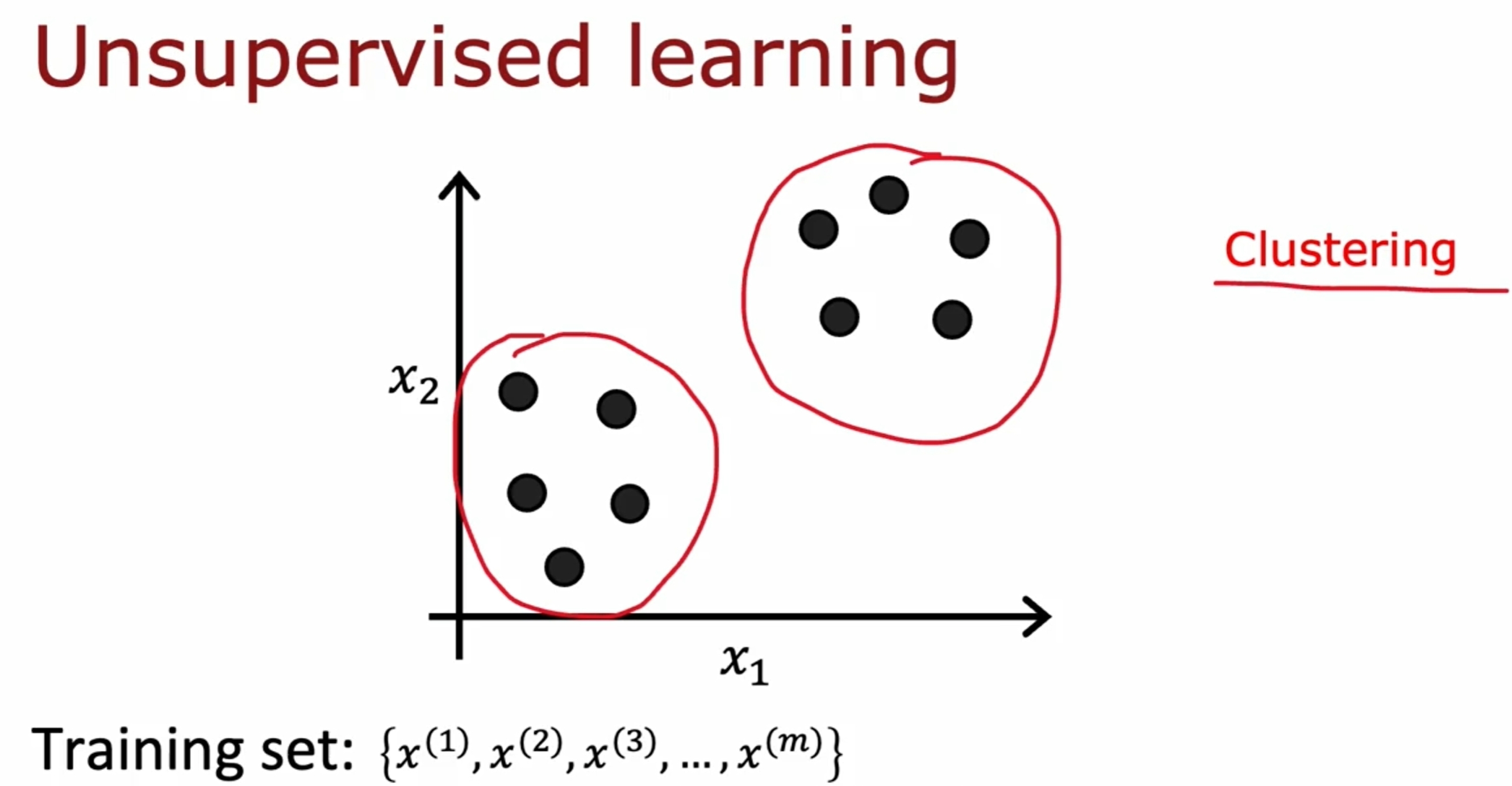
与Supervised Learning不同,Unsupervised Learning是没有label的,也就是说,目标是找到数据的结构或者模式,比如聚类(clustering),异常检测(Anomaly Detection),降维(Dimensionality Reduction)等。
Clustering(聚类)
输入的数据并没有label,也没有办法告诉模型什么才是“正确”的答案。
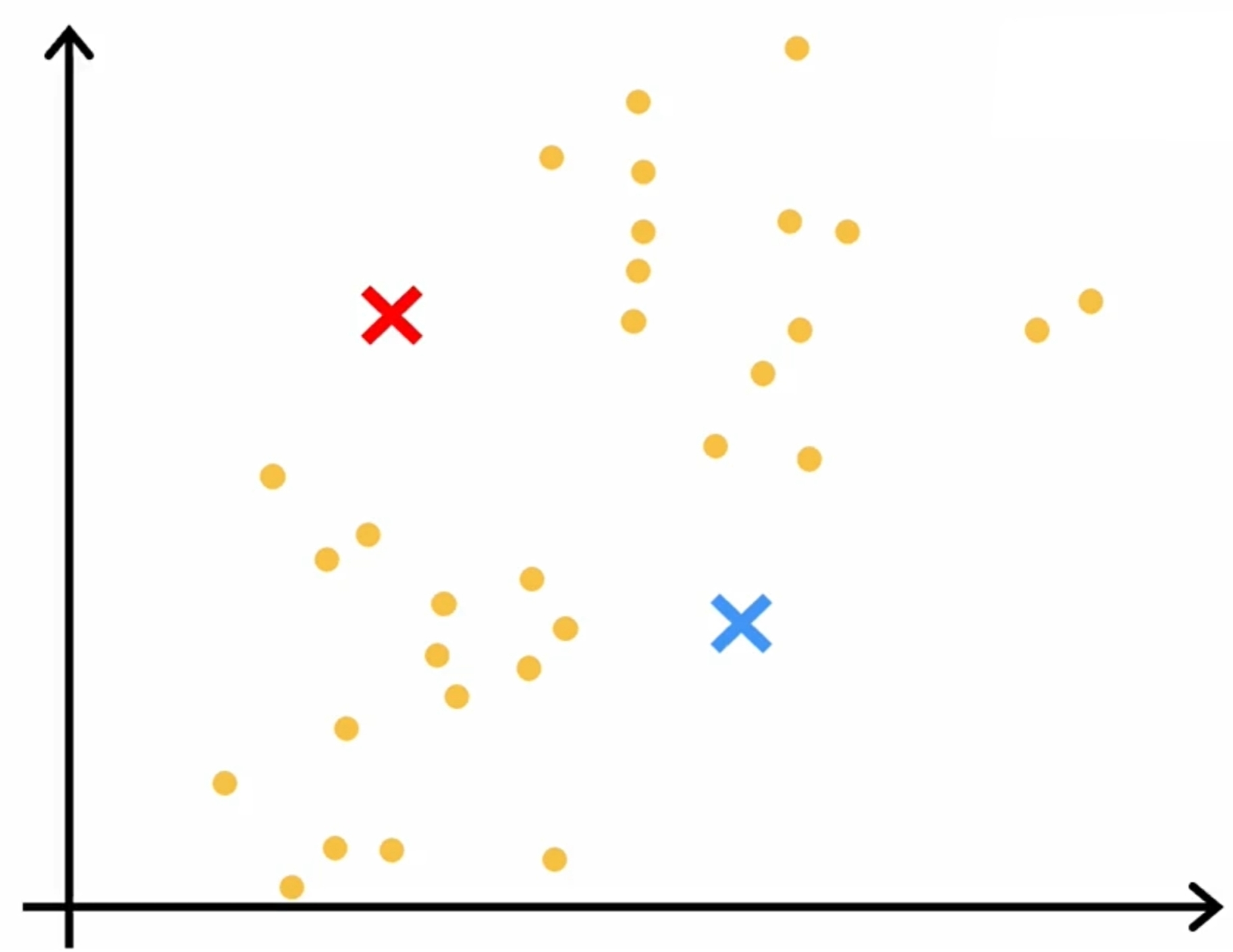
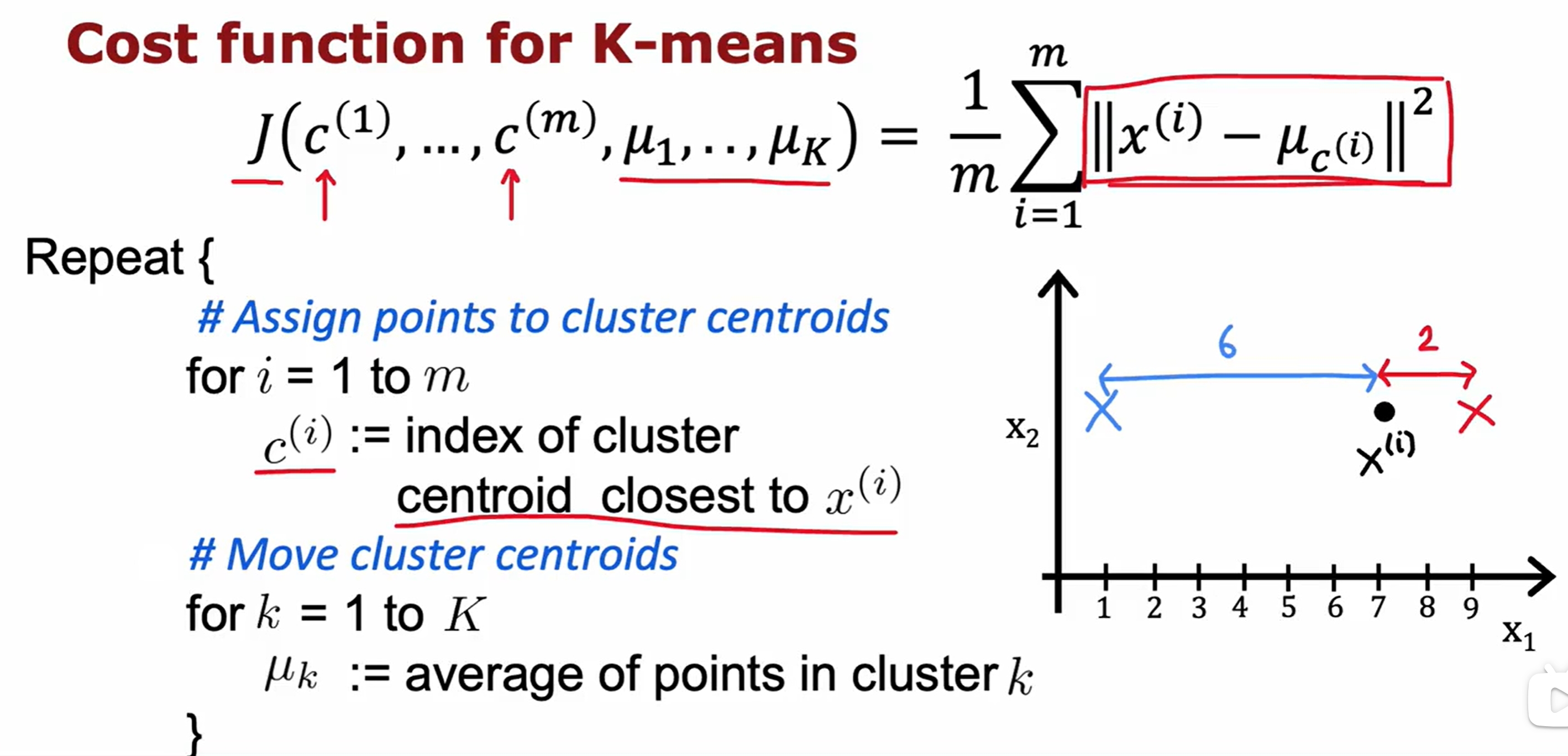
K-means
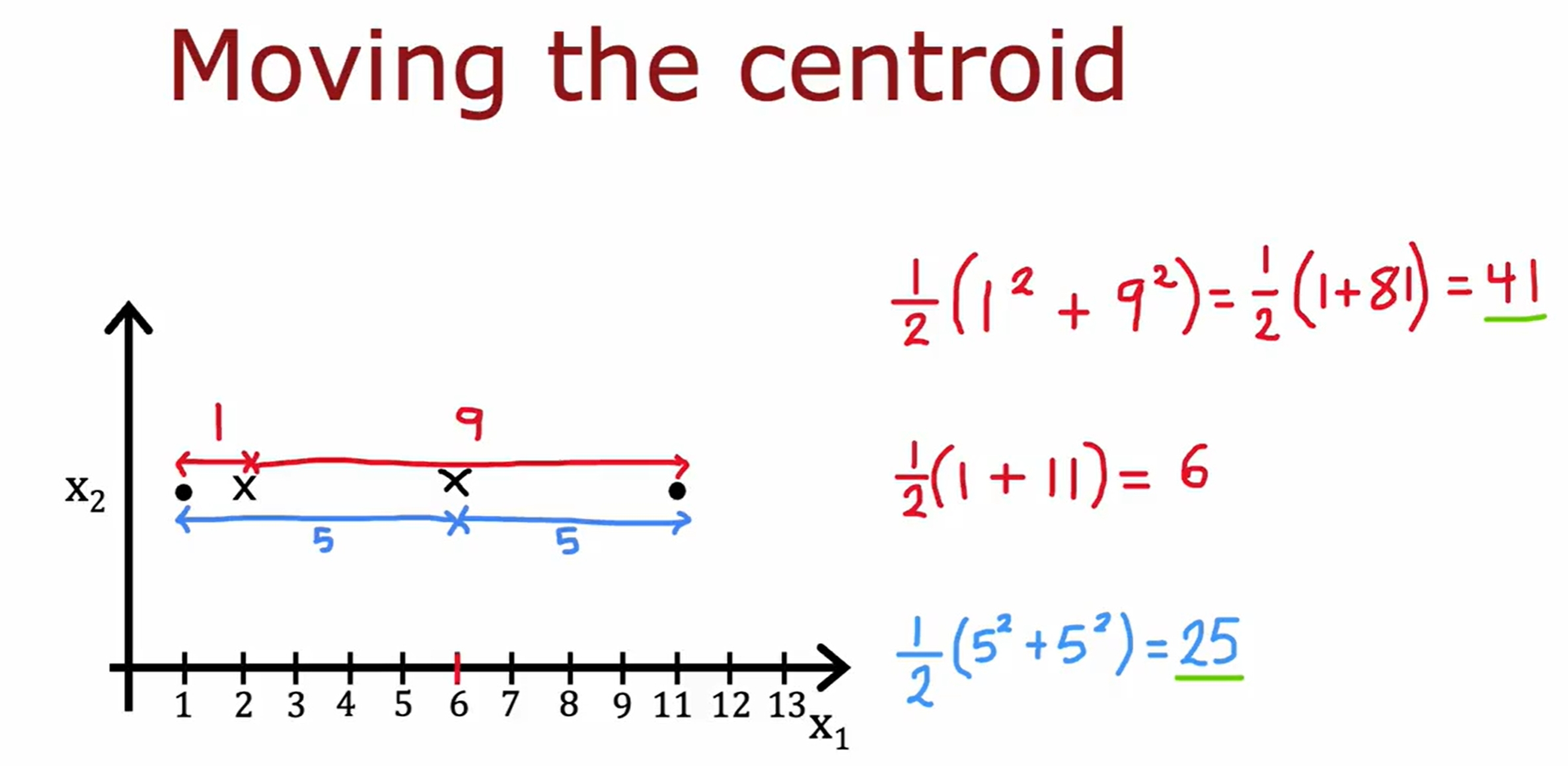
首先是随机初始化K(下图是两个)个中心点,然后不断的迭代,直到中心点不再变化为止。如下图所示:
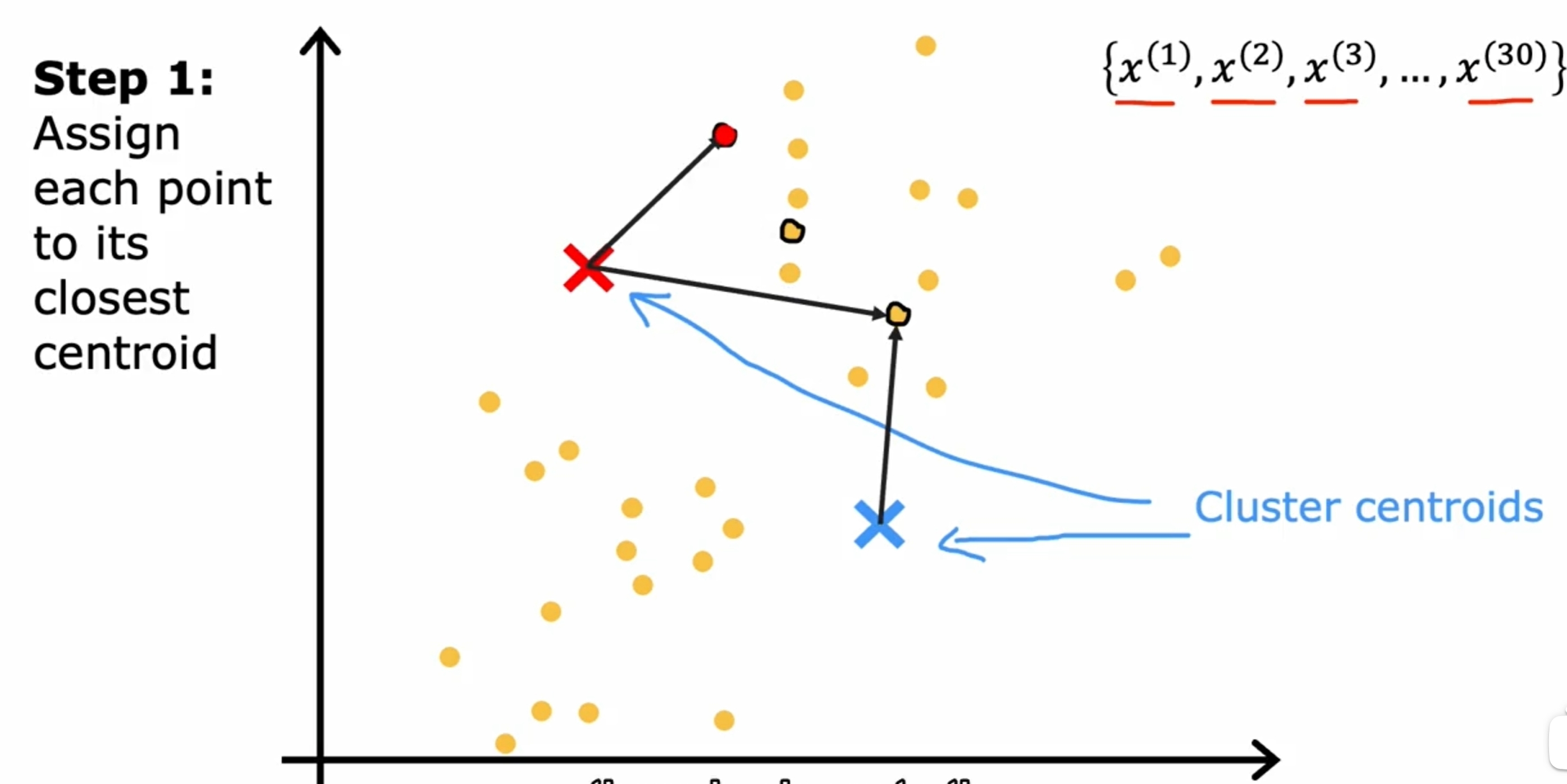
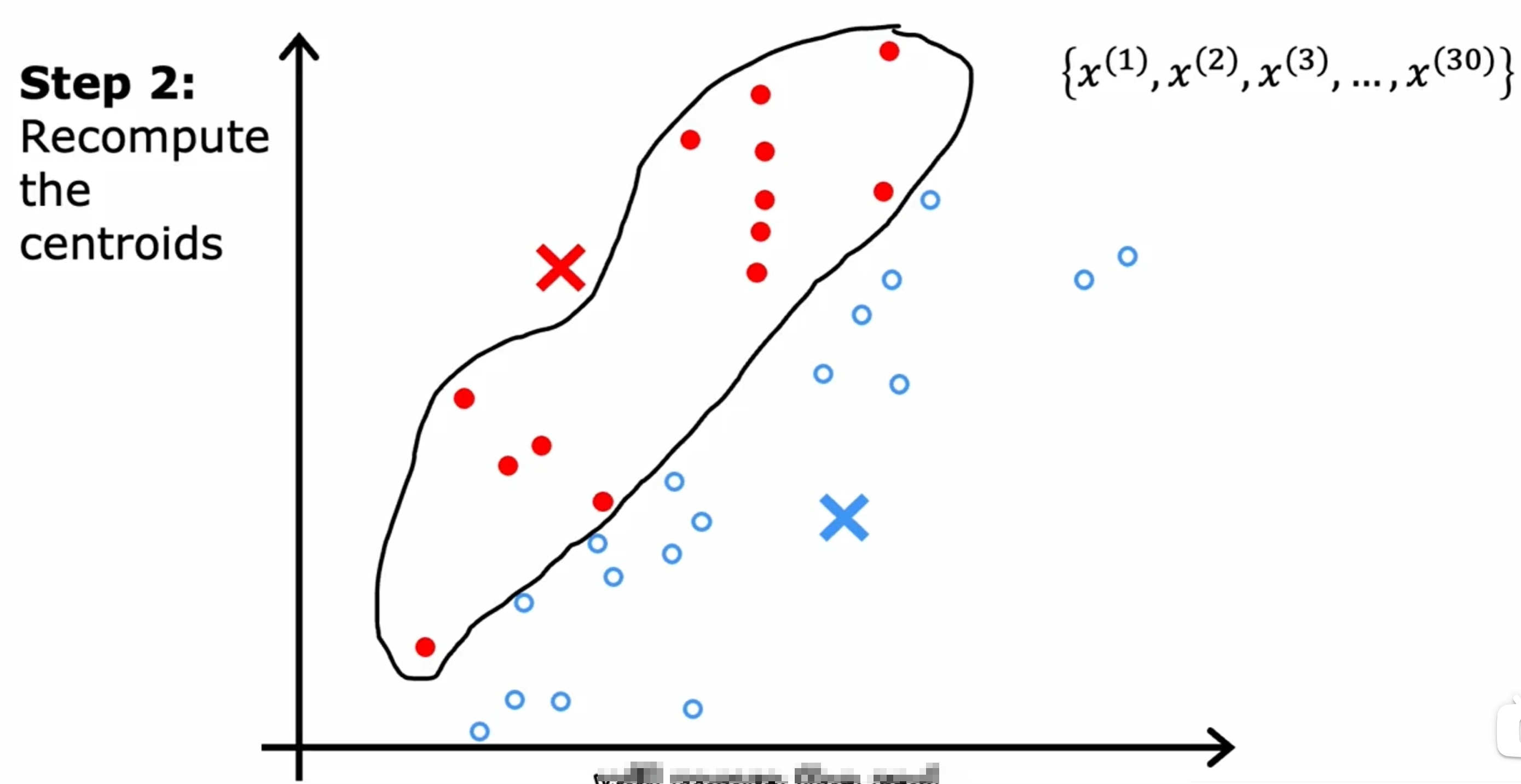
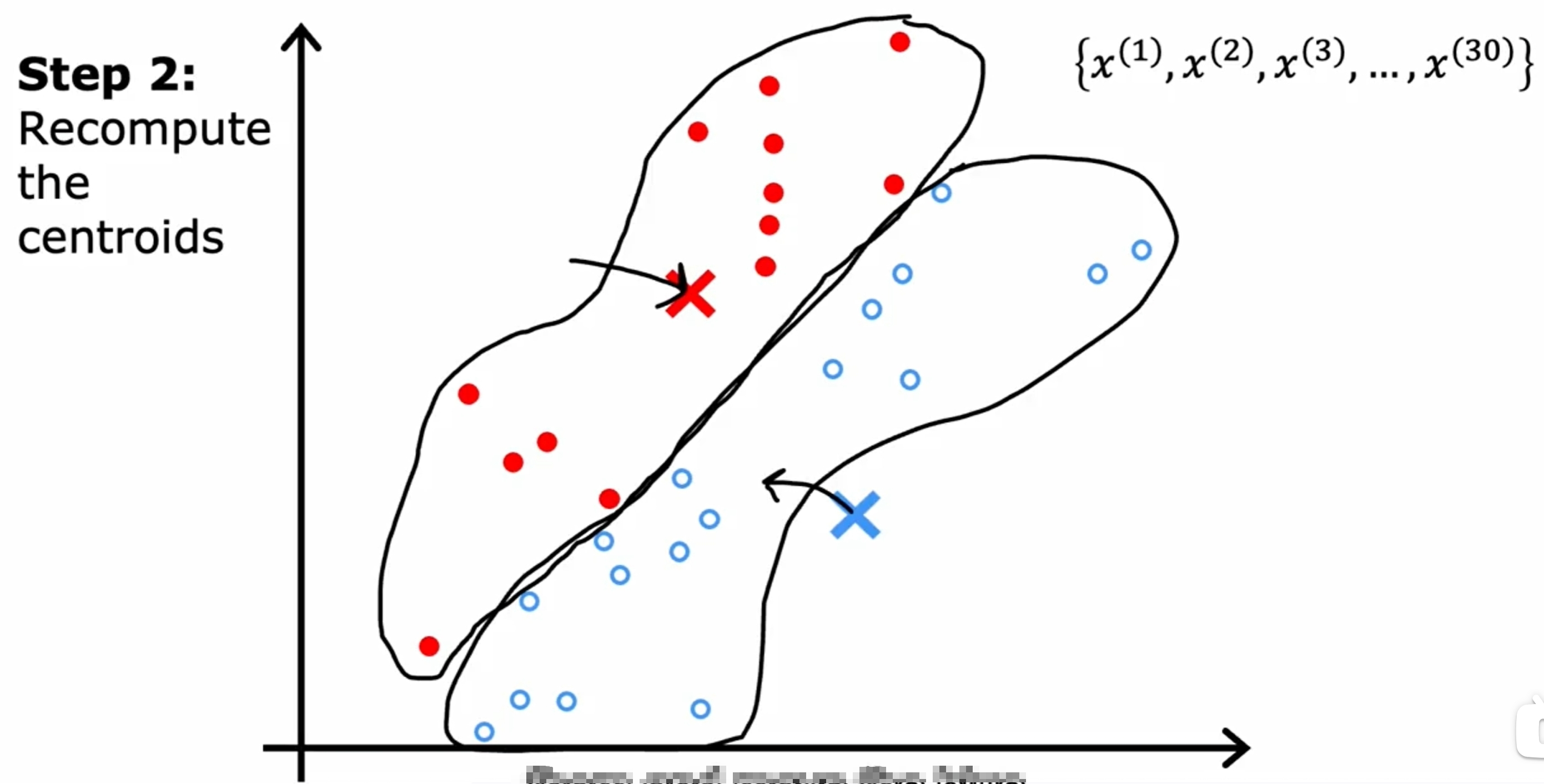
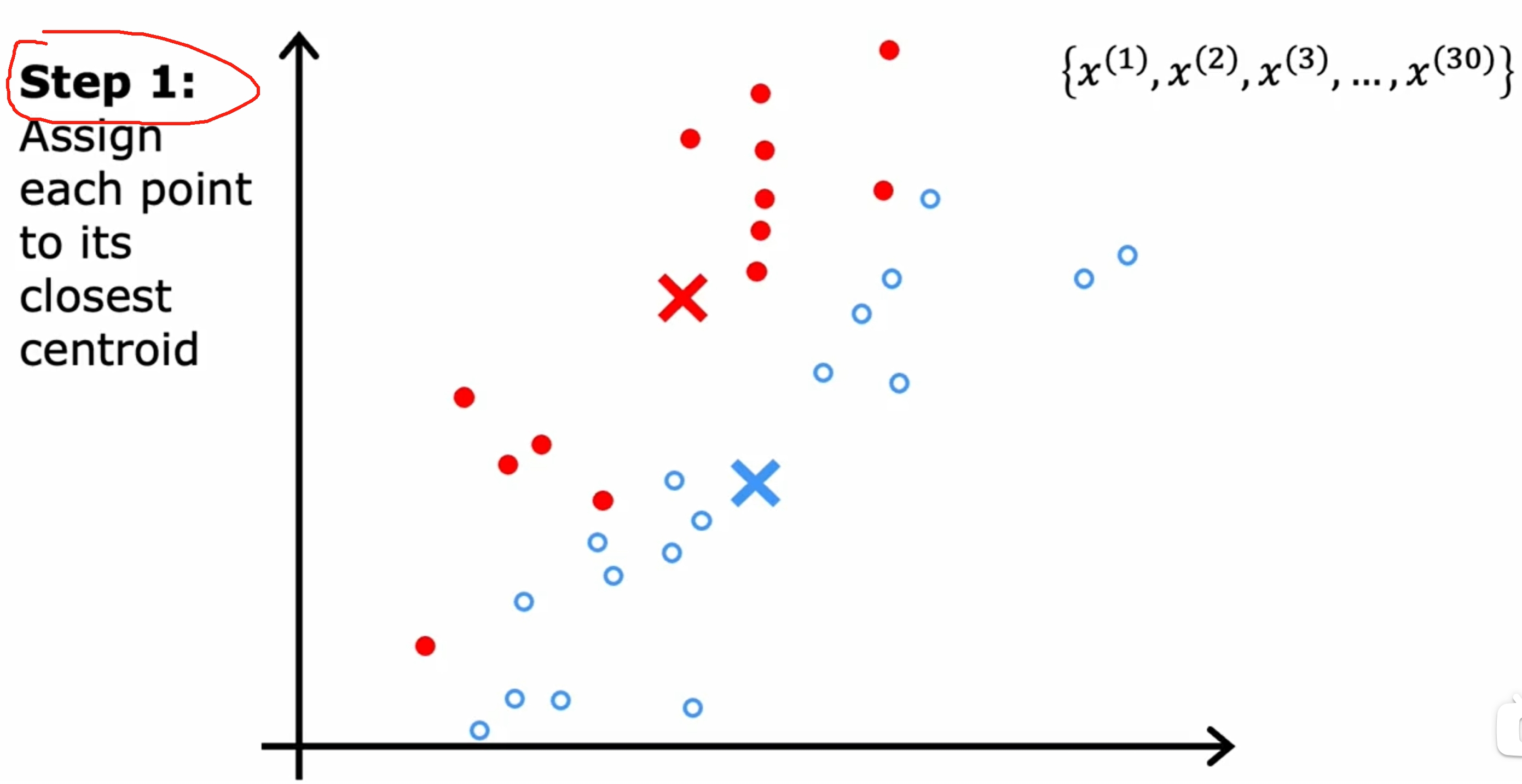
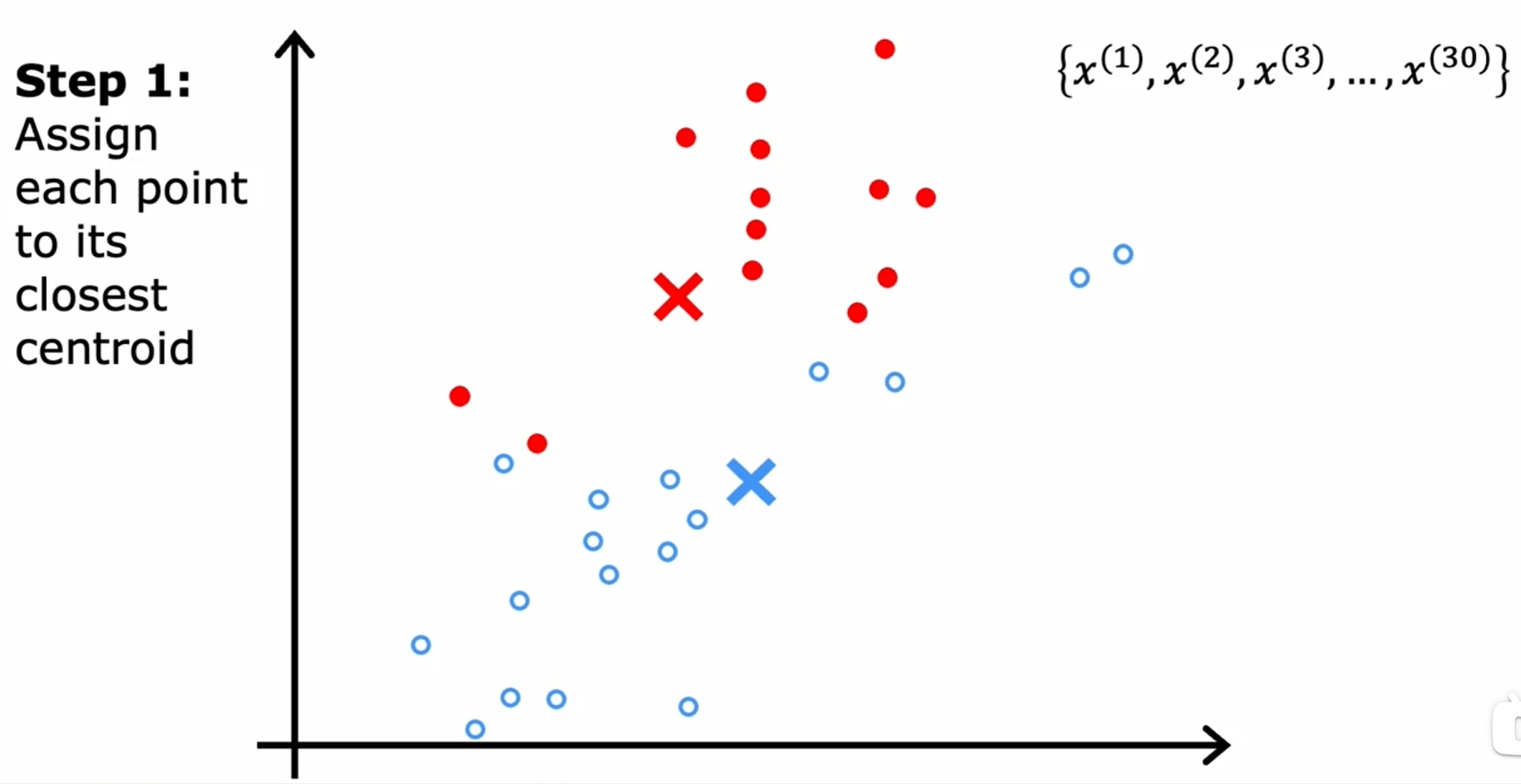
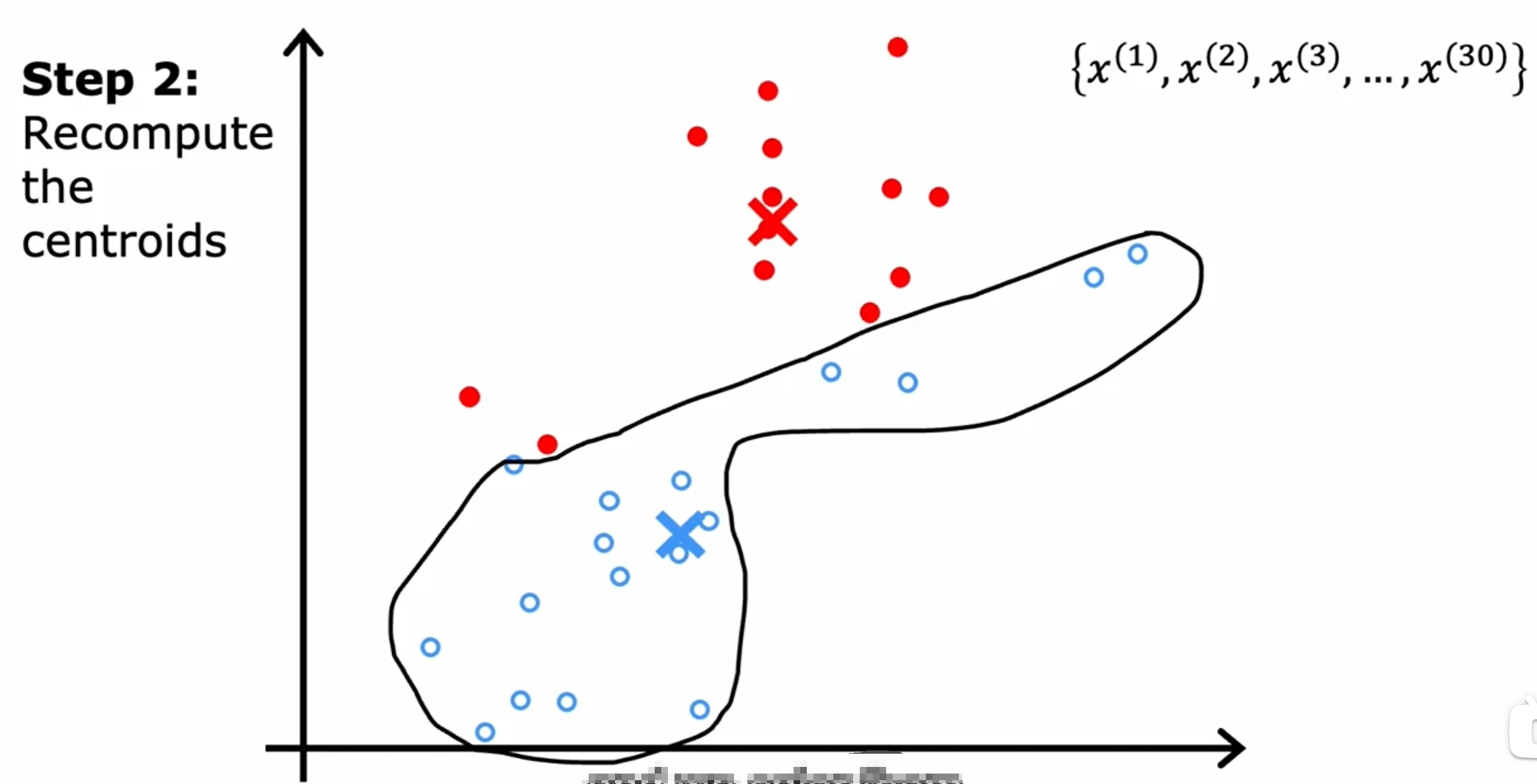
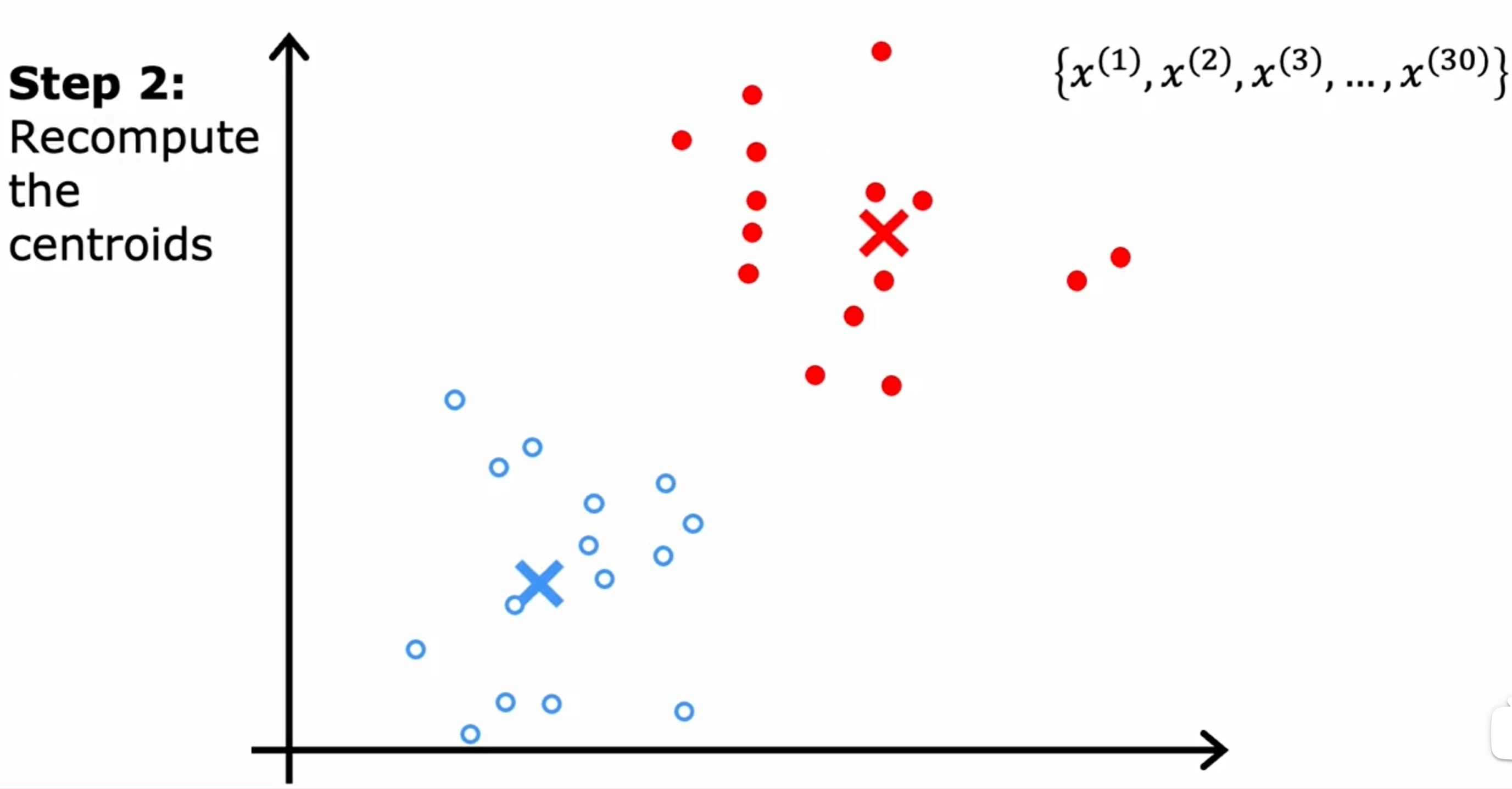

而对于数据之间界限没有明显的区分的情况,如下图所示:
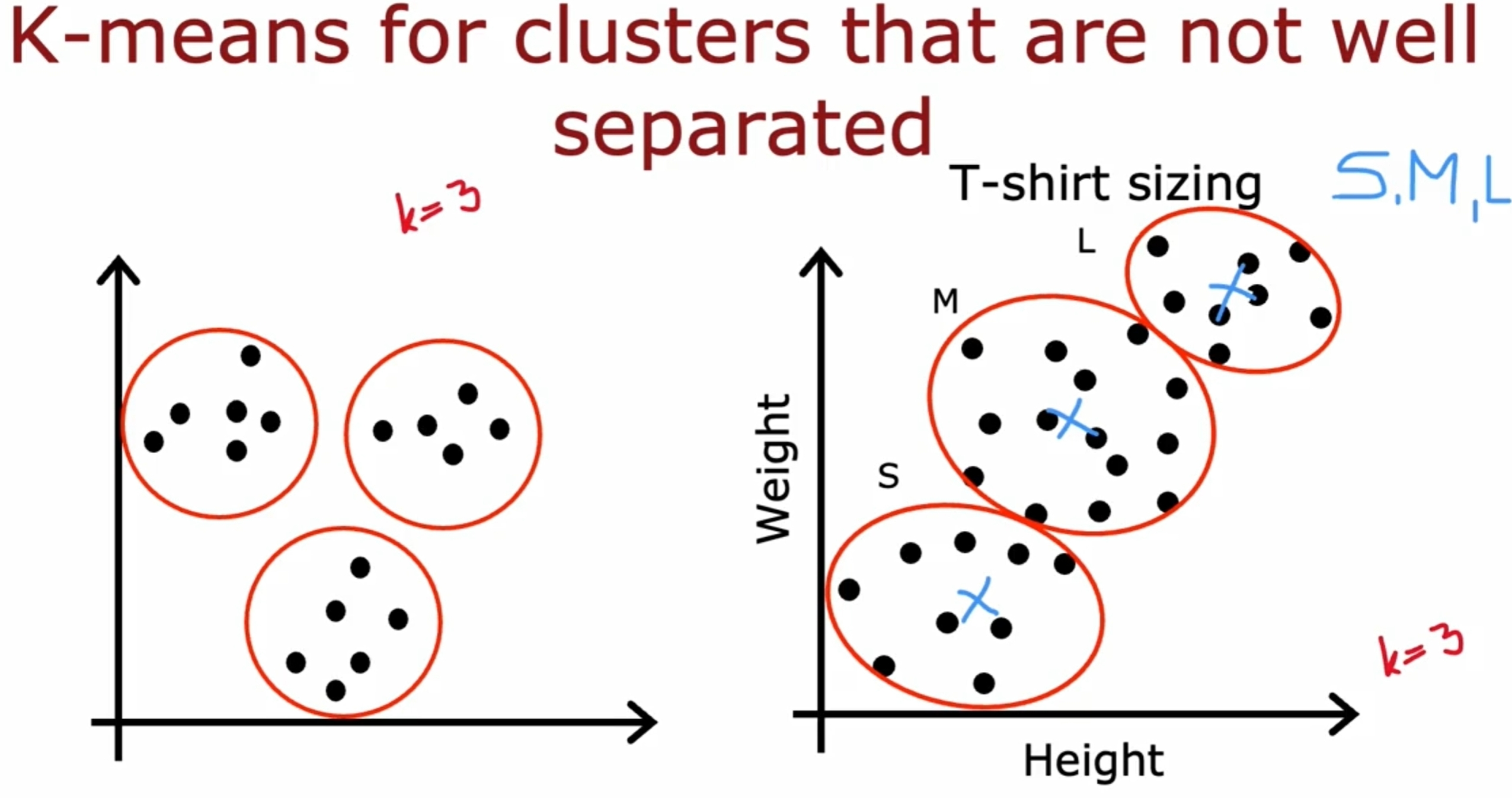


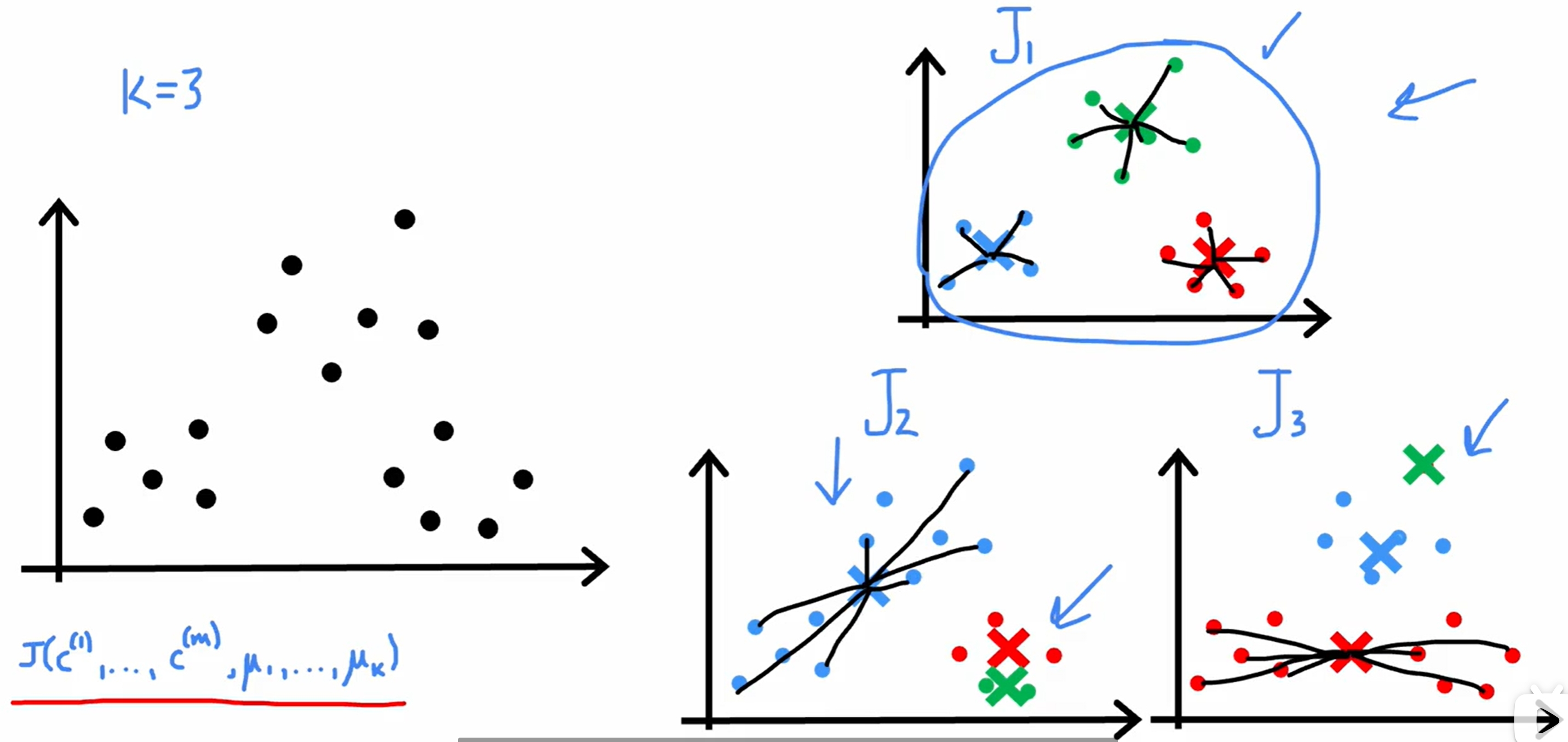

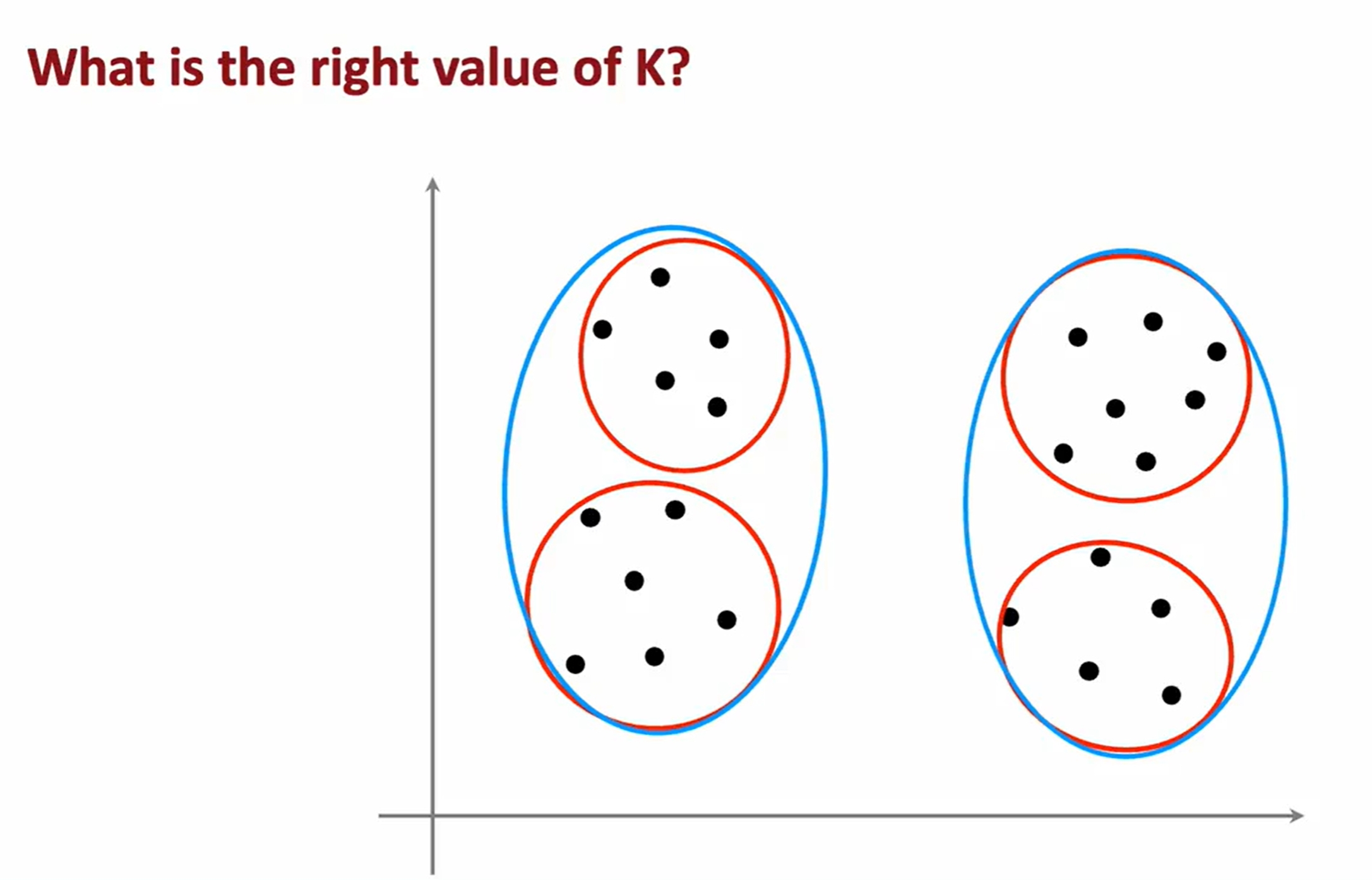
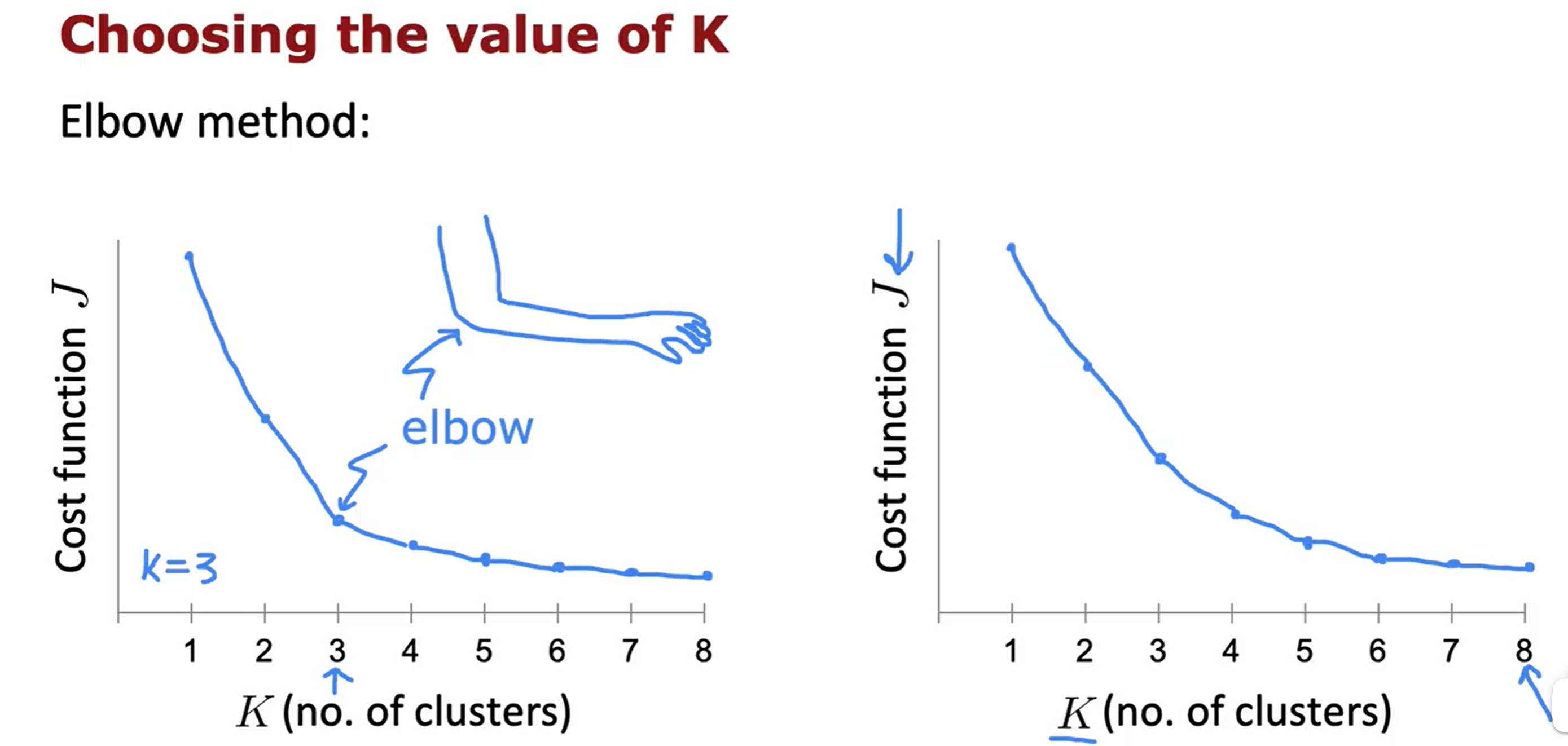
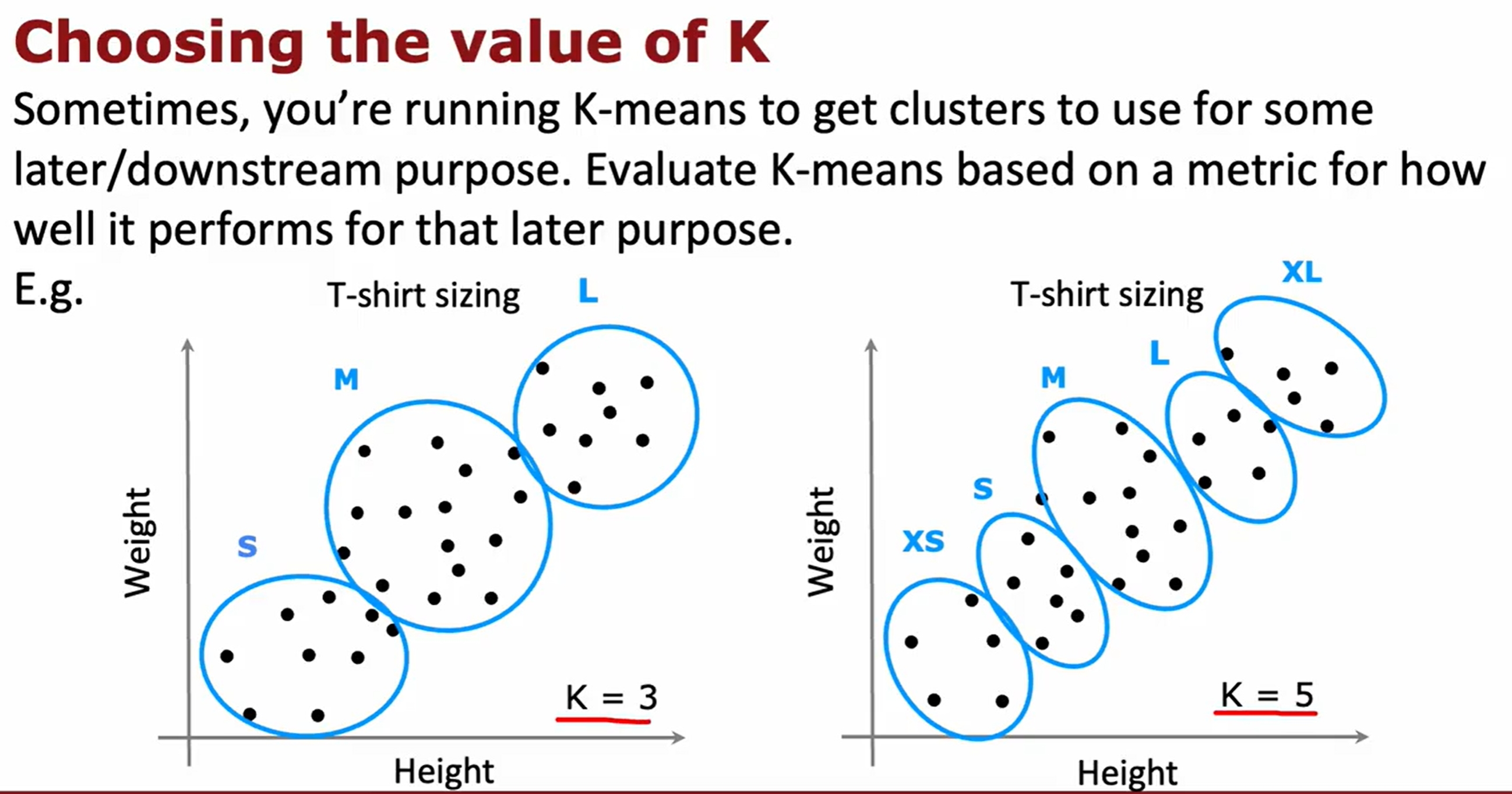
Anomaly Detection(异常检测)
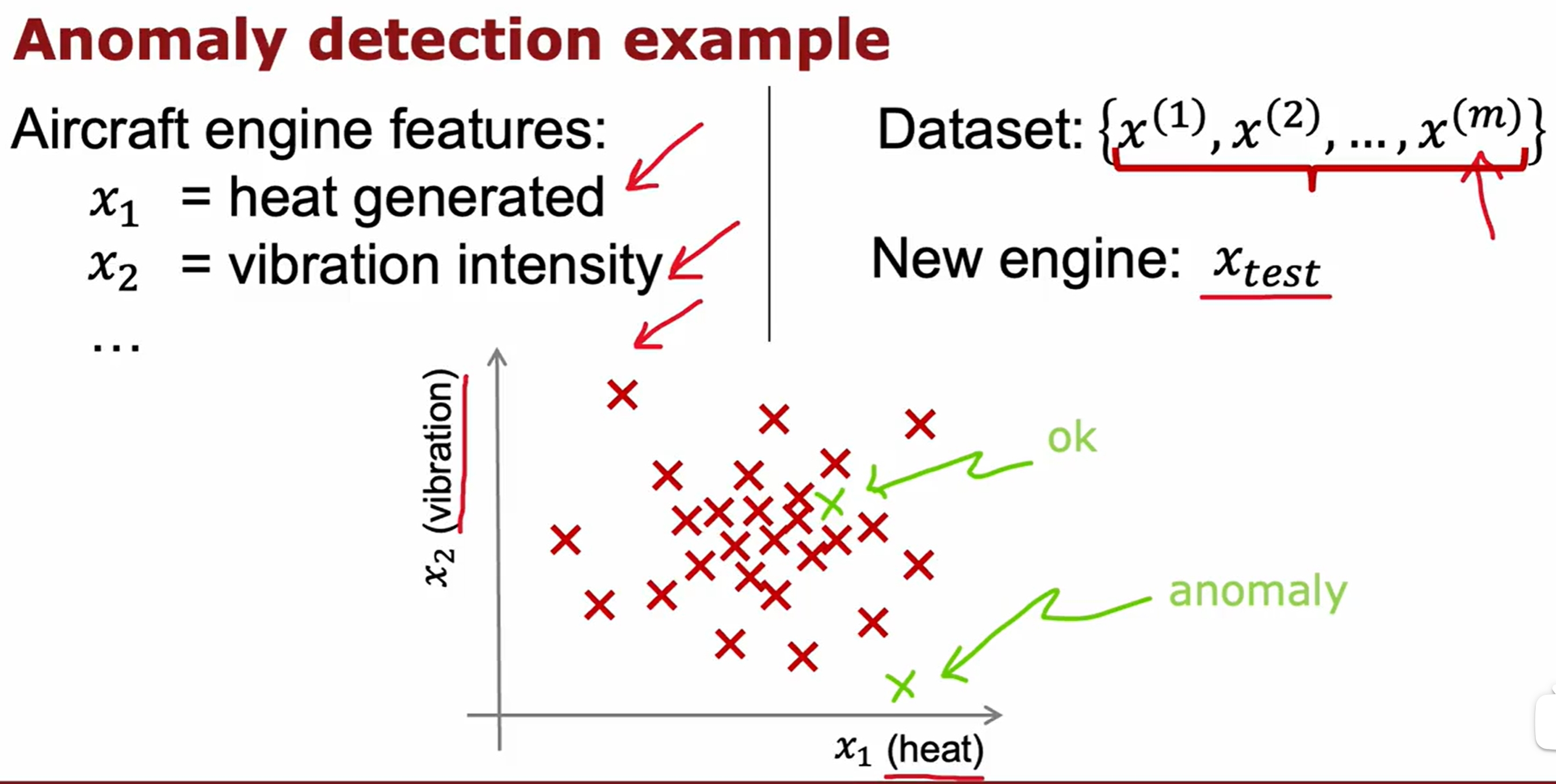
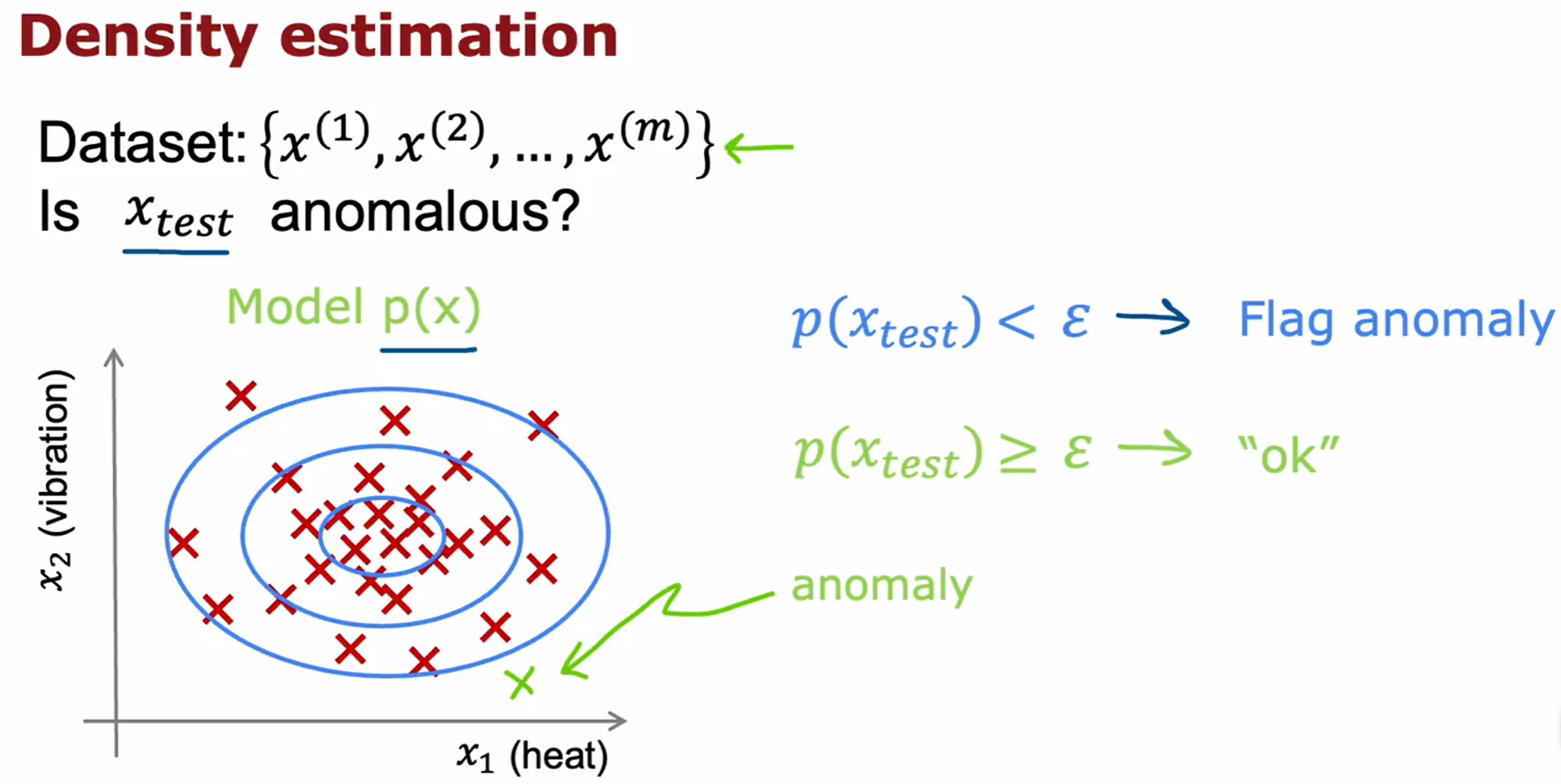
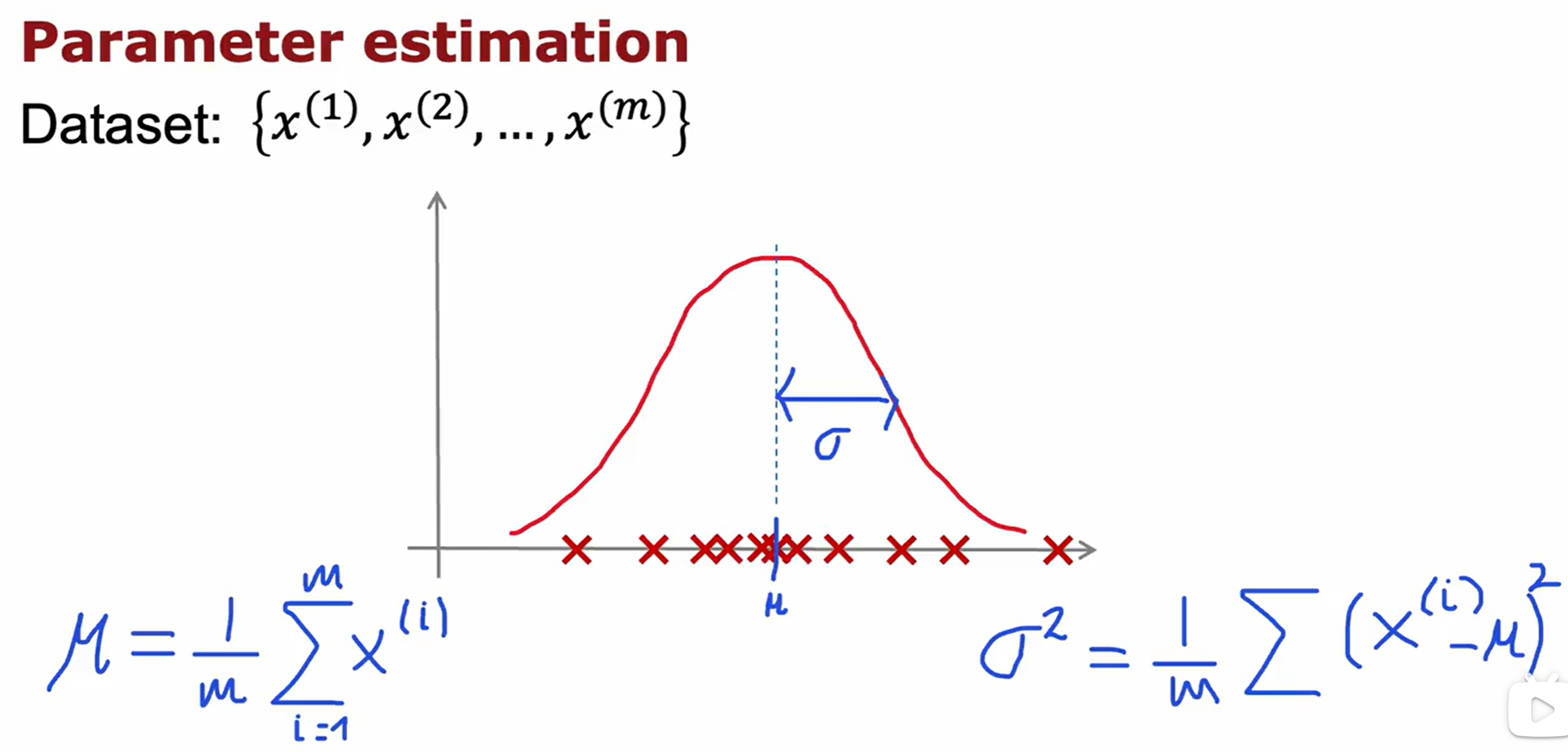
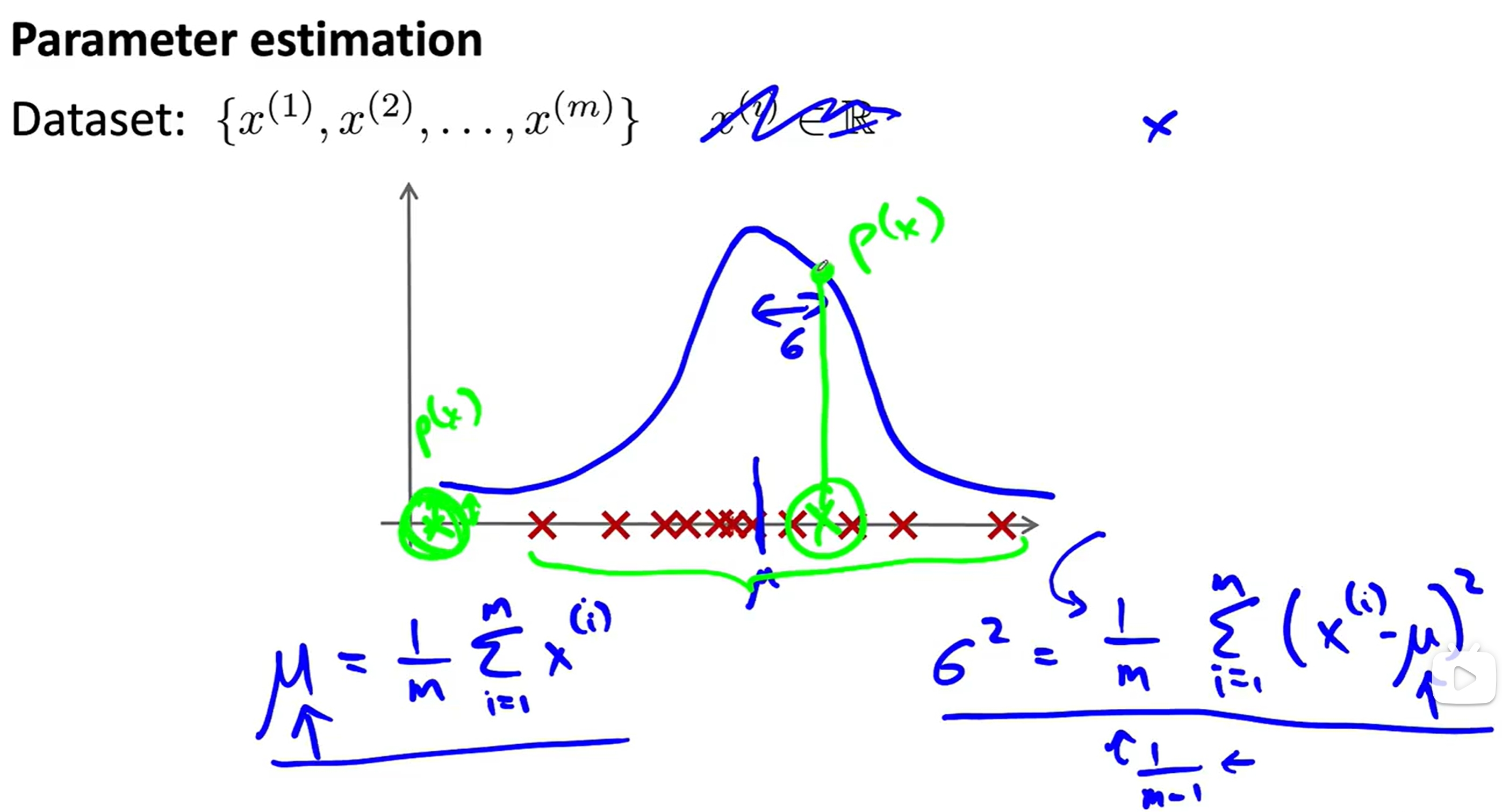


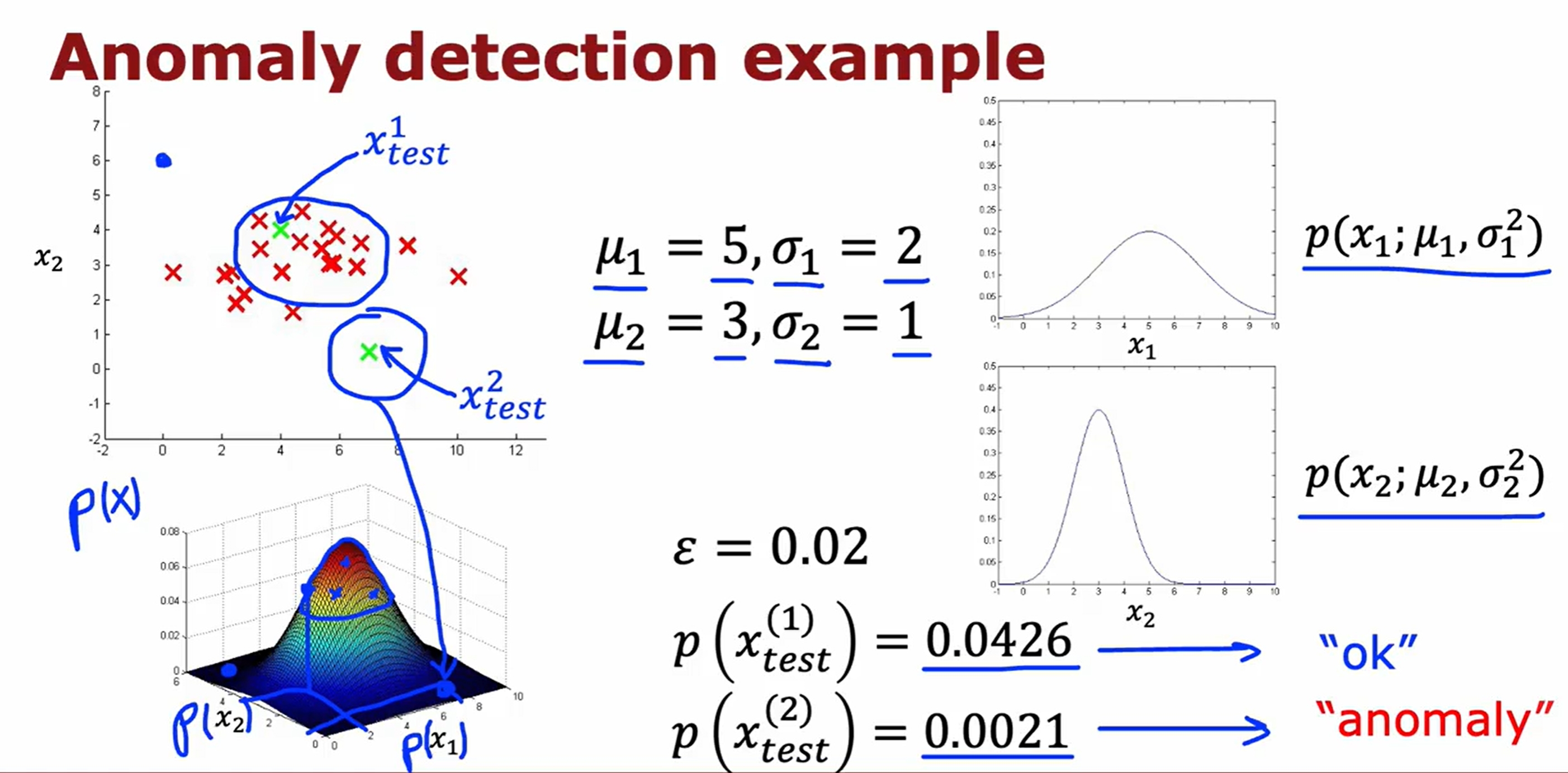

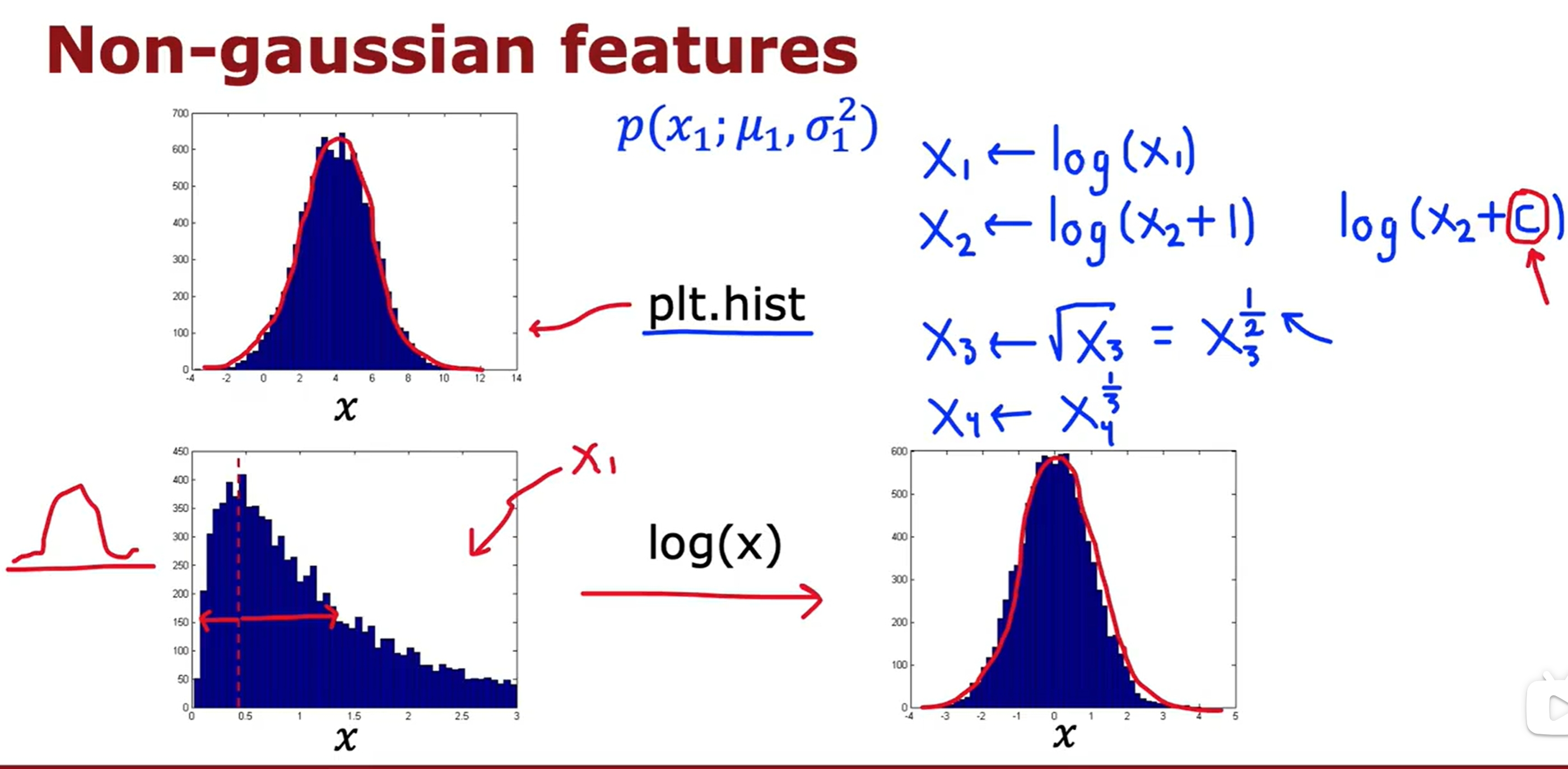
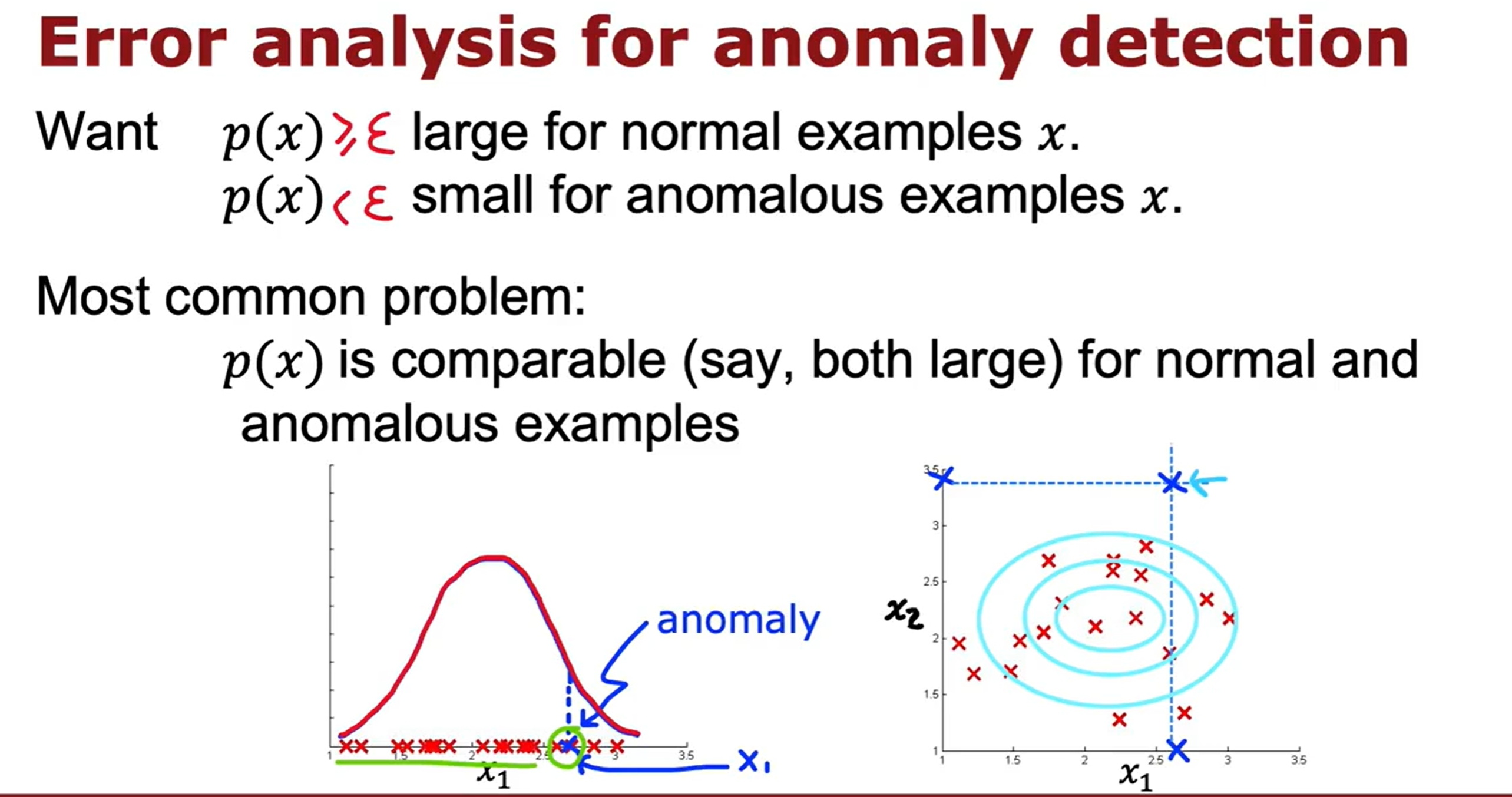
K-means与异常检测的实验代码
Reinforcement Learning
强化学习是要告诉模型什么是“正确”的答案,而是通过奖励来告诉模型什么是“好”的行为。也就是告诉模型what to do而不是how to do it,由模型自己来学习如何做。
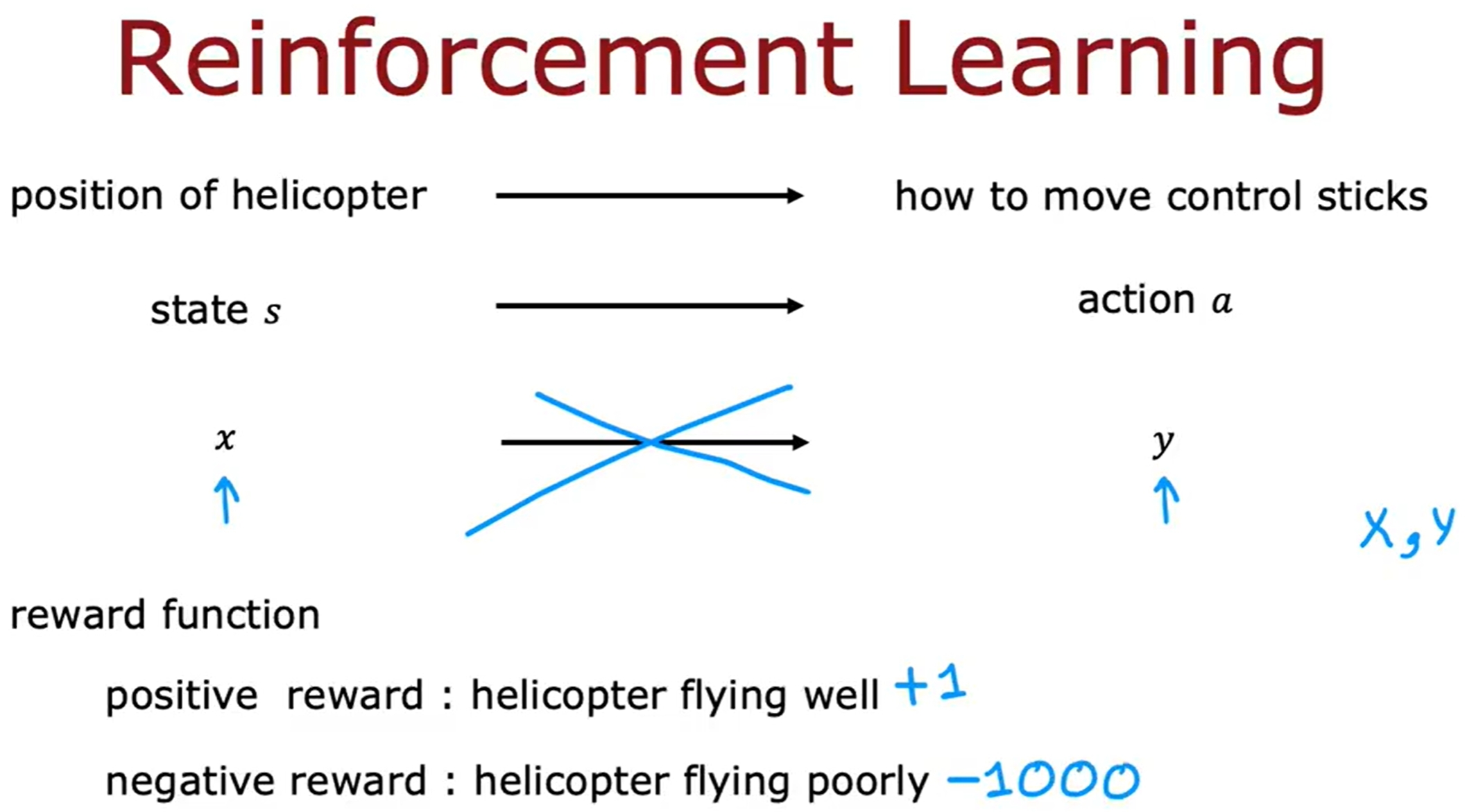
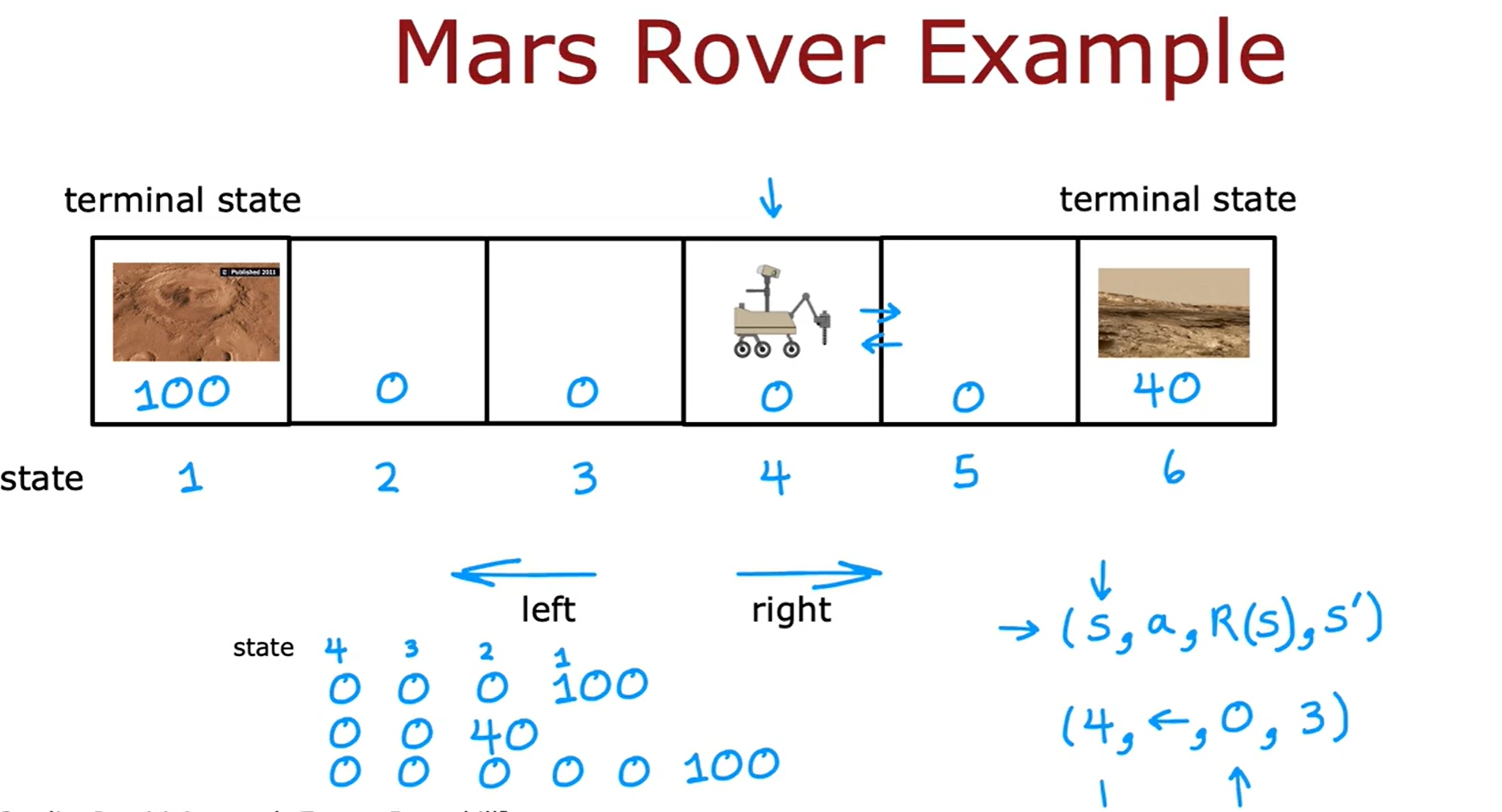


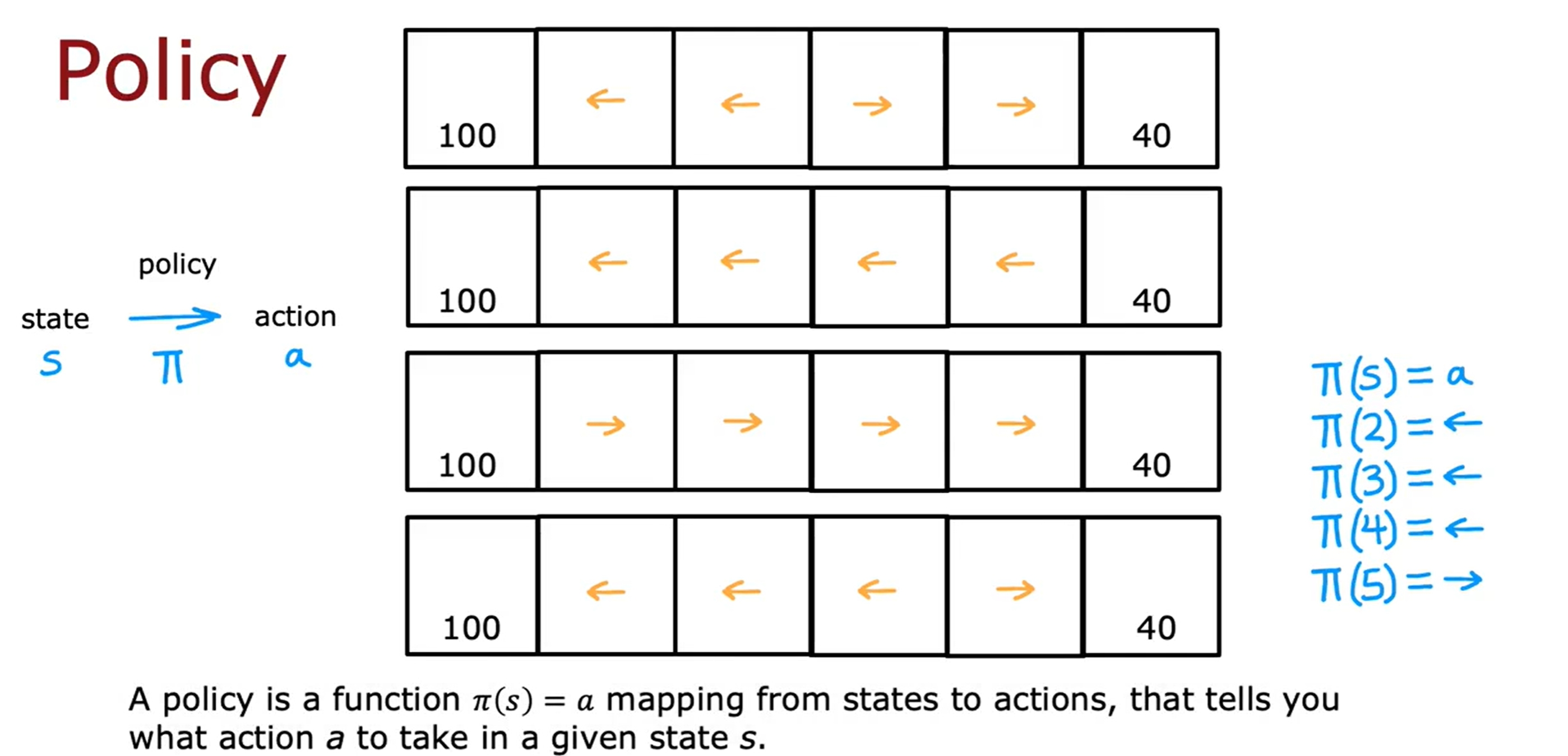
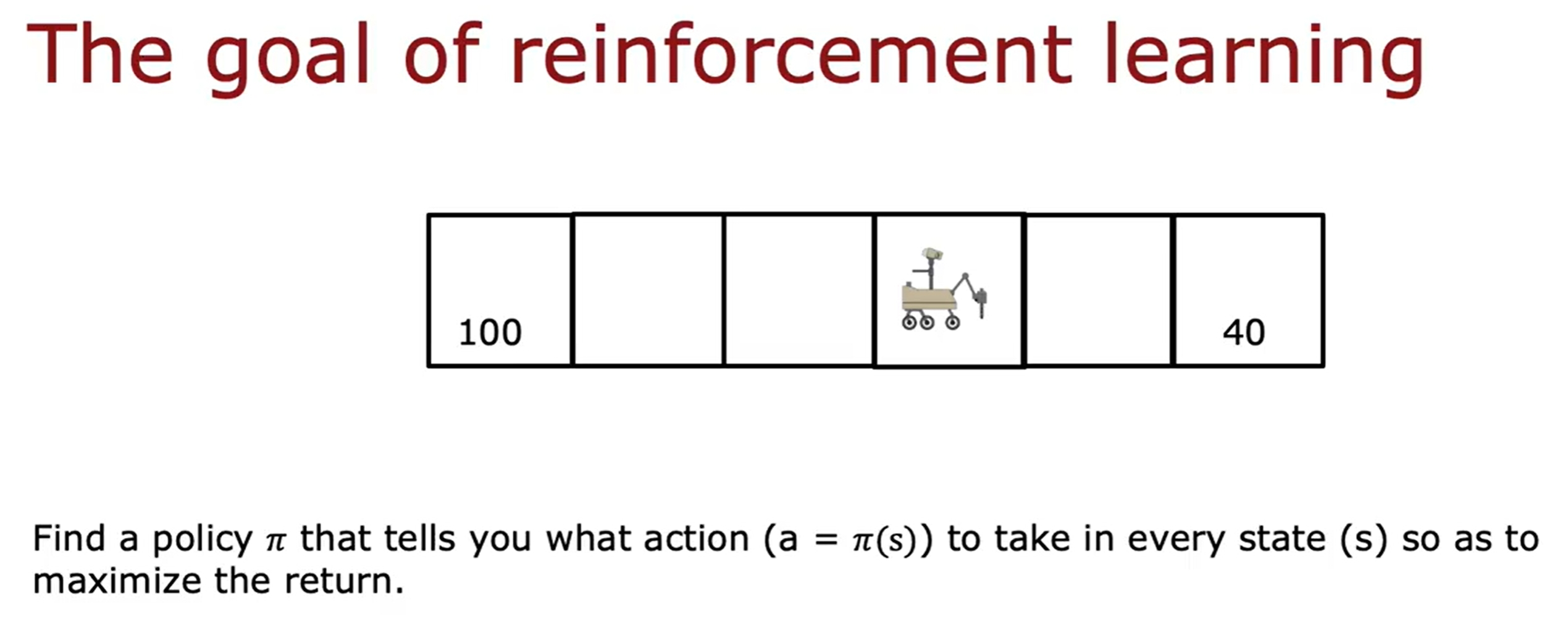
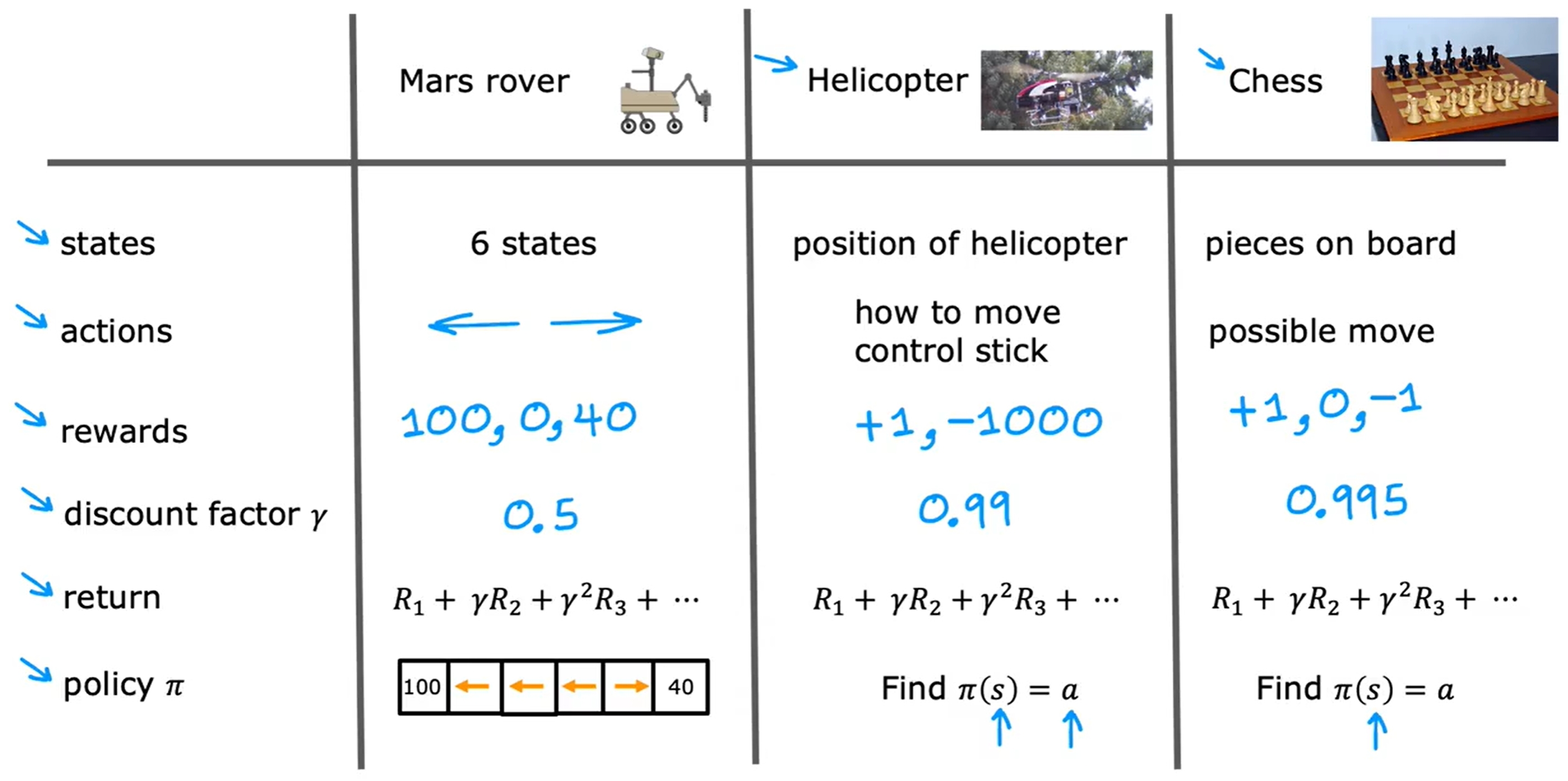
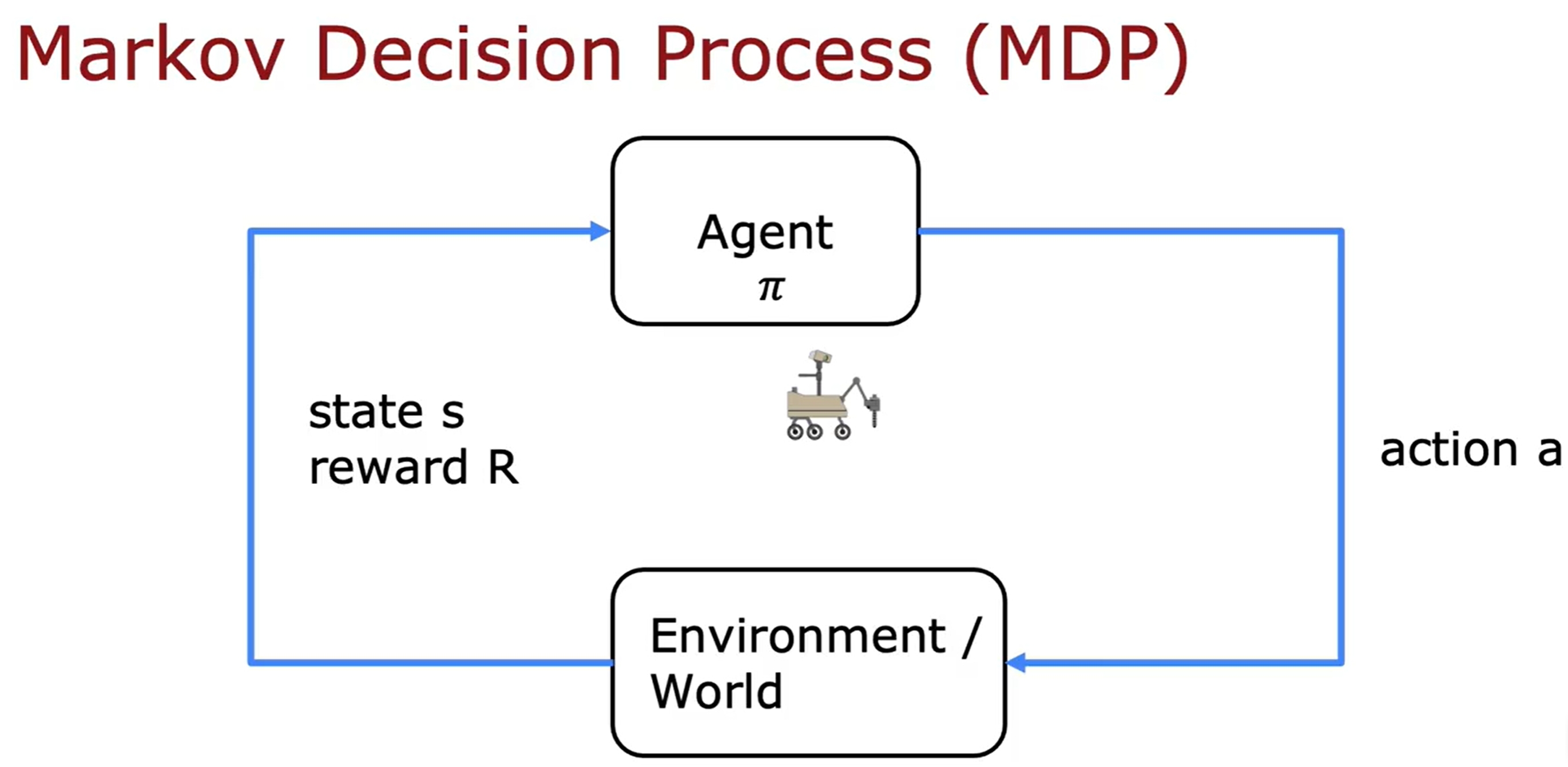
State-action value function/Q-function

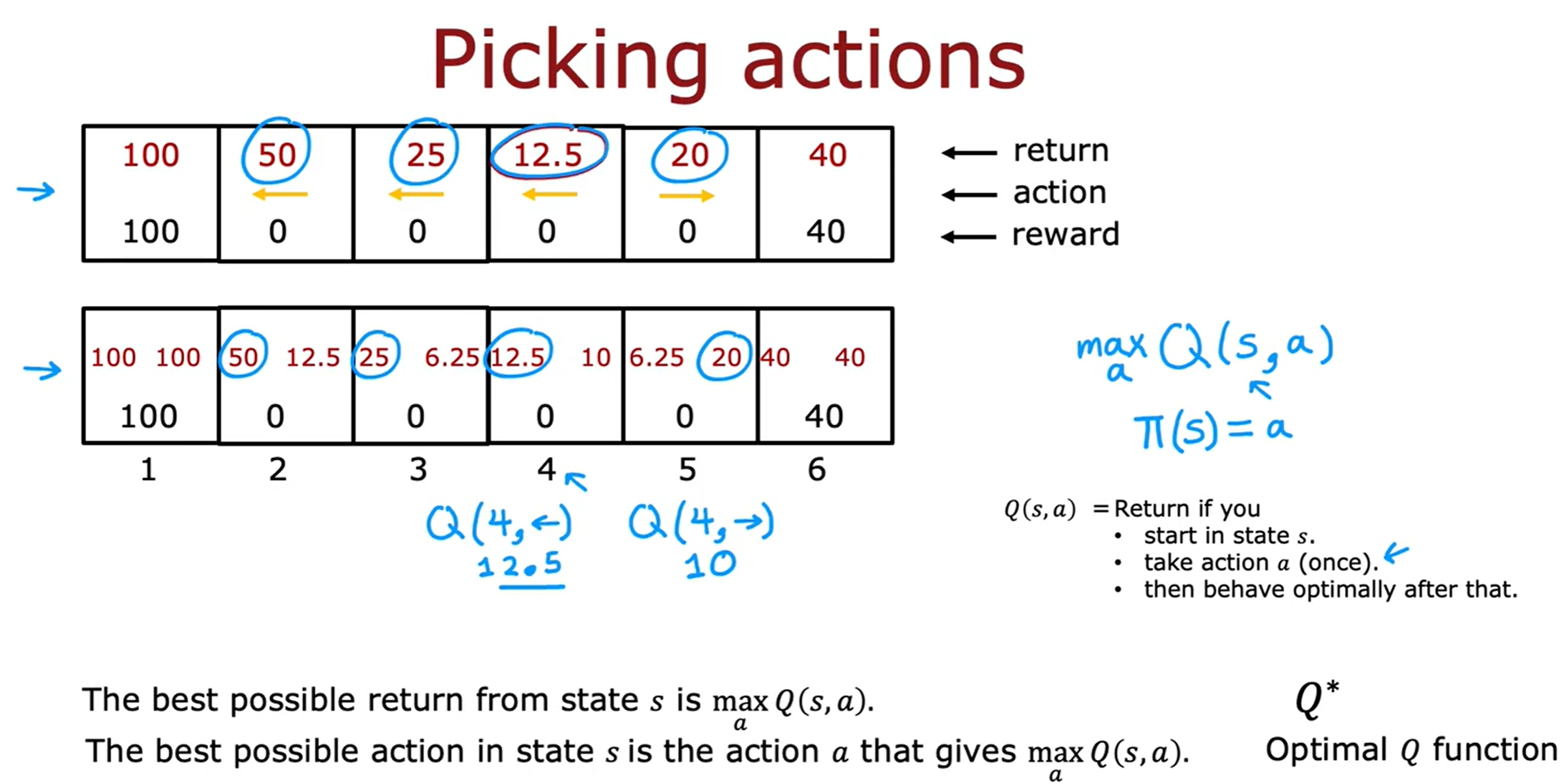
Bellman方程
Bellman方程是用来计算Q-function的,也就是用来计算在某个state下采取某个action的return。如下图所示:




Deep Reinforcement Learning
训练一个神经网络来学习Q-function,也就是DQN(Deep Q-Network)。如下图所示:
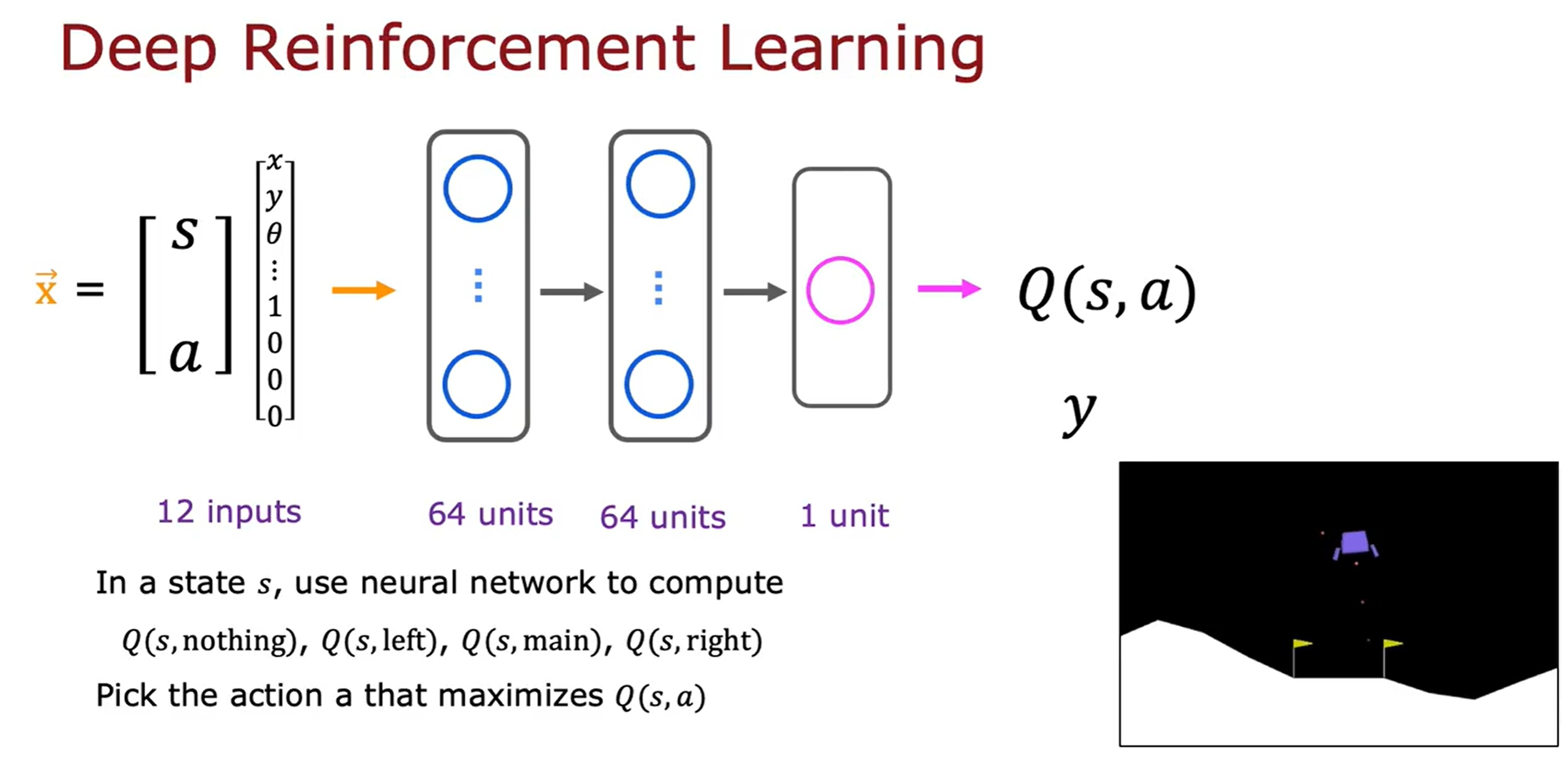


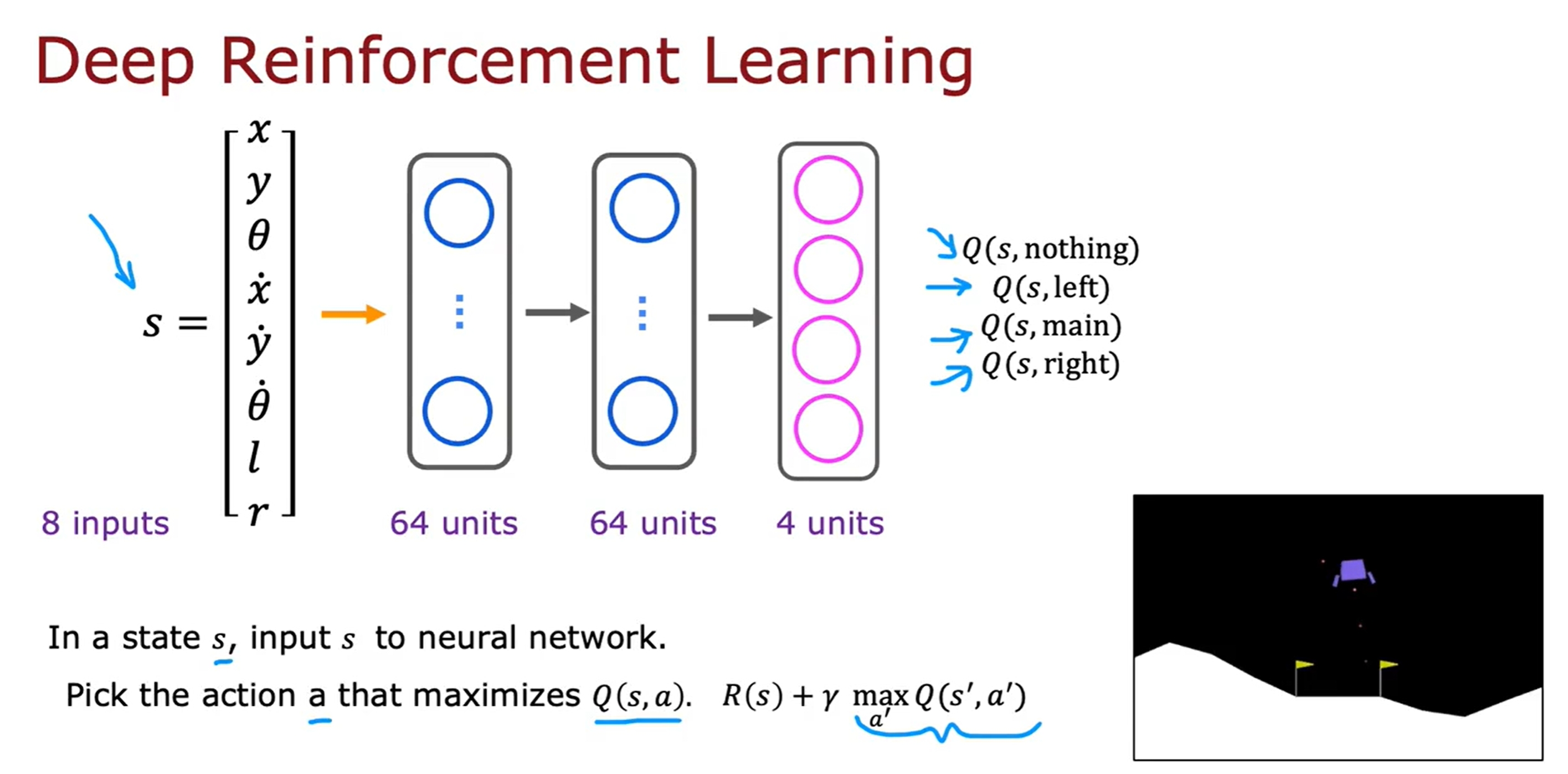
ϵ-贪婪策略
ϵ-贪婪策略是指在训练的过程中,以一定的概率ϵ来选择随机的action,而不是根据Q-function来选择action(这样可以避免由于初始化不够好导致陷入局部最优)。如下所示:

Mini-batch与soft updates
此处提供两个策略来提升模型的性能,一个是mini-batch,一个是soft updates。
当样本量很大时,可以通过mini-batch的方式来训练模型(将全部数据分为若干个batch),而不是一次性全部输入。如下图所示:
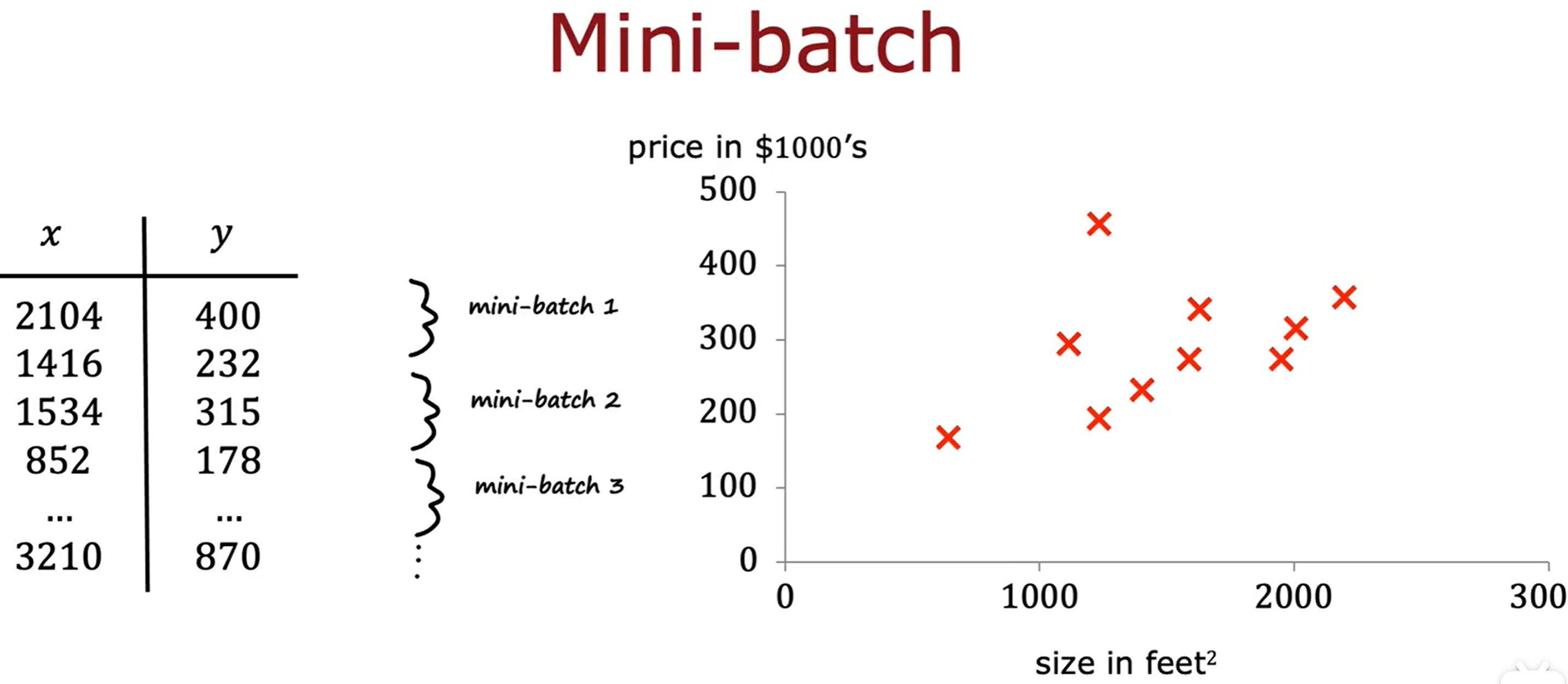

而所谓的soft updates是指每次更新模型的时候,不是直接将新的Q-function替换掉旧的,而是通过一个参数来控制新旧Q-function的比例。如下图所示:

基于强化学习的实验代码
Deep Learning
由于篇幅有限,关于Deep Learning的内容将在博客中详细介绍。
Artifical General Intelligence (AGI)
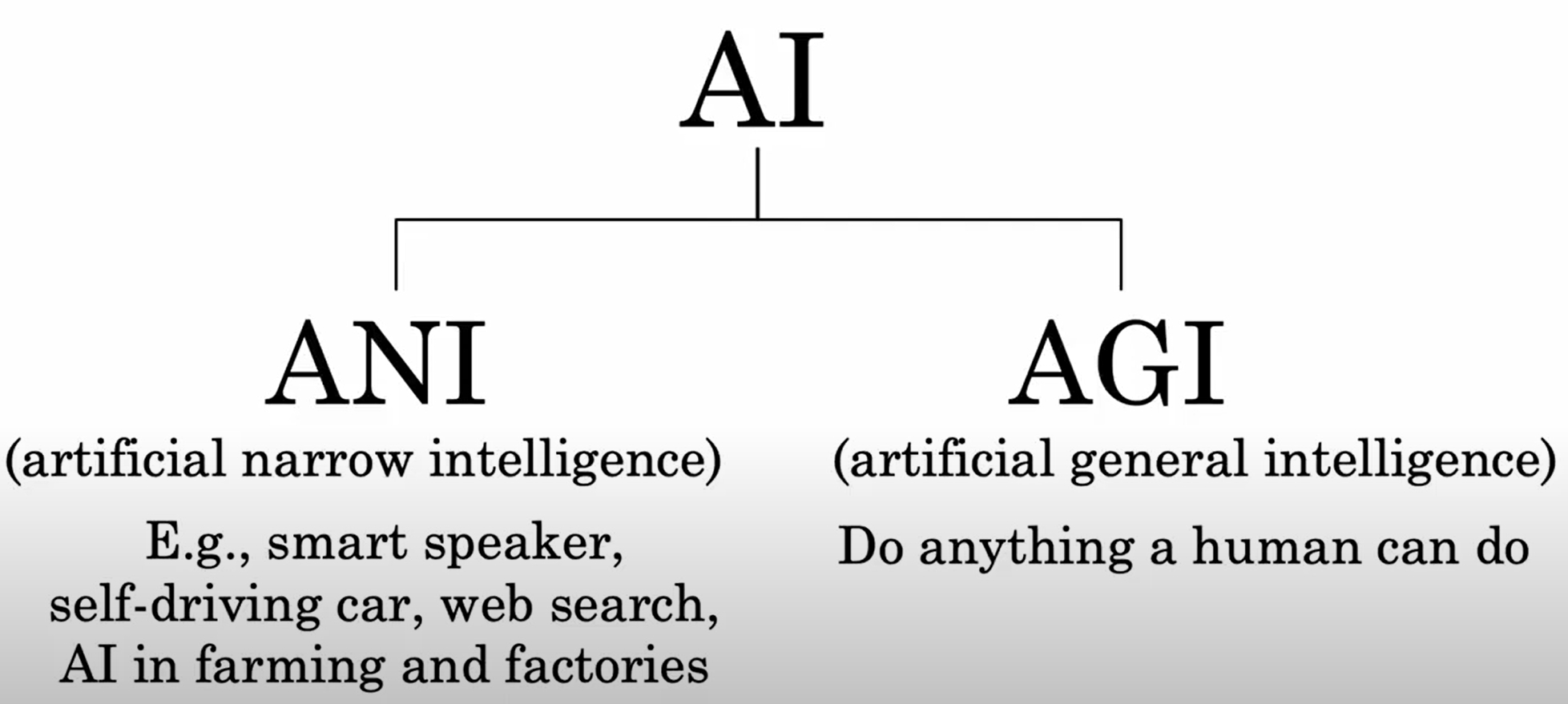
参考资料
- 机器学习(Machine Learning)- 吴恩达(Andrew Ng)
- 2024公认最好的 | 吴恩达机器学习
- B站更全的2022-Machine-Learning-Specialization
- Stanford CS229: Machine Learning Full Course taught by Andrew Ng | Autumn 2018
- 机器学习笔记目录
- 机器学习课程代码参考
- 机器学习课程代码参考2
- 2022-Machine-Learning-Specialization
- Machine-Learning-Specialization-Coursera
- deep learning- 吴恩达(Andrew Ng)
- Stanford CS230: Deep Learning | Autumn 2018
- coursera-deep-learning-specialization
- 深度学习笔记目录