最近在调研VLN工作的时候常常会涉及LLM、VLM、CLIP等大模型的相关知识,由于此前并没有系统了解过大模型这块,因此学习起来有点吃力。 本文对OpenAI 2021年发布的CLIP模型进行解读。 部分资料来源于网络,于文末给出参考材料。 本博文仅供本人学习记录用~
引言
CLIP( Contrastive Language–Image Pre-training)是基于对比学习的语言-图像预训练模型。 CLIP和BERT、GPT、ViT的区别在于,CLIP是多模态的,包含图像处理以及文本处理两个方面内容,而BERT、GPT是单文本模态的,ViT是单图像模态的。
在CLIP之前,CV的任务都是训练来预测固定组的预定义物体类别。 这严重限制了其泛化能力与可用性。 作者通过从400 million网络收集的图像文本对来预训练,预测哪个字幕属于哪张image(which caption goes with which image)可以很好的学习图像的表征,并且可以zero-shot 迁移到下游任务。(也就是通过大尺度自然语言监督来训练图像模型。) 作者测试了超过30个不同的CV数据集来验证其性能。
CLIP核心思想是通过海量的弱监督文本对,通过对比学习,将图片和文本通过各自的预训练模型获得编码向量,通过映射到统一空间计算特征相似度,通过对角线上的标签引导编码器对齐,加速模型收敛。CLIP是一种弱对齐,可应用于图文相似度计算和文本分类等任务~
架构与训练
CLIP的核心是learning perception from the supervision contained in natural language paired with images,从自然语言与图像配对的监督中学习感知
模型整体结构如下图所示。型的输入是若干个图像-文本对。
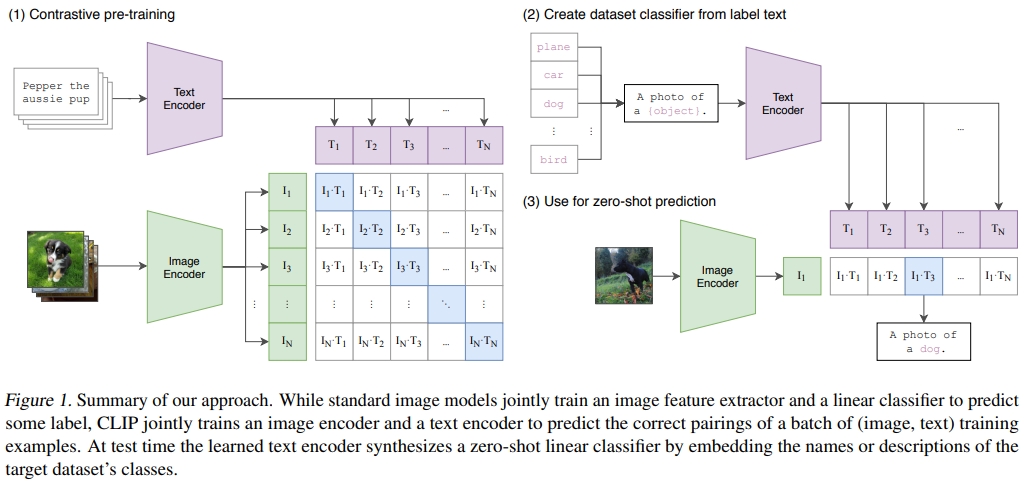
论文其中一个贡献点是作者团队收集了包含4亿对(图像,文本)的大规模数据集,每张图像都配有文字描述。
而为了构建有意义的嵌入表示,使得它们之间的相似度能够衡量文本描述与图像的匹配程度。核心部分则是是用于编码文本和图像的嵌入模型:
- 文本编码采用基于Transformer的模型,其架构与BERT相似。文本通过一个 Text Encoder 得到一些文本的特征。同样假设每个 training batch 都有 N 个 图像-文本 对,那么就会得到N 个文本的特征。
- 图像编码可使用传统卷积网络(如ResNet50)或视觉Transformer模型(ViT)。图像通过一个 Image Encoder 得到一些特征,这个 encoder 既可以是 ResNet,也可以是 Vision Transformer。假设每个 training batch 都有 N 个 图像-文本 对,那么就会得到 N 个图像的特征。
注意,如果单纯预测每张图片的所有文本,这会有大量的匹配情况,训练时间以及泛化能力都有限。因此作者只预测哪个文本作为一个整体与哪个图像配对,而不是该图像的确切文本单词。如下图所示.这样的做法大大提升效率。
此外,还会有一个投影器。所谓的投影器就是为了实现图像编码器和文本编码器输出的embedding向量在同一embedding空间中的一致性,使用了两个投影矩阵。这样,无论是图像还是文本编码器产生的向量,都将被投影到具有相同维度的空间中。(部分博客会称呼为多模态空间)
初始的4亿对图像和文本被分成批次。每个批次中的图像和文本分别通过图像或文本嵌入模型生成嵌入表示。如果批次中有n对嵌入,则会生成n个图像嵌入和n个文本嵌入(N*N个图像-文本对)。
接着,计算图像嵌入与文本嵌入之间的余弦相似度矩阵。
- 相似度矩阵主对角线上的每个元素代表批次中原本配对在一起的图像和文本之间的相似度。由于文本描述与图像对应良好,主对角线上的相似度应被最大化。
- 而非对角线上的元素并非原始配对,来自不同样本对,因此它们的相似度应被最小化。
而对比学习的目标函数就是让正样本对的相似度较高,负样本对的相似度较低。
CLIP 就是在以上这些特征上去做对比学习,需要正样本和负样本的定义,在这里配对的 图像-文本对就是正样本(即下图中对角线(蓝色)部分,配对的图像和文本所描述的是同一个东西,矩阵中剩下的所有不是对角线上的元素(图中白色部分)就是负样本。有了正、负样本后,模型就可以通过对比学习的方式去训练,不需要任何手工的标注。OpenAI专门去收集了一个数据集WIT(WebImageText),其中有4亿个图像-文本 对,且数据清理的比较好,质量比较高,这也是CLIP如此强大的主要原因之一。
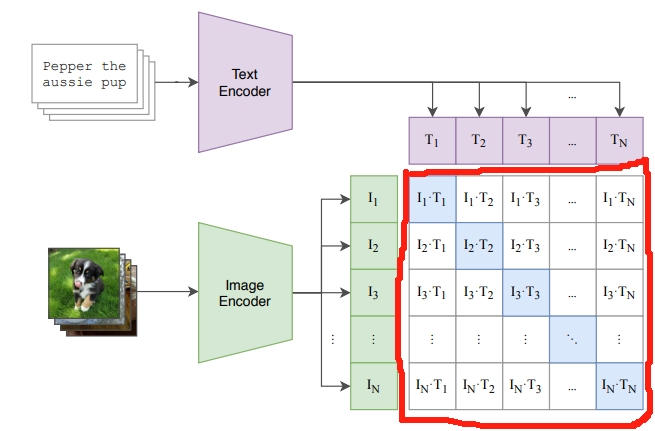
下面把CLIP中的对比学习总结流程如下:
- 特征提取:对于每个图像和文本输入,模型分别提取特征。这些特征是高维的向量表示
- 相似度计算:CLIP计算每个图像特征向量和每个文本特征向量之间的相似度,通常是余弦相似度
- 对比损失函数:模型使用一种特殊的损失函数(如对比损失),这种损失函数鼓励模型将匹配的图像和文本对的表示拉近,而将不匹配的推远。
CLIP可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类。 有以下的分类:
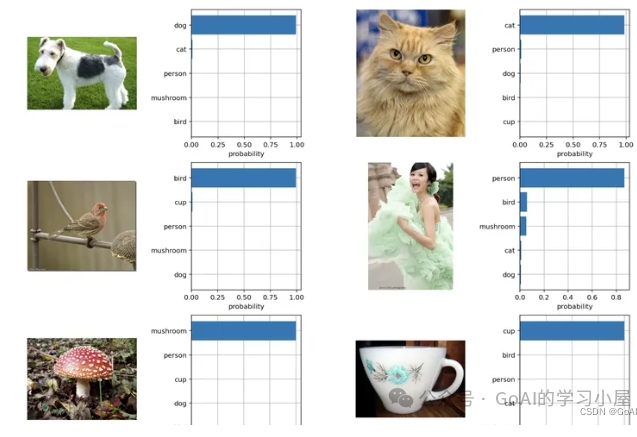
- 根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征;2.将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率。利用CLIP的多模态特性为具体的任务构建动态的分类器,其中Text Encoder提取的文本特征可以看成分类器的weights,而Image Encoder提取的图像特征是分类器的输入。(如下图所示)

|
|
CLIP主要应用场景
- 嵌入表示:最直接的应用是利用CLIP生成文本和图像的嵌入表示。这些嵌入可单独用于文本或图像任务,例如在相似性搜索流水线或RAG系统中。此外,如果需将图像与对应文本描述关联,可同时使用文本和图像嵌入。
- 图像分类:除了生成图像和文本嵌入,CLIP最强大的能力之一是以零样本学习方式解决其他任务。例如,在图像分类任务中,如果给定一张动物图像,目标是从动物列表中识别其类别,我们可以嵌入每个动物名称。然后通过寻找与图像嵌入最相似的文本嵌入,直接确定动物类别。
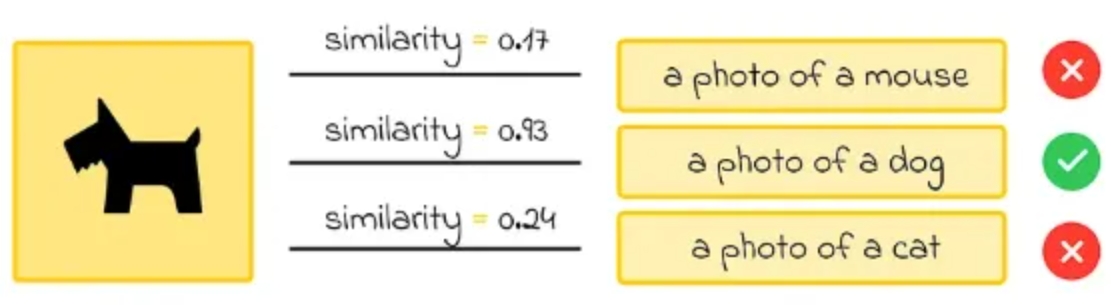
研究表明,对于此类识别任务,使用以下提示结构嵌入每个文本(类别名称)效果更佳:“一张<动物类别>的照片”。对于其他任务类型,最佳提示可能有所不同。
- CLIP不擅长某些抽象任务,例如计算照片中的物体数量、估计图像中两个物体的接近程度等;
- 在标准计算机视觉任务上,CLIP的零样本性能与其他传统模型(如ImageNet)相当。但作者指出,若要超越这些模型,CLIP所需的训练硬件需比现有硬件强数千倍,这在当前条件下难以实现。
对比学习(Contrastive Learning)
对比学习的核心思想是:通过让模型学会区分“相似”和“不相似”的数据对,从而学习到数据中有效的、高质量的表征(Representation)。 它不依赖于人工标注的标签,而是通过构造正样本对(相似的样本)和负样本对(不相似的样本),让模型在对比中学习。简单来说,它的目标不是识别出图片中具体是猫还是狗,而是学会判断“这两张图片是不是属于同一类事物”。
对比学习属于自监督学习方法,其目标是训练嵌入模型生成能够将相似样本在空间中拉近、相异样本推远的嵌入表示。 在对比学习中,模型处理成对的对象。训练过程中,模型并不知道这些对象在现实中是否真正相似。在通过计算出的嵌入预测它们的距离(相似度)后,损失函数被计算出来。主要分为两种情况:
- 初始对象相似:损失函数值引导权重更新,调整嵌入表示,使下一次相似度更接近;
- 初始对象不相似:模型更新权重,使得该对嵌入的相似度在下一次计算中降低。
一个生动的比喻
想象一下教一个孩子认识“猫”:
- 传统监督学习:你指着很多张不同的猫的图片,每次都告诉他“这是猫”。孩子通过归纳这些图片的共同特征来学习“猫”的概念。
- 对比学习:你拿出两张图片(比如一张猫和一张猫的另一个角度),告诉孩子“这两是一样的(正样本对)”;然后再拿出一张猫的图片和一张狗的图片,告诉孩子“这两是不一样的(负样本对)”。孩子通过不断比较“一样”和“不一样”来自己总结出“猫”应该长什么样。
后者就是对比学习的思路,它更侧重于通过比较来学习。