引言
本博文对于 2025 TRO的Transformer-based VIO工作进行阅读及复现。
本博文仅供本人学习记录用~
- paper
- code
- 基于Transformer的SLAM工作调研:paper list
- 基于Learning的SLAM工作调研:paper list
- 本博文复现过程采用的代码及代码注释(如有):My github repository
理论阅读
本文提出的是一个基于transformer的自监督VIO模型,结合shallow CNN以及时空增强的transformer来代替传统的基于learning的卷积架构。而极简交叉融合模块(cross-fusion module)使用单层的交叉注意力机制(cross-attention)来增强多模态(视觉与IMU)的交互。
大部分的基于learning的VIO方法都是需要大数据来进行监督学习的,并且需要真值数据。 而现有也有一些自监督的工作1,2,3,4,都是利用pose和depth的估计作为自监督信号,最小化图像重构的loss来作为训练,这样也避免了对GT label的需求. 尽管如此,这些方法对计算量、硬件要求、实时性都带来了挑战。并且这些方法都是基于ResNet或者VGGNet为骨架的,他们虽然很优秀但是对于计算量和内存消耗都比较大。
CNN在提取局部特征上表现是比较好,但是their limited receptive fields hinder the extraction of long-range features essential for accurate pose estimation(个人解读为其无法提取长距离或者说更大的局部特征,比如时间维度、运动距离较大等~),因此,一般都是通过更深或更复杂的网络来提升其感受野,但这也会导致计算量激增。
而基于LSTM(或者RNN)的网络,也同样面临着大计算量以及内存需求(并且根据之前调研learning-based IO的经验,LSTM类型的网络训练并不好收敛)。而近年来,基于transformer的VIO也有不少对工作1,2,但这些工作都需要多层的transformer,特别是在高分辨率图像上计算量巨大,也没有达到轻量级VIO的需求。
因此,作者提出采用单层的transformer(single-layer transformers)来设计自监督的VIO模型。其架构主要包括:
1.轻量级的CNN-transformer级联结构,作为视觉与IMU的统一的encoder来提取特征。特别地,作者设计了一个 spatial–temporal-enhanced transformer来更好的获取长距离的信息,以减少卷积层的数目。
- 不再依赖于更深的CNN,而是采用
shallow dilated convolution (SDConv)来增大感受野,SDConv可以用于减少特征的维度,进而减少计算量,并提高多尺度特征表达。 - 为了保证轻量级的设计,开发了一个
transformer-based cross-fusion (CoFusion)模块,其可以利用单层cross-attention来冬天捕获视觉与IMU特征的相关性,高效地处理尺度问题(ambiguity in geometric correspondences)
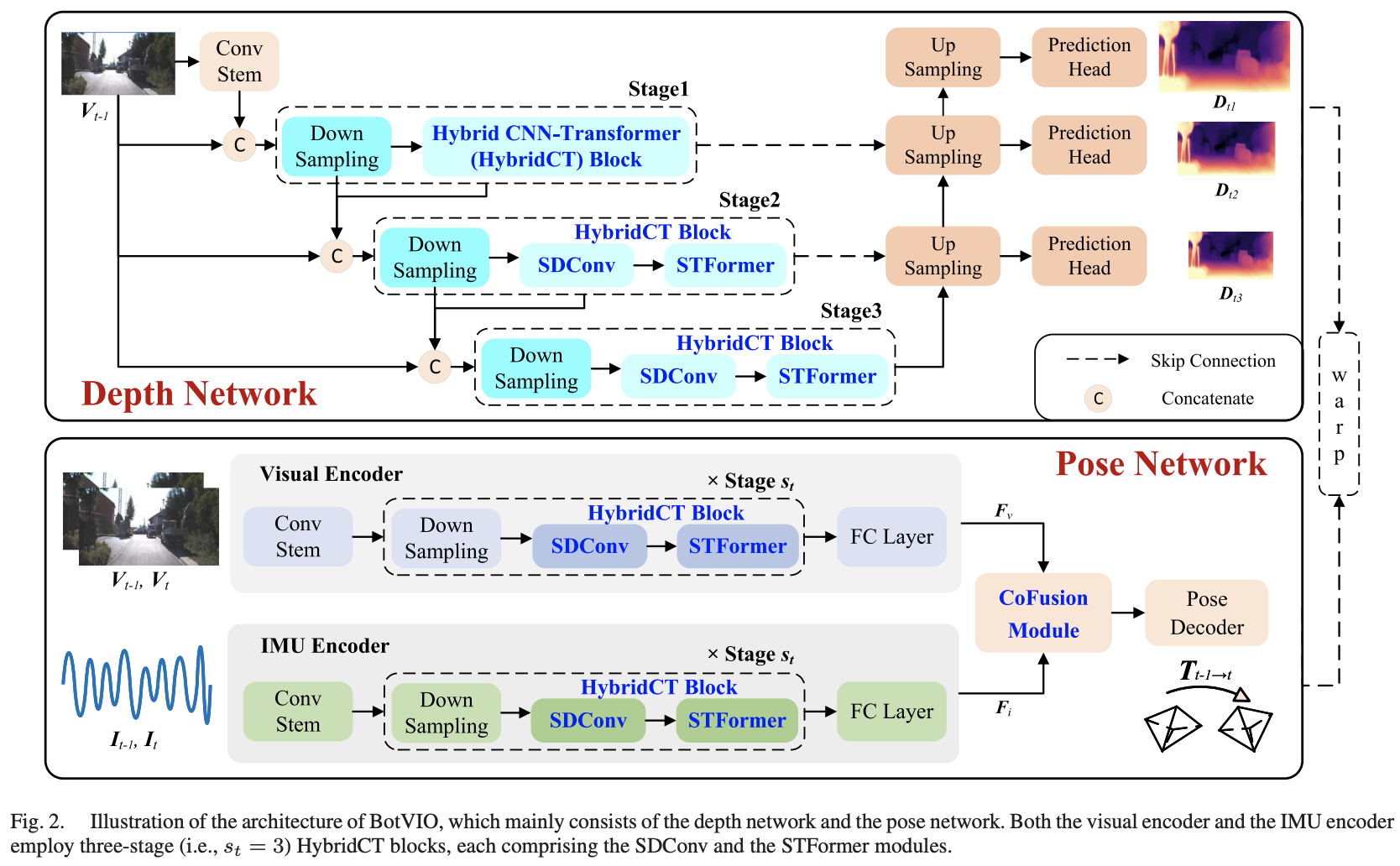
框架由两部分组成:
- 深度估计网络,从单目图像中估算深度图
- 姿态估计网络,提取视觉与IMU特征,并估算ego-motion
采用
view reconstruction的策略来训练模型的权重。而深度网络只是在自监督的训练过程需要,在推理阶段不需要。
HybridCT Block
所谓的HybridCT直观理解为结合了CNN和Transformer的网络,其结构如图三所示。
which cascades spatial–temporal-enhanced transformers with shallow CNNs to efficiently generate multiscale spatial features while minimizing computational overhead
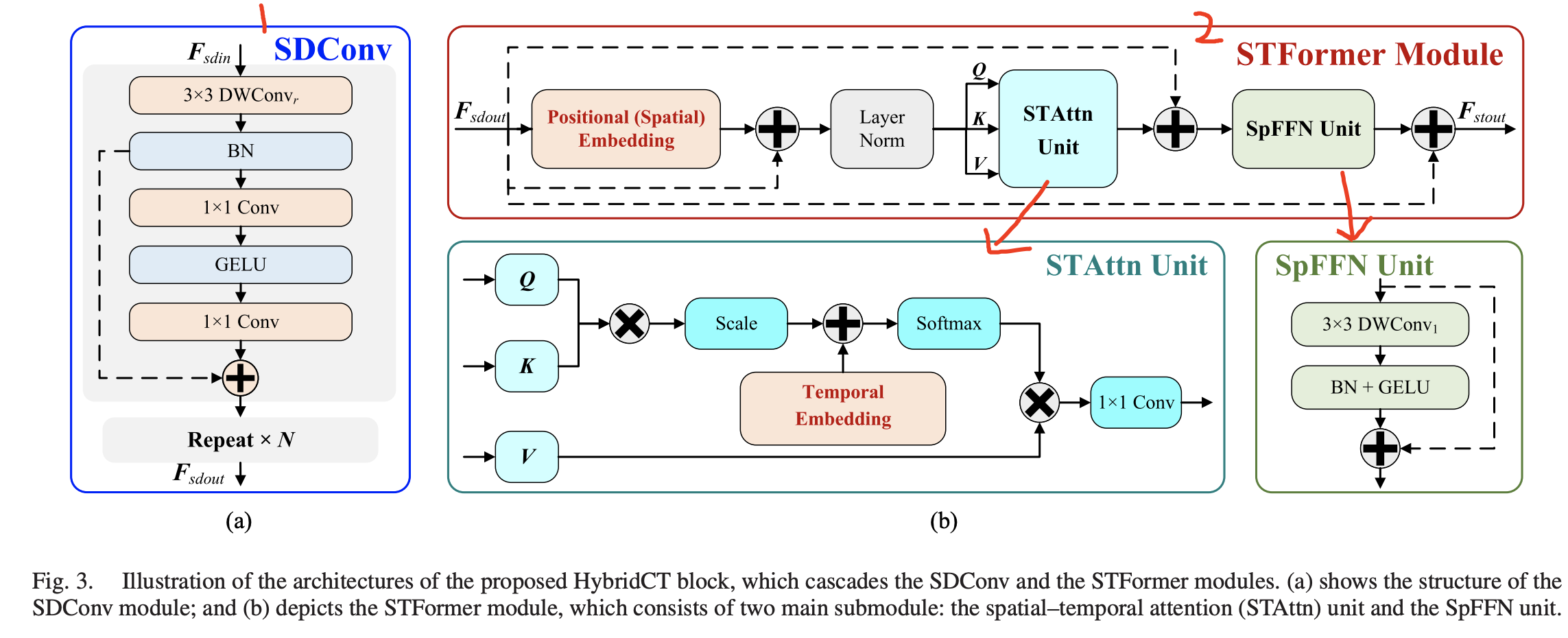
主要分为SDConv Module和STFormer Module。 SDConv Module主要是用于扩展感受野以及降低encoder的复杂性的。而STFormer Module则是为了捕获long-range feature representations同时保持轻量级的设计。
CoFusion Module
就是用于将视觉与IMU特征相结合的。其结构如下图所示。采用的是a single-layer cross-attention mechanism
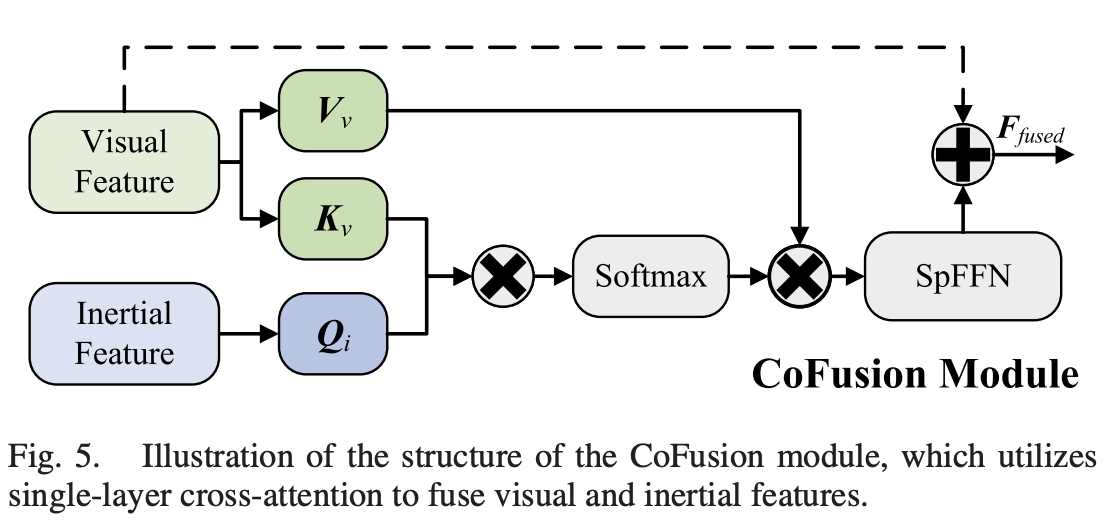
Decoder Network
对于Depth Decoder,如上面Fig.2所示,Decoder只包含了upsampling module 与 the prediction head。
对于Pose Decoder,只是一个轻量级的卷积层

Loss Functions
由两部分组成:
- Photometric Consistency Loss,直观理解就是像素点的重投影光度误差最小
- Depth Smoothness Loss,这个从原理上更像是深度图的对比度最小化

|
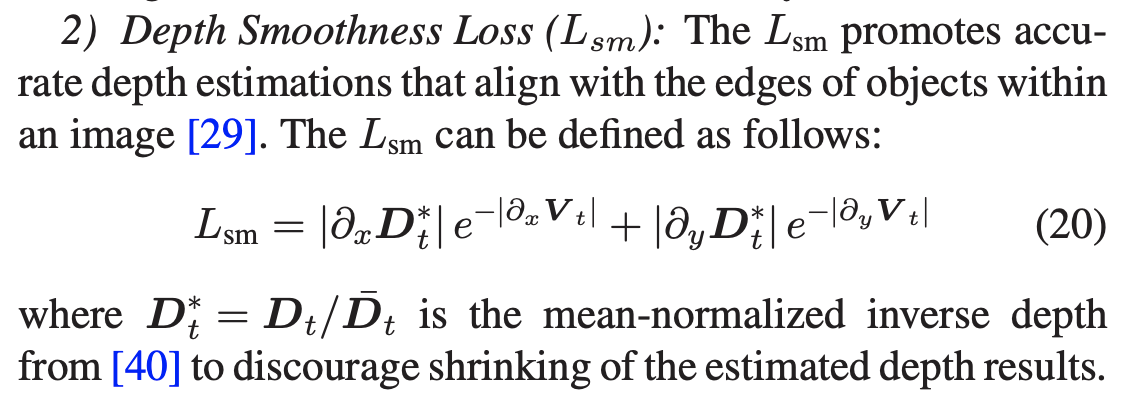
|
试验结果是在EuRoC以及KITTI上验证的,但是似乎就是跟ORB-SLAM3、VINS-MONO还有其他不太知名的learning算法对比,没有跟DPVO等对比~ 当然作者也采了实机数据,整体还是做了很多实验的~
作者在limitation也提到了:it may still struggle in scenarios with significant variations in scene and motion patterns. Furthermore, variations in image resolution present a challenge to the generalization capability of learning-based VO/VIO methods
代码复现
配置测试
git clone https://github.com/R-C-Group/BotVIO.git --recursive
conda create -n botvio python=3.10
conda activate botvio
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
pip install timm==0.4.12
pip install matplotlib
pip install gdown
pip install scipy
pip install scikit-image
pip install einops
pip install opencv-python
Data Preparation:采用KITTI数据集(注意要留有空间)
cd data
source data_prep.sh
然后下载预训练模型link,并且放在pretrain_models路径下
cd ./pretrain_models
python download.py
计算pose的结果:
conda activate botvio
python ./evaluations/eval_odom.py #这句运行需要创建一个results文件,并且运行了没有任何结果输出~~~
# CUDA_VISIBLE_DEVICES=0 PYTHONPATH=/home/gwp/BotVIO/ python ./evaluations/evaluate_pose_vo.py --load_weights_folder=pretrain_models --data_path=data
# Please modify '--data_path' in the options.py file to specify your dataset path.
# Additionally, update the pose embedding data type to float16 in PositionalEncodingFourier function within the depth encoder.py file.
# In addtion, comment out the fully connected (FC) layer in the pose_encoder.py.
# 注意vio中有一个额外的全链接层,如果运行vo的时候要注释
#需要先创建空的文件夹results
CUDA_VISIBLE_DEVICES=0 PYTHONPATH=/home/gwp/BotVIO/ python ./evaluations/evaluate_pose_vio.py --load_weights_folder=pretrain_models --data_path=data --eval_data_path=data
# Please modify '--data_path' in the options.py file to specify your dataset path. Additionally, update the pose embedding data type to float16 in PositionalEncodingFourier function within the depth encoder.py file.
运行效果结果:

整体而言只能测试序列9,序列10结果是nan,并且代码似乎有不少bug,无法运行,本人github push的版本是fixed的了~