最近在了解hardware acceleration方面的topic,正好前辈老师给我推荐了这篇论文,在此对其进行拜读。
本博文为论文阅读笔记,仅供本人学习记录用~
PS:目前对于这部分还不是特别熟悉,读起来未免有些囫囵吞枣😭
- 论文链接Link
引言
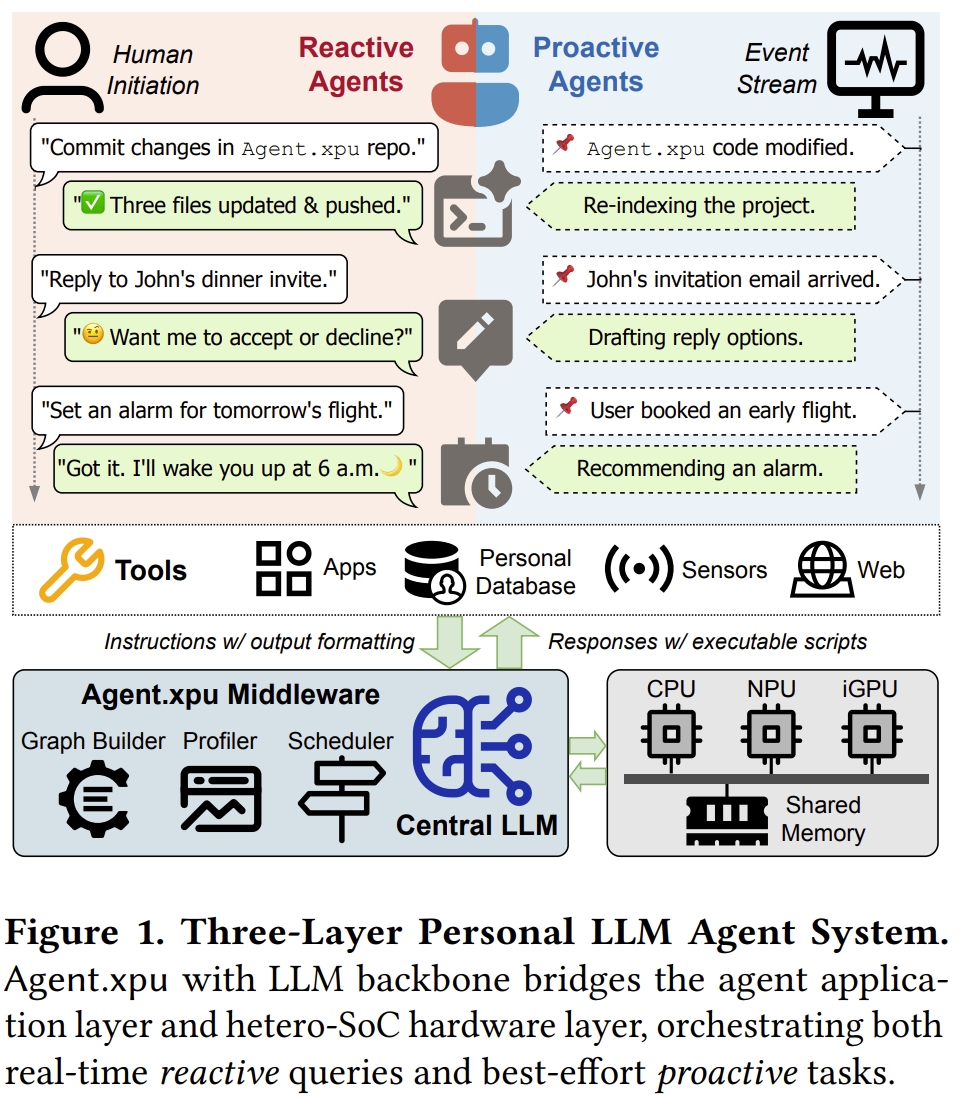
- LLM代理的兴起:代理式大语言模型(Large Language Models,LLMs)驱动的个人代理(如智能助手)需在本地设备(手机/PC)处理两类任务:
- 反应式任务(Reactive tasks):用户发起的,要求即时、低延迟的响应(例如<100ms)。
- 主动式任务(Proactive tasks):在后台隐式运行的长期任务,优先考虑吞吐量。
- 硬件平台局限:现有的消费级SoC(如Intel Core Ultra)配备CPU、集成GPU(iGPU)和神经网络处理单元(NPU),但存在内存带宽受限(共享LPDDR)、加速器异构性(NPU静态计算 vs. iGPU动态支持)和资源竞争等问题,无法高效管理这些冲突的请求。
该工作介绍了Agent.xpu,首个面向代理负载的异构SoC调度系统。 通过专门的离线剖析(offline profiling),Agent.xpu首先构建一个异构执行图(heterogeneous execution graph, HEG),该图融合并分块模型内核,用于基于亲和性引导的弹性加速器映射,并带有预测性内核标注。 在运行时,其在线调度器支持细粒度的内核级抢占,以保证反应式任务的响应性。 为了最大化SoC利用率,它采用空闲感知内核回填(slack-aware kernel backfill)机会性地附加主动式任务,并通过带宽感知调度(bandwidth-aware dispatch)缓解NPU-iGPU争用。 该系统实现反应式任务延迟降低4.6倍;主动式任务吞吐提升1.6–6.8倍;最大化SoC资源利用率(NPU/iGPU协作)。
作为设备端AI的基础,现代系统级芯片(system-on-chip,SoC)倾向于集成异构加速器,包括 CPU、集成GPU(iGPU)和神经网络处理单元(neural processing units,NPU)。 而基于PC或手机端设备的LLM日益增长的需求引发了硬件层面的激烈竞争。
然而,现实世界的个人助手与设备端LLM之间的差距仍在扩大。一方面,现有的设备端推理优化工作专注于孤立的推理任务,忽略了代理式LLM调用的动态性和并发性。 另一方面,代理式工作流优化的工作主要针对具有任务语义的多租户LLM服务,而未考虑个人设备上个人LLM代理的独特工作负载。
下图展示了代理式LLM工作负载,也就是跟上面提到的两种任务相对应:
- 主动式工作负载(Proactive workload):守护进程(daemon-like)式代理监听预定事件信号并据此采取行动,无需人工干预。主动式代理是轻松的,在后台消化事件流,没有严格的截止期限。
- 反应式工作负载(Reactive workload):由用户对话触发并期望及时响应。以LLM驱动的编码为例,主动式代理监控代码变更,静默执行项目解析、缓存构建或代码补全;而反应式代理则按需响应用户提示,根据当前上下文提供解释、建议或修复。作为中央协调器,LLM解析自然语言查询并生成融合其内部知识与工具交互命令的输出。
这两个混合的工作负载在高效执行上面临以下的挑战:
- LLM的动态特性与加速器的硬件刚性之间存在不匹配。NPU擅长处理静态的、预编译的计算图,但难以应对LLM推理固有的可变序列长度问题;而更灵活的iGPU则面临较低能效和图形任务干扰的问题。
- 共享内存SoC上受限的内存资源和带宽争用造成了关键瓶颈,导致性能下降,尤其是在延迟敏感型(latency-sensitive)和吞吐量导向型(throughput-oriented)任务并发运行时。
- 当前的异构SoC运行时,为代理式工作负载提供的抽象不足,缺乏对细粒度抢占、优先级调度和动态批处理(dynamic batching)的原生支持,而这些对于高效地共置(co-locate)反应式和主动式任务是必需的。
针对现有的这些主流推理引擎的缺陷(孤立推理设计,无法协调混合负载)。本文提出的Agent.xpu以在异构SoC上高效调度代理式LLM工作负载。 在高动态性、资源受限的异构SoC上,同时保障反应式任务的低延迟与主动式任务的高吞吐。 其设计的关键在于理解并协调不同的主动式和反应式任务,将它们智能地映射到底层硬件上,以平衡延迟、吞吐量和能效。
主要贡献点如下:
- 系统性地分析了代理式LLM工作负载的独特特性,量化了现代异构SoC上的算子-XPU亲和性(operator-XPU affinity)、内存争用(memory contention)、批处理效应(batching effects)以及主动-反应式干扰(proactive-reactive interference)。
- 异构执行图(heterogeneous execution graph, HEG):一种以异构为中心的计算抽象,用于弹性XPU映射。它支持一种原则性的、异构的预填充(prefill)和解码(decode)阶段分解(disaggregation)方法,跨越NPU和iGPU,以利用加速器优势并减轻干扰。
- 弹性核映射:将LLM算子按亲和性分组(如GEMM→NPU、MHA→iGPU),支持运行时动态绑定。
- 预填充-解码解耦:预填充(计算密集型)优先分派至NPU,解码(内存密集型)由iGPU处理,避免阶段干扰。
- 分块优化:长序列拆分为固定大小块(如4096 tokens),适应NPU静态编译需求(详见图3)。
- 在线调度器(online scheduler):结合了用于保证反应式响应性的细粒度内核级抢占机制,以及用于主动式任务工作守恒(work conserving)的空闲感知回填(slack-aware backfill)机制。其内置的XPU协调器(XPU coordinator)实现自适应内核分派(adaptive kernel dispatch),以避免带宽争用、减少流水线气泡(pipeline bubbles)并最大化系统吞吐量。
- 细粒度抢占:在核边界(非迭代级)保存上下文(KV缓存指针),实现反应式任务即时响应(<100ms)
- 空闲感知回填(Slack-Aware Backfill):利用反应式任务空闲间隙(如iGPU内存等待期),动态附加主动式任务。
- 带宽争用管理:实时监测DRAM压力,按阈值调度核并发。
- 统一内存架构优化:消除CPU-加速器间数据拷贝,通过指针传递实现零开销上下文切换。
背景介绍
异构SoC (Heterogeneous SoC)
异构SoC跨越移动、笔记本和边缘平台,具有如图2所示的类似架构。
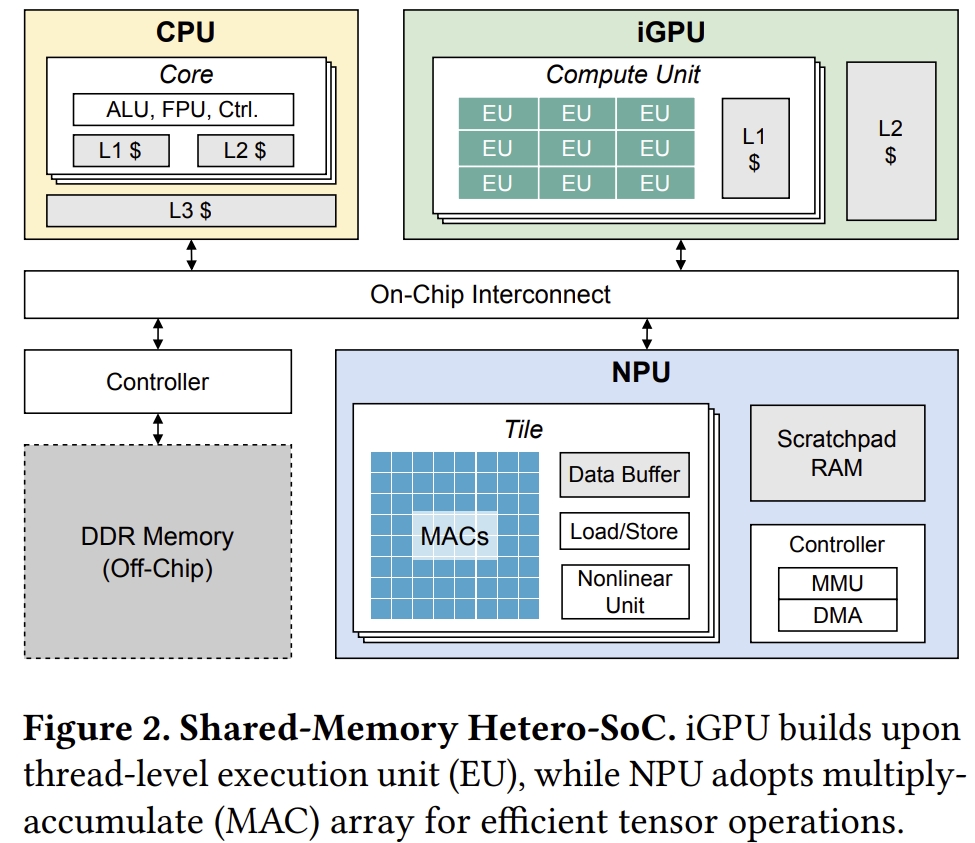
其内存层次结构与配备独立加速器(discrete accelerators)的大型异构系统显著不同。 CPU、iGPU和NPU共享系统物理内存,这避免了主机内存与设备之间的数据传输。
- 与独立GPU类似,iGPU由SIMT(单指令多线程)计算单元组成。但它们未配备专用的显存(VRAM);而是使用一部分系统内存。
- NPU专门为张量运算设计,与iGPU相比具有相当的并行性和更优的能效。大多数NPU的基本构建块是空间处理单元(spatial processing element, PE)阵列,每个PE每个时钟周期执行一次乘加(multiply-and-add)操作。NPU也共享系统内存,并具有有限的片上暂存SRAM(scratchpad SRAM)。
LLM推理: 从云端到个人设备端
LLM推理通常分为两个阶段:
- 预填充(Prefill)处理整个输入提示(prompt)以生成首个输出token和键值(KV)缓存;
- 解码(Decode)则逐个token地生成后续输出,利用并更新KV缓存。解码阶段通常占据大部分推理时间,尤其是在生成长文本时。
异构SoC与代理服务之间的Gap
- 模型动态性与硬件刚性不匹配:LLM处理任意大小的用户输入序列,但是主流的NPU都是处理具有静态形状的预定义神经网络(NN)运算而设计的。
- 受限的内存资源和带宽争用:PU和iGPU通常在有限的片上SRAM下运行,并严重依赖外部DRAM,而DRAM既是共享的又是带宽受限的。这限制了内核大小、上下文长度(context length)和批处理维度(batch dimensions)——这些对于服务吞吐量至关重要。此外,NPU和iGPU同时访问DDR会产生争用,从而拖慢并发请求。在处理混合代理式工作负载时,这个瓶颈会加剧:当内存受限(memory-bound)的解码阶段的主动式任务挤占DDR带宽时,延迟敏感的反应式请求在任何加速器上都会延迟。
- 代理式工作负载的运行时抽象(abstraction)不足:大多数异构SoC运行时针对无状态(stateless)、离线(offline)工作负载进行了优化,缺乏面向代理的LLM服务所需的基本抽象。首先,通常缺乏跨代理式LLM请求的动态批处理(dynamic batching)支持,导致硬件利用不足(suboptimal)。其次,异构SoC缺乏软件和硬件对细粒度抢占和优先级调度的辅助支持,使得难以将高优先级工作负载与后台推理隔离开来。第三,由于硬件级控制有限,软件调度器缺乏对加速器状态(例如NPU缓冲区占用率(buffer occupancy))的可见性,难以动态地跨加速器协调计算,导致负载不平衡(load imbalance)和利用不足(underutilization)。
异构SoC分析
接下来,进行了全面的异构SoC分析,以指导Agent.xpu的性能剖析器(profiler)、映射器(mapper)和调度器(scheduler)的设计。
算子级分析 (Op-Level Analysis)
在常见的LLM中,线性层(linear layers)中的密集矩阵乘法(GEMM)和多头注意力(multi-head attention, MHA)主导了计算量和总推理时间。其他非线性或逐元素张量运算(element-wise tensor ops)是次要的,并且可以轻松地与线性运算融合,这得益于现代NPU/iGPU中专用的非线性或向量单元。
作者根据LLM算子的作用域(scope) 进行分类:大多数LLM算子在token级(token-level) 操作,可以堆叠处理一个序列; 唯一的例外是MHA(多头注意力层),它计算序列级(sequence-level) 相关性,不允许按token分解(token-wise decomposition)。因此,MHA强制执行动态形状内核,而GEMM可以通过分块(chunking)利用静态内核。 算子类型和序列长度都会影响计算强度(compute intensity)和内存流量(memory traffic)。
关于算子-XPU亲和性(Op-XPU Affinity)这部分看不太懂,详细请见原文。
任务级分析 (Task-Level Analysis)
与孤立的LLM推理不同,现实世界的代理式工作负载同时管理延迟关键型(latency-critical)和吞吐量导向型(throughput-oriented)的LLM请求,其中来自不同请求的预填充或解码作业可能重叠。这些重叠的执行加剧了异构SoC有限资源的争用,并降低了系统性能。
- 异构SoC上的批处理效应:批处理多个LLM调用可以直观地提高整体系统吞吐量。然而,在资源受限的SoC上,每个请求的延迟对批处理或共置(colocated)作业的繁重程度变得更加敏感。作者分析了在单个加速器上多种情况的延迟,发现一个预填充作业几乎可以饱和一个NPU或iGPU,因为其延迟随批处理大小(batch size)成比例增加,而解码批处理的执行时间相对稳定。在NPU和iGPU上,与一个预填充任务一起批处理的解码任务的延迟退化(degradation)比预填充任务本身严重得多。这启发了可以利用SoC固有的异构性和内存共享来消除预填充-解码干扰。
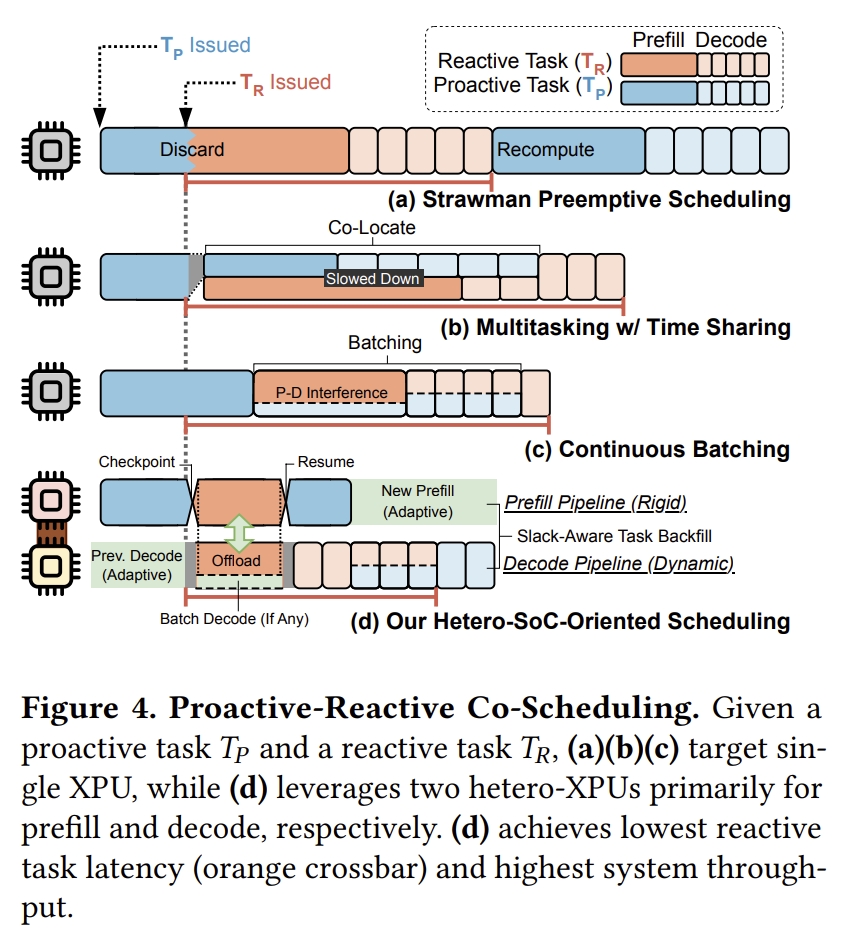
- 主动-反应式干扰:代理式LLM系统经常交织(interleave)主动式和反应式任务。为了满足不同任务冲突的延迟或吞吐量期望,需要高效地共同调度(co-schedule)这些LLM工作负载。下图4用四种共同调度方案(co-scheduling schemes)说明了主动式和反应式任务之间的干扰。
Agent.xpu 概述
Agent.xpu专注于以下主要目标:1) 优先考虑反应式代理LLM请求的端到端延迟,以提升用户体验;2) 提高来自主动式代理的后台LLM调用的整体吞吐量;3) 优化异构SoC中有限计算资源的利用率,以追求性能和能效。 其系统架构如下图所示:
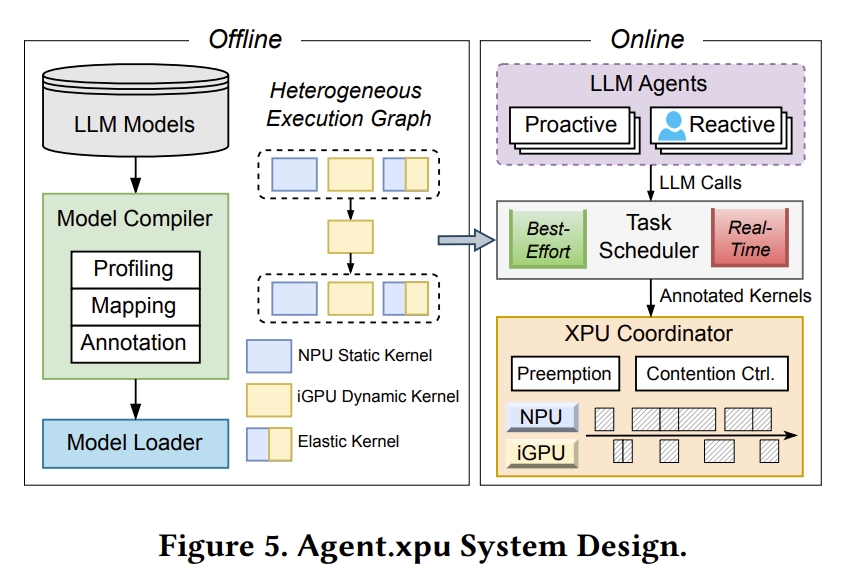
离线模型准备将给定的LLM模型映射到NPU或iGPU内核,形成异构执行图(HEG),然后使用性能或功耗估计对每个内核进行标注,以指导在线调度。弹性内核后端(elastic kernel backend)的具体选择推迟到运行时。当启动Agent.xpu引擎时,模型权重和带有优化内核的HEG被加载到共享内存中。在在线调度期间,Agent.xpu维护尽力而为(best-effort)和实时(real-time)任务队列,分别缓冲主动式和反应式LLM请求。每个任务被分解并转换以适应HEG。XPU协调器(XPU coordinator)对任务队列进行忙轮询(busy polling),并将原始或批处理的内核分派给NPU或iGPU。在Agent.xpu调度策略下,实时内核高效地抢占(preempt)尽力而为的内核以获得最优响应时间,而协调器则机会主义地(opportunistically)将等待队列中合适的尽力而为内核与正在运行的实时内核进行共同调度或批处理。这种空闲感知内核回填(slack-aware kernel backfill)方法在保证实时性的同时最大化系统吞吐量。XPU协调器通过动态内核分配(给NPU/iGPU)、内核批处理以及争用感知、减少气泡(bubble)的内核重排序(reordering)来实现对底层SoC的策略执行。
- 离线阶段:
- 性能画像:量化算子-XPU亲和性(如GEMM在NPU能效比iGPU高3×)、内存带宽敏感度。
- HEG构建:融合线性/非线性算子,标注核执行时间、内存占用等预测参数。
- 在线阶段:
- 双队列调度:实时队列(反应式任务)优先于尽力而为队列(主动式任务)。
- XPU协调器:动态分派核至NPU/iGPU,支持核级抢占与回填(图5)。
异构执行图 (Heterogeneous Execution Graph)
这部分涉及的是执行的图及计算框架。
在线工作负载感知调度(Online Workload-Aware Scheduling)
Agent.xpu中的在线调度器协调执行从HEG派生的异构内核,动态适应代理式工作负载的到达模式和优先级。与仅优化吞吐量的传统LLM服务系统不同,调度器必须在资源受限的SoC上平衡最小化反应式任务延迟和最大化主动式任务吞吐量这两个冲突的目标。
调度指南与组件
- 双队列架构(Dual-Queue Architecture)。Agent.xpu采用双队列架构,按优先级隔离工作负载。实时队列(real-time queue)缓冲要求即时响应的反应式LLM请求,而尽力而为队列(best-effort queue)累积可容忍更高延迟的主动式请求。这种分离实现了差异化的调度策略,而无需复杂的优先级反转(priority inversions)。每个传入的LLM请求在到达时根据其优先级标记并相应入队。
- 任务分解与分派(Task Decomposition and Dispatch)。出队时,每个LLM任务根据预编译的HEG分解为一系列内核。通常,预填充时的分块token级内核分配给NPU,而其他内核,包括动态形状的预填充内核和所有解码内核则分配给iGPU。这种分解避免了NPU-iGPU内存争用,并提高了能效,因为解码计算的iGPU利用率较低。然而,内核分派是自适应的(adaptive),取决于当前的工作负载。例如,分派器(dispatcher)可以将反应式任务的预填充内核同时发送给NPU和iGPU以增加并行性,或者在反应式预填充耗时较长时在iGPU上启动饥饿的(starved)主动式预填充。这些任务转换步骤在保持数据依赖关系(data dependencies)的同时,暴露了跨异构加速器的并行性机会。
- XPU协调器(XPU Coordinator)。核心的XPU协调器实现了一个忙轮询循环(busy-polling loop),持续监控两个队列并协调内核分派。协调器维护几个关键数据结构:1) 活动内核表(Active kernel table):跟踪每个加速器上当前正在执行的内核。2) 内存压力估计器(Memory pressure estimator):聚合(aggregates)活动内核的带宽利用率。3) 抢占上下文缓冲区(Preemption context buffer):存储指向被抢占内核的中间缓冲区的指针。4) 回填候选池(Backfill candidate pool):维护准备执行(ready-to-execute)的尽力而为内核。
细粒度内核级抢占
为确保反应式任务的响应性,Agent.xpu实现了一种新颖的内核级抢占机制,在最小化上下文切换开销的同时保留计算进度。
- 抢占粒度(Preemption Granularity)。与丢弃整个计算或延迟传入请求的迭代级(iteration-level)抢占不同,我们的方法在HEG内的内核边界(kernel boundaries)操作。当在主动式执行期间到达反应式任务时,协调器允许当前内核完成(避免内核中段中断)。我们适当的分块策略将每个预填充内核的执行时间限制在100毫秒以内,从而最小化了抢占延迟。然后,协调器对主动式任务的状态进行检查点(checkpoint),包括部分KV缓存和层进度(layer progress)。检查点操作没有额外开销,因为内核执行后中间结果已位于DDR中,无需显式传输。然后,根据延迟要求或功耗预算(power budget),反应式内核被立即调度到预填充或解码流水线(pipelines)。与迭代级或层级(layer-level)抢占相比,这种细粒度机制利用了LLM计算中的自然边界;每个内核产生定义明确的中间激活,作为高效的检查点。
- 上下文管理(Context Management)。调度器维护每个被抢占请求的元信息(meta information)和上下文(context)。元信息包括输入提示(input prompt)、到达时间(arrival time)以及预填充或解码进度。如果被抢占的请求处于预填充中途,则可以根据提示长度和内核标注推导出其预计完成时间(estimated time to completion, ETC)。对于已进入解码阶段的请求,除非它们遵循某种输出模板,否则无法跟踪其ETC。ETC将指导我们稍后讨论的恢复策略(resumption strategy)。
- 恢复策略(Resumption Strategy)。考虑被抢占的主动式任务恢复执行时的场景:反应式任务完成预填充,而原始的主动式解码可以自动与卸载到iGPU的反应式预填充一起批处理。被抢占的主动式任务基于一个动态优先级恢复预填充执行,该优先级同时考虑任务进度(progress)和自抢占以来经过的时间(elapsed time)。为避免饥饿(starvation),等待时间(pending time)超过特定阈值的主动式任务将首先恢复。其他任务的优先级将由其ETC决定:ETC较低的任务优先,因为它们可以更早进入iGPU上的解码流水线,这提高了解码流水线的整体吞吐量。恢复时,可以无额外开销地召回请求上下文。
空闲感知内核回填
为了在不影响反应式性能的前提下最大化系统利用率,Agent.xpu采用空闲感知回填(slack-aware backfill),机会性地将尽力而为内核与实时工作负载共同调度。
- 空闲识别(Slack Identification)。调度器在反应式工作负载中识别三种类型的执行空闲(execution slack):
- 结构性空闲(Structural slack):NPU和iGPU操作之间固有的并行性(inherent parallelism)。当其中一个(NPU或iGPU)运行时,另一个可能处于空闲。
- 计算空闲(Compute Slack):在内存受限内核期间计算资源利用不足(underutilized),这在iGPU解码内核中很常见。批处理(batching)是提高吞吐量最直接的方法。
- 内存空闲(Memory slack):在计算受限内核期间带宽利用不足。解决方法是利用结构性空闲,在另一个XPU上调度内核。
- XPU内与跨XPU回填(Intra- and Inter-XPU Backfill)。基于识别出的空闲,主动式内核可以在同一XPU或另一XPU流水线上回填反应式内核。
- XPU内回填(Intra-XPU backfill):通过自适应批处理(adaptive batching)利用内存受限内核未充分利用的计算吞吐量。这适用于iGPU上的token级解码内核,而注意力内核(attention kernels)必须逐个执行。在每次解码迭代(decode iteration)的边界,等待中的(pending)主动式解码请求加入批处理,而不会干扰反应式延迟。
- 跨XPU回填(Inter-XPU backfill):通过消除NPU或iGPU流水线中的气泡(bubbles)来利用结构性和内存空闲。例如,NPU上的主动式预填充可以与iGPU上的反应式解码并行工作。
其中,候选的主动式内核必须满足几个约束:
- 持续时间约束(Duration constraint):在反应式内核的执行窗口(execution window)内完成。
- 内存约束(Memory constraint):组合带宽利用率低于阈值。
- 亲和性约束(Affinity constraint):尽可能针对非冲突(non-conflicting)的加速器。
主要实验结果与结论
关键性能:
- 反应式任务延迟:
- Agent.xpu:平均4.6倍降低(图7),尤其在主动任务高负载下保持稳定(Llama.cpp延迟陡增)。
- 主动式任务吞吐:
- Agent.xpu:1.6–6.8倍提升(图6),NPU利用率达85%,iGPU负载<30%。
- 资源效率:
- 内存带宽争用减少40%(通过分时调度GEMV类核)。
- 能耗降低2.1倍(J/token),因NPU处理高能效GEMM。
Agent.xpu通过HEG解耦计算阶段与动态核调度,在异构SoC上首次实现代理负载的高效并发:低延迟(反应式)与高吞吐(主动式)的协同优化,为端侧LLM代理系统奠定基础。