本博客对VLA(Vision-Language-Action)进行调研整理。
在VLA模型出现之前,机器人技术和人工智能主要分布在彼此割裂的几个子领域:
- 视觉系统能够“看”并识别图像。传统的CV可以通过CNN来识别物体或者进行分类,但是并不能理解语言、也没有将视觉转换为action的能力。
- 语言系统能够理解和生成文本。语言模型,特别是基于LLM的虽然可以革新了文本的理解以及生成,但是他们仍然只能处理语言文本,而不能感知或者推理物理世界。
- 动作系统则能够控制物体运动。机器人中基于action的系统一般都是依赖于传统控制策略(hand-crafted policies)或者强化学习来实现例如目标抓取等等,但是这需要复杂的工程实现。
VLA即视觉-语言-动作,是一种将视觉感知与语言理解结合,实现自主操作决策的多模态任务。
VLA概述
在传统的自动化场景中,我们常常看到这样的景象:机器人高效、精准地重复着预设动作,但一旦遇到未经编程的细微变化——比如流水线上一个零件被意外放歪——整个系统就可能陷入停滞或错误。这背后的根本原因在于,传统机器人更像一个“照本宣科的演员”,其行为完全依赖于工程师事无巨细的代码编写,缺乏对动态环境的理解和自主决策能力。 为了突破这一瓶颈,人工智能领域正涌现出一种革命性的架构:视觉-语言-动作模型(Vision-Language-Action)。VLA模型旨在为机器人构建一个能够像人一样“观察、思考、行动”的统一大脑。它通过将视觉感知、语言理解与物理动作控制深度融合,使机器人能够直接理解人类的自然语言指令,感知周围的三维世界,并自主生成与之对应的复杂动作序列。
一个典型的VLA模型由几个核心部分组成:视觉与语言编码器负责分别处理图像信息和文本指令;跨模态融合机制(通常基于强大的Transformer架构)是模型的核心,它能将视觉特征与语言语义进行深度对齐,理解例如“请把桌子上的那个红色杯子拿给我”这类指令中“桌子上的”、“红色杯子”所指代的具体视觉实体;最后,动作解码器会将这种融合后的高级理解转化为具体的、可执行的电机控制指令(如关节角度、末端位姿等)。部分先进的模型还引入了反馈模块,通过实时视觉信息对动作进行闭环修正,进一步提升操作的鲁棒性。
VLA模型的巨大潜力主要体现在以下三大优势上:
- 端到端的统一框架:它彻底打破了传统机器人技术中“感知-规划-控制”三个模块相互割裂的架构。通过一个模型实现从原始信号(图像像素和语言文字)到最终动作(机器人末端控制指令)的直接映射,极大地简化了系统设计和部署流程,降低了整体的复杂性。
- 卓越的语义泛化能力:得益于背后的大语言模型(LLM、VLM)与大规模视觉-语言预训练,VLA模型具备出色的推理和泛化能力。它不仅能理解指令的字面意思,更能捕捉其背后的隐含逻辑。例如,当被要求“让房间更整洁”时,模型可以推理出需要将散落的玩具放入收纳箱、将书本放回书架等一系列具体动作,而无需对每一种物品和场景进行单独编程。
- 广泛的跨平台通用性:一个在大量多样化数据集上预训练好的VLA模型,可以相对容易地部署到不同的机器人硬件平台上。由于其已经具备了通用的世界知识和任务理解(common sense),针对特定场景或新机器人的适配只需进行少量数据的微调,极大地降低了迁移成本,为实现“一个模型控制万千机器人”的愿景奠定了基础。
综上所述,VLA模型不仅仅是一项技术改进,它更代表着机器人智能化研究的一次范式转移。它将机器人的能力边界从预设的、结构化的环境,拓展到了开放的、动态的真实世界,为开发能够真正理解人类意图、灵活适应未知环境的通用型机器人,照亮了前行的道路。
VLA经典方法阅读
VLA方法总览
VLA模型的分类方式有很多,比如:基于自回归(autoregression)的,基于diffusion的,基于强化学习的,混合的(双系统)等。详细请见survey paper——Pure Vision Language Action (VLA) Models: A Comprehensive Survey
在深入看各种方法之前,先通过下面表格来总览VLA的发展脉络。 后续也是基于此表格来对各个算法进行展开阅读。
| 年份 | 单位 | 模型 | 方法 | 说明 | |
|---|---|---|---|---|---|
| 2025 | 极佳科技 | SwiftVLA | VLM | 4D transformer(StreamVGGT)实现从2D图像提取4D特征(2D+4D输入),以此来增强VLM(SmolVLM-0.5B)的特征,真机实验比7倍更大的VLA模型(π0)性能相当(真机成功率为0.76,π0为 0.48,LIBERO成功率为95.1%),在边端设备(NVIDIA Jetson Orin)上快18倍(推理速度为0.167s=5.98HZ),内存消耗少12倍 | |
| 2025 | 复旦大学 | ProphRL | VLA+RL+World Model | 提出了一个世界模型(Prophet)作为模拟器来训练VLA,方法采用VLA+在线RL;在AgiBot、DROID、LIBERO 和 BRIDGE 等benchmark上为各类 VLA 模型(VLA-adapter-0.5B, Pi0.5-3B, OpenVLA-OFT-7B)带来 5–17% 的SR提升,在真实机器中取得 24–30% 的成功率提升 | |
| 2025 | 复旦大学 | WholeBodyVLA | VLM+RL | 统一框架实现全身控制(下肢移动+上肢捉取)。LAM (Latent Action Model)采用分段训练的方式,用真实机器人操作数据集(AgiBot World)+带有“移动-操作”的视频进行预训练,学习locomotion–manipulation skill。而loco–manipulation–oriented (LMO) RL policy则用于实现稳定的移动(如,前进、转弯、下蹲) | |
| 2025 | 阿里达摩院 | RynnVLA-002 | Action World Model | 统一框架实现(VLA+World Model);“双向增强” 逻辑:世界模型通过学习物理动态(预测/生成未来图像),可优化 VLA 模型的动作生成精度;而 VLA 模型的对视觉的理解,能提升世界模型的场景预测保真度;在LIBERO的成功率达97.4% | |
| 2025 | 清华大学 | X-VLA | 双系统 | 通过可学习的Soft-Prompt(编码硬件特性) 嵌入让模型“理解”不同机器人和环境的差异;0.9B参数量(LIBERO上平均SR为98.1%);实现120分钟无辅助自主叠衣服 | |
| 2025 | National University of Singapore | VLA-4D | 4D(VGGT+时间维度)+VLM(Qwen2.5-VL-7B,vision encoder + LLM) | 4D感知视觉表征,视觉特征(三维位置信息)+一维时间信息嵌入;时空动作表征(空间动作表征拓展了时序信息维度) | |
| 2025 | University of Maryland | TraceGen | DINO(几何特征)+SigLIP(语义特征)+T5(编码指令)+flow-based model | 引入“3D轨迹空间”(world model/VGGT),将视频转换为3D轨迹;把预测的3D轨迹,通过逆运动学转换成机器人的关节运动指令,直接驱动机器人执行。但真实机器人上的成功率仍然只有67.5% | |
| 2025 | 上海交大 | Evo-1 | VLM+cross-modulated diffusion transformer | VLM为Internvl3(InternViT-300M+Qwen2.5-0.5B);采用两阶段训练(freeze VLM训练action expert+ full-scale fine-tuning);仅0.77B参数在LIBERO上获取94.8%,MetaWorld(80.6%,PI0 47.9%)和RoboTwin(37.8%,PI0 30.9%) | |
| 2025 | HKUST-GZ | Spatial Forcing | VGGT+PI0(VLM+action expert) | 隐式地给VLA赋予3D感知能力;在中间层(相对较深但非最深)通过最大化余弦相似度,强制视觉token与3D特征的对齐;LIBERO benchmark4个任务的平均成功率>98% | |
| 2025 | 上海交大 | Evo-0 | VGGT+PI0(VLM+action expert) | 将VGGT的几何特征与VLM视觉特征通过融合模块(lightweight fusion model)进行融合;在真机捉取实验带来的提升28.53%->57.41% | |
| 2025 | 北京大学 | EvoVLA | OpenVLA-OFT(ViT+LLM)+自监督RL | 三个组件:RL(阶段对齐奖励、基于位姿的物体探索)+长时程记忆模块(可查询的数据库);解决了VLA模型的stage hallucination(即假装完成了某个任务阶段而获取奖励);将长程任务(搭桥、堆叠、枣子入杯)的平均准确率提升到69.2% | |
| 2025 | Physical Intelligence | PI0.6 | PI0.5(VLM+action expert)+RL | VLA通过强化学习在现实部署中实现自我改进;基于经验与校正的优势条件策略强化学习(RECAP) ;VLM模型采用Gemma 3 4B,动作专家860M参数量 | |
| 2025 | 美团 | RoboTron-Mani | 3D 感知增强(RoboData数据集+3D感知架构) + 基于LLM的多模态融合架构 | 通过引入相机参数矫正及occupancy监督来增强3D空间感知能力 | |
| 2025 | Generalist | GEN-0 | Harmonic Reasoning模型被训练同时推理与action | 27万小时真实物理交互数据训练;(机器人领域)首次发现7B参数量以内模型会出现固化,而超过这个参数量,可展示良好Scaling Laws | |
| 2025 | Dexmal | Realtime-VLA | pi0(VLM+diffusion action expert) | cuda graph+simplified graph+optimized kernels;捉取落笔任务成功率100%;RTX 4090 GPU实现30HZ推理及up to 480HZ动作生成 | — |
| 2025 | University of British Columbia | NanoVLA | VLM+action expert | 视觉-语言解耦(后期融合+特征缓存)+长短动作分块+自适应选择骨干网络;首次实现在边缘设备(Jetson Orin Nano)上高效运行VLA(41.6FPS); | |
| 2025 | Shanghai AI Lab | InternVLA-M1 | VLM planner+action expert双系统 | VLM是采用了空间数据进行训练的,action expert输出可执行的电机指令 | |
| 2025 | Figure AI | Helix | VLM+Transformer;快慢双系统 | 首个能让两台机器人同时协同工作的VLA 模型;控制人形上半身 | |
| 2025 | Russia | AnywhereVLA | SmolVLA+传统SLAM导航(Fast-LIVO2)+frontier-based探索 | 消费级硬件上实时运行VLA;移动机械臂 | |
| 2025 | AgiBot-World | GO-1 | VLM+Action Expert | AgiBot World:5个场景下217个task对应的一百万条真实机器人轨迹;通过 latent action representations来提升机器人数据的利用; | |
| 2025 | Physical Intelligence | PI0.5 | PI0+PI-FAST+Hi Robot+多源异构数据 | 多源异构数据联合训练+序列建模统一模态+层次规划推理;首个实现长期及灵巧机械臂操作 | |
| 2025 | NVIDIA | GR00T N1.5 | 双系统; NVIDIA Eagle2.5 VLM + Diffusion Transformer | VLM在微调和预训练的时候都frozen | |
| 2025 | NVIDIA | GR00T N1 | 双系统;VLM(NVIDIA Eagle-2 VLM)+flow-matching训练的Diffusion Transformer | heterogeneous training data | |
| 2025 | KAIST | LAPA | VLM | 首个通过无监督学习(没有真值机器人action label)来训练VLA模型的方法 | |
| 2025 | 美的 | DexVLA | VLM+diffusion | 1B参数量的diffusion expert with multi-head架构,实现不同实体形态的学习;三阶段的分离式训练策略; | |
| 2025 | 美的 | DiVLA | VLM+autoregressive+diffusion | autoregressive进行推理,而diffusion进行动作生成以控制机器人 | |
| 2025 | 上海AI Lab与北京人形 | TinyVLA | ViT+LLM | 在OpenVLA基础上引入轻量VLM模型以及diffusion policy decoder | |
| 2025 | Stanford | OpenVLA-OFT/OpenVLA-OFT+ | ViT+LLM | 在OpenVLA基础上引入了并行解码、action chunking、连续的动作表示、简单的L1回归作为训练目标;其中OpenVLA-OFT+则是在SigLIP和DINOv2之间插入了FiLM | |
| 2025 | Physical Intelligence | Hi Robot | PI0+快慢双系统(VLM+VLA) | 分层交互式机器人学习系,可以执行高层推理与底层任务执行 | |
| 2025 | Physical Intelligence | PI0-Fast/π₀-FAST | PI0+频率空间action Tokenization | 探索VLA训练的action representation;通过频域对动作序列的Token化,将训练时间减少5倍 | |
| 2024 | Physical Intelligence | π0/PI0 | VLM+action expert(diffusion) | 通才模型(generalist model);预训练+task-specific微调策略 | |
| 2024 | Stanford | OpenVLA | SigLIP与DNIO-v2作为视觉编码器,大语言模型(LLaMA2-7B)作为高层推理 | 首个全面开源的通用 VLA 模型,结合多模态编码与大语言模型架构;首次展示了通过低秩适应(LoRA)和模型量化等计算高效的微调方法,实现降低计算成本且不影响成功率 | |
| 2024 | UC Berkeley | Octo | Transformer | 采用diffusion作为连续动作生成;基于Open x-embodiment训练的大型架构;通用机器人模型的探索 | |
| 2024 | 字节 | GR-2 | GPT-style 视频生成模型 | GR-1的晋级版,用了更多、更diversity的数据来预训练 | |
| 2024 | 字节 | GR-1 | GPT-style 视频生成模型 | 通过GPT式生成模型的预训练(video generative pre-training model),结合机器人数据进行微调 | |
| 2024 | Stanford | ReKep | ViT+VLM | DINOv2提取3D关键点,VLM通过指令与图像生成关键点与空间的约束,通过求解优化获取机器人末端执行轨迹 | |
| 2023 | Google DeepMind | RT-2 | VLM | 正式提出VLA概念;采用VLM作为骨架;Internet-scale预训练VLM模型在机器人控制上展示良好的泛化性及语义推理;将action也表达成文本token的形式 | |
| 2023 | Stanford | ALOHA/ACT | CVAE+Transformer | 动作分块;用低成本平台实现精细操作,如线扎带、乒乓球 | |
| 2023 | Stanford | VoxPoser | LLM+VLM | LLM进行代码生成驱动机器人完整操作任务,VLM获取3D价值地图获取实现任务的轨迹规划 | |
| 2023 | SayCan | LLM | 探索如何利用 LLM 实现对机器人动作的控制,通过预定义的运动(motion primitives)来与环境进行交互 | ||
| 2023 | Google DeepMind | RT-1 | EfficientNet+Transformer | VLA任务首次用到实际机械臂 |
PS: VLA的方法实在太多了,后续看到有意思的工作会及时更新此表格,但方法解读实在没办法都整理,只能囫囵吞枣,错漏之处,欢迎评论区指出🙏
VLA常用的数据集













RT-1
其架构如下图所示:
- 输入处理:图像和文本首先通过一个基于ImageNet预训练的EfficientNet进行处理。在FiLM层嵌入预训练的指令(将指令转换为嵌入向量),进而提取与任务相关的视觉特征。
- Token Learner:将提取的视觉特征转换为Token的形式;
- Transformer对获取的Token做一系列的attention操作生成action token;
- 最终输出的action包括:手臂的七个自由度的运动:xyz,rpy,双指夹持器开合。此外,action还需要包括移动地盘的xy和航向角(yaw)。并且还需控制手臂、控制底盘、终止,三个模块的切换。
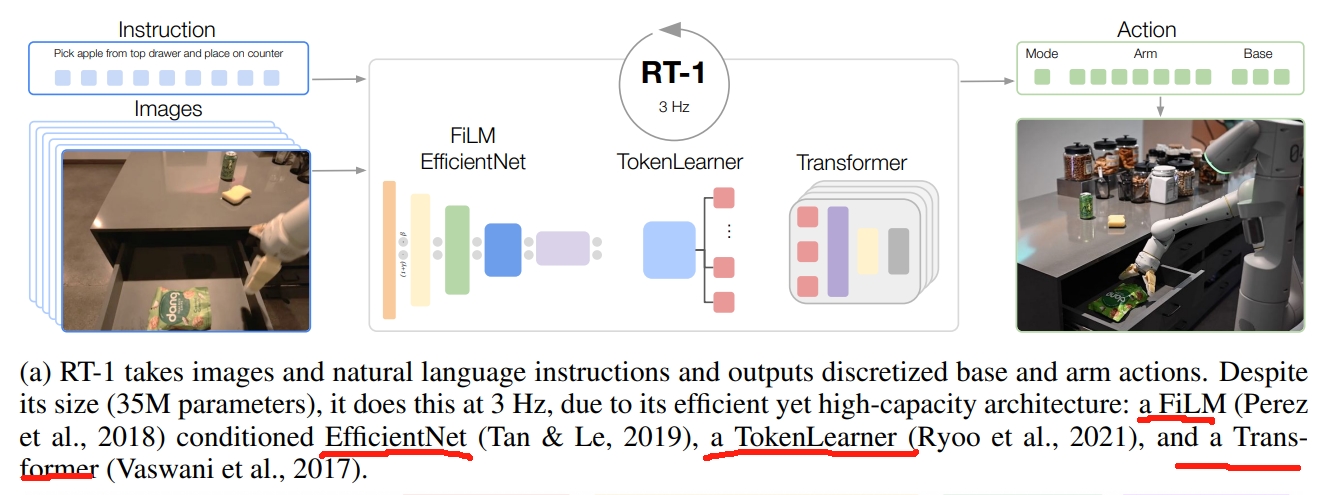
而其关键的contribution应该是数据集部分:17个月,13个机器人,13万此示范,700多个任务。


RT-1 在真实机器人平台上进行了大量实验,展示了其在多任务、多目标环境中的鲁棒性与泛化能力,在定量准确率和演示视频中均表现良好。
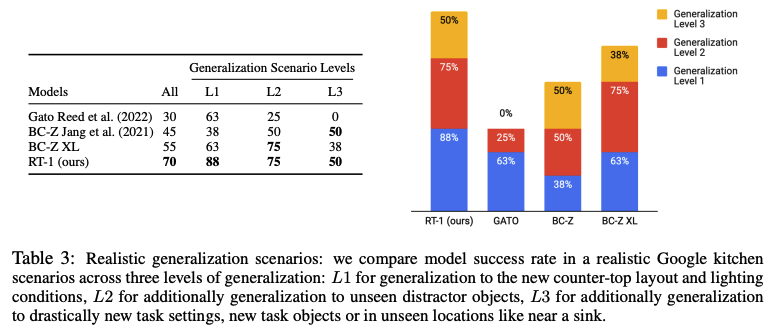 RT-1 和baseline在seen任务上的整体性能、对unseen任务的泛化能力以及对干扰物和背景的鲁棒性
RT-1 和baseline在seen任务上的整体性能、对unseen任务的泛化能力以及对干扰物和背景的鲁棒性
|
 RT-1在各种指令下的轨迹
RT-1在各种指令下的轨迹
|
RT-1 在真实机器人平台上进行了大量实验,展示了其在多任务、多目标环境中的鲁棒性与泛化能力,在定量准确率和演示视频中均表现良好。下面是其demo视频
SayCan
SayCan 在语言理解与机器人底层动作之间架起了一座桥梁。它通过将大型语言模型(LLM)的语义推理能力与机器人可执行技能的价值函数相融合,使机器人能够理解复杂的指令并执行相应操作。 这属于早期的VLA工作,甚至在 VLA 概念尚未明确形成之前,就已开始探索如何利用 LLM 实现对机器人动作的控制。
尽管 LLM 能够理解和生成复杂语言,但它缺乏与现实环境的直接交互经验。由于 LLM 生成的内容并未获得来自物理过程的反馈,它本身无法直接与物理世界互动。不过,LLM 确实掌握了大量常识性知识,因此本文研究如何从中提取有用信息,以指导机器人遵循高层级的文本指令。
SayCan 借助预训练技能对应的价值函数,为 LLM 提供现实环境中的上下文信息,使其能够根据当前环境状态选择可行的机器人行为。 需要注意的是,该系统中机器人已配备一系列学习好的“原子”行为技能,能够执行底层的运动控制。具体来说,LLM 的输出为每个技能生成对应完整指令的概率分布,系统基于最高概率执行具体动作。
- 所谓的价值函数根据当前场景评估每个动作的可行性。例如,在包含红牛罐和苹果的场景中,“抓取红牛罐”和“抓取苹果”这两个动作会被赋予较高的价值;而在空旷场景中,所有抓取类动作的价值则会被调低。
VoxPoser
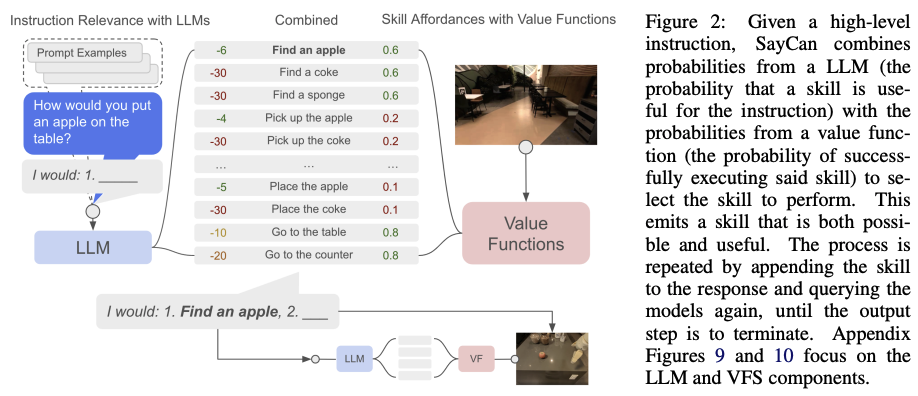
VoxPoser也属于早期的工作,同样的当时VLA的概念还没出来。 LLM虽然已经被证明有大量丰富的actionable知识可以用于机器人操作的推理和规划,但是只能依赖于了预定义的运动(motion primitives)来与环境进行交互。 因此本文首先合成了机器人轨迹(包括六自由度的末端的waypoint),包括了开放的指令和开放的物体。 作者首先发现:LLM在语言指令下擅长推理affordances(可行性) 和 constraints(约束条件),更重要的是利用模型自动生成代码,并结合VLM模型,将自然语言中的可行性与约束条件映射为3D价值地图(3D value maps)。
而该3D value maps就是将知识用到agent观测到的空间上。如下图所示。affordance maps中,蓝色区域就是要抓取操控的目标,代表high reward;constraint map中, 红色区域就是约束,也就是要避开的障碍,代表high cost;value map中,机器人尽量往蓝色区域走,避开红色区域。

本质上,该工作就是通过语言生成代码并驱动机器人执行全过程,而生成的3D value maps就是为运动规划器的目标函数,生成轨迹。
ReKep
结合视觉模型DINOv2和多模态大模型GPT-4o,将自然语言任务转换为关键点之间的空间约束,通过优化求解生成机器人精确动作。
本文同样的,也是VLA概念出来前的探索。 它跟Voxposer是有点类似的,通过LLM将将自然语言任务转换为3D关键点之间的空间约束,通过优化求解生成机器人精确动作。 而3D关键点点获取则是采用DINOv2。
整体流程如下图所示:DINOv2从RGB图像中获取场景中的3D关键点,并叠加在图像上。然后该图像与语言指令一并输入VLM模型(GPT-4o)中来生成一系列带约束的python代码。而所谓的约束其实就是3D关键点与不同时段任务的空间约束。最后约束转换为优化问题,通过求解优化问题来获得机器人末端的控制序列。
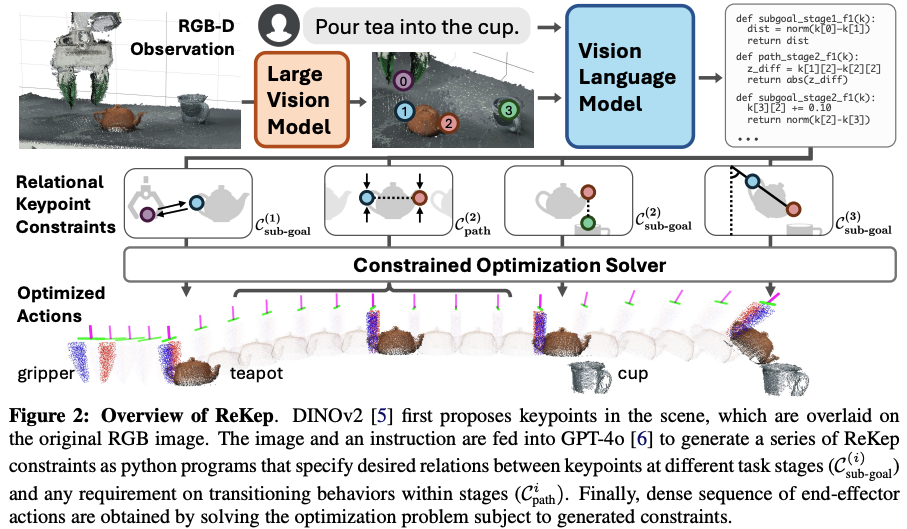
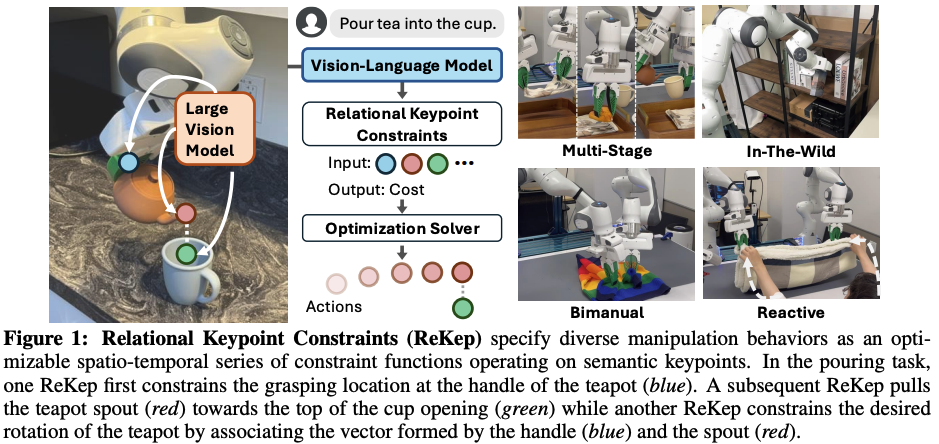
如上图所示,机器人需要抓握杯柄,在运送过程中始终保持杯身直立,将壶嘴对准目标容器(杯子),然后以特定角度倾斜杯子完成倾倒。此处的约束条件不仅编码了中间子目标(如对准壶嘴),还定义了过渡动作(如运送时保持杯身直立),这些约束共同规定了机器人动作在空间、时序及其他组合维度上与环境交互的要求。
上述例子中所谓的“约束”就是本文要提取的。所谓的“ReKep”可以理解为一个python function,将一系列3D关键点映射到数值成本(numerical cost),而每个keypoint是场景中跟任务相关的,具有语义的3D点。
- 视觉模型DINOv2用于提取关键点
- VLM模型用于将约束写成python函数 而获得了对应的约束后,通过优化求解就可以基于跟踪的关键点来生成robot actions。如下图所示,每个子action的坐标都可视化出来了:

GR-1
作者认为,生成式预训练模型对基于视觉的机器人操作(visual robot manipulation)任务是有利的。也就是说:基于过去的图像和语言指令预测未来帧的能力使机器人能够预测即将发生的事件,进而生成相关的动作。 因此,GR-1模型首先在大规模视频数据集上进行预训练,学习时空动态。随后,在机器人数据上微调,训练其根据环境感知生成合适动作并预测未来图像;
GR-1本文说一个GPT类型的模型,将语言指令、一系列观测图像,机器人状态作为输入,输出为robot action以及未来的图像。如下图所示。
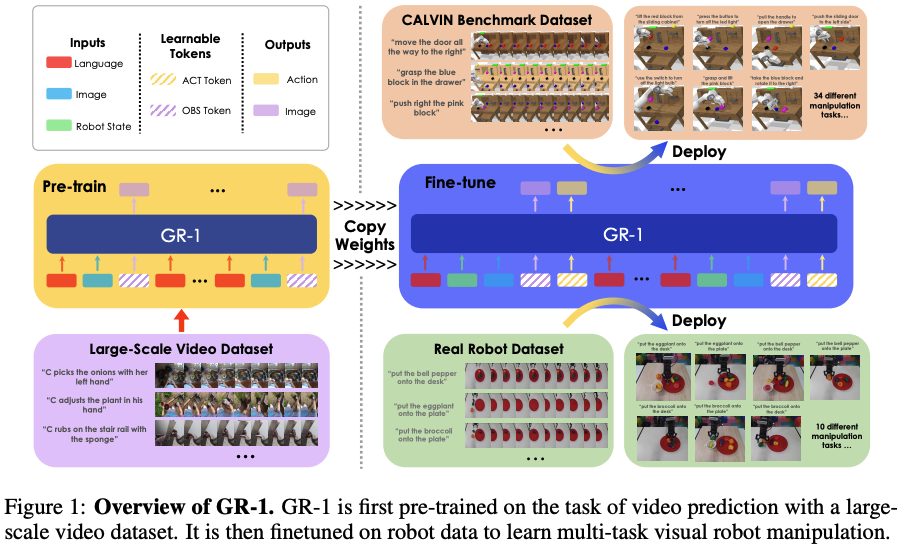
本文也是首次展示同意的GPT类型的transformer通过大尺度生成模型的预训练,可以有效地泛化到机器人操作任务上。 GR-1模型细节如下所示。左侧为输入编码器;右侧为输出解码器,负责动作生成和未来图像预测。
- 对于语言输入,采用CLIP的文本编码器
- 对于视觉观测,采用的ViT
- 对于机器人状态输入,采用线性MLP层
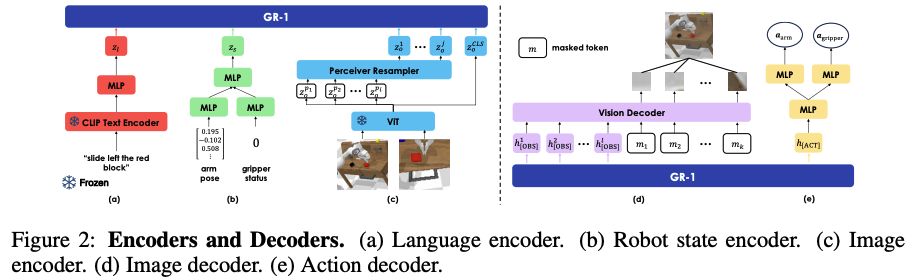
而实验效果则是主要在CALVIN 基准上成功率为76.4%~94。9%
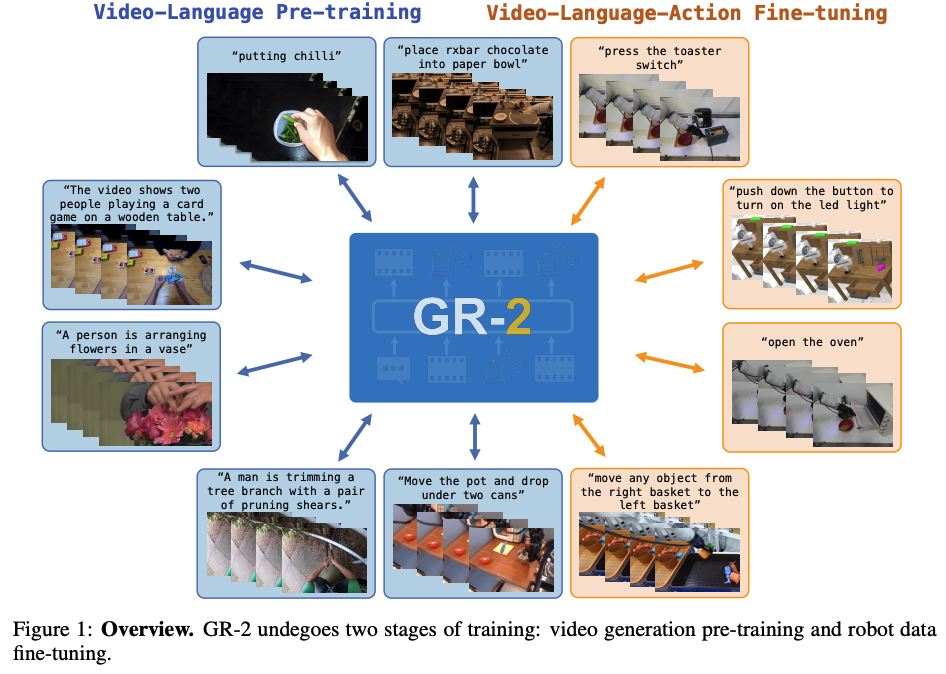
GR-2
GR-2是GR-1的进化版本(直观来看就是在GR-1的基础上,用了更多的更diversity的数据来预训练)。同样地,也是基于视频生成模型,通过大规模视频-语言预训练(Internet videos)和动作轨迹微调(video generation and action prediction using robot trajectories),进一步提升了机器人多任务操作的精度、连贯性和泛化能力,相比GR-1实现了显著的提升(在超过100个task上的平均成功率达97.7%)。
GR-2训练分为两个阶段:
- 进行视频-语言预训练,利用大规模互联网视频学习时空动态与语言描述的对应关系,超过38 million文本-视频数据
- 进行机器人数据微调,不再仅生成单点动作,而是学习连续的动作轨迹,以完成复杂的机器人任务
而为来将预训练获得的知识更好的转移到下游微调任务中,作者用了新的模型架构(但其实只是相比起GR-1换了text encoder,以及image部分采用了VQGAN)。 此外,通过whole-body control (WBC) algorithm来实现真实机器人部署的轨迹优化和实时运动跟踪。
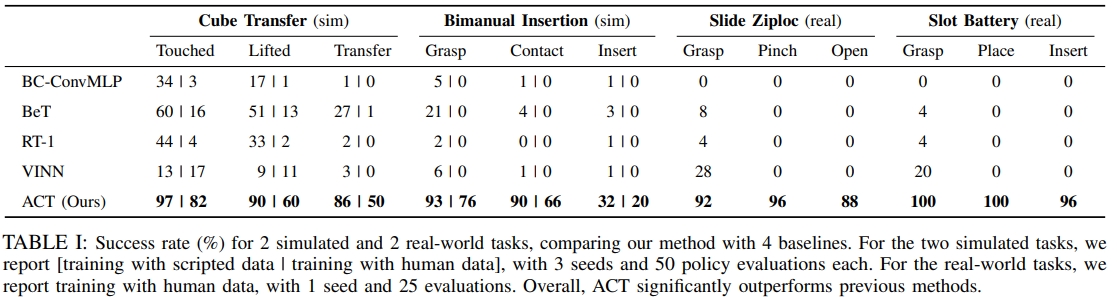
ACT
本研究中,作者致力于开发一种低成本、易获取且可复现的精细操作系统。为了实现这个目标引入了学习的机制。 人类并不具备工业级的本体感知能力,却能够通过从闭环视觉反馈中学习,并主动补偿误差,来完成精细任务。受此启发,作者在系统中训练了一个端到端策略,能够直接将普通摄像头拍摄的RGB图像映射为机器人动作。 而为了训练这个端到端的策略,作者构建了一个低成本(20K美金😂)但灵巧的数据采集遥操作系统
ACT(Action Chunking with Transformers)通过模仿学习,从真人演示(遥操作)中掌握精细操作任务(Fine manipulation tasks)。 为应对模仿学习存在的固有局限——例如策略误差随时间累积、人类示范行为不稳定等问题,研究者提出了基于Transformer的动作分块模型(ACT)。
该方法创新地引入动作分块与时间集成机制,构建了一个动作序列的生成模型。实验证明,仅通过10分钟的示范数据,机器人就能学会6项复杂操作,如打开半透明调料杯、精准插装电池等,成功率高达80%–90%。
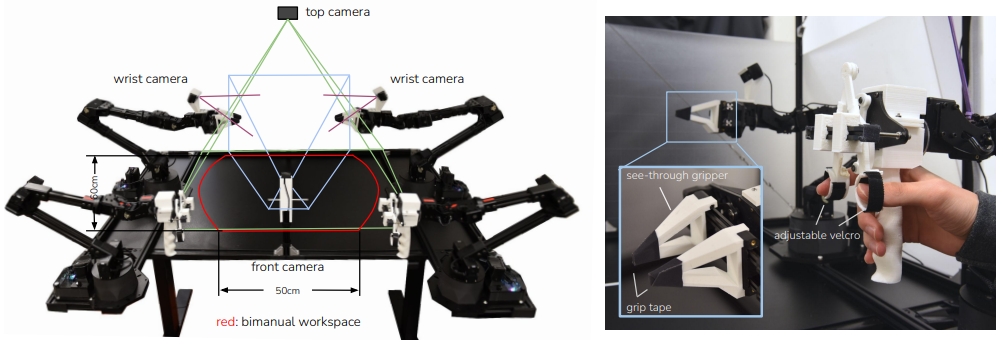
本文的主要贡献是一种低成本的精细操作学习系统,包括遥操作系统(如上图所示)和新型模仿学习(imitation learning)算法。所谓的新型模仿学习算法就是ACT引入动作分块机制。 动作分块由Transformer 架构实现,然后将其训练成条件变分自编码器(conditional VAE,CVAE)来捕获人类数据,进而实现高效平滑的动作预测。 ACT架构如下图所示。
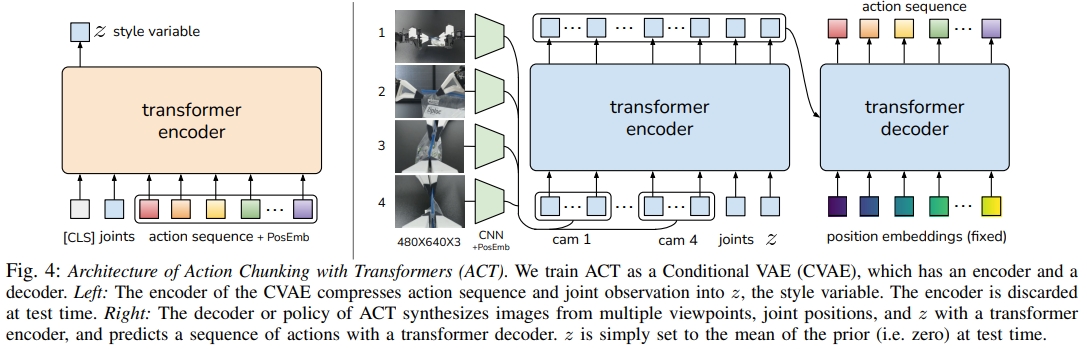
对于CVAE分为两部分:编码器(上图4的左边)与解码器(上图4的右边)。 编码器只有在训练解码器的时候用到,而推理/测试的时候是不用的。 而CVAE编码器(BERT-like transformer encoder)预测风格变量(style variable)z分布的均值和方差(参数化为对角高斯分布)。 而CVAE解码器(ResNet image encoders+transformer encoder+ transformer decoder),也就是policy,基于编码器给的z和当前观测(图像和关节位置)来预测动作序列。 而在测试的时候,z被设定为先验分布的平均值,即零到确定性解码( i.e. zero to deterministically decode)
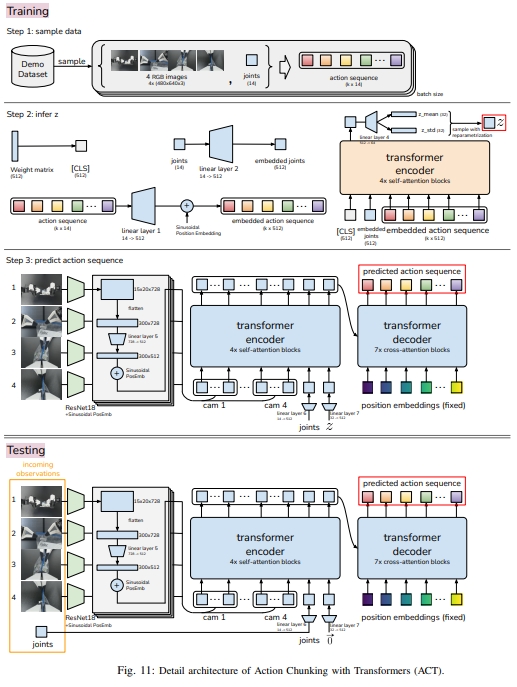
结构流程:
- 采用ALOHA采样数据;记录leader robots(也就是人类操作者的输入)的关节位置。注意,记录的关节数据是leader的,而不是follower的。
- 训练AVT来推理z,以获得CVAE解码器输入中的风格变量(style variable)z;
- CVAE解码器预测动作序列。此处每个action对应着两只机械臂下一刻的目标关节位置。而目标关节的位置则是由PID控制器实现的。
ACT在ALOHA系统(A Low-cost Open-source Hardware System for Bimanual Teleoperation, 一种低成本的开源硬件系统,用于双臂遥操作)上实现了对多种任务的学习与泛化,尤其在人类示范数据下表现出显著优于现有方法的性能和鲁棒性。

|

|
Octo
Octo是一个大型的,在 Open X-Embodiment 数据集的800K轨迹训练的,基于Transformer的policy。 作者期待设计一个预练好的通用机器人策略,通过fine-tune来用于下游任务。 因此,作者也宣称Octo是第一个通才机器人策略(generalist robot policies)可以通过fine-tuned到新的观测及action space。
此外,Octo也探索了采用diffusion model作为policy heads来实现连续的动作生成。
Open X-Embodiment dataset:是一个由 DeepMind 创建并开源的超大规模机器人数据集,汇集了来自 22 种不同机器人类型的数据。简称OXE dataset。
Octo 的整体架构如下图所示。左侧展示输入端,语言指令通过预训练语言编码器进行编码,图像则经CNN编码为token; 右侧上方为Transformer依次处理Task,观察token以及输出readout token(粉色的);而readout token再通过head生成action。 右侧下方为为通过分块注意结构灵活支持输入/输出扩展。
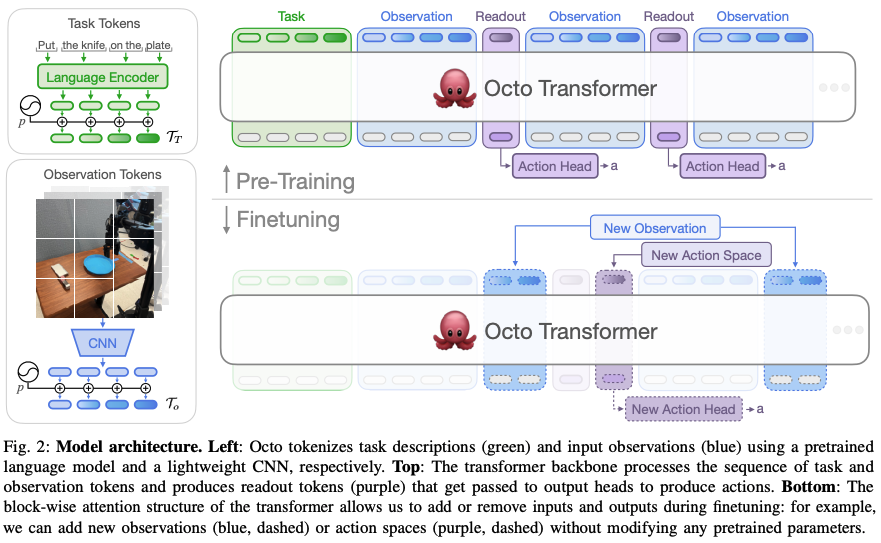
对于action的预测采用的是diffusion decoding,输出的是一系列的连续动作块(chunk)
而加入新的task、观测、或者loss等下游时,可以retain或者fine-tune整个网络(而主干网络上可以复用的,不需要根据任务重新初始化),仅仅需要添加新的位置embedding,新的编码器或者动作空间需要的新的head(比如不同自由度的机械臂)
RT-2
RT-2是正式提出VLA概念以及采用VLM作为骨架。
使单个端到端训练模型能享受基于网络语言和视觉-语言数据进行大规模预训练的优势,因此, RT-2旨在将VLM的语义推理与语言生成能力引入机器人控制,通过统一token 格式,将动作作为“语言”进行训练与推理,实现更通用、更具泛化能力的机器人策略。
作者提出提议对VLM模型进行联合微调,同时利用机器人轨迹数据和互联网规模的视觉-语言任务(如视觉问答)进行训练。 而为了既满足自然语言相应任务又满足机器人action的需求,将action表达为text token的形式,将他们以跟语言token一样的方式合并到模型的训练集中。
本质上本文就是采用预先训练好的VLM到VLA任务上,并验证其可行性~
而前人的做法还是重新训一个VLM for robot policy或者设计新的VLA结构。
像RT-1还是将大型的视觉-语言框架在大尺度的数据上训练的,而本文则是已有的VLM在小尺度的数据上fine-tune
RT-2架构如下图所示。机器人动作被表示为文本 token,与语言 token 使用相同的格式,统一纳入 VLM 的训练 流程中,从而实现闭环控制。该设计允许模型同时从机器人轨迹数据和大规模视觉-语言数据中学习,实现 语义理解与控制策略的融合。
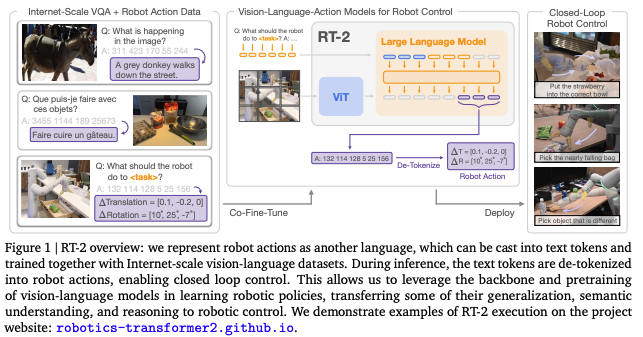
- 采用的VLM模型高达55B参数量(用网络数据以及机器人轨迹训练好的)
- 将action转换为蕾诗文本token用于fine-tune网络
- 超过6K个机器人测试验证其效果。
- 采用了两个VLM模型:PaLI-X和PaLM-E;
RT-2展现出显著的泛化能力和新兴推理能力,能够处理未见场景下的复杂任务,其背后依赖的是 VLM 中预训练语义知识的成功迁移与融合。
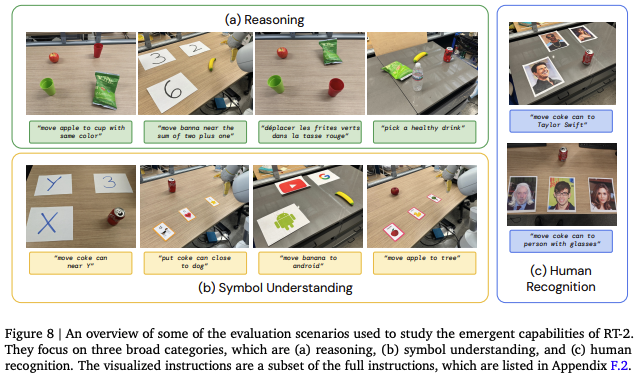 RT-2 展现的新兴能力分为三个维度:符号理解、复杂推理以及以人为中心的语义识别任务,反映了 VLM 预训练知识的迁移效果。
RT-2 展现的新兴能力分为三个维度:符号理解、复杂推理以及以人为中心的语义识别任务,反映了 VLM 预训练知识的迁移效果。
|
 RT-2 在不同泛化场景下的表现示例,包括未见物体、背景和环境
RT-2 在不同泛化场景下的表现示例,包括未见物体、背景和环境
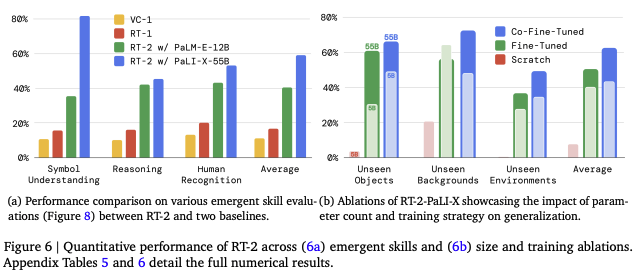 模型泛化性能对比
结论:1. 完全重训性能较差;2.联合微调效果更好;3.模型越大,泛化能力越强
模型泛化性能对比
结论:1. 完全重训性能较差;2.联合微调效果更好;3.模型越大,泛化能力越强
|
RT-2实验效果如下所示。在现实世界中评估RT-2,发现具有能够泛化到未见过物体的能力(emergent capabilities/应急能力),其中除了蓝色立方体之外,其他物体都没有在训练数据集中出现过。
OpenVLA
OpenVLA 是首个大规模开源的通用 VLA 模型,结合多模态编码与大语言模型架构,具备强泛化能力和高可用性,适用于多机器人平台。 它在包含97万个机器人操作轨迹的Open X-Embodiment数据集上进行训练。
该模型在多机器人控制和高效微调方面表现出色,其性能在29项任务中比参数量更大的封闭模型RT-2-X(550亿参数,OpenVLA为70亿参数,参数量少7倍)的绝对成功率高出16.5%。 OpenVLA 在涉及多对象和强语言基础的多任务环境中表现出强大的泛化能力,并且在将语言与行为结合的任务中,其微调后的策略明显优于从头开始的模仿学习方法(如Diffusion Policy)和预训练策略(如Octo)。
OpenVLA支持通过低秩适应(low-rank adaptation,LoRA)和模型量化(quantization)在消费级GPU上进行计算高效的微调和推理,而不会影响下游任务的成功率。这使得OpenVLA模型能够在消费级GPU上进行适应,而不是依赖大型服务器节点,同时不影响性能。
采用SigLIP与DNIO-v2作为视觉编码器来提取视觉特征,LLaMA tokenizer来进行文本指令的embedding,大语言模型(LLaMA2-7B)作为高层推理。 而LLM的输出则用于预测离散化action token。
LLaMA 2是一个大型语言模型(LLM),得益于互联网规模的预训练数据集所捕获的先验知识;
SigLIP是一个视觉语言模型(VLM),与单独使用CLIP或SigLIP编码器相比,融合DINOv2特征的SigLIP已被证明有助于改进空间推理能力,
OpenVLA其实就构建在Prismatic-7B VLM(如下图2所示)的基础上的。Prismatic拥有一个6亿参数(600M-parameter)的视觉编码器、一个小巧的两层MLP投影器,以及一个70亿参数(7B-parameter)的Llama 2语言模型作为其核心骨干。 Prismatic采用了双部分视觉编码器,由预训练的SigLIP和DinoV2模型组成。输入图像的补丁会分别通过这两个编码器进行处理,然后将生成的特征向量进行通道级联。 与更常用的视觉编码器(如仅使用CLIP或SigLIP的编码器)不同,DinoV2特征的加入已被证明有助于提升空间推理能力,这对于机器人控制来说尤其重要。
 OpenVLA 可在多种机器人平台上直接部署,并支 持参数高效的快速微调。
OpenVLA 可在多种机器人平台上直接部署,并支 持参数高效的快速微调。
|
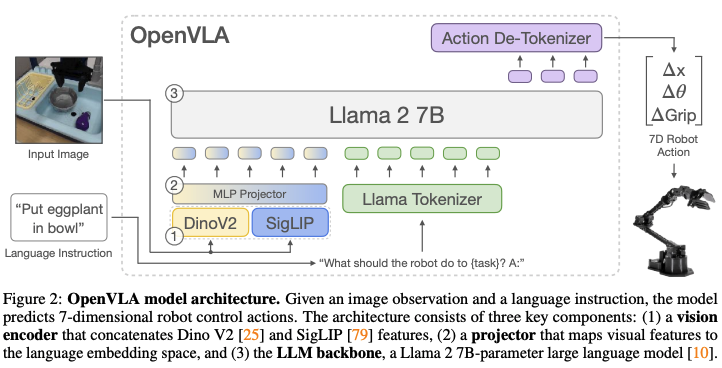 OpenVLA模型结构:输入为图像观察和语言指令,输出为7维机器人控制动作。
OpenVLA模型结构:输入为图像观察和语言指令,输出为7维机器人控制动作。
|
为了让VLM的语言模型骨干能够预测机器人动作,作者将连续的机器人动作映射到语言模型分词器使用的离散符号(token)来表示LLM输出空间中的动作:
- 离散化处理:将机器人动作的每个维度独立地离散化为256个bin。
- bin宽度设定:每个动作维度的bin宽度是根据训练数据中动作的第1个百分位数到第99个百分位数之间的范围均匀划分的。
- 避免异常值影响:采用分位数来设定边界。这样做是为了忽略数据中的异常值,因为异常值可能会大幅扩展离散化区间,从而降低动作离散化的有效粒度或精度。
实验效果方面,OpenVLA 在多个泛化维度下表现出色,全面优于现有通用策略,展现了开源模型在真实机器人控制任务中的强大潜力。
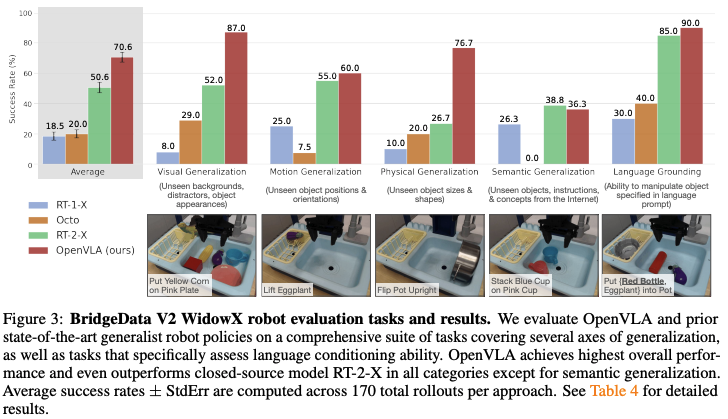
对于New Robot Setups,同样展示较好的泛化能力
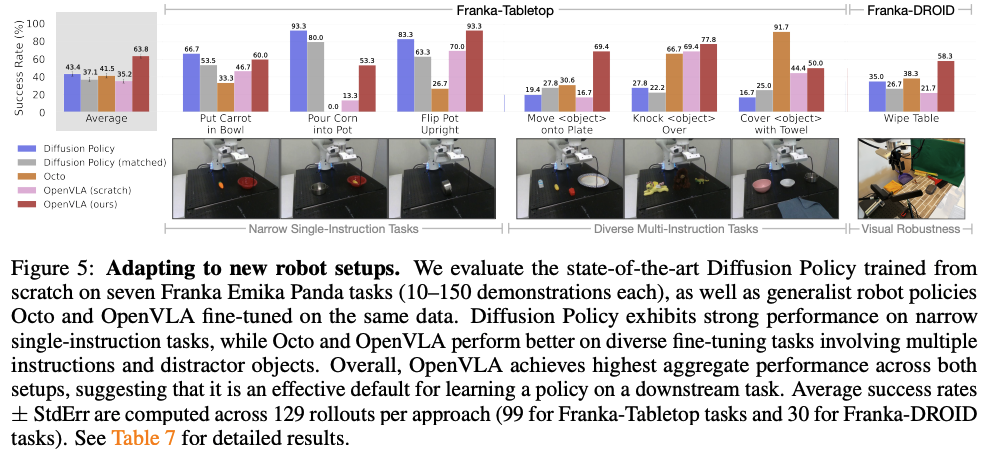
此外,网页显示:OpenVLA在Jetson AGX Orin 64GB,速率可达1.1~2.9FPS左右,成功率可达85%.
而论文在5.3和5.4节有介绍其Parameter-Efficient Fine-Tuning与 Memory-Efficient Inference via Quantization,涉及轻量化模型的话可以参考一下~
OpenVLA-OFT/OpenVLA-OFT+
OpenVLA-OFT是OpenVLA的优化及微调版本(Optimized Fine-Tuning, OFT),包括:不同的action解码方案(从原来的自回归解码变为并行解码)、不同的action 表征(原本是离散的变为连续动作表示)、以及微调的学习目标(采用L1回归):
- action decoding scheme (autoregressive vs. parallel generation): 使用动作分块的并行解码不仅提高了推理效率,还提高了下游任务的成功率,同时使模型的输入输出规范具有更大的灵活性;
- action representation (discrete vs. continuous):连续的动作表达比起离散的可以进一步提升模型质量
- learning objective (next-token prediction vs. L1 regression vs. diffusion):相比起基于diffusion,L1更容易收敛,推理速度也更快;
- 在OpenVLA-OFT基础上,引入语言增强模块(FiLM),就是OpenVLA-OFT+, 成功执行灵巧的双手任务,如折叠衣服和根据用户提示操纵目标食物(如下图所示)
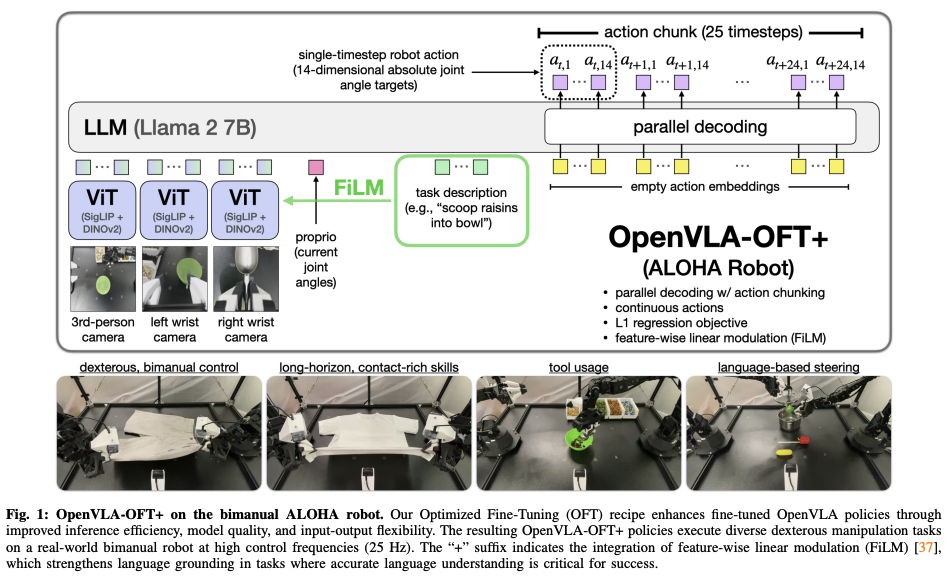
此处再次总结下OpenVLA:
7B-参数量的 Prismatic VLM,在Open X-Embodiment dataset上1M个轨迹微调。
采用自回归,在每个时间步预测7个离散机器人动作token:3个位置控制,3个方向控制,1个捉取控制;
基于交叉熵损失(cross-entropy loss)来预测下一个token
下图左侧为自回归和并行解码的对比,实用并行解码的目的其实是为了可以使用action chunking更加高效;
- 关于action chunking(动作分块),也就是在没有中间重新规划的情况下预测和执行一系列未来行动,可以很好的提升不同机械臂任务的policy success rate; 但原本OpenVLA的自回归(autoregressive)生成方案使得动作分块并不实际,因为即使生成单个时间步的动作都需要将近0.33秒(NVIDIA A100 GPU); 而对于一个K时间步以及D维度的action所组成的块,OpenVLA需要KD此解码器前向递推,而不是只需要D次递推而不进行分块(requires KD sequential decoder forward passes versus just D passes without chunking),延迟的K倍使得在原始formulation下高频机器人的动作组块变得不切实际。因此作者采用并行生成方案而不使用自回归。
- 对于自回归的VLA推理速度都比较慢(3-5HZ),不适合高频控制。所谓的autoregressive generation需要按顺序处理一个一个的token,而平板解码可以同时生成所有action,允许高效的action chunking
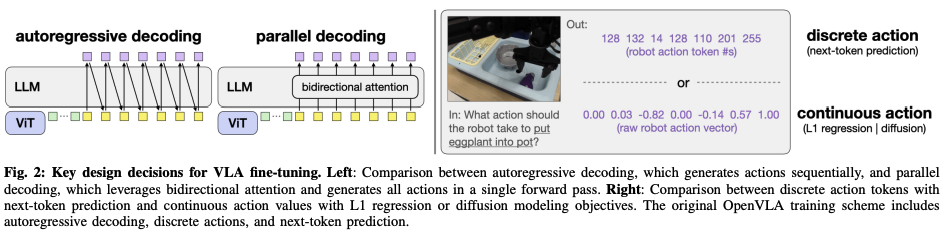
上图右侧为离散和连续动作L1或diffusion的对比;
- 对于离散的动作(256bin)通过基于softmax的token预测,而连续的则是直接由MLP action head生成。
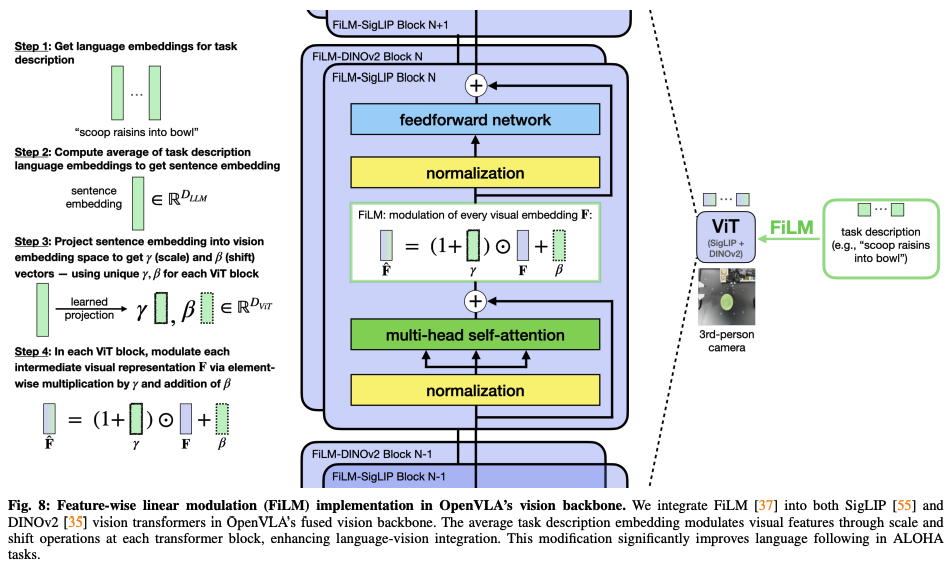
而所谓的FiLM,即Feature-wise linear modulation (特征线性调制),其架构如下图所示,插在SigLIP和DINOv2之间
- 作者发现当采用ALOHA 机器人setup时,由于视觉输入中的虚假相关性,policy可能会在语言跟随方面遇到困难。因此为了增强对语言增强采用FiLM,而FiLM将语言embedding跟视觉表征相融合,这样模型就可以更关注语言的输入。
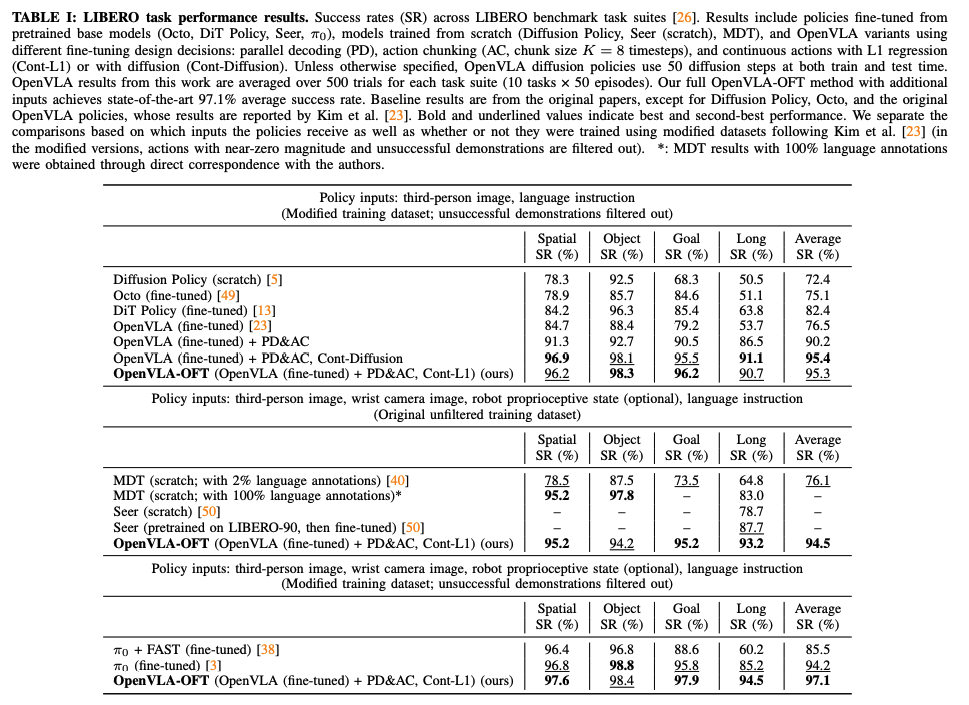
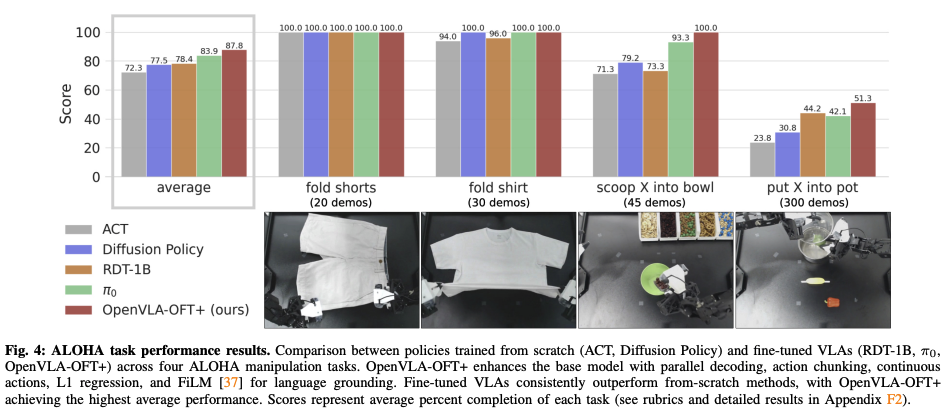
实验结果:在四个任务平均成功率从76.5%提升到97.1%,而action生成的吞吐量加快了26倍。而在ALOHA真实机器人实验中,超越其他VLA方法(π0 和RDT-1B).
- 如果配备25-时间步的动作块(25-timestep action chunks),OpenVLA-OFT+的吞吐量比OpenVLA快43倍
- 如下视频对比(更多对比效果请见网页),OpenVLA-OFT+相比其他VLA策略展示更好的语言理解与任务执行能力:
| ACT | OpenVLA-OFT+ |
| π0 | OpenVLA-OFT+ |
TinyVLA
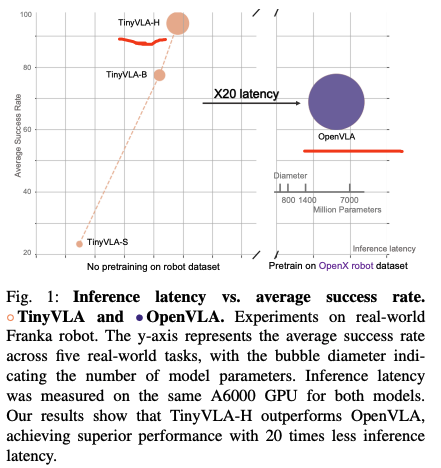
TinyVLA是为了探索如何在保留现有VLA模型优势的情况下,让其推理跟快,而数据效率更高(data-efficient); 传统的VLA模型之所以推理延迟高主要有两个原因:
- 基于大的视觉语言模型(一般都超过7B参数量);
- 通过自回归来生产离散的action token,这就要求对每个自由度进行重复推理;
TinyVLA也是基于OpenVLA的,通过轻量架构(VLM模型<1B参数量)与diffusion policy方法,在显著降低推理延迟的同时,保持甚至超越了原本OpenVLA的性能。
|
|
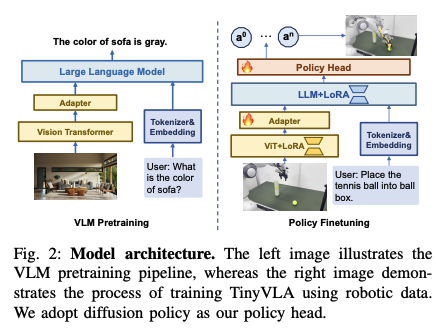
TinyVLA的模型架构如上右图所示:左图为多模态预训练流程,右图为基于机器人任务的微调流程。采用视觉-语言编码器、LoRA微调技术与轻量解码器,高效实现策略输出。
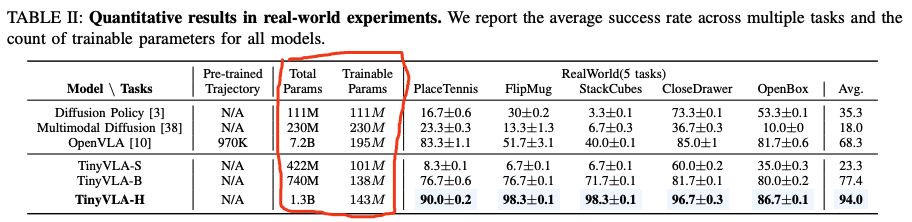
- 采用鲁棒、高速的(轻量化的)多模态模型。首先用预训练的VLM模型初始化,然后在机器人数据上训练时,先freeze预训练部分,然后采用LoRA(一种参数高效的微调技术,parameter-efficient finetuning technique)实现需要训练的参数仅仅为整个模型的5%;采用的是Pythia作为语言模型的后端,而采用的VLM模型参数从70million~1.4B参数量。
- 在微调的时候引入diffusion策略来作为解码器,以获取更精确的robot action。不再使用下一个token预测的方式来独立预测动作token,而是将一个基于diffusion的head附加到预训练的多模态模型上,以直接输出机器人动作
TinyVLA 在指令理解、物体变化以及视角迁移等多种泛化任务中均展现出优越的性能,说明即便是轻量模型也能具备强大的现实世界适应能力。
DiVLA
DiVLA 采用自回归(autoregressive)和diffusion模型来实现自主推理和机器人策略学习。本文的核心是自回归推理(由预训练的VLM实现的任务分解和解释过程)来指导基于diffusio的action policy。
- 自回归的VLA拥有较强推理能力(所谓自回归也就是next-token prediction,NTP),但是缺乏精确与鲁棒的动作生成,并且生成动作是不高效的(上面OpenVLA-OFT也提到了)
- diffusion较好实现动作生成(将action序列建模为去噪的过程),但缺乏推理的能力。
那么基于自回归和diffusion的优缺点,本文将
the reasoning power of autoregressive models与the robustness of high frequency action generation offered by diffusion models相结合。基于预训练的VLM模型,然后加入自回归的能力来进行重训以实现基于文本的推理。之后,再整合diffusion模型来通过去噪的过程学习机器人的actions。
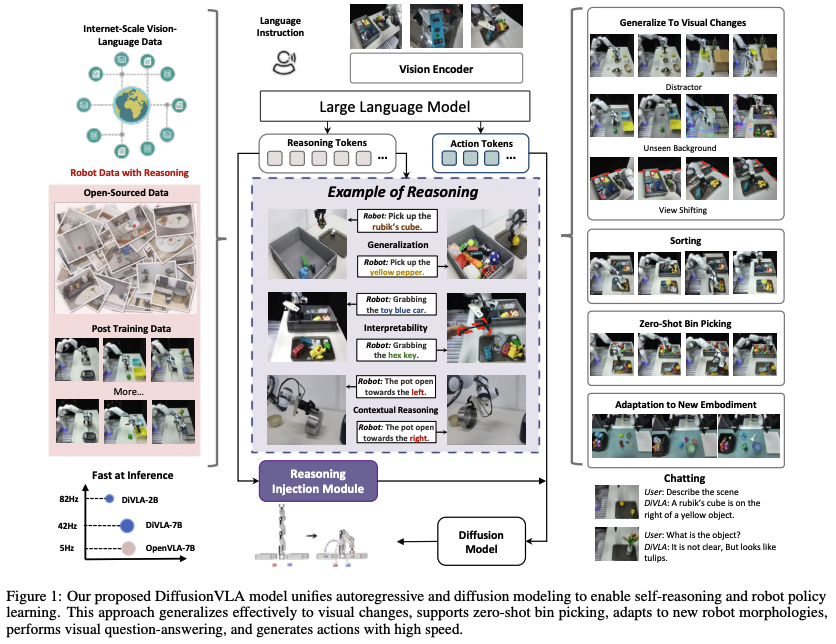
而为了将两者更加有机的结合,本文还提出了一个reasoning injection module:重用推理输出并将其直接嵌入到policy head中,从而用明确的推理信号丰富policy的学习过程。进而可以将推理融入到action生成中。 reasoning injection module通过从推理组件(reasoning componen)的标记化(tokenized)输出中获取最终embedding,并通过Feature-wise Linear Modulation (FiLM)将其直接注入策略模型。
实验效果:
- DiVLA-2B可以可以运行82HZ(单个A6000 GPU)
- 将模型从2B拓展到72B,发现:随着模型size的增加,泛化能力持续提升
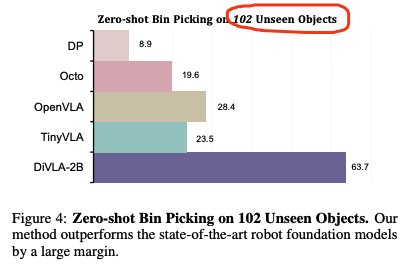
- zero-shot捉取任务,对102个未见物体实现63.7%的精度;
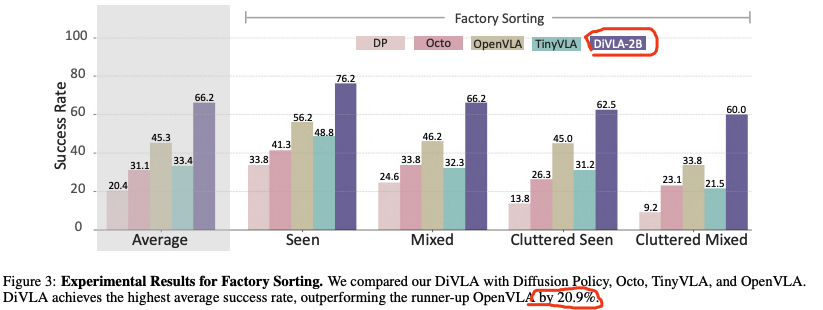
- DiVLA 显著优于 Diffusion Policy、Octo、TinyVLA 和 OpenVLA,在平均成功率上领先 20.9%
DexVLA
DexVLA(Plug-in Diffusion Expert for Vision-Language-Action models)通过三阶段的分离式训练策略,将扩散动作生成与多模态感知有效融合。 拟人的三阶段训练:
- Stage1 (cross-embodiment pre-training): 单独在交叉实体数据集(cross-embodiment)下,训练diffusion expert。
- 对于diffusion expert,考虑到传统action expert的缺陷,提出一个新的diffusion expert(大约是1B参数量),该diffusion expert拥有多个head结构,每一个head对应a specific embodiment,进可以实现跨不同形态的有效学习。
- cross-embodiment pre-training是为了学习底层的,共性的运动技能;
- Stage2 (embodiment-specific alignment):将VLA与具体的实体进行对齐;直观理解就是适应具体的身体;将视觉-语言表征跟特定机器人的物理约束相关联起来;仅仅此阶段就使模型能够完成各种任务,例如衬衫折叠、域内对象的垃圾箱拾取等
- Stage3 (task-specific adaptation):快速适应到新的task的后训练;让机器人掌握复杂的任务,包括长程任务(long-horizon tasks)和泛化到新的物体。 Stage2&3实际上就是实现:将训练好的diffusion expert与VLM融合
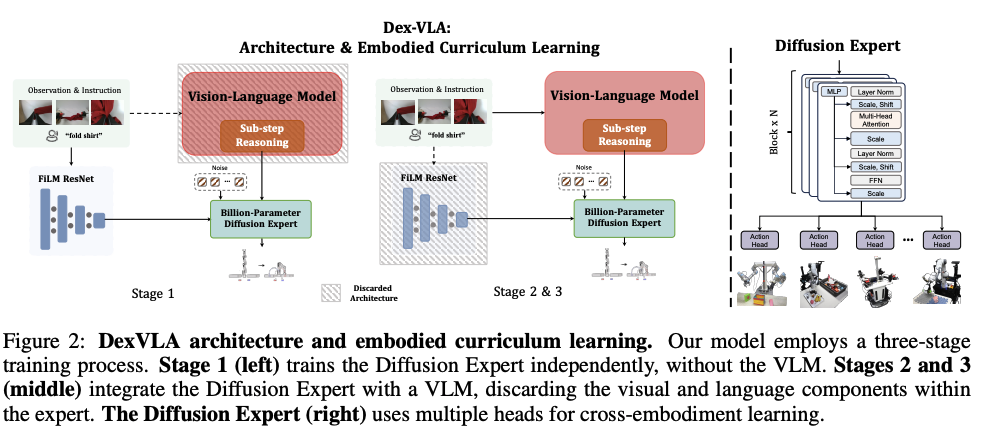
- VLM模型采用的是Qwen2-VL
实验部分:
- 在单个A6000GPU上可以跑到60HZ
- 无需任务特定适配的示例,包括 简易抓取、T恤折叠与桌面清理。
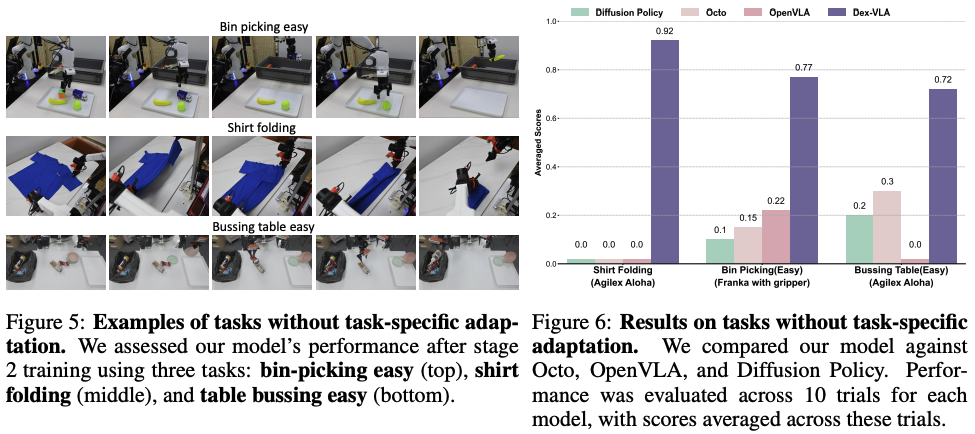
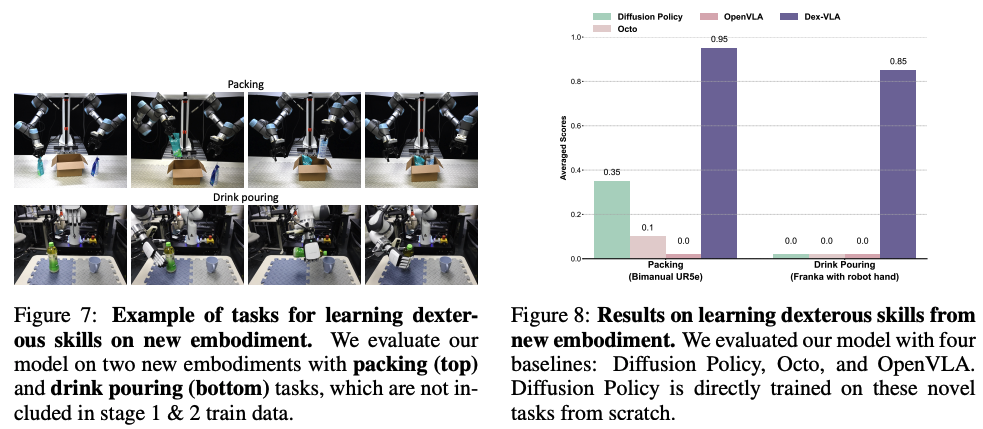
- 新机器人上的新任务示例,包括包装(上)和倒饮料(下),这两个任务未曾出现在阶段1和2的训练数据中
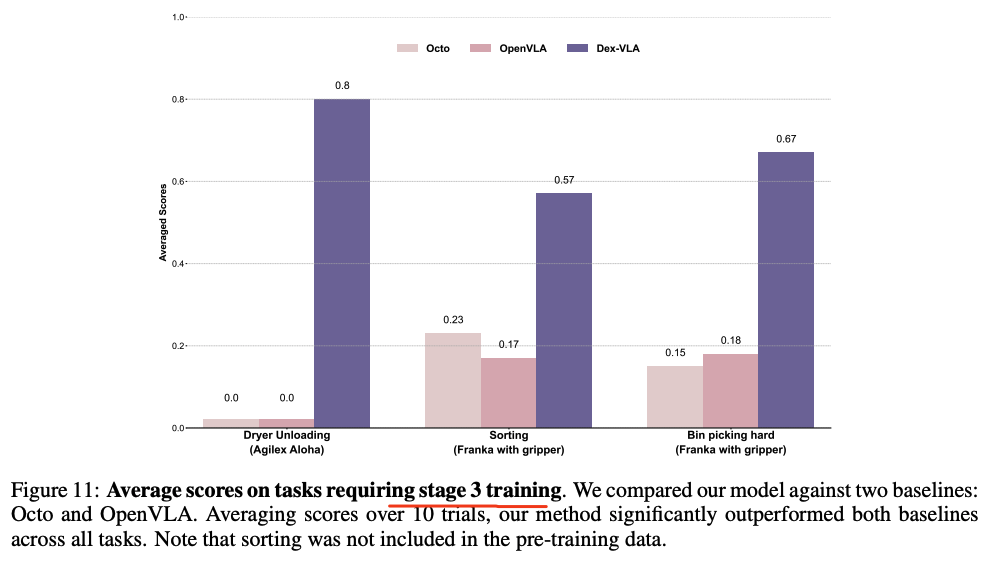
- DexVLA 能够处理复杂的长时任务(比如laundry folding/洗衣折叠),远超Baseline。

π0/PI0
Pi0(还有后面的pi0.5/pi0-fast)。都是Physical Intelligence的经典工作。 这类的方案具有多任务的泛化性与实时推理能力,也被称之为“Generalist Policy”(通才策略)
PI0是一个面向通用机器人的多模态控制模型,通过大规模多模态预训练和流匹配动作专家,构建了一个可扩展、可微调、可跨机器人部署的通用控制策略。
PI0是要实现通才模型(generalist model)的学习框架: 利用在互联网数据训练的VLM+action expert 组成一个VLA模型,这里结合开源+内部的机器人数据训练得到异构本体foundation model,然后可以在不同的本体/特定的任务上post-training,以完成多任务的泛化或某种复杂任务的灵巧操作(以高达50HZ频率控制机器人)。
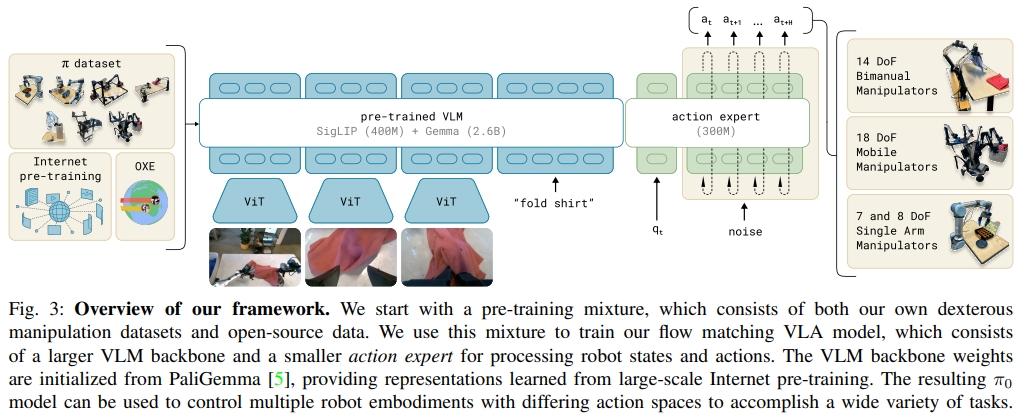
- 对于VLM,PI0中采用PaliGemma(使用大量互联网文本图像数据预训练的VLM)。通过。预训练的大模型实现从大量网络数据种获取
common sense/general knowledge; PaliGemma是在2024 年 Google I/O 活动上发布的。它是一种基于两个模型的组合多模态模型:视觉模型 SigLIP 和大型语言模型 Gemma,这意味着该模型是 Transformer 解码器和 Vision Transformer 图像编码器的组合。它将图像和文本作为输入,并生成文本作为输出,支持多种语言。 - 对于Action Expert:用于接受VLM输出,专门输出action的网络。为了能够执行高度灵巧和复杂的物理任务,作者使用了action chunking architecture架构和flow matching来表示复杂的连续动作分布。
- action chunking architecture:预测动作序列,核心思想是将动作分块(Chunking)与时间集成(Temporal Ensemble)结合,提升动作执行的平滑性和鲁棒性
- flow matching:diffusion的一种变体,flow match是噪声等于零的特解,更简单直接。
训练阶段:Pre-training ->post-training。百万兆级别的MLLM中常见操作也是分两个阶段,首先在一个非常大和diverse的语料库上进行预训练,然后在更具体、更特别的数据上进行微调:
- Pre-training:这里有面向于具身智能的专用数据集,如open x-embodiment dataset和 pi cross-embodiment robot datasets,这些数据中已经包含了大量场景的机器人操作数据。训练后可以得到foundation model,也就是一个可以统一所有任务/本体的基础模型,这样的模型具备初步的泛化性,但不一定在专项操作任务上有好的性能。
- Post-training(也可以题解为fine-tuning):根据上一个阶段的foundation model,进行fine-tuning, 这里分为两类任务的post-traing数据,以提高模型在某种任务表现的专门数据,包含unseen tasks(未见任务)、high dexterity task (高灵巧任务),一共包括20多项任务;
关于数据集的补充:
Open X-Embodiment dataset:是一个由 DeepMind 创建并开源的超大规模机器人数据集,汇集了来自 22 种不同机器人类型的数据. RT-2也这个数据集上训练的,简称OXE dataset。
Pi cross-embodiment robot datasets:pi0公司内部采集的本体数据集(灵巧操作数据集),共有7种不同机器人的配置,和68个不同任务的数据,长度为1w个小时。cross-embodiment robot 也可以理解为异构本体,不同的机器人类型具有不同的配置空间和动作表示,包括固定基座的单臂和双臂系统,以及移动机械手。
PI0可以完成的任务类型:
- Zero-shot in-distribution任务: Zero-shot 但是强调了任务的 in-distribution(这里不是场景的in-distribution)。通俗讲就是任务类型是见过的(比如清理桌台),但是具体到某种数据没见过,这样也可以一定程度泛化。
- 用特定任务数据微调后的困难任务:这里重点提及的是柔性操作的任务,如叠衣服(不同类型/颜色/材质的衣服在以各样的形状散落在场景中)
- 高效fine-tuning后的未见任务:训练阶段、后训练阶段都没有见过的任务,但是最终训完的模型却具备的能力
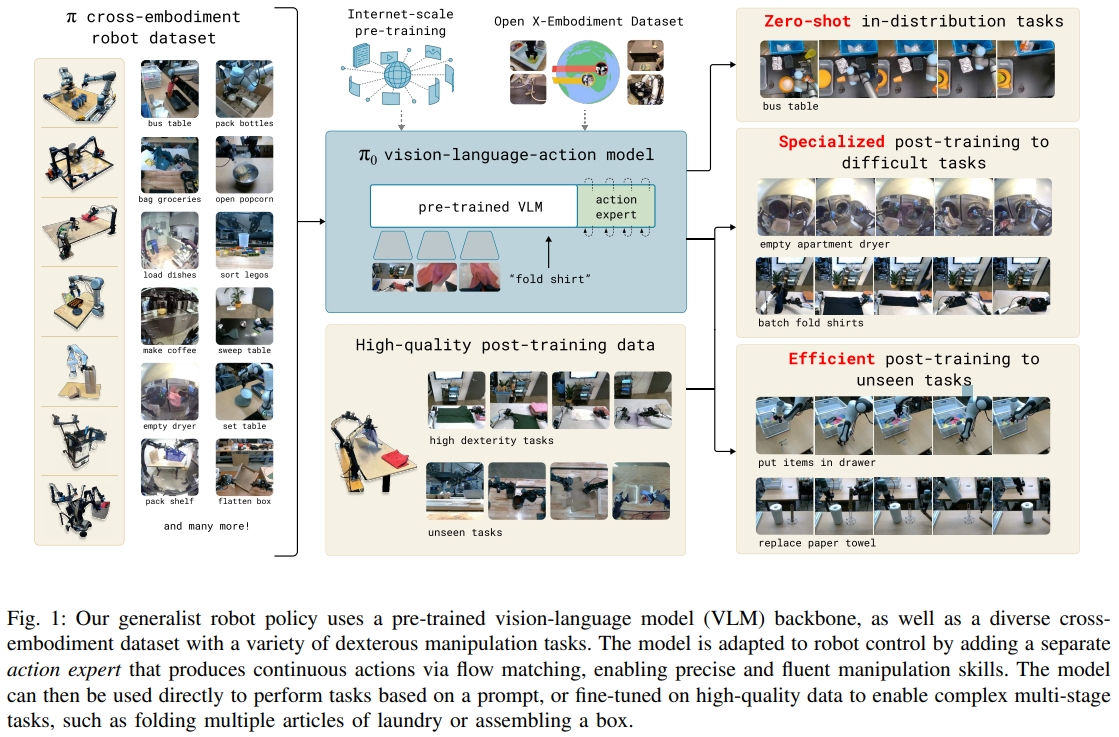
π₀在无需微调的开箱测试中已展现强大表现,经过微调后在复杂任务和语言理解方面更具优势,超越所有现有baseline。
试验阶段。通过5种测评任务来进行对比验证:
- 衬衫折叠:机器人必须折叠T恤,T 恤开始时是压平的。
- 简单清理餐桌:机器人必须清洁桌子,将垃圾放入垃圾桶,将盘子放入洗碗机。该分数表示放置在正确容器中的对象数。
- 困难清理:具有更多目标和更具挑战性的配置,例如故意放置在垃圾目标上的器皿、相互阻碍的目标以及一些不在预训练数据集中的目标。
- 杂货装袋:机器人必须将所有杂货装袋,例如薯片、棉花糖和猫粮。
- 从烤面包机中取出吐司
结果如下图7所示。π0 遥遥领先,在衬衫折叠和更轻松的餐桌整理上有近乎完美的成功率(接近100%)。
图9则是指令跟随能力(但此处对比只是不同参数量的PI0)。每个任务的文本说明包括要选取的对象和放置这些对象的位置,以及长度约为 2 秒的语言标记段。

|
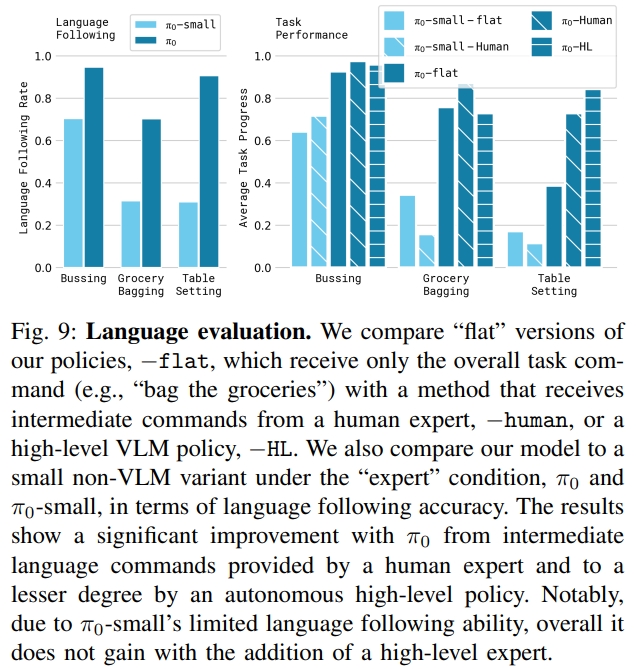
|
PI0在复杂真实任务中展现出前所未有的灵活性、恢复力与策略创新,标志着多模态机器人模型从“演示学习” 走向“自主通用”的关键转折点。
π0-FAST/PI0-Fast
前面的PI0是采用diffusion decoding的形式,进行k步 预测噪声去噪得到最终的action输出。 本文探索VLA训练的action representation;可以在高频数据上训练自回归 VLA。和diffusion的pi0相比,性能相当,但训练效率更快(时间减少5倍)。 FAST token化方案具有很少的超参数,并且可以高精度地重建动作,同时提供强大的压缩属性。
所谓的FAST就是频率空间动作序列Token化(Frequency-space Action Sequence Tokenization,FAST)。能够通过简单的下一个token预测来训练自回归 VLA policy;
- 动作信号在训练前进行压缩,也就是进行action tokenization:将H个动作映射为k个离散的token;
- 采用基于离散余弦变换discrete cosine transform (DCT) encoding;
- DCT Tokenization 是一种将整段动作序列用频率信息表达的 token 化方法,它能更有效地压缩和建模连续动作序列,特别适合高频控制场景。
- DCT其核心思想是:利用离散余弦变换(DCT)将整个序列转换到频域(frequency domain)
- 接下来对 DCT 系数矩阵进行离散化或量化,最终生成 token 序列;
- 先将Sparse frequency matrix转换为一组dense tokens。拉成一维向量,并把不同动作维度的频率值“交叉穿插”起来,形成一个长整数序列;
- 接下来采用BPE(Byte Pair Encoding)对这串整数进行无损压缩;
BPE是一种简单的数据压缩算法,它在 1994 年发表的文章“A New Algorithm for Data Compression”中被首次提出。
BPE每一步都将最常见的一对相邻数据单位替换为该数据中没有出现过的一个新单位,反复迭代直到满足停止条件。
例子:
假设我们有需要编码(压缩)的数据 aaabdaaabac。
相邻字节对(相邻数据单位在BPE中看作相邻字节对) aa 最常出现,因此我们将用一个新字节 Z 替换它。
我们现在有了 ZabdZabac,其中 Z = aa。
下一个常见的字节对是 ab,让我们用 Y 替换它。
我们现在有 ZYdZYac,其中 Z = aa ,Y = ab。
剩下的唯一字节对是 ac,它只有一个,所以我们不对它进行编码。
我们可以递归地使用字节对编码将 ZY 编码为 X。我们的数据现在已转换为 XdXac,其中 X = ZY,Y = ab,Z = aa。
它不能被进一步压缩,因为没有出现多次的字节对。那如何把压缩的编码复原呢?反向执行以上过程就行了。
实验证明,该方法和pi0结合时,能够扩展到处理10k小时的机器人数据,性能上媲美当前diffusion VLA模型,同时训练时间减少了多达5倍。
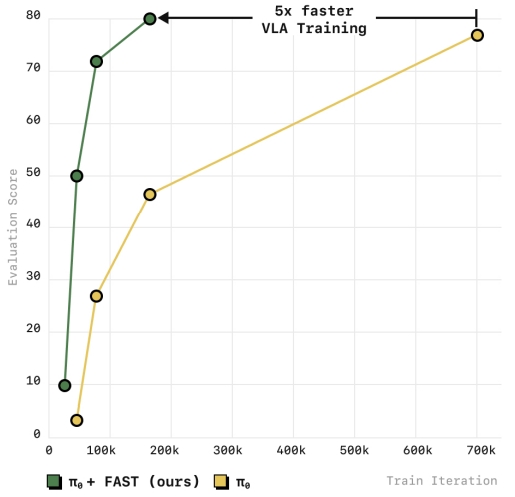
此外论文还探讨了tokenization如何影响VLA的training,此处先略过~
博客 是GRASP Lab 的一篇在复杂真实场景中(in the wild)评估PI0-FAST-DROID 的工作,在验证其强大性能的同时也发现一些缺点:
- VLM无法理解某些指令:与那些具有大量参数的商业聊天机器人不同,Pi0是基于 PaliGemma(一个非常小的 VLM 模型)构建的。它缺乏 LLM 可以用来识别不熟悉物体类别的常识性推理能力。当它无法理解命令时,就会卡住。
- 无记忆:Pi0是一种无记忆策略,这意味着它的下一步动作仅取决于当前的摄像头图像,它永远不会“记住”之前做过的事情。这适用于单次、快速的动作(例如拿起一个杯子),但当任务需要多个协调步骤时可能会失效。
- 空间推理不正确。 policy 缺乏一种精确的度量方法来确定夹持器与周围环境之间的距离。因此,在高度的空间推理方面存在困难。例如,当被要求拾取一个物体并将其放入容器中时,该策略无法将物体提升到足够高的高度以越过容器的高度。
- 纯粹基于图像的策略缺乏触觉反馈。在试验中,有时,机器人会对手指等精细物体施加过大的力,而对塑料瓶等较重物体施加的力又太小,无法牢牢抓住。
- 拾取和放置任务中,严重依赖腕部摄像头。即使侧摄像头被遮挡,仍然可以工作。腕部摄像头被遮挡,但侧面摄像头没有,效果会更差。
Hi robot
对于VLA,不仅需要理解语言,还需要能够在当前上下文中放置命令并组合现有技能来解决新任务。 这类似于 Kahneman 的快慢双系统。“快”系统 S 1 对应于能够通过触发预先学习的技能来执行简单命令的策略,而更具深思熟虑的系统 S2 涉及更高层次的推理,以解析复杂的长期任务、解释反馈并决定适当的行动方案。
Hi Robot是基于 PI0 方案搭建的快慢双系统,作者团队也称之为分层交互式机器人学习系统(hierarchical interactive robot learning system)。 Hi Robot系统在分层结构(hierarchical reasoning system)中使用 VLM,首先对复杂的提示和用户反馈通过VLM进行推理,以推断出合适的言语回应(verbal responses)与原子指令(atomic commands,例如抓住杯子),然后以传递到低级 policy中执行。 该low-level policy就是一个 VLA 模型,通过fine-tuned的视觉语言模型(VLM)来生成机器人的action(本文在PI0VLA上搭建的)。
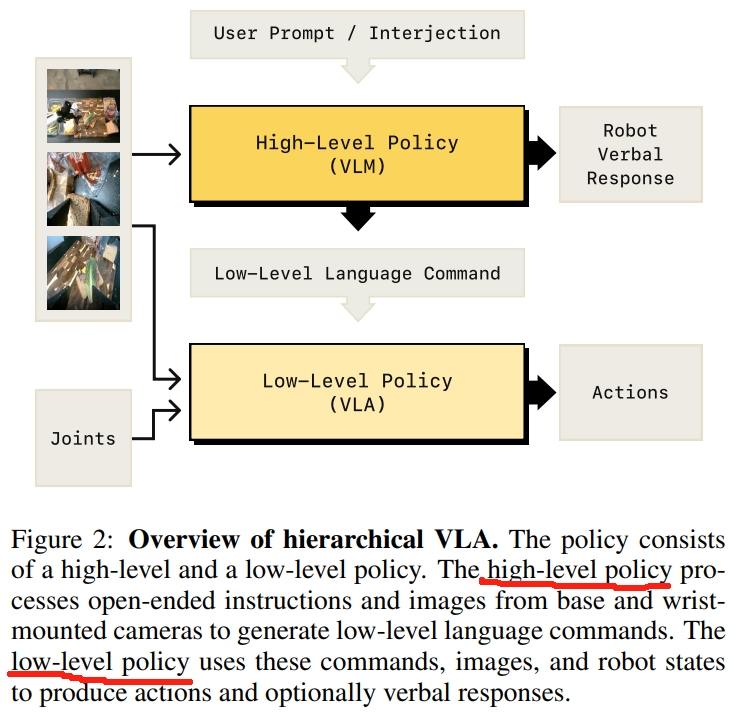
如上图所示。作者将policy分为底层和高层推理两部分:
- low-level policy:生成动作块的VLA(PI0,VLM+flow-matching),用以相应简单的、底层的语言指令
- high-level policy:处理开放任务提示词(open-ended task prompt)的VLM,用以输出底层语言指令来做底层推理。
这两个策略以不同的频率在运行,low-level policy以高频产生动作块,而high-level policy则是在设定时间后或收到新的语言反馈后调用(频率较低)。 故此,也称呼为“快慢系统”。
两个policy都是采用PaliGemma-3B VLM模型,而low-level policy则直接是PI0
此外,(这属于data collection以及训练部分了)用原子命令(atomic commands )注释的机器人演示不足以训练高级模型来遵循复杂的、开放式的提示( complex, open-ended prompts),因此需要复杂指令跟随的代表性样本(representative examples of complex prompt following)。作者对机器人观察到的状态和采取的动作进行“合成标注(synthetically label)”,即给这些数据配上假设性的指令或人类的互动语句,这些语句是有可能在当时情境下出现的。
本文主要的贡献点如下:
- 分层交互式机器人学习系统(hierarchical interactive robot learning system,Hi Robot)。使用VLM不仅进行抽象的“思考”(高层推理),还能指导具体的“行动”(低层任务执行)
- synthetic data generation scheme。合成数据生成方案来提升e low-level VLA policy性能。
此外,系统还有以下的一些特点:
- 用户可以在policy执行的时候打断,提供额外的信息、反馈、甚至改变整个task;而high-level policy也可以选择语言反馈用于做确认及澄清;
- 此外,还有一些感叹词(interjection),比如“leave it alone”,就是退回上一个command并且继续任务的执行。
而实验中,通过收拾餐桌、制作三明治、杂货购物这三个负责的指令来测试其性能。
- 收拾餐桌 (Table bussing):为有些物品需要细致的抓取策略(例如,从边缘抓取盘子),机器人必须拾取并分离不同的物品,在某些情况下甚至可能使用其他物品来操作(例如,拿起一个上面有垃圾的盘子,然后倾斜盘子将垃圾倒入垃圾桶)。在评估中,机器人会收到实质性改变任务目标的提示,例如“你只能清理垃圾,不能动碗碟吗?”、“你只能清理碗碟,不能动垃圾吗?”以及“收拾所有发黄的东西”。这要求高层模型对任务和每个物体进行推理(例如,识别可重复使用的塑料杯是碗碟,而纸杯是垃圾),然后修改机器人始终清理所有物品的“默认”行为。这包括理解要做什么以及不要做什么(例如,当被要求只收集垃圾时,避免触碰碗碟)。机器人还可能在任务期间收到情境化反馈,例如“这不是垃圾”、“剩下的别管了”或“别碰它”,这些都需要它理解干预并相应地做出反应。
- 制作三明治 (Sandwich making):数据包含不同类型三明治的示例,以及分段标签(例如,“拿起一片面包”)。使用这项任务来评估复杂提示,例如“你好机器人,你能给我做一个有奶酪、烤牛肉和生菜的三明治吗?”或“你能给我做一个素食三明治吗?我对腌黄瓜过敏”,以及实时修正,例如“就这些了,不要再加了”。
- 杂货购物 (Grocery shopping):包括从杂货架上取下组合好的所需物品,放入购物篮中,并将购物篮放到附近的桌子上。这项任务需要控制一个双臂移动机械手(参见图 4),并解释涉及可变数量物品的细微语义。提示示例包括“嘿机器人,你能给我拿些薯片吗?我准备开电影之夜了”、“你能给我拿些甜的吗?”、“你能给我拿些喝的吗?”、“嘿机器人,你能给我拿些 Twix 和 Skittles 吗?”,以及干预指令例如“我还要一些 Kitkat”。
π0.5/PI0.5
PI0.5 是 PI0、Hi robot 的进一步升级版本. 核心的解决方案就是(多源联合训练 + 序列建模统一模态 + 层次规划推理 )相当于是把 PI0Z+PI-FAST+Hi Robot 的方案进一步升级了。其架构如下图所示。

π0.5就是在π0的基础上,通过采用异构的任务联合训练来获取更好的泛化能力。 所谓的异构数据指的是:多个机器人、高层语义预测、网络数据,以及其他可以增强机器人泛化能力的数据。 通过将不同模态联合到相同的序列化框架下,进而实现可以把机器人、语言、计算机视觉等数据都结合起来训练。
数据包括:
- 移动机械臂在不同的真实家庭环境下的数据(400 小时)
- 非移动机器人,在实验室条件下采集的数据。
- 基于机器人观测的高层语义任务
- 人类监督员给机器人的语言指令。
- 来自网络的多模态数据
训练阶段,采用的仍然是类似双系统架构。:
- 首先,模型首先通过标准的VLM(建立在PI0的基础上,也是采用的PaliGemma)来初始化权重。然后,在异构任务数据下,对模型进行预训练;
- 然后基于底层运动样本和高层语义动作来联合微调机械臂;在post-training阶段,模型也需要跟π0一样有一个action expert,来以更精细的粒度表示动作,并为实时控制提供更高效的计算推理。
模型架构如下图所示。
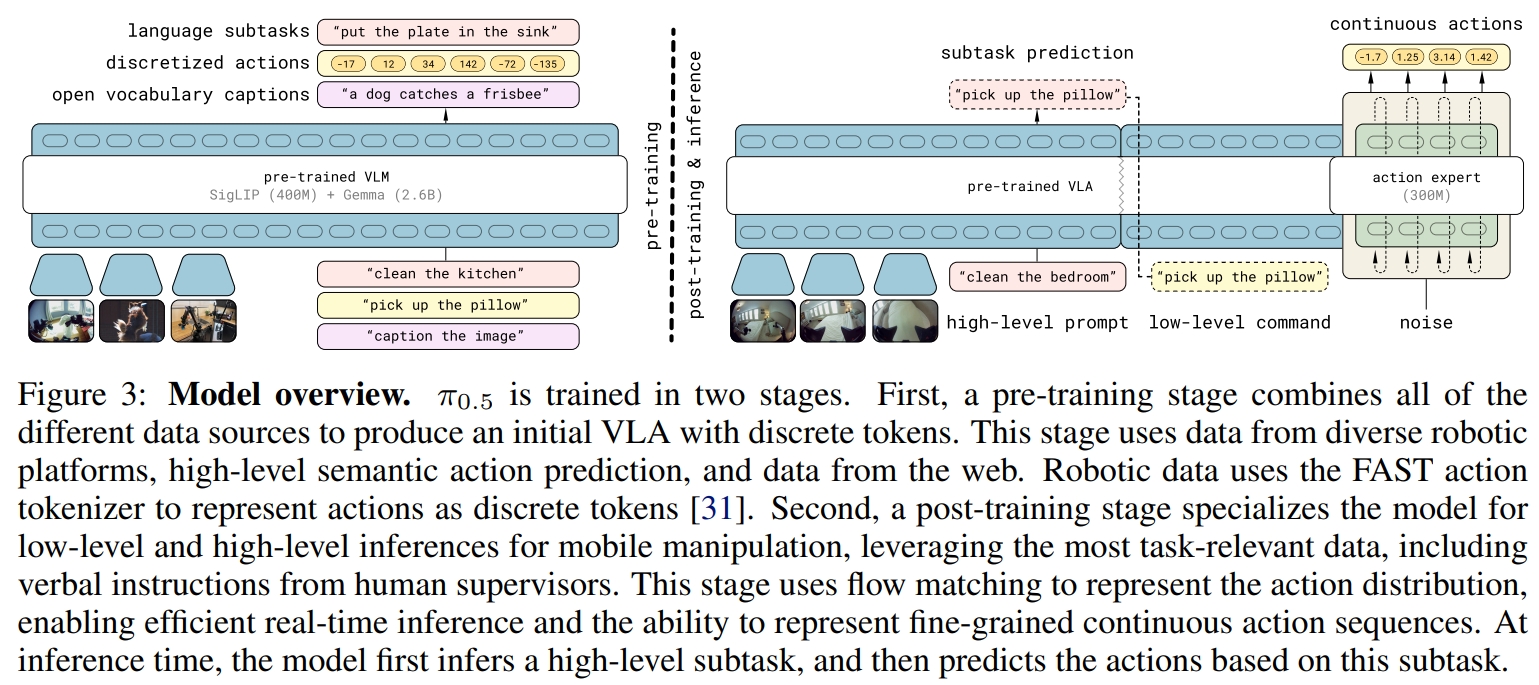
而在推理阶段,模型首先预测语义子任务,基于任务结构以及场景语义来推断机器人的下一个要执行的行为。然后再预测基于该子任务的动作块。 这为模型提供了通过长期行为(long horizon behaviors)推理的能力,并在低层次和高层次上利用不同的知识。
PI0.5也是首个实现长期(long-horizon)及灵巧机械臂操作。这里的long-horizon理解是长时间的任务,比如在完全新的家庭内,清洁厨房和卧室等。
下图展示了PI0.5在不同环境下的实验效果。从上到下,分别是:把物体放到柜子里;把碟子放到洗碗槽;把衣服放到洗衣篮。

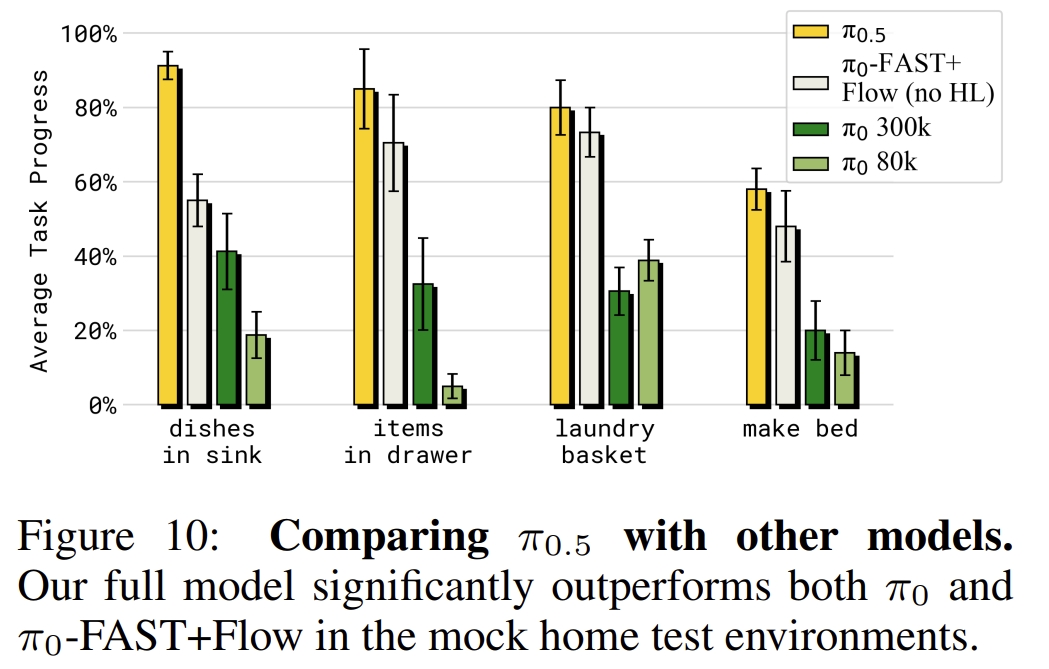
下图则是PI0.5跟PI0和PI0-Fast的对比,用的衡量指标是任务的进度:
LAPA
LAPA是首个通过无监督学习(没有真值机器人action label)来训练VLA模型的方法。而现有的大多数VLA工作都需要action label(一般是由人类操作员收集的),这大大限制了数据的来源以及尺度。 因此,本文提出通过互联网视频数据(internet-scale videos )来学习潜在动作(latent action)、并结合小规模机器人数据进行微调。
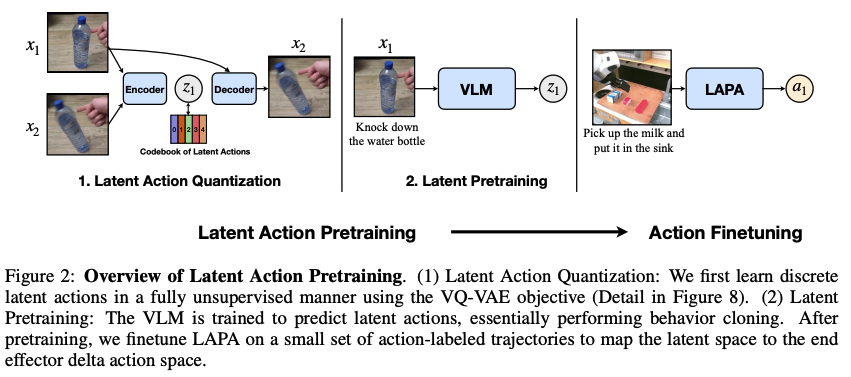
下图为LAPA整体流程,包括三个阶段:
- 潜在动作量化(Latent Action Quantization)模型的训练:通过VQ-VAE来学习图像帧之间的离散latent action,采用的量化模型为C-ViViT tokenizer的变种。
- 潜在预训练(Latent Pretraining):通过latent VLM model来根据观测和任务的描述生成latent action
- 动作微调(Action Fine-tuning):通过小规模的机器人操作数据来进行微调,实现将latent映射到机器人action上。 三个阶段联合实现如何将互联网视频中隐含的行为知识转化为可用于机器人操作的技能模型。
下面是一些实验效果:
- 用毛巾盖住甜甜圈:
 OpenVLA
OpenVLA
|
 LAPA
LAPA
|
- 敲击物体进行清洁:
 OpenVLA
OpenVLA
|
 LAPA
LAPA
|
GO-1
该工作首先提出了AgiBot World,是一个大规模的机器人数据平台,包含5个场景下,217任务,超过一百万条机器人轨迹。在该数据集下预训练的policy比起在Open X-Embodiment上训练的能提升30%
而在数据集的基础上,作者提出了Genie Operator-1 (GO-1),通过利用 latent action representations来最大化数据利用。 对于此前大部分的机器人基础模型都严重依赖于域内的机器人数据,而GO-1则是通过latent action representations来实现从异构数据中学习,并有效地将通用VLM模型与机器人顺序决策联系起来。 通过对网络规模数据的统一预训练,将人类视频转换为我们的高质量机器人数据集,GO-1实现了卓越的泛化能力和灵活性。
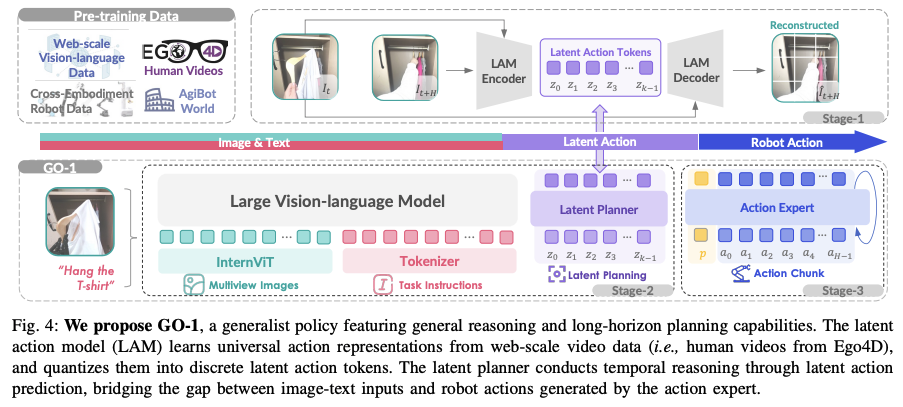
GO-1是一个层次视觉语言潜在动作框架(hierarchical Vision-Language-Latent-Action,ViLLA),如下图所示,传统的VLA模型是基于视觉-语言条件的action,而ViLLA模型预测的是latent action tokens,后续的机器人动作生成则是基于latent action tokens。
- Stage1(Latent Action Model):基于internet-scale的异构数据,训练一个encoder-decoder latent action model (LAM),将连续的图像投影到latent action space。这使得latent action可以作为一个中间的表达来连接图-文输入和机器人action;
- 此步的目的其实就是把异构的真实数据集转换为通用的机器人知识;
- Stage2(Latent Planner):latent actions作为伪label来训练latent planner,进而实现与实例无关(embodiment-agnostic)的长程规划并利用预训练的VLM的通用能力。
- 此步采用的是 InternVL2.5-2B作为VLM的骨架,将LAM学到的机器人通用知识与VLM的通用能力相结合
- Stage3(Action Expert):结合action expert,跟latent planner进行联合训练。
- action expert采用的是diffusion来获取连续的底层action。
- action expert与latent planner共享相同的架构框架,但是它们的目标不同:latent planner通过掩码语言建模生成离散的潜在动作(discretized latent action )token,而action expert通过迭代去噪过程回归底层动作。
实验效果:
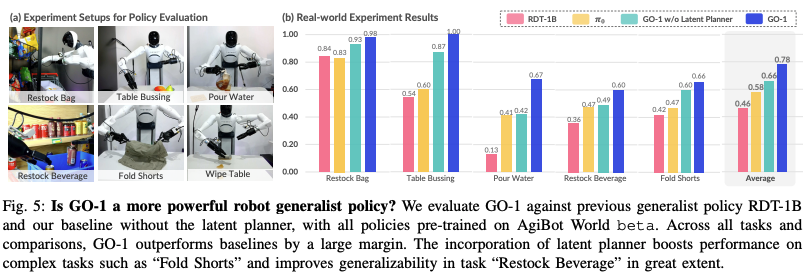
- Go-1相较于RDT-1B和去掉latent planner的对比效果:
AnywhereVLA
本文通过将微调的VLA操纵,与探索、SLAM等传统任务结合,实现了移动机械臂(Mobile manipulation)的VLA任务。 系统架构如下图所示。
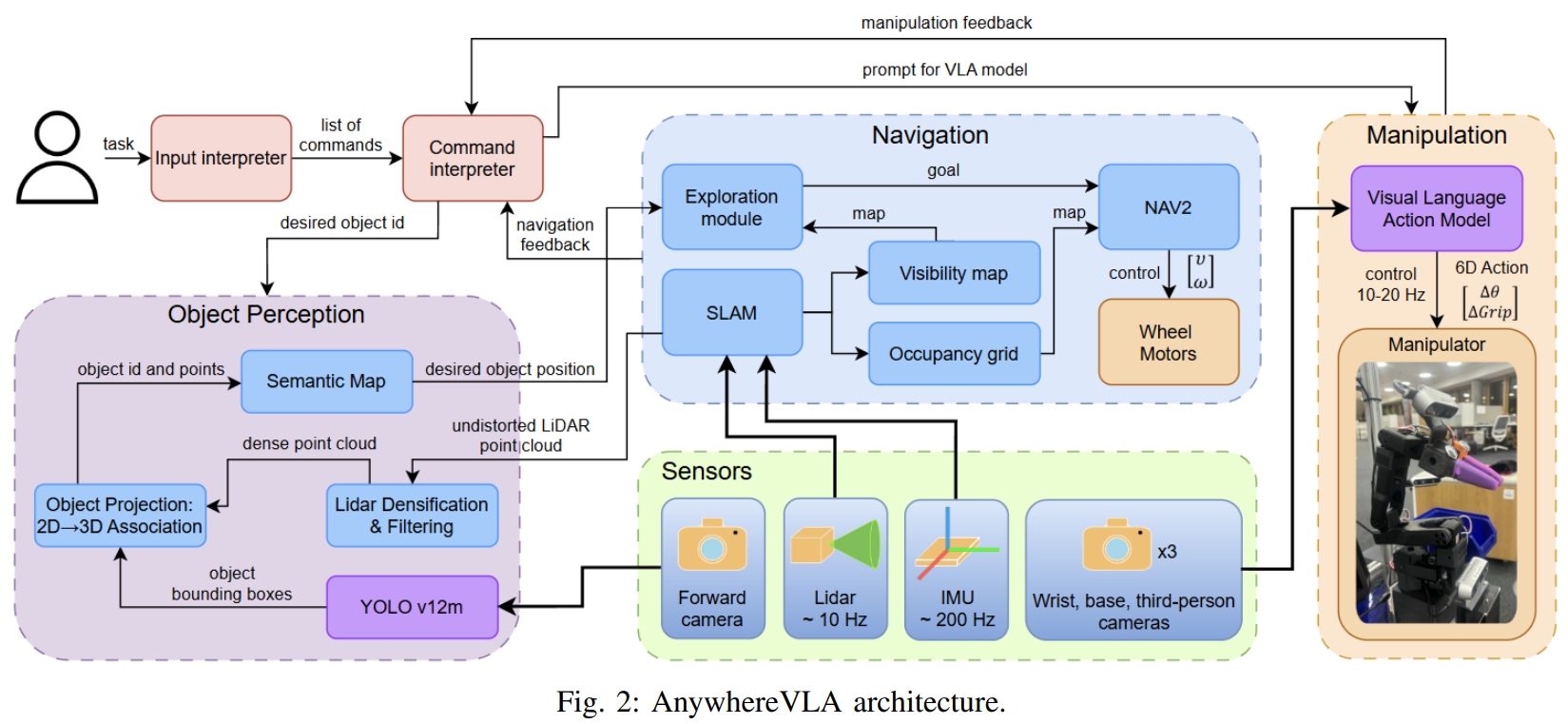
workflow通过语言指令作为输入,然后同时执行VLA模块实现基于task的操纵以及自主探索。主要分为三个部分:
- 3D语义建图。通过雷达-惯性-视觉SLAM(Fast-LIVO2)构建3D点云地图,而语义部分来自于目标检测模块。
- 主导环境探索(Active Environment Exploration,AEE),基于语言指令推导出的目标物体类来执行frontier-based exploration。一旦检测到目标对象并在语义图中定位,探索就会停止。而探索部分则是将LiDAR点云投影成2D栅格地图。
- VLA操作,采用的为fine-tune(在SO-101机械臂上训练)的SmolVLA模型。
主体推理框架仍然采用预训练的VLM(对机器人轨迹数据和互联网规模的视觉语言任务进行联合微调)。 而为了保证可移动性,利用了传统的navigation stacks。 既利用了传统SLAM导航的鲁棒性,同时也利用了VLA模型对环境的泛化理解能力。 属于传统方法跟VLA的结合版本。但个人认为只是让其可移动(Mobile manipulation),对于VLA任务本身,SLAM与导航似乎是不起任何帮助的😂
其他补充:
- 感知及VLA部分运行在Jetson Orin NX上,而SLAM,探索以及控制则是运行在Intel NUC上;
- 任务成功率:46%
- 目前项目还没开源,但后续应该是有开源的打算吧Website, Github
Helix
Helix是 Figure的专有视觉-语言-动作系统。 通过端到端联合训练的快系统(S1)与慢系统(S2),实现了机器人在广泛任务中兼顾深度理解与快速响应,突破了以往通用性与实时性难以兼顾的瓶颈。
- 多机器人协作 (Multi-robot collaboration):首个能让两台机器人同时协同工作的VLA 模型;
- 全上身控制 (Full-upper-body control):Helix 是第一个能够高频率、连续地控制机器人整个上半身的 VLA 模型,包括手腕、躯干、头部,甚至独立的每根手指。
- 拾取任何物品 (Pick up anything):解决了机器人“抓取泛化”的巨大挑战,大大提高了机器人的通用性和适应性,不再需要为每种新物品都进行特定训练。
- 单一神经网络 (One neural network):与以往需要针对不同任务训练不同 AI 模型的方法不同,Helix 使用一套神经网络权重就能学习并执行所有行为——无论是抓取放置、使用抽屉冰箱,还是机器人间的协作,无需针对特定任务进行微调。
本质上就是利用了大模型LLM或VLM实现即时泛化,将VLM中抽象的“常识性知识”(比如“拿起物体需要张开手”)转化为“可泛化的机器人控制”(即具体的机械臂运动指令,并能适用于各种不同形状的物体)。将 VLM 的高级语义理解转化为机器人能够执行的低级物理动作,并且能够将这种理解泛化到新颖的环境和物体中。
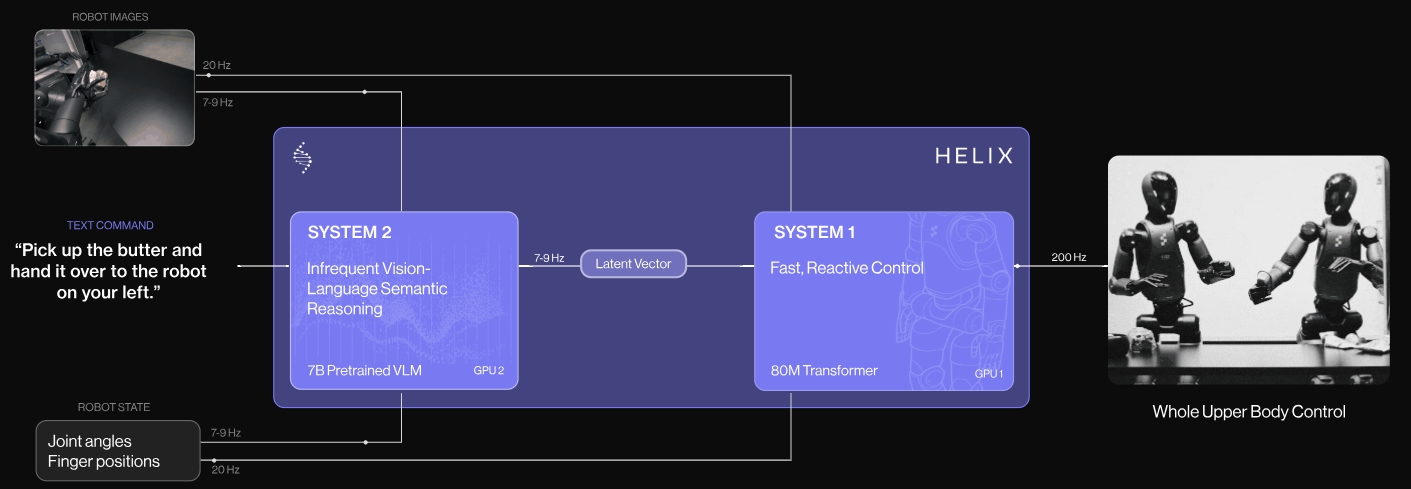
系统结构由两部分组成(快慢双系统,类似自动驾驶领域的 DirveVLM),S2与S1串联,异步推理:
- 上层模型 S2:VLM,构建在开源的7B参数量的VLM模型上。处理单个机器人的图像以及机器人的状态信息(包括手腕姿势和手指位置),然后投影到视觉语言的embedding space。结合语言命令对应的目标动作,S2将所有语义任务相关的信息提炼为latent vector,然后传到S1来执行low-level action;
- 下层模型 S1:latent-conditional visuomotor transformer,是一个80M参数的cross-attention encoder-decoder transformer用于实现底层控制。输入为跟S2一样的视觉与状态输入。对于视觉的输入采用全卷积以及多尺度的骨架。对于来自S2的latent vector投影到S1的token space上,然后跟视觉特征concatenated到一起。
数据采集部分:采用自标签(auto-labeling)的VLM来生成指令,根据机器人机载camera获取的视频来生成指令。
Helix以200HZ频率控制着35个自由度的动作空间,
GR00T N1
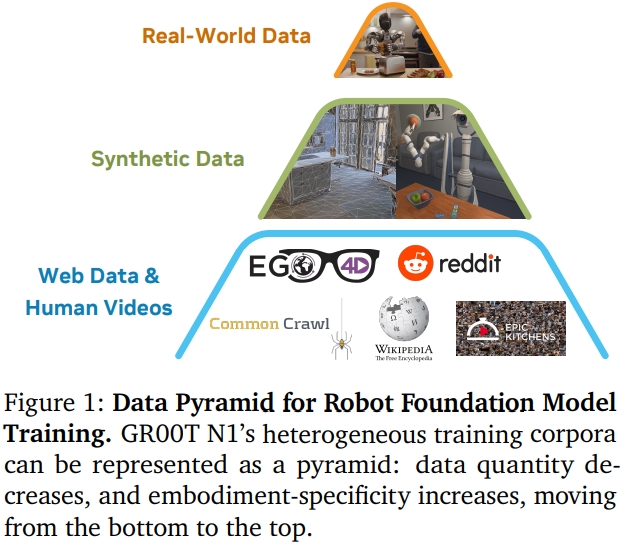
GR00T N1是NVIDIA Research提出的一个人形机器人的开源基础模型(VLA with dual-system architecture)。 为了避免“data island/数据孤岛”问题。其训练是由异质的真实机器人轨迹、人类视频、合成/生成数据集。
- System2(推理模块):是预训练的VLM模型(NVIDIA Eagle-2 VLM),在单个 NVIDIA L40 GPU上跑10HZ。
- System1(action模块):是一个由flow-matching训练的Diffusion Transformer,宣称能以120HZ生成闭环的电机动作(closed-loop motor actions)
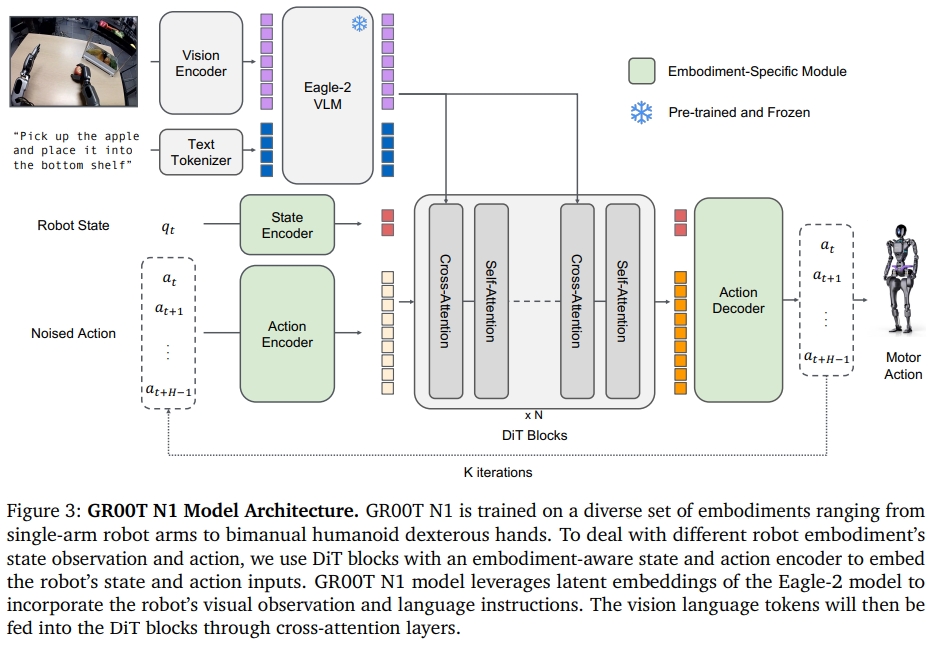
- 对于不同机器人本体不同维度的状态和action,采用一个MLP来投影为DiT标准的输入。
- 采用action flow matching,通过迭代去噪来采样action;
- NVIDIA Eagle-2 VLM:采用的是SmolLM2(作为LLM encoder)和SigLIP-2 (image encoder)来组成的。图像分辨率为224*224,
推理时间对于16个actions的采样块为63.9ms;
实验部分也在GR-1人形机器人上验证,而 GR00T-N1-2B模型(一共是2.2B参数,VLM部分占了1.34B)也开源了。
GR00T N1.5
N1.5是N1的升级版本,主要的不一样的地方有两点:
- 预训练和finetuning的时候VLM都被冻住,且VLM模型更新至Eagle 2.5(具备更出色的定位能力和物理理解能力);
- 连接视觉编码器与语言模型(LLM)的适配器多层感知机(MLP)被简化,并在输入到 LLM 的视觉和文本token嵌入中都添加了层归一化(layer normalization);
- 除了 N1 所使用的流匹配损失外,对于 N1.5,作者还添加了未来潜在表示对齐(参见FLARE项目)FLARE 并非生成性地对未来的帧进行建模,而是将模型与目标未来的嵌入进行对齐.
- DreamGen引入通过 DreamGen 生成的合成神经轨迹,从而能够泛化到超出遥操作数据的新行为和任务。
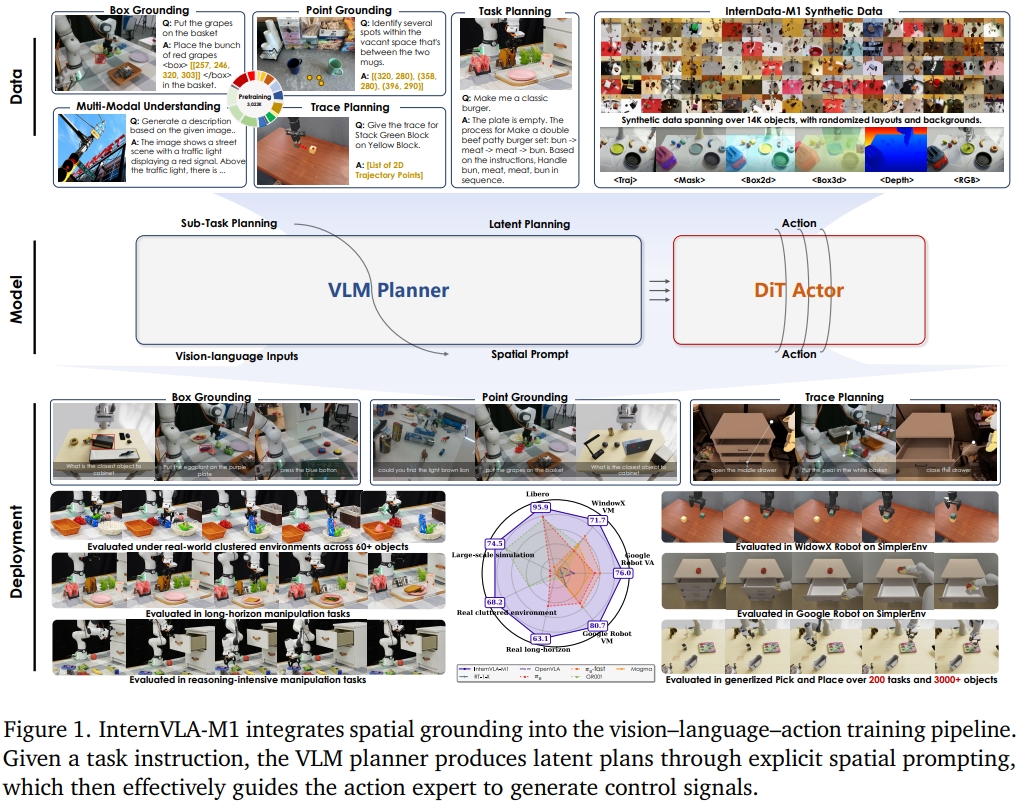
InternVLA-M1
InternVLA-M1的核心是spatially guided vision-language-action training空间指导的VLA训练,分为两个pipeline:
- 超过2.3M空间推理数据下进行spatial grounding 的预训练,通过将指令与视觉、实施例无关的位置(embodiment-agnostic positions)进行对齐,进而实现“where to act”的决策;
- spatially guided action后训练,通过生成通过即插即用的空间提示生成感知实施例的动作(embodiment-aware actions),决定“how to act”
作者采集了超过3M个多模态训练样本,其中包括了2.3M spatial grounding data以及0.7M 从网络、真实场景以及仿真资源收集的multimodal understanding data. 此外,构建了一个仿真的engine收集了244K个拾取与放置的案例。
InternVLA-M1架构如下图所示。建立在空间先验VLM planner和action expert(具体化的特定控制/embodiment-specific control)之上的双系统框架,将高级推理(high-level reasoning)与底层执行(grounded execution)相结合。
- VLM planner负责推理语言指令以及空间关系的推理。(注意该VLM是采用了空间数据进行训练的)
- action expert 负责讲过VLM输出的representation转换为可执行的电机命令
训练也是分为两个阶段(multimodal supervision 与 action supervision),进而实现高层语义以及底层运动控制:
- VLM的空间推理(spatial grounding)预训练,通过在points、boxes、traces的大尺度的多模态监督建立可迁移的空间理解。所采用的训练数据都是基于机器人的数据集,包含了bounding-box检测,轨迹预测、启示性识别、思维链推理等等,同时将其转换为QA形式的结构,这样使得跟传统VLM一样训练。
- 空间指导的运动后训练,通过联合监督训练,将先验应用于具体化的特定控制(embodiment-specific control)。Action Expert是基于机器人演示数据训练的,并且是跟VLM一起联合训练。
模型的架构如下所示。经典的快慢双系统,跟Helix是相似的架构。 对于System2,采用的是Qwen2.5-VL3B-instruct。 对于System2采用的是diffusion policy,通过DINOv2作为视觉编码器和轻量级的状态编码器,来组成vision-action model。
训练采用了16块A100GPU。 在推理阶段只需要单个RTX4090 GPU (用12GB左右的内存)。 而采用FlashAttention,VLM可以进一步将推理速度加快将近10 FPS。
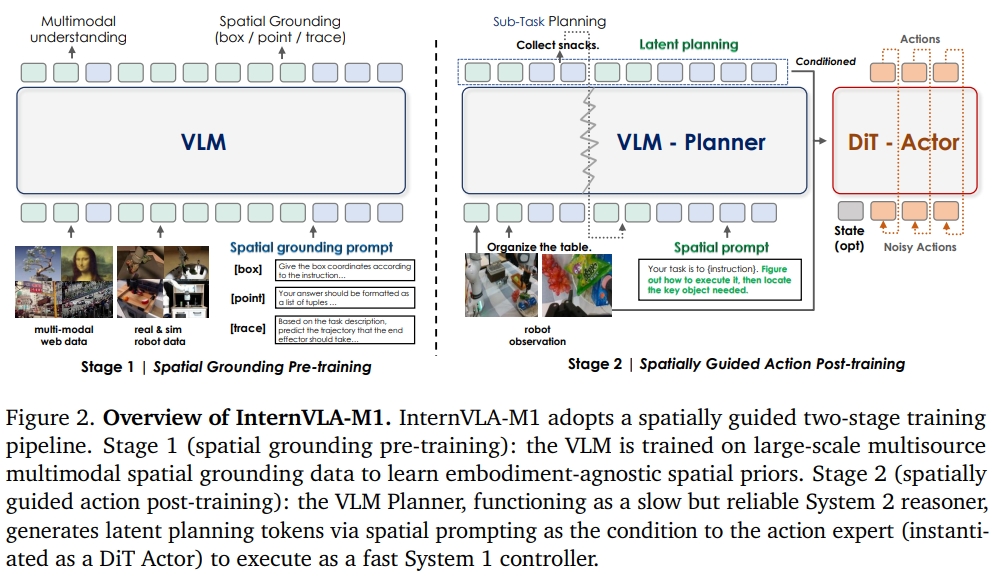
为了将VLM planner以及action expert联系在一起,作者提出了一个轻量级的querying transformer,进而实现将VLM输出的 latent planning embeddings转换为固定的可学习的query tokens。
而为了显式激活学习到的空间感知的能力,作者还采用了一个spatial prompting(相当于与空间信息相关的提示词,如上图的绿色字所示).直观上来讲,更像是对语言指令的增强。比如store all toys into the toy box—>Identify all relevant toys and their spatial relationships to the container
实验结果发现,比起benchmark能提升10多个点。 如下图所示,分别为在仿真及实操下跟SOTA的对比效果
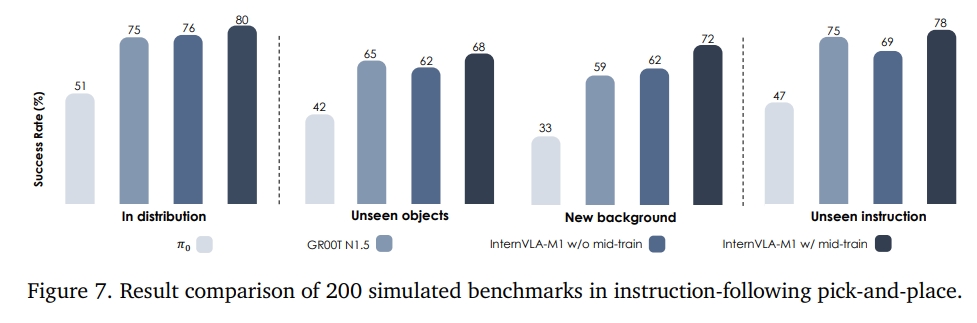
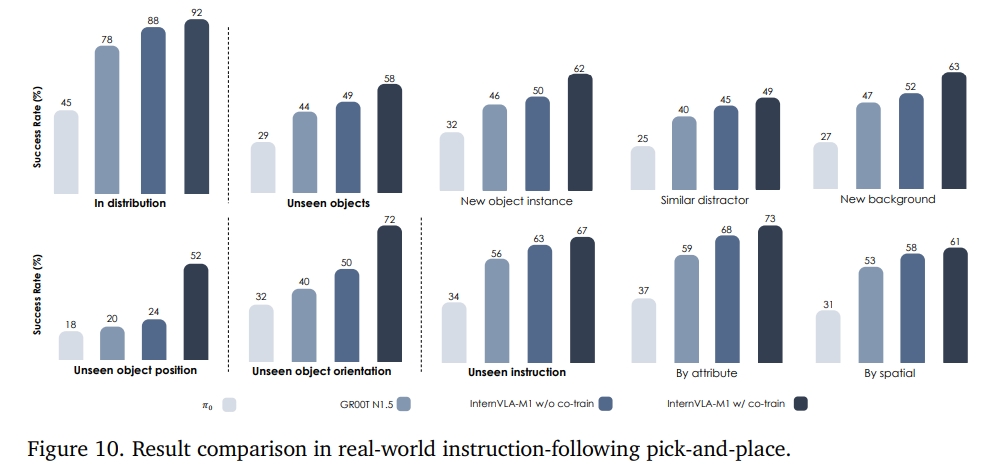
至于其他实验,似乎更多的是对比Visual Matching、Variant Aggregation。而instruction-following pick-and-place大部分的成功率都是70~80%左右。
NanoVLA
NanoVLA 的突破思路是——“不单纯缩小模型,而是让计算‘按需分配’”:通过解耦静态指令与动态视觉(视觉-语言解耦+缓存机制)、分阶段规划动作(长短动作分块)、自适应选择骨干网络(动态路由),在精度不损失的前提下,实现了高性能和低资源消耗,适配边缘设备的资源限制。 既保留通用 VLA 模型的任务精度与泛化能力,又将推理速度提升 52 倍、参数量压缩 98%,首次实现 “在边缘设备上高效运行通用机器人策略” 的目标。
传统的VLA模型由于计算需求高,难以部署在资源受限的边缘设备上,尤其是在对功耗、延迟和计算资源有严格要求的实际场景中。 NanoVLA通过重新组织模态融合方式、动作随时间展开方式以及何时调用更大的模型骨干网络,弥补了这一部署差距。
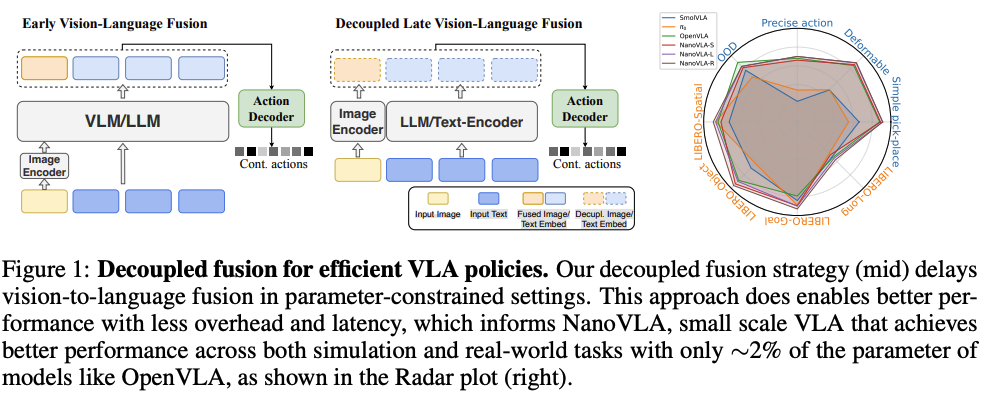
NonoVLA等“三大核心设计”:重构模态交互、动作规划与资源分配方式。
- 视觉-语言解耦(Vision-Language Decoupling):传统 VLA 模型的致命缺陷是 “每次控制步骤都需重新计算视觉与语言特征(forcing the language backbone to recompute at every control step,even when the instruction remains the same)”,而 NanoVLA 通过 “解耦架构 + 缓存机制”,彻底消除冗余计算。将传统的VLM中视觉和语言的融合从早期融合推迟到后期阶段,这样可以避免指令部分的重复计算;
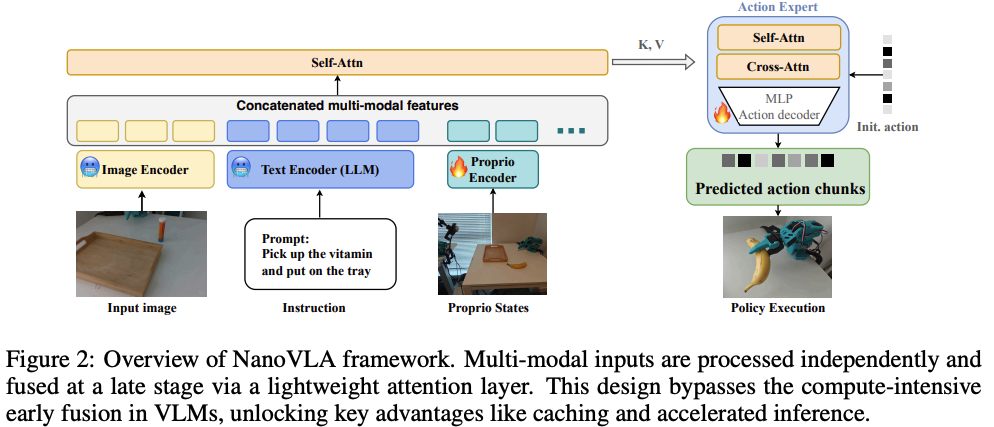
- (分离模态编码,延迟融合时机)将视觉和语言模态进行解耦,也就是就是分离到各自的编码器中。视觉编码器(如ResNet或ViT)提取紧凑的场景特征,而语言编码器(如BERT或Qwen)编码任务指令。此外,机器人本体感知(如机器人关节状态)则是通过轻量 MLP 投影融入;
- 这些编码器在训练过程中保持冻结,以保留其预训练的语义知识并避免灾难性遗忘。
- (后期阶段融合)仅仅在动作生成阶段,使用一个轻量级的Transformer来合并模态特定的嵌入(对 “视觉嵌入+语言嵌入+本体嵌入” 进行一次交叉注意力融合)。每一层首先对输出token应用自注意力机制,然后应用交叉注意力机制融合视觉和语言特征以生成动作。
- 这种设计通过仅在后期阶段执行一次跨模态注意力,显著减少了冗余计算,避免了VLM中常见的计算密集型早期跨模态纠缠。
- (缓存优化)除了解耦,另外一个关键是能够缓存中间特征————锁定静态特征,动态更新视觉。在交互任务中(如 “拿起维生素放入托盘”),指令通常固定不变,因此:
- 语言嵌入、本体状态嵌入仅需计算一次并缓存,后续步骤直接复用;
- 仅视觉嵌入需随每帧图像更新,计算量减少 62%(基于 Qwen 0.5B 骨干测试),边缘设备推理延迟显著降低。
- (分离模态编码,延迟融合时机)将视觉和语言模态进行解耦,也就是就是分离到各自的编码器中。视觉编码器(如ResNet或ViT)提取紧凑的场景特征,而语言编码器(如BERT或Qwen)编码任务指令。此外,机器人本体感知(如机器人关节状态)则是通过轻量 MLP 投影融入;
这部分的设计优势在于:预训练视觉 / 语言编码器的语义表征能力被完整保留,晚期融合还能避免早期模态干扰,实验证明——该设计在 LIBERO 任务中,用 52M 可训练参数量实现了超越 7B 参数量 OpenVLA 的精度。
- 长短动作分块(Long-Short Action Chunking,LSAC):在平滑、连贯的多步规划和实时响应能力之间取得平衡;为解决 “逐步预测抖动” 与 “固定长序列僵硬” 的矛盾,NanoVLA 提出 “训练时规划长序列,推理时执行短窗口(short window)” 的分块策略。
- NanoVLA的策略是生成一个较长的动作块,但只执行其中的一小部分,然后用新的观察结果重新规划;
- (训练阶段,学习长序列) 在训练期间,模型优化目标是预测长时程动作序列(如$H_{train}$ 50 步),通过监督回归学习动作间的时序连贯性,确保长任务中运动平滑,
- (推理阶段,根据高频反馈来调整,执行短窗口) 每次仅执行预测序列的前 h 步(h«$H_{train}$ ,如 h=10),随后基于最新视觉观测重新规划;
- 既通过 “长规划” 保证动作连贯,又通过 “短执行 + 高频反馈” 适配环境变化(如物体位置偏移、抓取打滑)。将规划分摊到多个控制(推理)步骤中,同时保持行为的平滑性,并能适应新的视觉观测。
- NanoVLA的策略是生成一个较长的动作块,但只执行其中的一小部分,然后用新的观察结果重新规划;
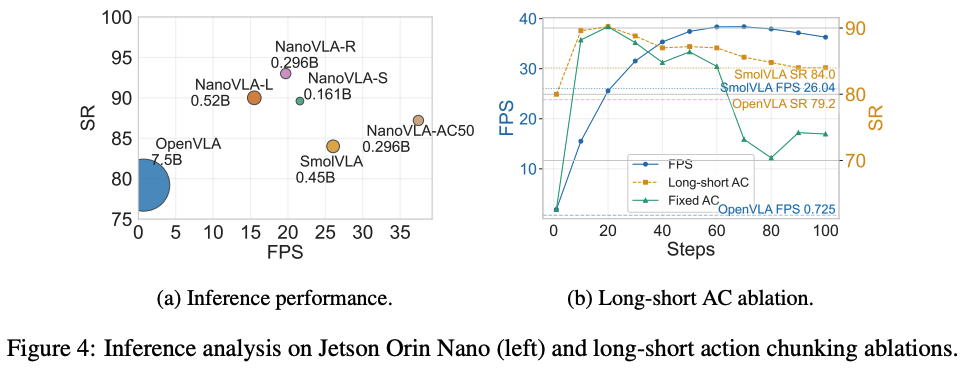
这部分的设计优势在于:在 LIBERO 长任务中,长短分块策略比固定长序列执行的成功率高 16%(84% vs 68%),且动作抖动减少 30%,完全适配真实场景的动态需求。
- 动态路由(Dynamic Routing):为解决 “单一骨干网络容量错配” 问题,NanoVLA 引入 “轻量级路由器(router)”,根据任务复杂度自适应分配轻量级或重量级骨干网络,以优化推理效率;
- 动态路由模块根据任务的不确定性来选择最合适的模型。它通过贝叶斯成功建模来评估任务的复杂性;
- 用 Beta-二项分布建模不同骨干网络(如轻量 BERT-base、重量级 Qwen 0.5B)在各类任务上的成功率,通过蒙特卡洛估计(MCB)计算 “模型 - 任务” 匹配概率;
- 动态切换逻辑:在默认情况下,系统会使用小型骨干网络。只有当任务难度增加,导致不确定性超过预设阈值时,系统才会升级到更大的骨干网络。
- 这种机制确保了在简单任务中保持低计算成本,而在复杂任务中能够调用更强大的模型以保证性能。
- 简单任务(如短距离抓取):轻量骨干占比超 80%,参数量仅 161M,推理速度提升 43%;
- 复杂任务(如多步组装):自动切换到重量级骨干,精度不损失(甚至比固定重量级骨干高 3.7%);
- 平均参数量降至 296M(仅为 OpenVLA 的 4%),边缘设备内存占用减少 92%。
- 动态路由模块根据任务的不确定性来选择最合适的模型。它通过贝叶斯成功建模来评估任务的复杂性;
实验效果:NanoVLA在多个基准测试和实际部署中,与现有最先进的VLA模型相比,在边缘设备上的推理速度提高了52倍,参数减少了98%,同时保持或超越了其任务准确性和泛化能力;
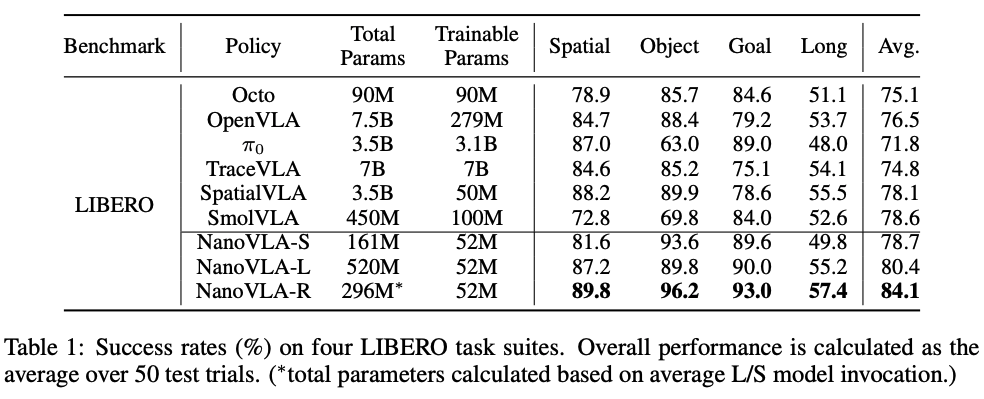
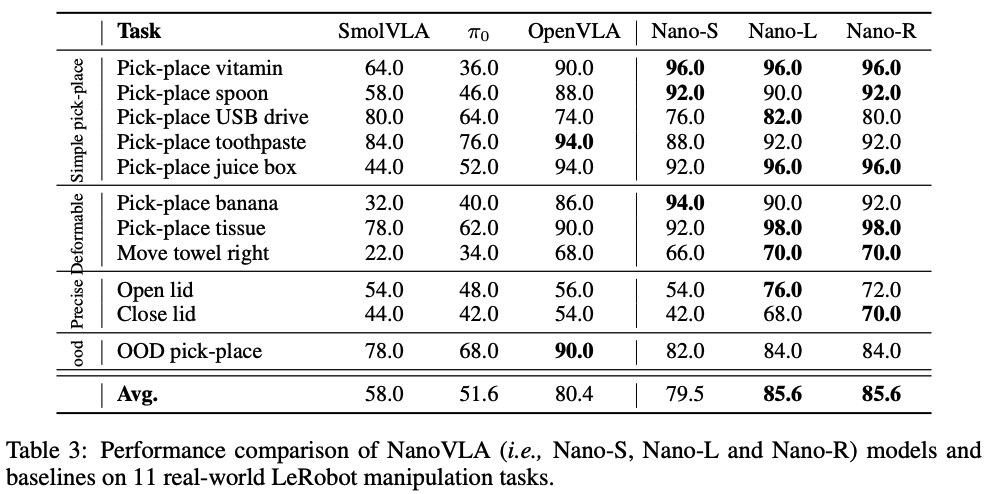
- 在LIBERO任务中,NanoVLA始终优于Octo、OpenVLA、πo、TraceVLA和SpatialVLA等数十亿参数的VLA模型。比 7.5B 参数量的 OpenVLA 高 7.6%,比 450M 参数量的 SmolVLA 高 5.5%;推理速度是 OpenVLA 的 52 倍,是 SmolVLA 的 8 倍,完全满足边缘设备实时性要求(≥10 FPS)。
- 在低成本真实机器人 LeRobot(搭载 Jetson Orin Nano,1280×720 RGB 相机)上,测试 12 类真实任务(含刚性物体抓取、柔性物体操作、精密控制):
- 简单抓取任务(如拿起 USB、牙膏):NanoVLA-S(161M)成功率 92%-96%,超越 OpenVLA(7B)的 74%-90%;
- 柔性物体任务(如拿起香蕉、毛巾):所有 NanoVLA 版本成功率均≥90%,超越SmolVLA ;
- 精密控制任务(如开盖、关盖):NanoVLA-L 成功率 76%,比 OpenVLA 高 20%(56% vs 76%),且无物体损坏;
- 泛化能力:对未见过的物体(如护手霜)、未见过的指令(如 “移动新毛巾”),成功率仍达 84%,比模型高 26%。
- 在边缘设备标杆 Jetson Orin Nano(8GB 内存,67 TOPS 算力)上,NanoVLA 的部署性能如下:
GEN-0
Generalist 公司发布了GEN-0,其关键点在于:具身智能的基础模型,它的能力可预测地随物理交互数据(不仅仅是文本、图像、仿真,还有真实数据)增加而提升。 其主要贡献点如下:
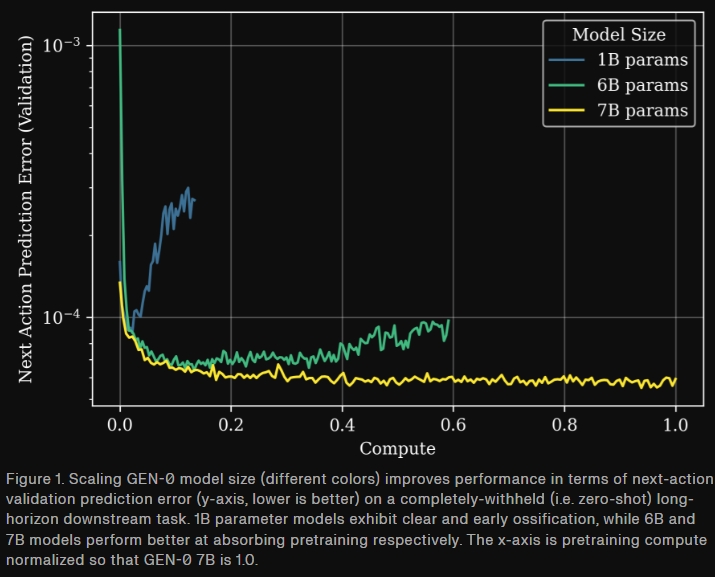
- 超越智能阈值(7B参数量):使用前所未有的大量数据,Generalist 观察到在 7B 参数上出现了一个「相变 (phase transition)」;较小的模型表现出「固化 (ossification) 」现象,而较大的模型性能则能持续提升。Generalist进一步将GEN-0扩展到10B+的模型规模,并观察到它们能以越来越少的后训练快速适应新任务。
- 1B 模型在预训练期间难以吸收复杂多样的感觉运动数据;模型权重随着时间推移无法吸收新信息。
- 6B 模型开始从预训练中受益,并显示出强大的多任务能力。
- 7B+ 模型能够内化大规模的机器人预训练数据,这些数据仅需几千步的后训练就能迁移到下游任务。
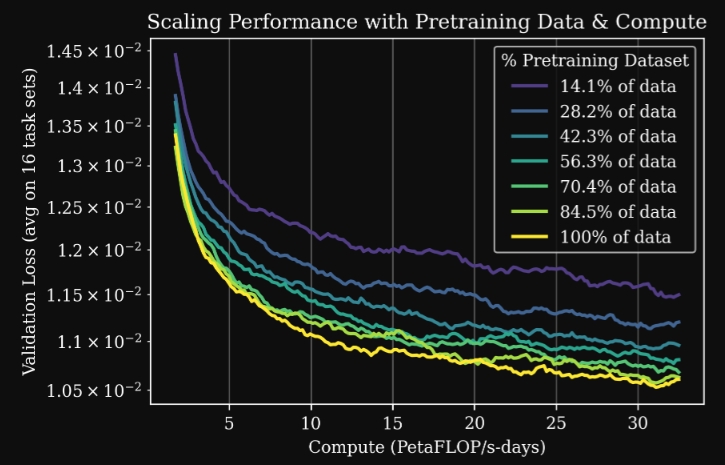
- Scaling Law:GEN-0 模型展现出了强大的 Scaling Law,即更多的预训练数据和算力,能够持续(且可预测地)提高模型在众多任务上的下游后训练性能(post-training performance)。
|
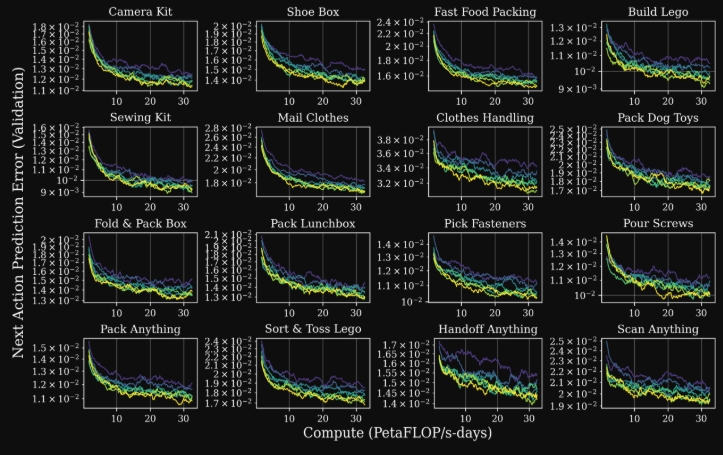
|
- Harmonic Reasoning:在异步、连续时间的「感知」和「行动」token 流之间建立了一种「Harmonic/和谐」的相互作用。这使模型能够扩展到非常大的规模,而无需依赖双系统(System1-System2) 架构或「推理时指导( inference-time guidance)」;
- Cross-Embodiment:GEN-0 架构通过设计使其适用于不同的机器人。Generalist 已经在 6 自由度 (6DoF)、7 自由度和 16+ 自由度的半人形机器人上成功测试了模型;
- 不再受数据限制:GEN-0 在 Generalist 内部的机器人数据集上进行了预训练,该数据集包含超过 27 万小时的真实世界多样化操作数据,并以每周 1 万小时的速度增长;
- Mapping the Universe of Manipulation: 为了扩展 GEN-0 的能力,Generalist 正在构建有史以来最大、最多样化的真实世界操作数据集,包括人类能想到的每一项操作任务,涵盖家庭、面包店、自助洗衣店、仓库、工厂等。
- Infrastructure for Internet-Scale Robot Data: Generalist 与多家云服务商合作,构建了定制的上传机器,扩展到 O (10K) 级核心用于持续的多模态数据处理,压缩了数十 PB 的数据,并使用了前沿视频基础模型背后的数据加载技术,能够在每训练一天就吸收掉 6.85 年的真实世界操作经验。
- 预训练的科学(The Science of Pretraining):不同的预训练数据混合(来自不同来源,例如数据工厂)会产生具有不同特性的 GEN-0 模型。Generalist 分享一些在这种海量数据情景下的早期经验观察,以及这些观察如何追溯到特定的数据收集操作;
- 数据质量和多样性比纯粹的数量更重要,而且精心构建的数据混合可以带来具有不同特性的预训练模型.
RoboTron-Mani
以 “3D 感知增强 + 多模态融合架构” 为核心,通过构建涵盖多平台数据的RoboData数据集,实现了 “跨数据集、跨机器人、跨场景” 的全能操作:既通过相机参数与占用率(occupancy)监督强化 3D 空间理解,又借助大语言模型(OpenFlamingo)实现模态隔离掩码(Modality-Isolation-Mask)以及多模态解码块提升多模态融合精度,最终在模拟与真实场景中,成为首个超越专家模型的通用型机器人操作策略。
- RoboData数据集似乎只是集成了9个不同的数据集:CALVIN, Meta-World, LIBERO, Robomimic, RoboCAS, ManiSkill2, RoboCasa, RLBench, and Colosseum。主要的工作则是把缺失的模态(深度图、相机参数)补充。
RoboMM架构如下图所示。该模型具备3D环境感知的能力以及处理多模态的输入。主要包含一些部分:
- 视觉编码器模块:提取observation feature;
- 3D感知自适应模块(Adapter Block):通过结合相机参数来增强物理空间的感知;采用RoboUniView的UVFormer(一个强大的3D环境感知模型)
- 基于LLM的特征融合解码器(Feature Fusion Decoder):融合文本、视觉信息来输出多模态特征,同时采用模态隔离掩码(Modality-Isolation-Mask)来增强模态融合的灵活性;对于Feature Fusion Decoder,采用的是llaVA的自回归(AutoRegressive)机制,并且采用OpenFlamingo的cross-attention作为Feature Fusion Decoder。
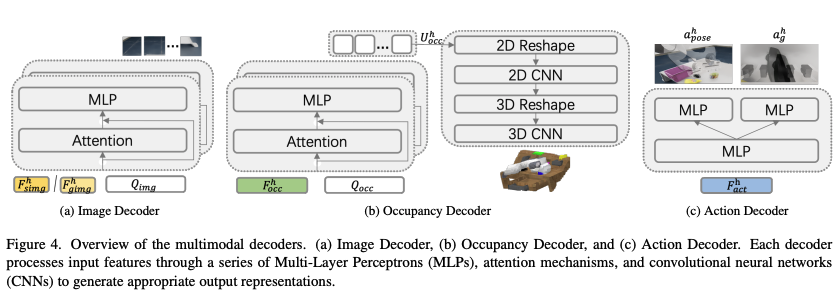
- 多模态解码块(Multimodal Decoders):通过多模态输出增强模型的细粒度感知(fine-grained perception)和理解。所谓的多模态解码器(如图4所示),作者是根据不同的模态设计来对应的解码器:image、occupancy、action

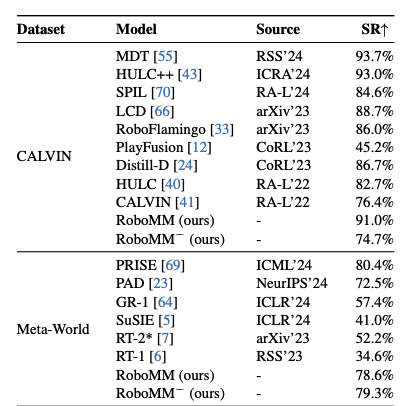
接下来看看实验结果。首先RoboMM− 指的是没有对齐的RoboData数据集(不同数据集具有不同的世界坐标,如果不做映射到相同的系统可能导致训练的过程3D恢复有问题)
|
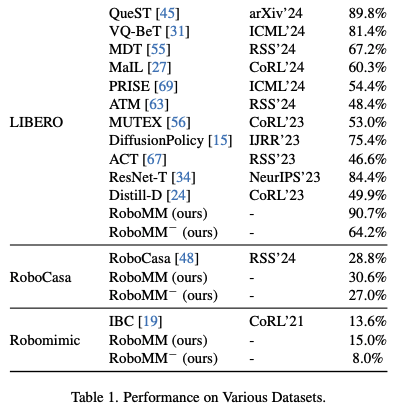
|
参考资料
- Vision-language-action models: Concepts, progress, applications and challenges
- Vision Language Action Models in Robotic Manipulation: A Systematic Review
- Large VLM-based Vision-Language-Action Models for Robotic Manipulation: A Survey
- Exploring Embodied Multimodal Large Models:Development, Datasets, and Future Directions
- A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
- Blog for VLN
- 论文阅读笔记之——《Vision-language-action models: Concepts, progress, applications and challenges》
- Helix 系列报告解读,Figure团队快慢双系统层级化范式
- 【VLA系列】 万字深度解析PI-0
- 【VLA系列】Pi0-FAST,统一具身智能的动作Tokenization训练加速5倍
- Evaluating pi0 in the Wild: Strengths, Problems, and the Future of Generalist Robot Policies
- 【VLA 系列】复杂真实场景中评估 PI0-Fast
- 【VLA 系列】Hi Robot, PI 团队的快慢双系统方案
- 【VLA 系列】万字详解 PI0.5
- Pure Vision Language Action (VLA) Models: A Comprehensive Survey
- Efficient Vision-Language-Action Models for Embodied Manipulation: A Systematic Survey
- 边缘设备上高效运行!NanoVLA :保留 VLA 模型的精度与泛化能力,推理速度提升 52 倍