
二叉树的种类:

二叉树解题的思维模式分两类:
1、是否可以通过遍历一遍二叉树得到答案?如果可以,用一个 traverse 函数配合外部变量来实现,这叫「遍历」的思维模式。
2、是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案?如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值,这叫「分解问题」的思维模式。
无论使用哪种思维模式,你都需要思考:
如果单独抽出一个二叉树节点,它需要做什么事情?需要在什么时候(前/中/后序位置)做?其他的节点不用你操心,递归函数会帮你在所有节点上执行相同的操作。
二叉树的所有问题,就是让你在前中后序位置注入巧妙的代码逻辑,去达到自己的目的,你只需要单独思考每一个节点应该做什么,其他的不用你管,抛给二叉树遍历框架,递归会在所有节点上做相同的操作。
二叉树的遍历方式
DFS深度优先遍历
DFS深度优先遍历:先往深走,遇到叶子节点再往回走。
分为:
前序遍历(递归法,迭代法);
中序遍历(递归法,迭代法);
后序遍历(递归法,迭代法);
这里前中后,其实指的就是中间节点的遍历顺序,只要记住:前中后序指的就是中间节点的位置就可以了。
三道题看二叉树的前中后序遍历
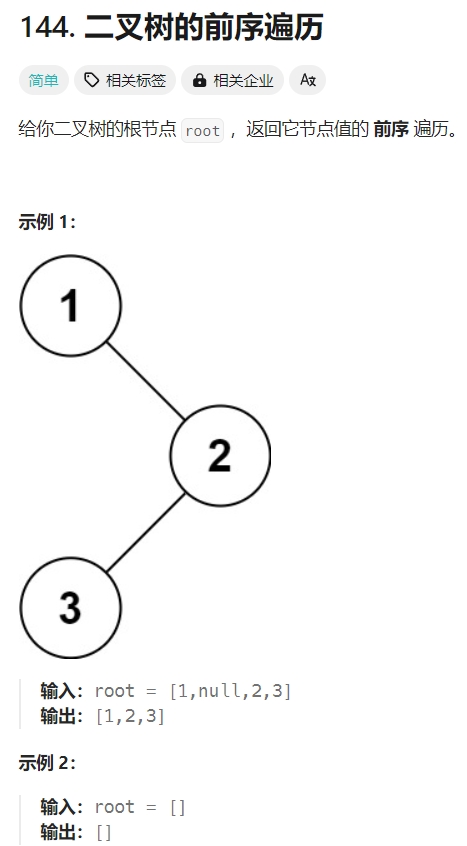
根据首页图片中关于二叉树遍历的思路,用递归解题。时间复杂度和空间复杂度都是O(N):
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void calculate(TreeNode* root, vector<int> &result)//注意以地址的方式来传递参数
{
if(root==nullptr)
return;
result.push_back(root->val);//前序遍历的位置
calculate(root->left,result);
calculate(root->right,result);
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
//用递归的形式去解算
calculate(root, result);
return result;
}
};
此外,也可以用栈解题。时间复杂度也是O(N)
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
// 解法:用堆栈的形式,复杂度为O(N)
stack<TreeNode*> stack_tree;
//要先确保root不为空指针
if(root==nullptr)
return result;
stack_tree.push(root);
while(!stack_tree.empty())//当堆不为空,那就是还有,所以继续
{
TreeNode* top=stack_tree.top();//获取栈顶
stack_tree.pop();
result.push_back(top->val);//放入
// 通过测试来判断顺序~
if(top->right!=nullptr)
stack_tree.push(top->right);
if(top->left!=nullptr)
stack_tree.push(top->left);
}
return result;
}
};
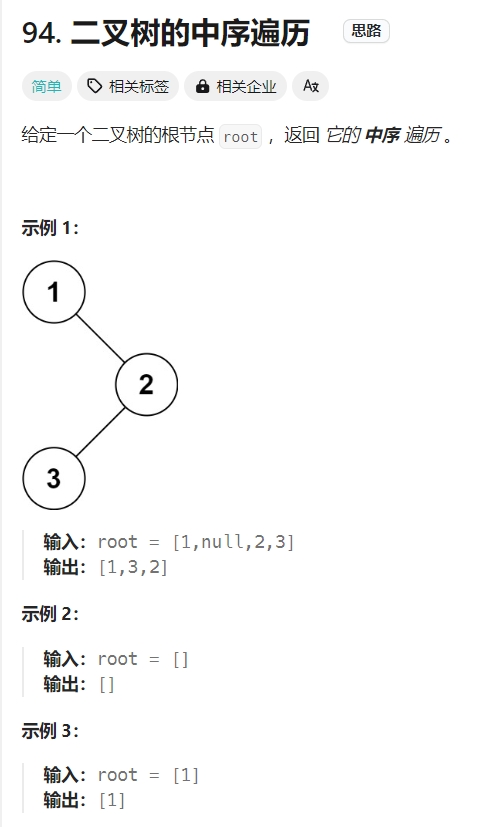
用递归解题最直接,复杂度跟上面一样,放对了递归的位置,结果就自然出来了~
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
void calculate(TreeNode* root, vector<int> &result)
{
if(root==nullptr)
return;
calculate(root->left,result);
result.push_back(root->val);//注意位置
calculate(root->right,result);
}
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
// 解法1:递归(中序遍历就是先左后中再右,从例子中,3才到2,所以先3)
calculate(root,result);
return result;
}
};
也可以采用栈的思路去解题,但是相对复杂一些,要考虑细致读取顺序
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
vector<int> result;
// 解法2:堆栈
stack<TreeNode*> stack_int;
while(!stack_int.empty() || root!=nullptr)
{
//从最左开始,左中右
while(root!=nullptr)
{
stack_int.push(root);
root=root->left;//相当与先将所有的左节点放入栈中,直到根节点
}
root=stack_int.top();//获取栈顶
stack_int.pop();//删掉
result.push_back(root->val);
root = root->right;//下一次就从它的右边开始检查~
}
return result;
}
};

Click to expand the code
深入理解前中后序
void traverse(TreeNode* root) {//其实就是一个能够遍历二叉树的函数(类似于链表)也就是一个递归
if (root == nullptr) {
return;
}
// 前序位置
traverse(root->left);
// 中序位置
traverse(root->right);
// 后序位置
}
所谓前序位置,就是刚进入一个节点(元素)的时候,而后序位置就是即将离开一个节点(元素)的时候。
如下图所示:
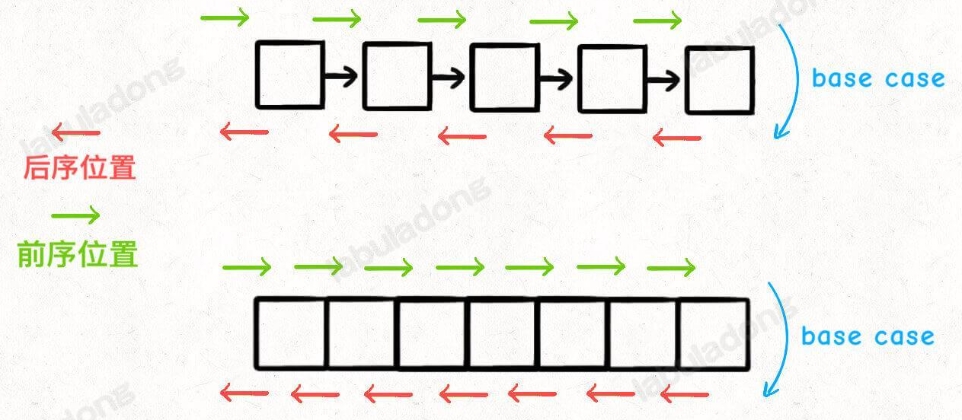
后序位置的代码在将要离开一个二叉树节点的时候执行;(中序遍历:左中右)
中序位置的代码在一个二叉树节点左子树都遍历完,即将开始遍历右子树的时候执行。(后序遍历:左右中)
所谓的前中后,其实指的就是中间节点的遍历顺序。如下图所示:
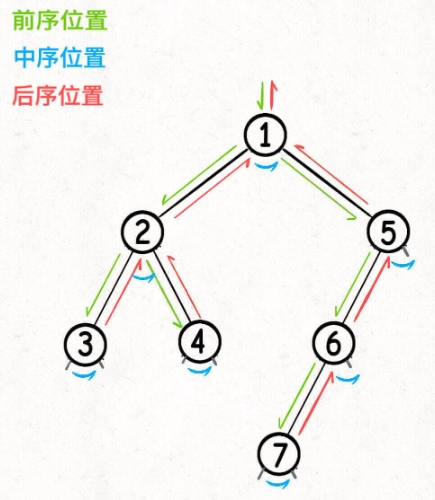
对于递归遍历(DFS)本质上就是递归算法。也就说博客Link中提到的大部分二叉树的算法都可以用递归来解决的缘由。上面介绍的前中后序遍历都是递归遍历的一种。
当然,除了使用递归也可以采用栈的方式来解决,这样的话就是迭代法。此处不做深入介绍,请见Link。
二叉树的直径
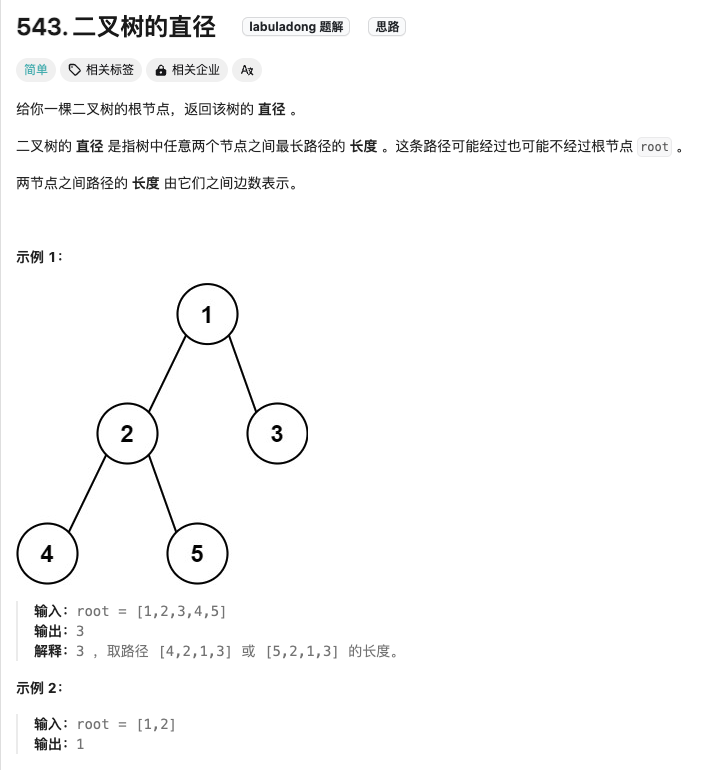
Click to expand the code。其实只是在二叉树的最大深度的基础上的一个小拓展而已~
平衡二叉树
Click to expand the code.DFS跟统计高度/深度基本一样,只是当两边高度差不符合的时候返回-1,而-1就是对应false,其余都是true
左叶子之和
Click to expand the code。注意题目要求的只是左子叶的和。采用前序遍历
Click to expand the code.另外一种写法(采用后序遍历)
二叉树的构造
二叉树的构造问题一般都是使用「分解问题」的思路:构造整棵树 = 根节点 + 构造左子树 + 构造右子树。
从中序与后序遍历序列构造二叉树
Click to expand the code.图片解析见下图。这题其实不难,关键是理解清楚后序与中序遍历相对的位置。而构建的节点以及分割数组都是在前序位置进行的。
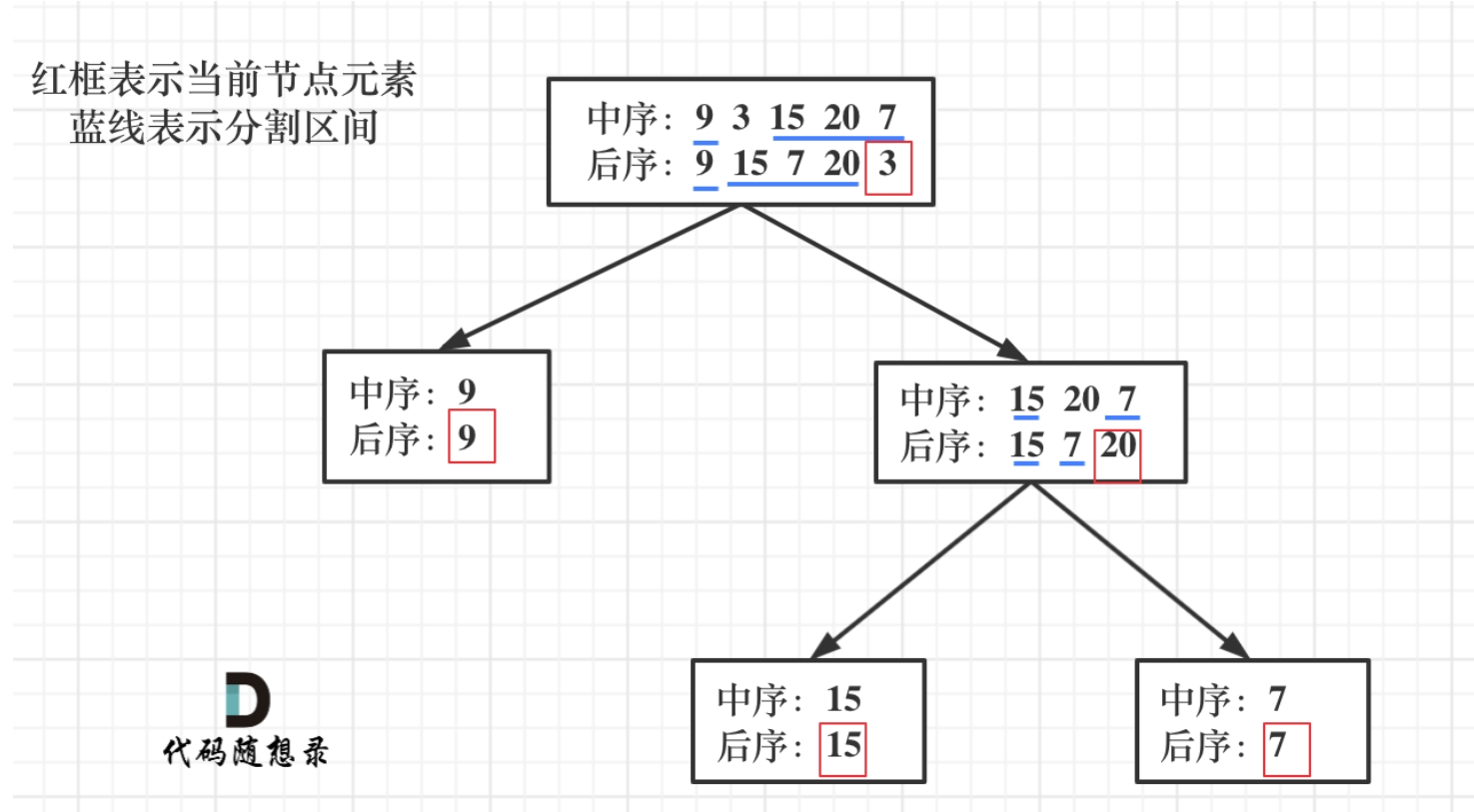
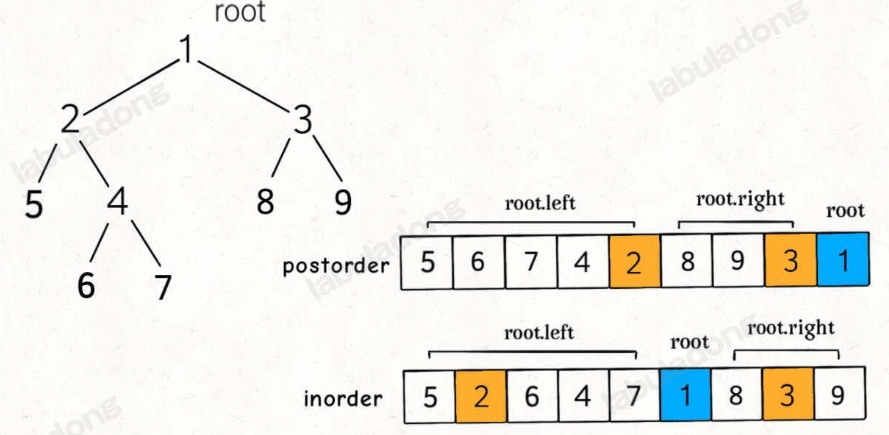
分为以下几步:
第一步:如果数组大小为零的话,说明是空节点了。
第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
第五步:切割后序数组,切成后序左数组和后序右数组
第六步:递归处理左区间和右区间
从前序与中序遍历序列构造二叉树
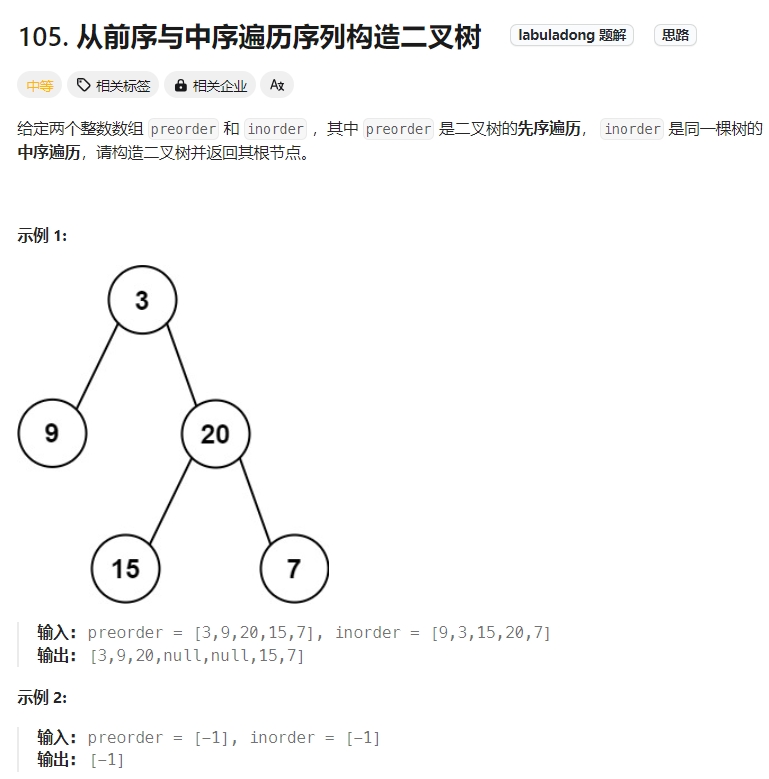
Click to expand the code。此题跟上一题基本是一样的,不一样的只是前序遍历是第一个值
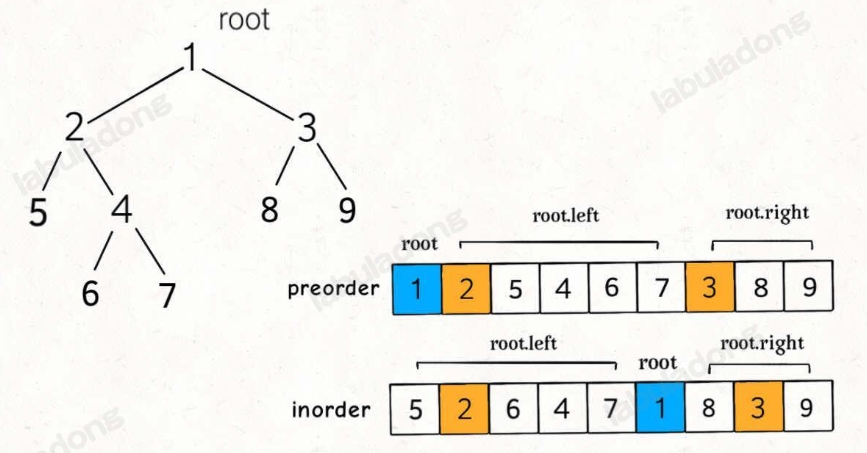
Tips🙋通过上面两道题,前序和中序可以唯一确定一棵二叉树;而后序和中序也可以唯一确定一棵二叉树。但是,前序和后序不能唯一确定一棵二叉树!,因为没有中序遍历无法确定左右部分,也就是无法分割。但是leetcode上还是有这道题,为此是让返回其中任意一个答案
根据前序和后序遍历构造二叉树
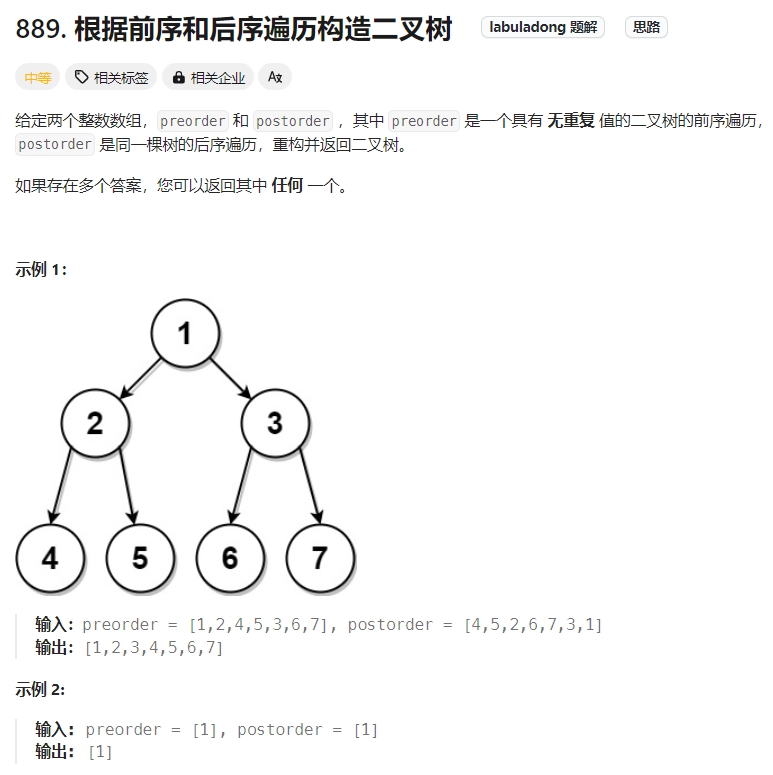
Click to expand the code。
1、首先把前序遍历结果的第一个元素确定为根节点的值(注意,这个值必然等于当前后序遍历结果的最后一个元素)。
2、然后把前序遍历结果的第二个元素作为左子树的根节点的值。
3、在后序遍历结果中寻找左子树根节点的值,从而确定了左子树的索引边界,进而可以对后序数组进行切割,分为左右子数组,再递归构造左右子树即可。
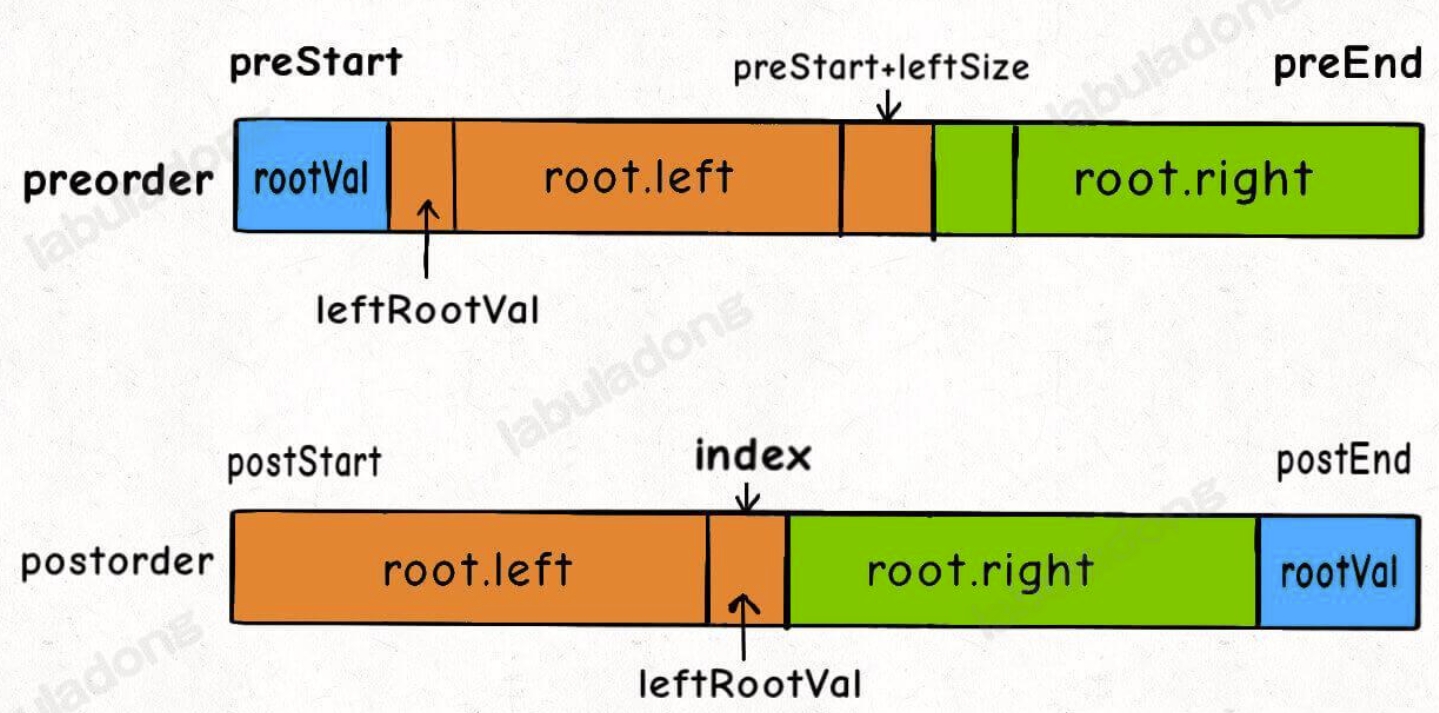
构造最大二叉树
Click to expand the code。跟上面两题很像,只是上面两题通过前序或后序列表先确定本节点的值及在中序的分割,但此题是通过最大值来确定的,然后把输入的数组看成是中序数组即可~
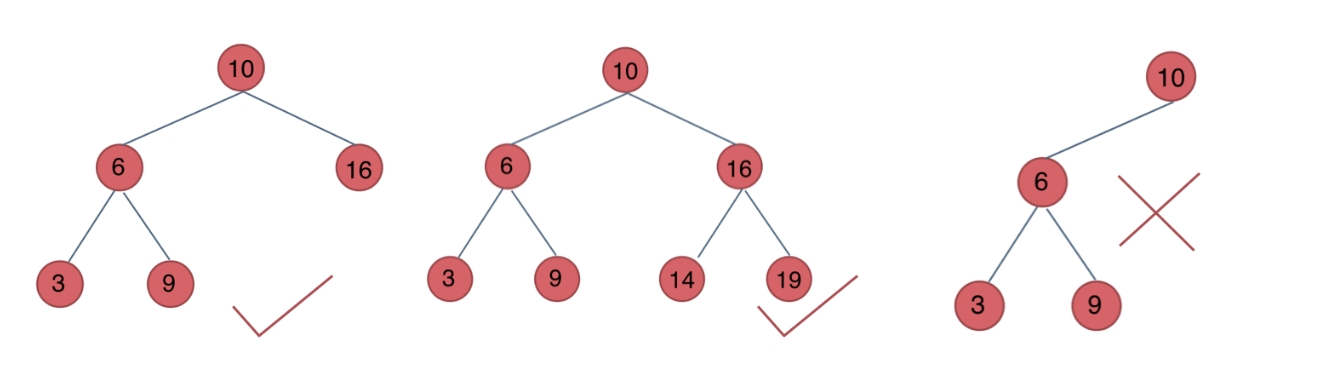
中序遍历解决二叉搜索树(Binary Search Tree, BST)
对于二叉搜索树(BST)它的中序遍历必然是有序的!!! 因此,遇到在二叉搜索树上求什么最值,求差值之类的,都要思考一下二叉搜索树可是有序的,进而转换为前中后序遍历。 同时在递归遍历的过程中记录前后两个指针,就可以实现对比
验证二叉搜索树
Click to expand the code.DFS,注意要求是左边子树的全部都要小于当前的节点,而并不仅仅判断当前的左右的大小!而细看题目的要求,实际上就是中序遍历,然后看该数组是否严格递增,如果是那么就是true
Click to expand the code。直接在dfs的时候判断,但是这种写法相对不好理解~
二叉搜索树的最小绝对差
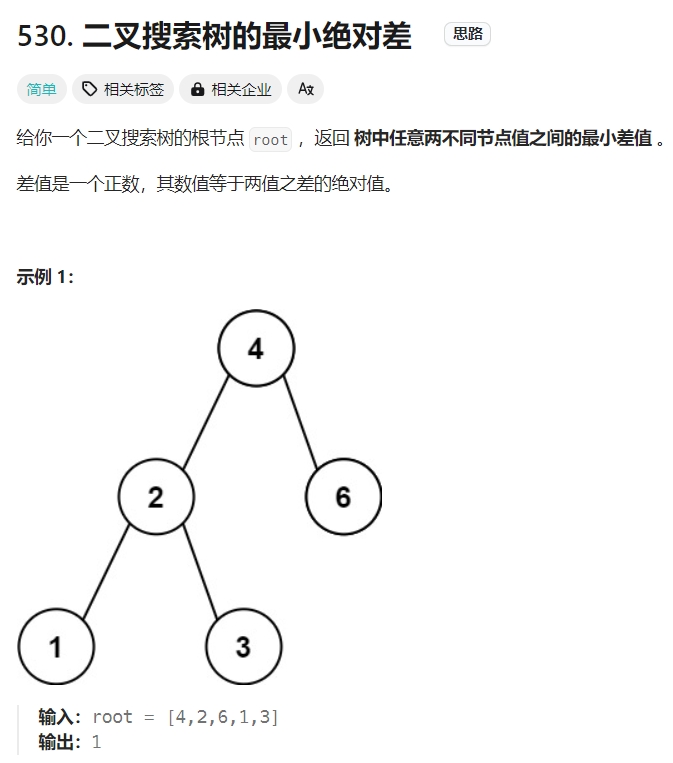
Click to expand the code。此题本质上也是一个中序遍历,求的就是中序遍历的数组两两之间的差值的最小值
二叉搜索树中的众数

Click to expand the code。最直接的解题思路如下。当然hash table记录的话放前中后序都一样
Click to expand the code。上面的解决思路其实是对于普通的二叉树是通用的,但是由于本题是二叉搜索树,为此它的中序遍历必然是有序的,那么就很自然而然通过计数法就可以得到众数!
此外,需要注意的是:关于计数次数的更新不能写入pre!=nullptr中,因为会存在只有一个数也就是pre为空的情况
二叉搜索树中的搜索
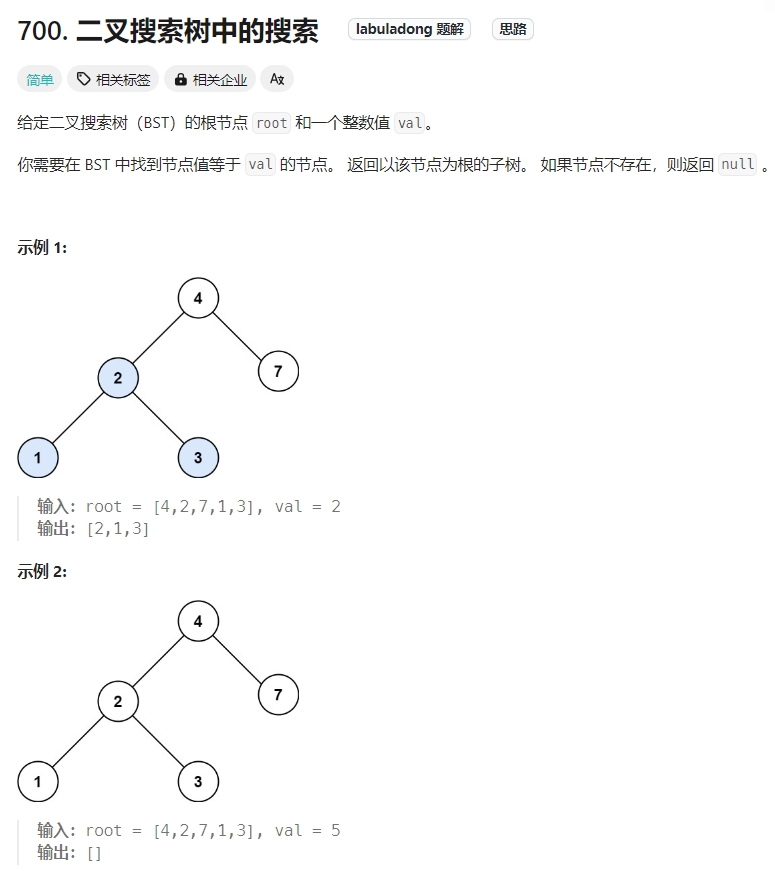
Click to expand the code。DFS,应该是后序遍历,在后序的位置处理
Click to expand the code。采用BFS
Click to expand the code.上面两种解题的思路其实都是适用于普通的二叉树的,对于二叉搜索树,其实更加简单些
二叉搜索树中的插入操作
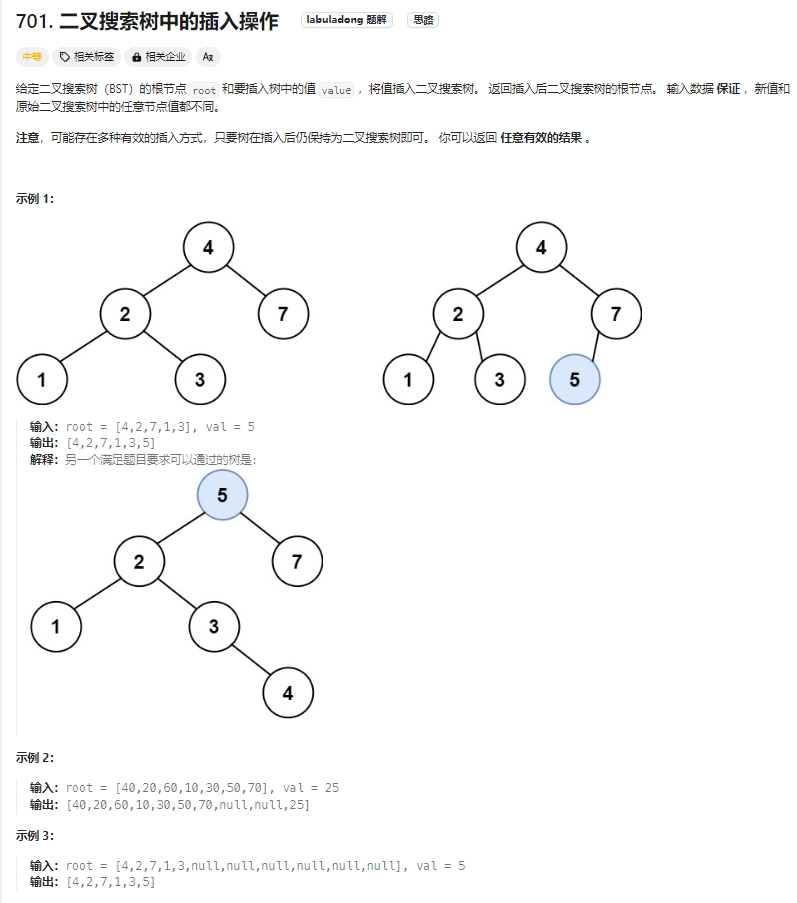
Click to expand the code。注意只需要给出一个合理结果即可,因此不需要考虑题目中提示所说的改变树的结构的插入方式,只要按照二叉搜索树的规则去遍历,遇到空节点就插入节点就可以了。
同时注意!BST是有序的,因此并不需要全部遍历,根据插入元素的数值,决定递归方向。
此外,通过递归函数返回值完成了新加入节点的父子关系赋值操作了,下一层将加入节点返回,本层用root->left或者root->right将其接住。
Click to expand the code。不带返回值的写法如下
Click to expand the code。更简单的,带引用地址传指针,连上一个值也无需保留处理,因为递归决定方向的时候已经做了!
删除二叉搜索树中的节点
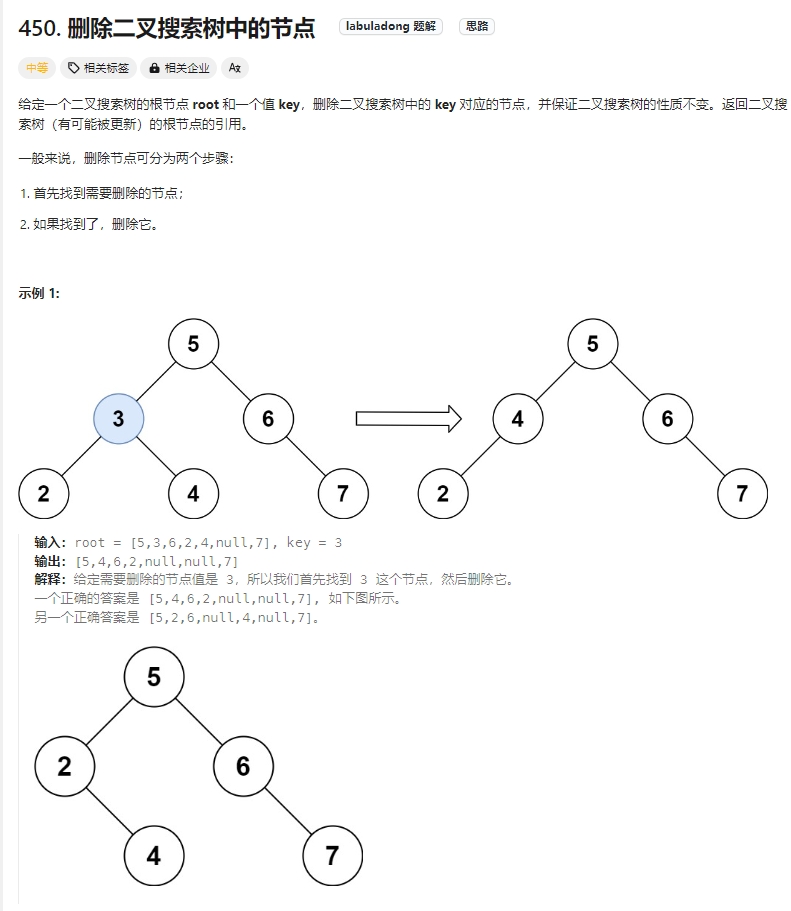
Click to expand the code.
对于二叉搜索树中,删除节点,涉及到二叉树的结构调整,故此有以下5种情况:
1、没找到删除的节点,遍历到空节点直接返回了。
2、左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点。
3、删除节点的左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点。
4、删除节点的右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点。
5、左右孩子节点都不为空,则将删除节点的左子树头结点(左孩子)放到删除节点的右子树的最左面节点的左孩子上(这样就可以保证满足BST的特性),返回删除节点右孩子为新的根节点。
修剪二叉搜索树
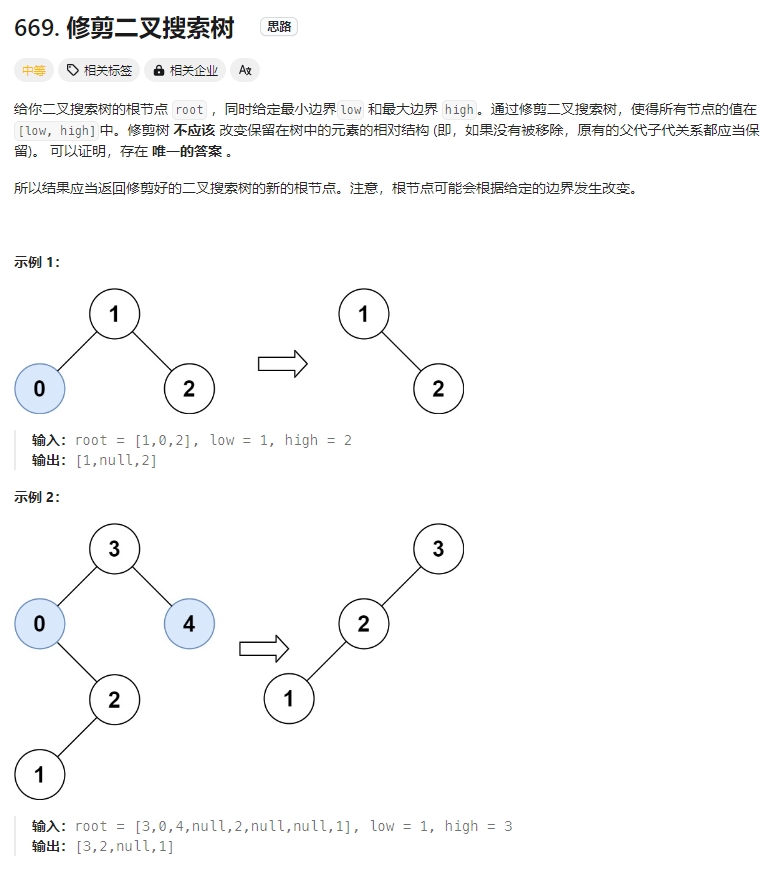
Click to expand the code
将有序数组转换为二叉搜索树
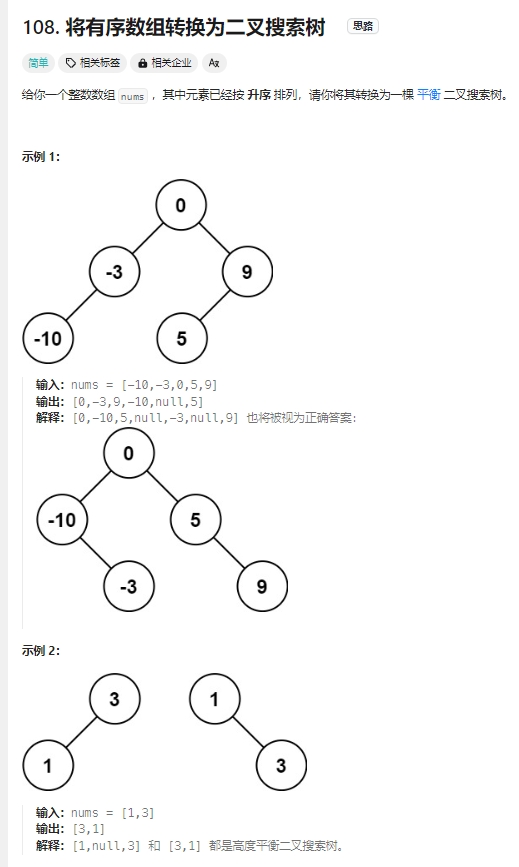
Click to expand the code。不断中间分割,然后递归处理左区间,右区间,类似二分法
逆向中序遍历: 把二叉搜索树转换为累加树
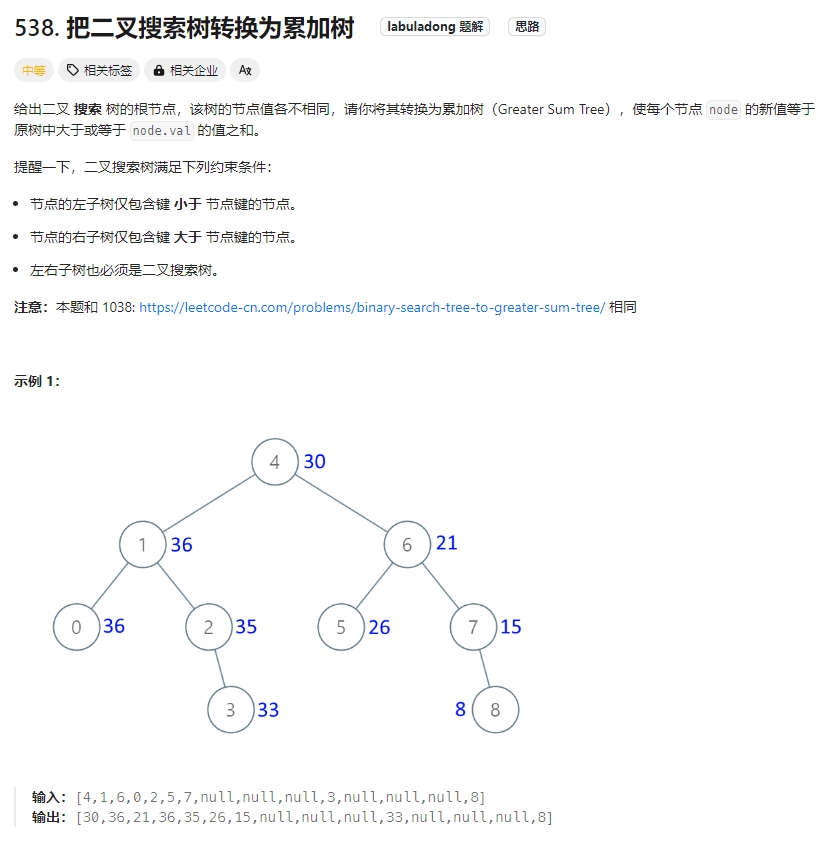
Click to expand the code.对于BST本质上就是有序数组。那么换个角度来看。一个有序数组[2, 5, 13],求从后到前的累加数组,也就是[20, 18, 13]。故此对于BST也应该是从后向前一直遍历累加。中序遍历是左中右。那么此处的反过来遍历应该是右中左。
逆向中序遍历,此题跟《1038.从二叉搜索树到更大和树》一模一样
二叉搜索树中第 K 小的元素
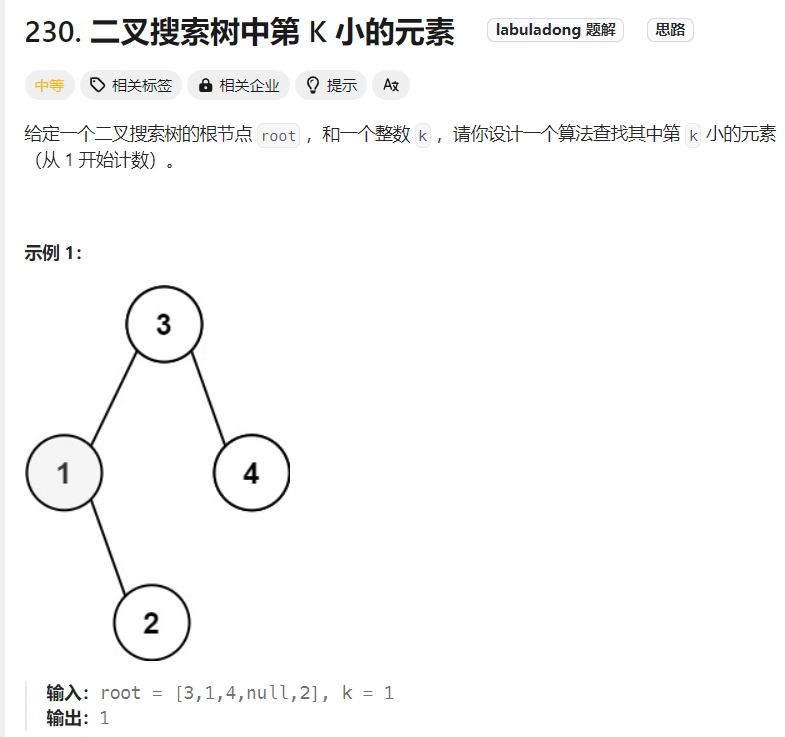
Click to expand the code
Click to expand the code。另外一种写法
后序遍历解最近公共祖先系列(Lowest Common Ancestor,LCA)
这个其实也是git push与merge的基本原理了。
1.求最小公共祖先,需要从底向上遍历,那么二叉树,只能通过后序遍历(即:回溯)实现从底向上的遍历方式。
2.在回溯的过程中,必然要遍历整棵二叉树,即使已经找到结果了,依然要把其他节点遍历完,因为要使用递归函数的返回值(也就是代码中的left和right)做逻辑判断。
3.要理解如果返回值left为空,right不为空为什么要返回right,为什么可以用返回right传给上一层结果。
二叉树的最近公共祖先

Click to expand the code.首先后序遍历实现了自下而上的过程,根据目前左右节点的情况来往前推断。
而递归的终止就是直到跟节点或找到p或q开始从下而上。
而注意p和q必然会出现且只会出现一次,因此当找到了最近处左右都不为空的情况,返回了当前的节点,那么就是最近的祖先了。而之后是不会再存在左右不为空的情况了。
更详细的分析请参考博客:代码随想录。
二叉搜索树的最近公共祖先

Click to expand the code.首先对于二叉搜索树(BST)满足中序遍历有序,而对于公共祖先,需要后序遍历从底而上。
因为是有序树,所以 如果 中间节点是 q 和 p 的公共祖先,那么 中节点的数组 一定是在 [p, q]区间的。即 中节点 > p && 中节点 < q 或者 中节点 > q && 中节点 < p。
Click to expand the code。当然直接用上一题的思路去解决也可以
除了上面两题以外,Leetcode上还有三道LCA的题目,分别是: 1644, 1650, 1676。 但是均要会员才可以看到题目,后面有机会再补充吧hhh
BFS广度优先遍历
BFS广度优先遍历:一层一层的去遍历.
层次遍历(迭代法)
对于二叉树的层序遍历,就是从左到右一层一层的去遍历二叉树。
这种遍历方式通常需要借助队列来实现。队列先进先出,符合一层一层遍历的逻辑,而用栈先进后出适合模拟深度优先遍历也就是递归的逻辑(故此上面DFS也有给出栈解法,只是递归前中后序更直接~)。
代码框架如下 :
void levelOrderTraverse(TreeNode* root) {
//当到终点的时候就返回
if (root == nullptr) {
return;
}
// 初始化队列,将根节点加入队列
std::queue<TreeNode*> q;
q.push(root);
while (!q.empty()) {
TreeNode* cur = q.front();//获取队列的头
q.pop();//删除队列的头
// 访问 cur 节点
std::cout << cur->val << std::endl;
// 把 cur 的左右子节点加入队列
if (cur->left != nullptr) {
q.push(cur->left);
}
if (cur->right != nullptr) {
q.push(cur->right);
}
}
}
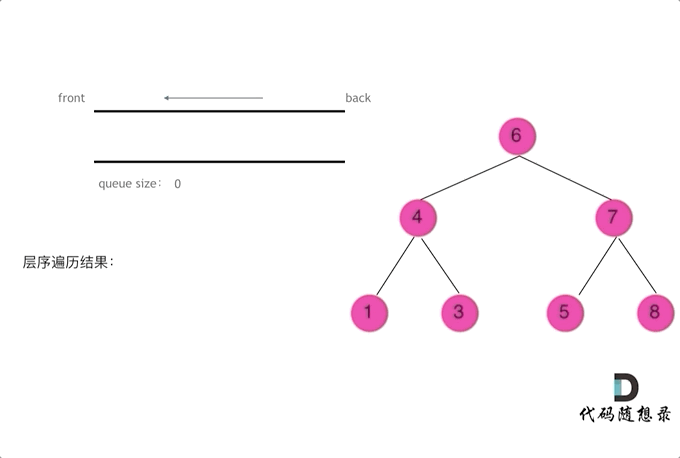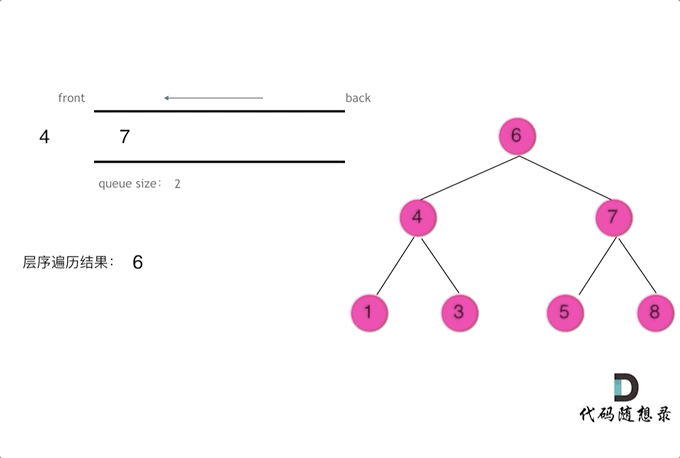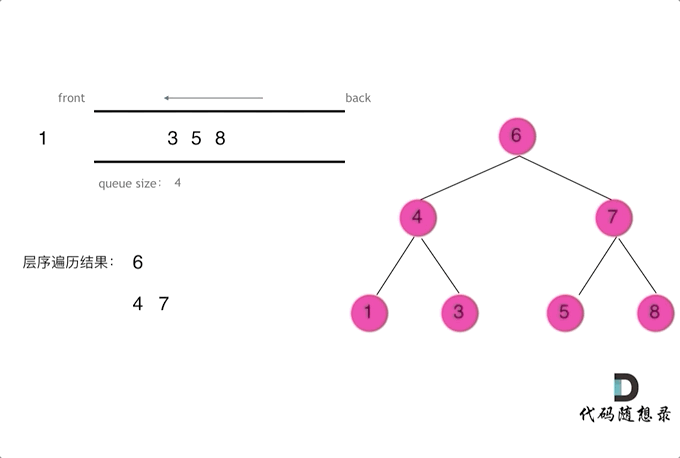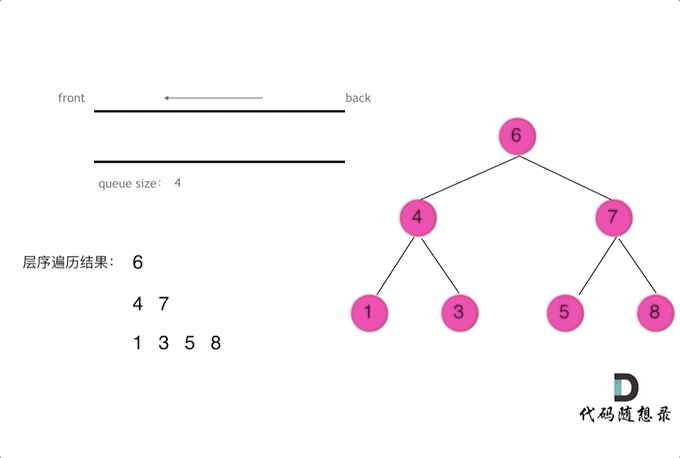
二叉树的层序遍历
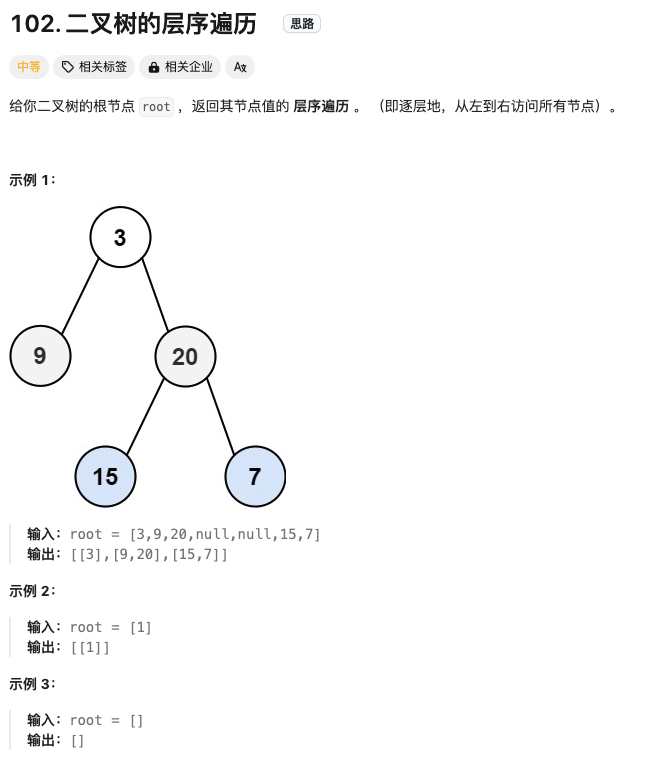
Click to expand the code。采用队列进行层序遍历,注意检查是否为空再放入队列中
二叉树的层次遍历 II
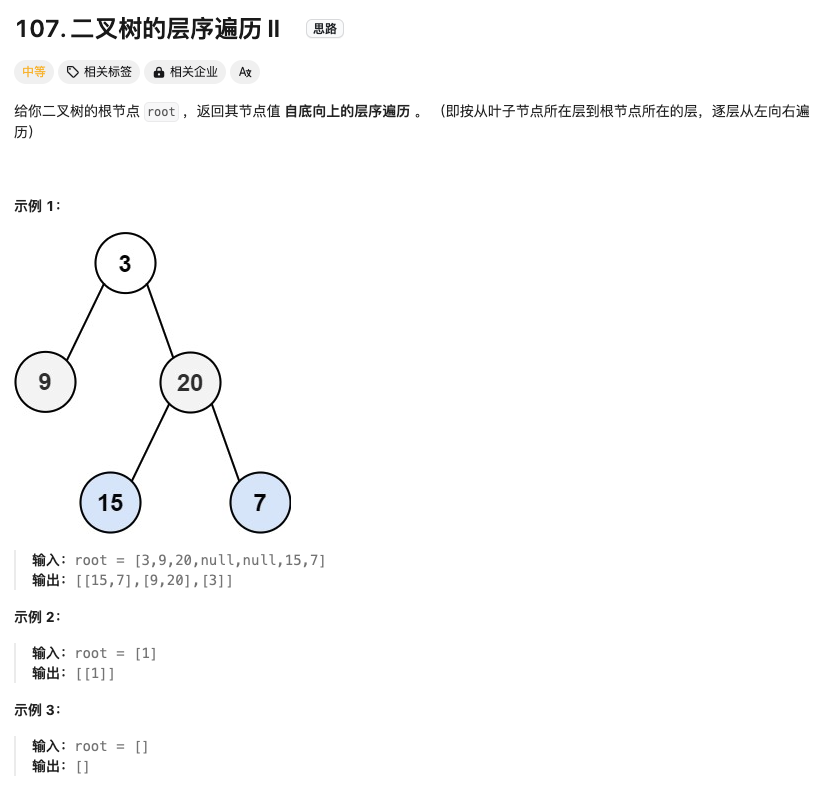
Click to expand the code。跟上题一样,只是结果加个反转
二叉树的右视图
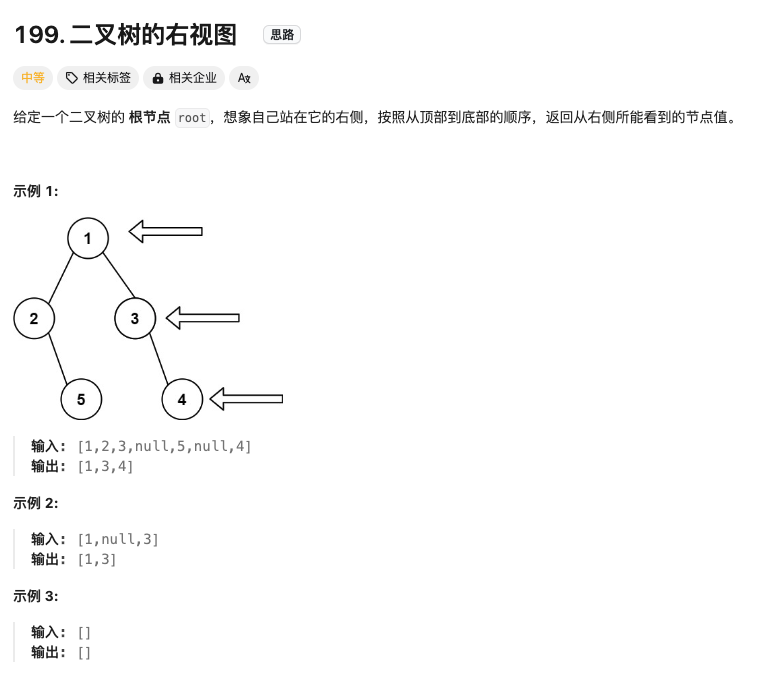
Click to expand the code。同样是层序遍历,不过只看最后一个节点(注意是最后一个,不一定是右侧的)
二叉树的层平均值
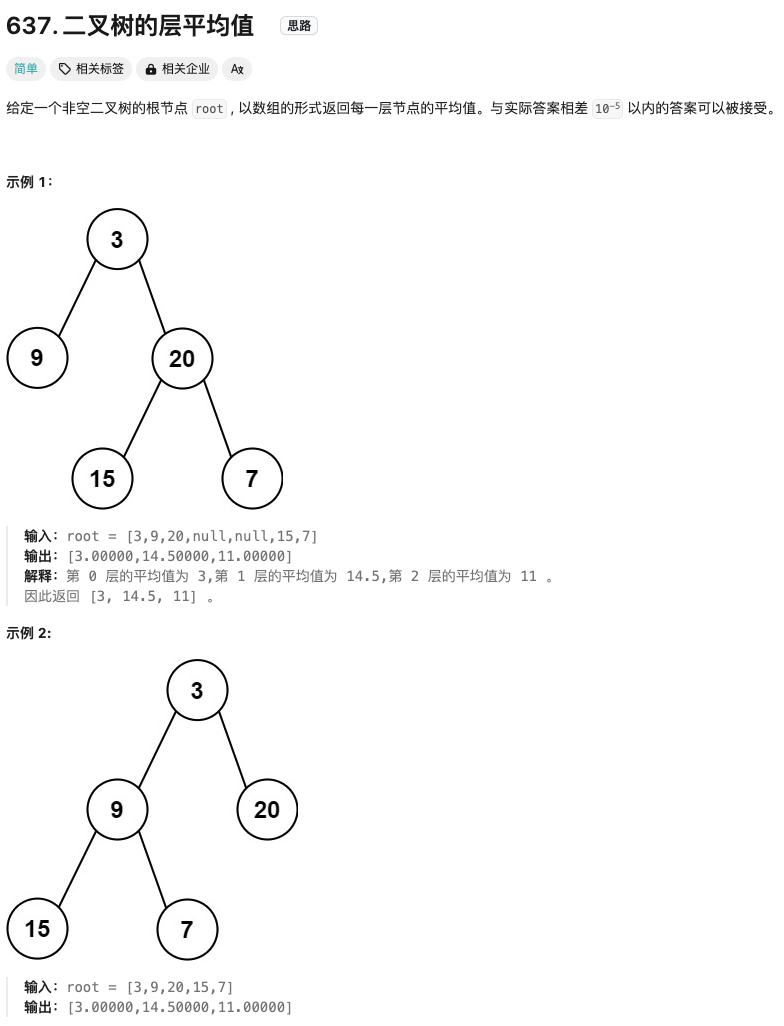
Click to expand the code
N叉树的层序遍历
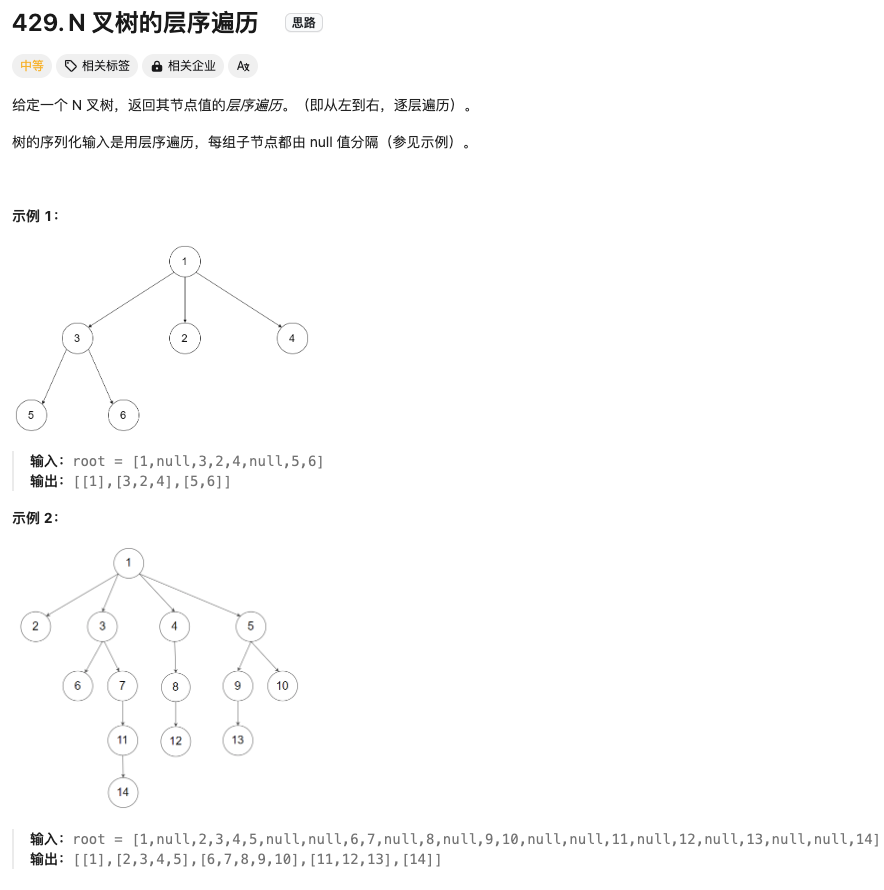
Click to expand the code。N叉树只是二叉树的简单拓展~
在每个树行中找最大值
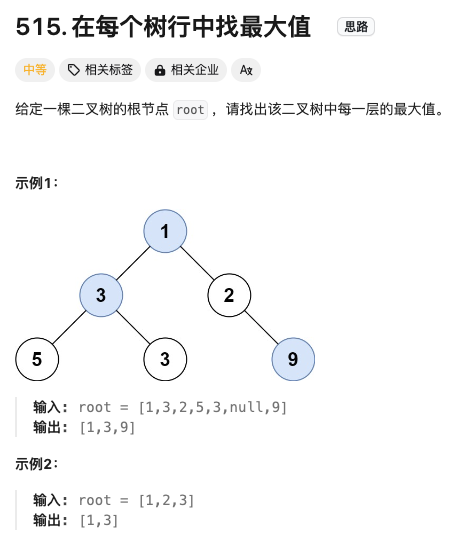
Click to expand the code
填充每个节点的下一个右侧节点指针

Click to expand the code。不要采用指针的思想,单纯把每个节点的next赋值即可
二叉树的最小深度
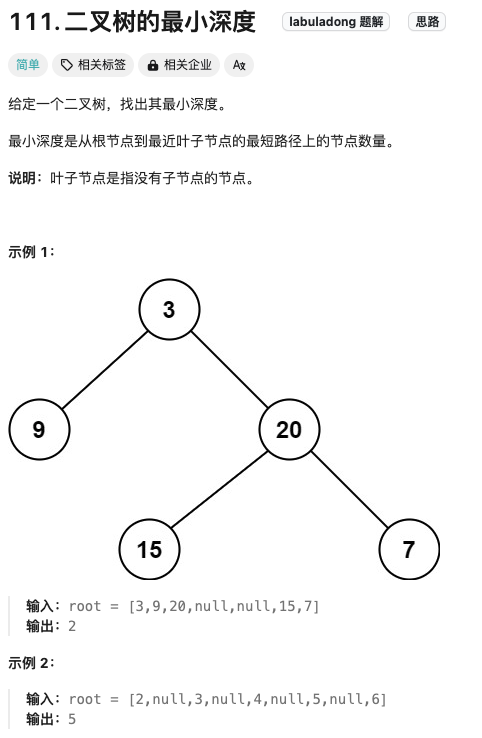
Click to expand the code。采用DFS,要注意区分空子树和非空子树。如果一个节点只有一个非空的子树,它的最小深度应该是非空子树的深度,而不是 0。
Click to expand the code。BFS解法。所谓的叶节点指的是左右两个子节点均为空~
找树左下角的值
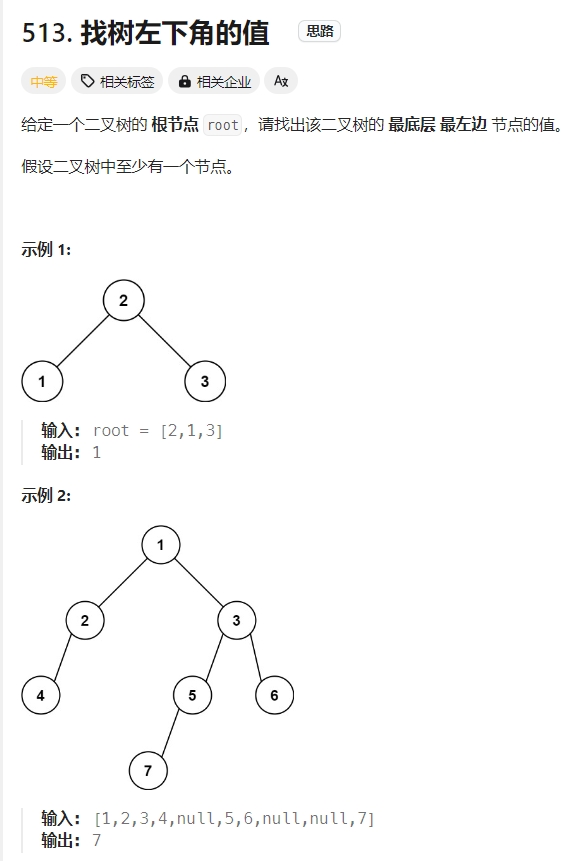
Click to expand the code。BFS
同时适用DFS与BFS两种解法
针对二叉树的问题,解题之前一定要想清楚究竟是前中后序遍历,还是层序遍历。前中后序遍历是DFS,层序遍历是BFS。当然部分的题目两种解法均可,下面给出样例。
翻转二叉树
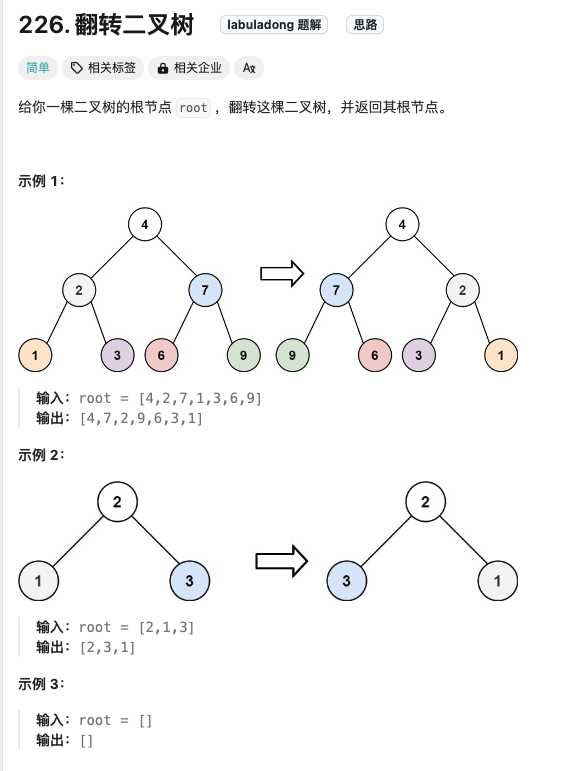
Click to expand the code,采用DFS来做
Click to expand the code。采用BFS
对称二叉树
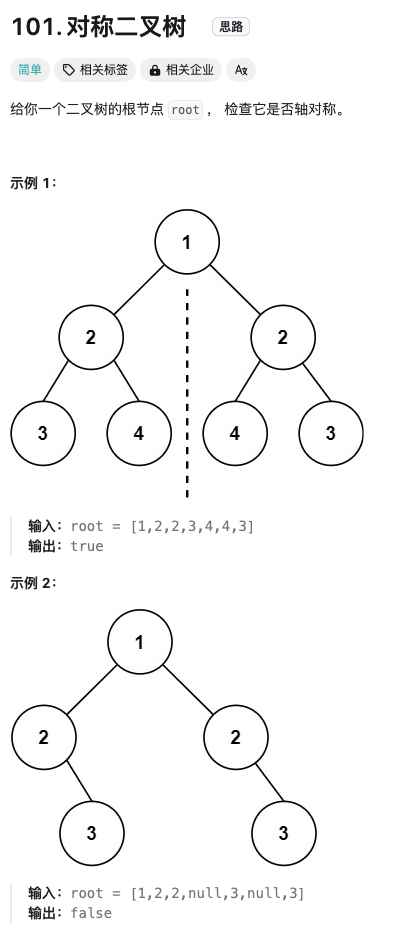
Click to expand the code。类似BFS的解题思路请见动图。注意对称是对比完一半再到另外一半
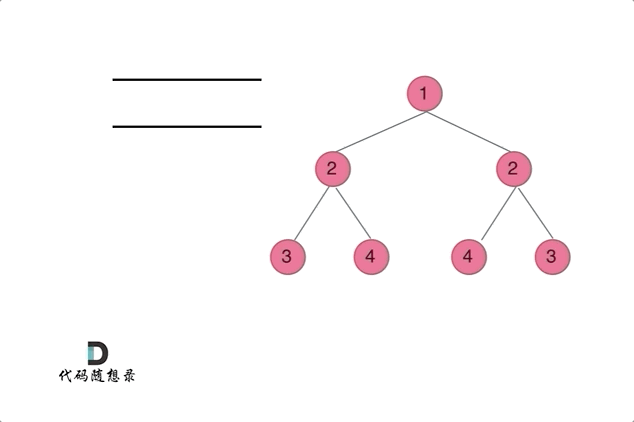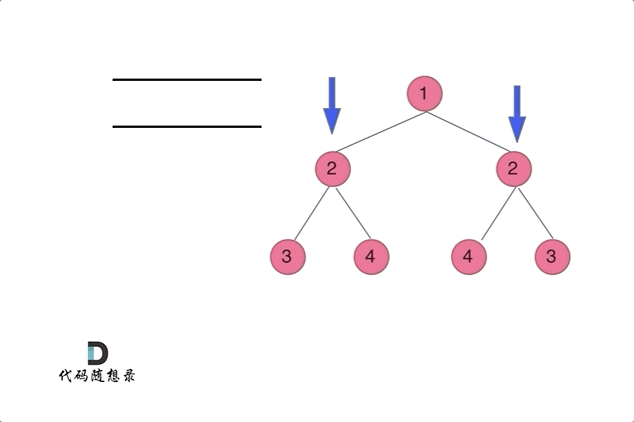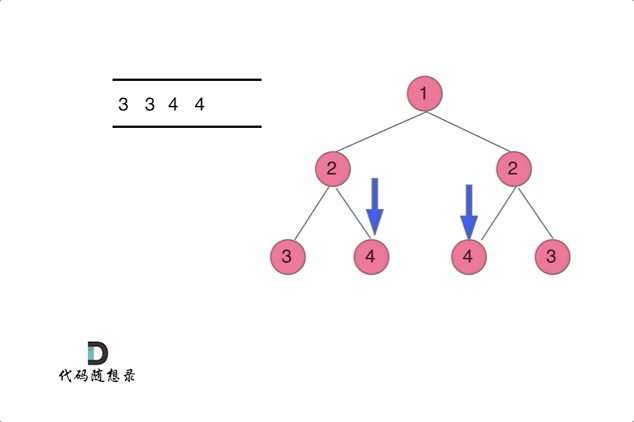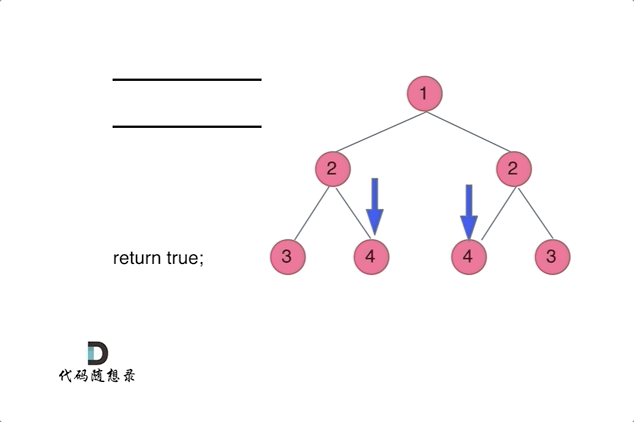
Click to expand the code。DFS的解法,注意只有在左右不同时为 nullptr 的情况下,才是不对称的。用 != 逻辑符号可能会导致空节点情况判断错误
二叉树的最大深度
时间复杂度:O(n),其中 n 为二叉树节点的个数。空间复杂度:O(height),其中 height 表示二叉树的高度。递归函数需要栈空间,而栈空间取决于递归的深度,
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int traverse(TreeNode* root)
{
if(root==nullptr)//到达跟节点
return 0;
//前序的位置
int left=traverse(root->left);//左侧的树的深度
//中序的位置
int right=traverse(root->right);//右侧的树的深度
//后序的位置
return max(left,right)+1;//// 整棵树的最大深度等于左右子树的最大深度取最大值。然后再加上根节点自己
//为什么在后序呢?
//要首先利用递归函数的定义算出左右子树的最大深度,
//然后推出原树的最大深度,主要逻辑自然放在后序位置。
}
int maxDepth(TreeNode* root) {
return traverse(root);
}
};
Click to expand the code。上面是DFS的解法,至于BFS的解法如下:
N叉树的最大深度
Click to expand the code。DFS写法
Click to expand the code。BFS写法
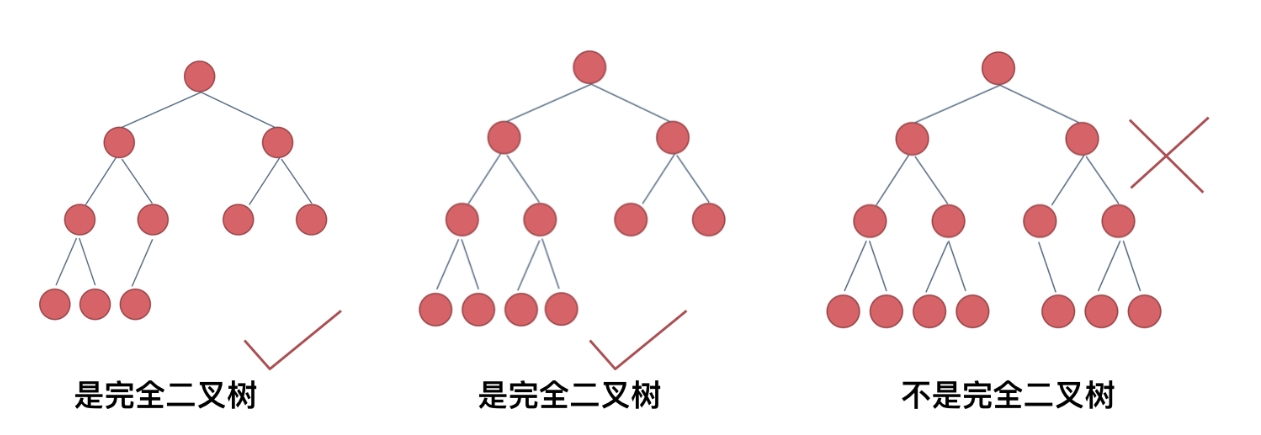
完全二叉树的节点个数
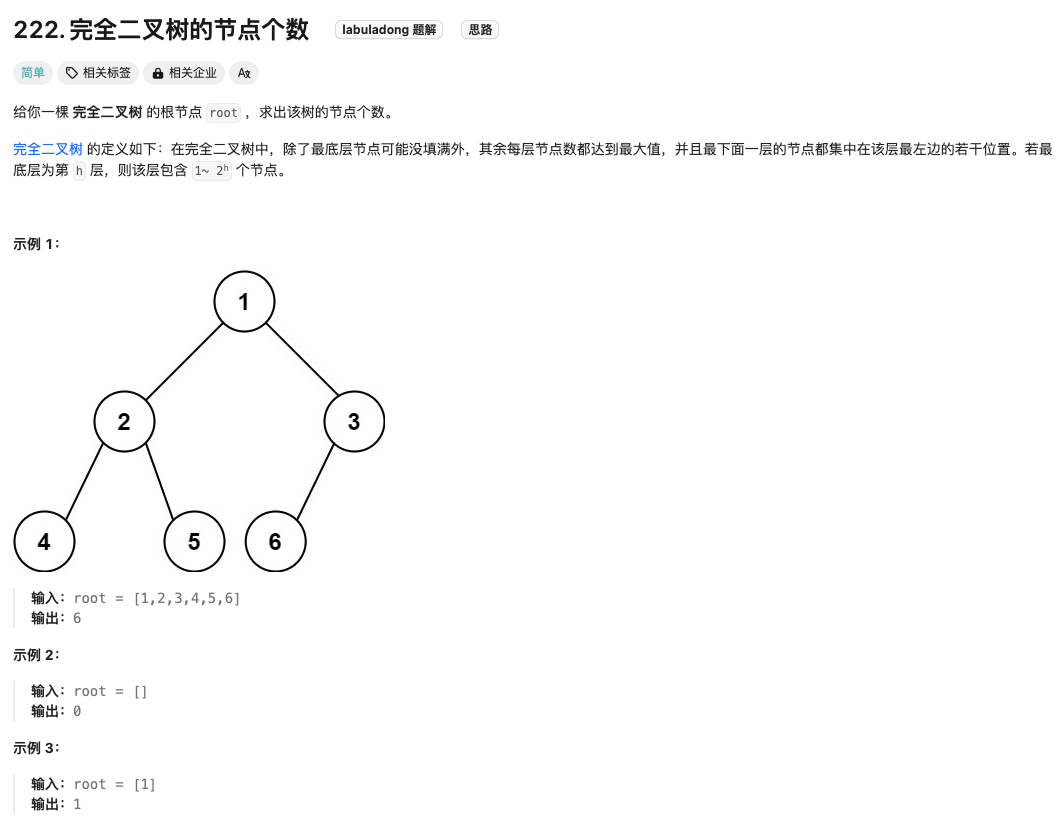
Click to expand the code.BFS解法。时间复杂度:O(n)。空间复杂度:O(n)
Click to expand the code.DFS解法。时间复杂度:O(n)。空间复杂度:O(log n),算上了递归系统栈占用的空间(注意平衡二叉树的空间复杂度是O(log n),普通二叉树的空间复杂度是O(n))
合并二叉树
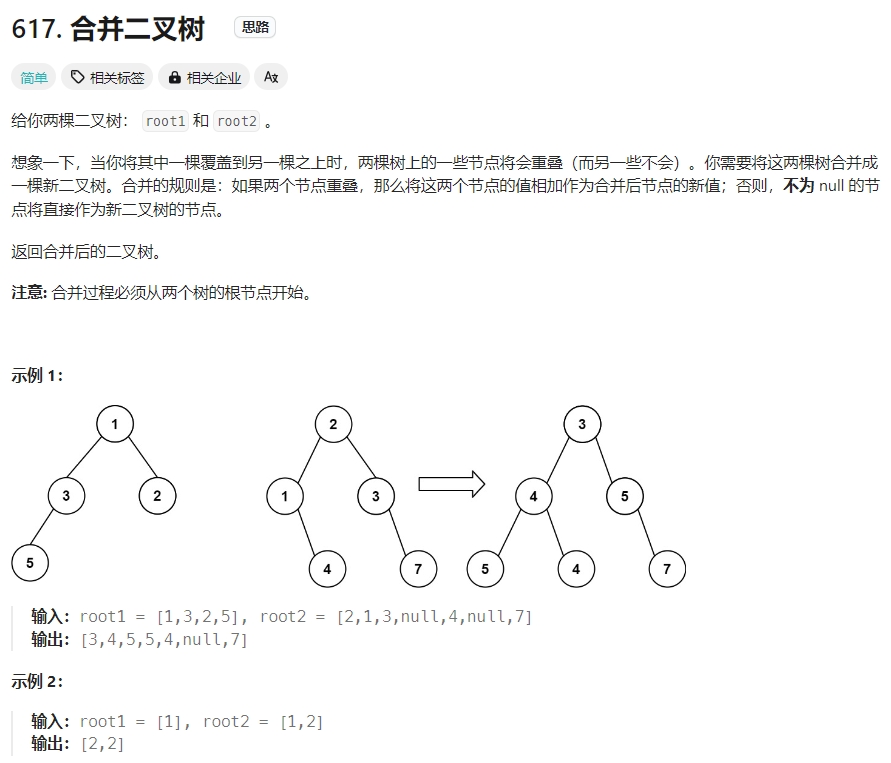
Click to expand the code。DFS前序遍历
Click to expand the code。采用BFS,层序遍历。注意由于que中push了两个树,故此当前的数目应该要除2
回溯算法解二叉树
更多关于回溯算法的介绍请见博客Link
二叉树的所有路径
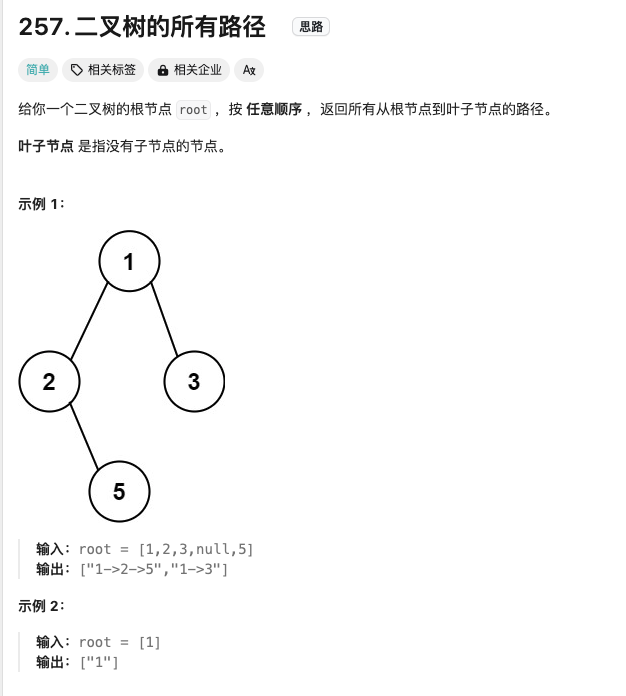
Click to expand the code,采用DFS其实也就是回溯算法的思路
路径总和
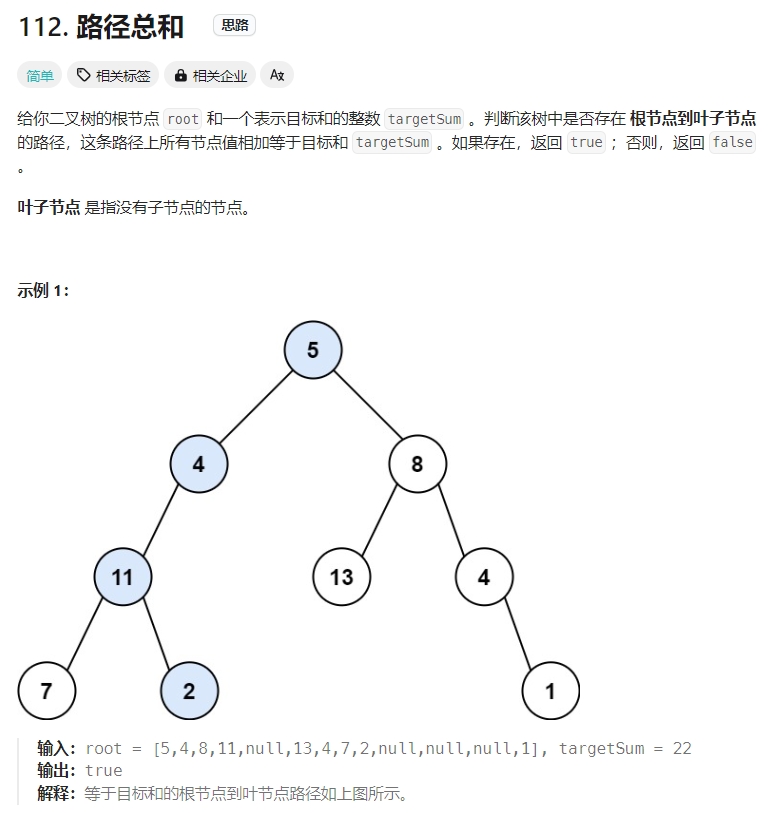
Click to expand the code。DFS+回溯,注意对于回溯终止的条件:并不是判断root是否为空,而是判断root的子节点是否为空
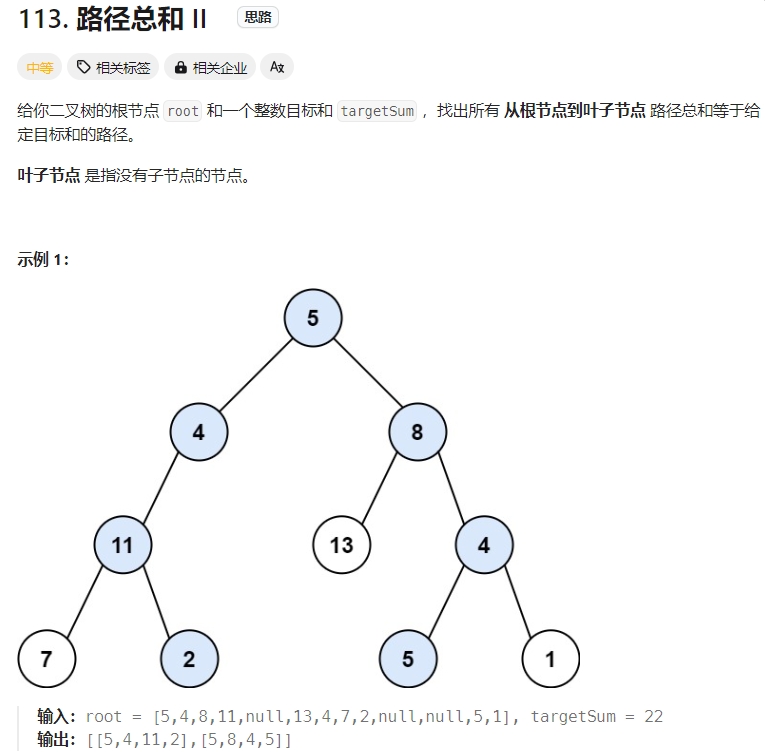
Click to expand the code。跟上面题目几乎是一样的。但是注意初始化的时候不要漏了targetSum也要减
参考资料
- My Leetcode
- labuladong二叉树(PS:感觉写得不是很好,思路不清晰且大部分要付费)
- 代码随想录