引言
传统SLAM算法一般都是运行在CPU上的(除了基于Learning的或者部分dense SLAM需要GPU)。 最近有一些工作基于CUDA实现SLAM的加速进而提升实时性。 本博文对相关工作进行调研与整理.
PS:对于CUDA加速SLAM从两个层面来看待:
1. 最大化SLAM系统的实时性。
2. 最大化利用硬件资源。将SLAM一部分算子(如特征提取、数据关联等)迁移到GPU上运行,既减轻CPU的压力,又可以把GPU的资源利用上,不至于浪费~
经典论文阅读
下面是整理的相关paper list:











1. FastTrack: GPU-Accelerated Tracking for Visual SLAM
对于大部分的SLAM系统,为了保证实时性(特别是资源受限的平台),往往会drop掉一些图像帧(比如30HZ的只按20HZ甚至10HZ来处理)但这会导致定位精度变差,回环失败,甚至更极端的——tracking loss。 因此,为了跟上系统和环境状态的变化,尽快/实时(越快越好)运行pose tracking非常重要~
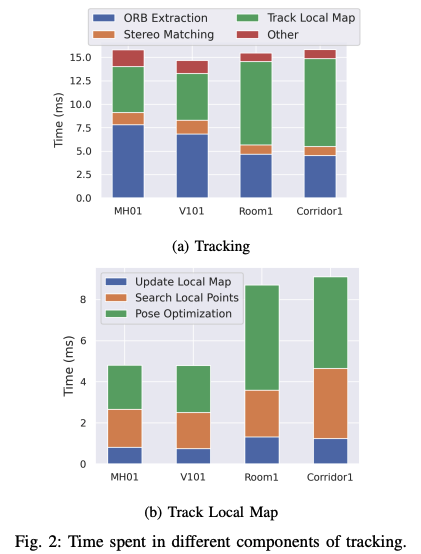
此外,将计算资源加载到GPU的标准是该资源可以并行化的程度。并且也需要考虑到CPU和GPU之间数据迁移的耗时(作者通过实现发现,tracking the local map, ORB extraction, and stereo matching这三个上最耗时间的模块),不然会导致并行化加速并没有带来增益。
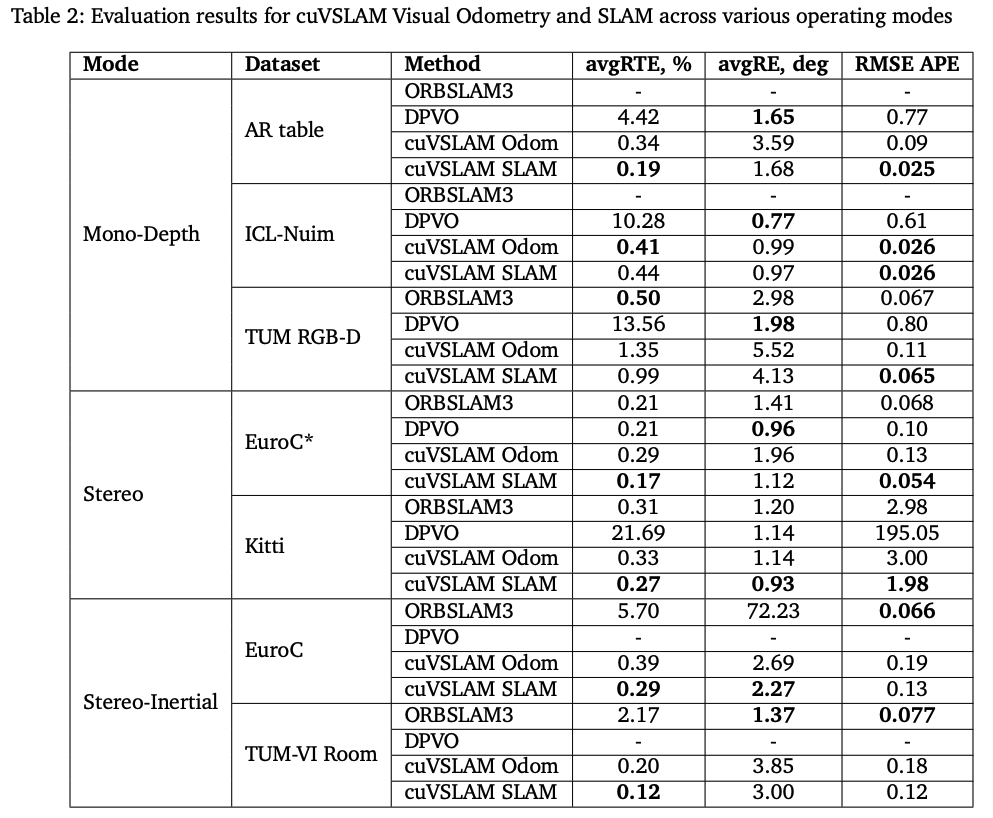
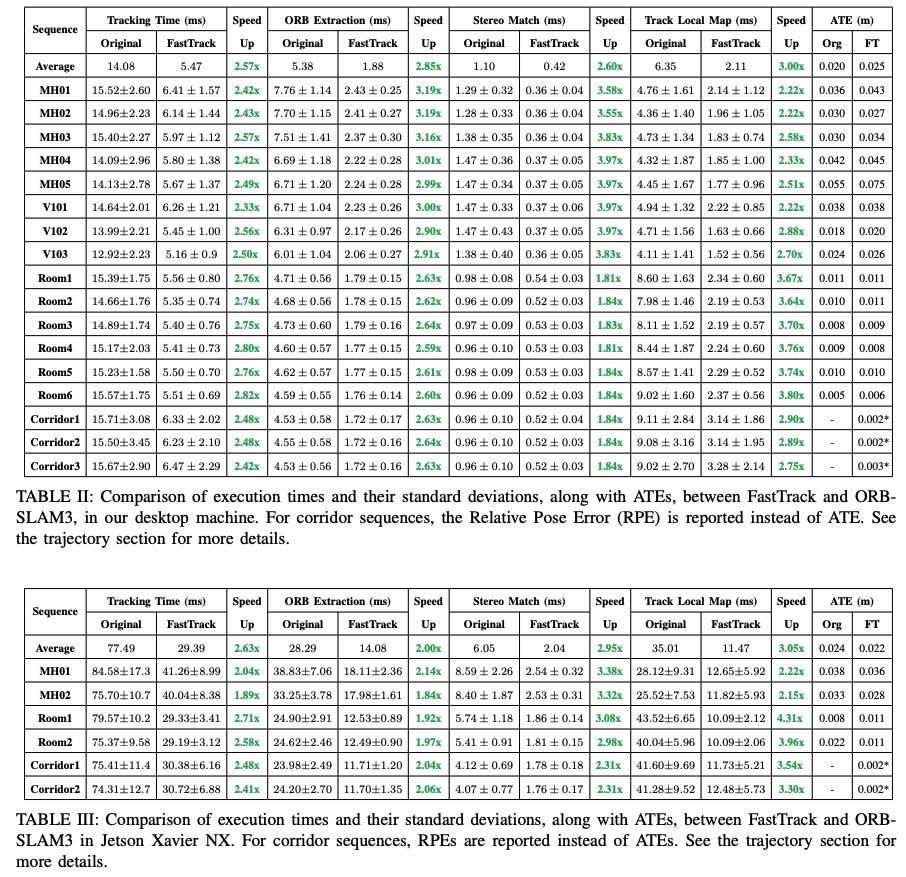
该论文通过利用GPU来加速ORB-SLAM3中的双目特征匹配及局部地图tracking两个部分。速度提升达2.8倍。同时性能精度保持相似水平。 如下图所示,分别是在desktop(表格2)和Jetson Xavier NX(表格3)上的实时性及精度对比:
这篇论文将pose tracking的几个不同的部分加载到GPU中:
- 加速双目特征匹配(基于pinhole或者鱼眼相机的)。采用已有的基于GPU实现的ORB特征提取(基于图像金字塔的特征提取);而双目匹配也是在GPU上实现的,对于每个点可以独立的进行匹配而无需依赖其他点。
- 搜索当前帧中的局部map point。将
Search Local Points任务加载到GPU上;Search Local Points负责将局部地图点鱼当前帧的特征点进行匹配,这步也是非常耗时的,因此在GPU上并行运算处理。并且地图点相互之间上独立的,不受影响,因此可以执行并行加速的操作;
此外,还需要确保CPU-to-GPU数据传输的开销最小化。
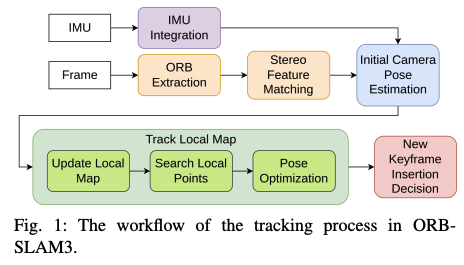
下图为加速前后的算法框架对比:
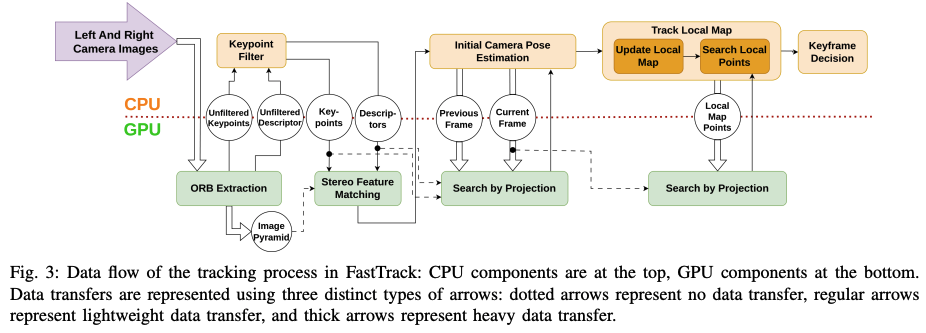
- 对于更新地图点(Update Local Map),如果将所有的局部关键帧观察到的map point都进行转移,会非常耗时,因此此处仍然保留在CPU上做;
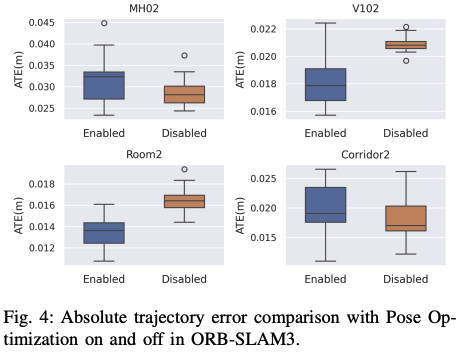
- 对于位姿优化,作者并没有加载到GPU上,并且将其关掉了。从下图可以看到,姿态优化在跟踪局部地图部分时耗占比是很大的。关掉可以大大的减少tracking的时间并且对误差的影响不大。
|
|
2. Accelerated Feature Detectors for Visual SLAM: A Comparative Study of FPGA vs GPU
特征提取是最常见也是slam中比较耗时的一个模块,GPU和FPGA都是常用的加速器,本文通过对比GPU(Nvidia Jetson Orin)和FPGA( AMD VCK190)加速的FAST,Harris以及superpoint的性能。
- 选用的SLAM pipeline为ICE-BA (Visual-Inertial SLAM, CVPR18)
- 测试数据为Euroc
- 更具体的实验分析请见原文,此处直接给出论文的结论。
结论发现,非learning的方法GPU的实时性及能效比FPGA的要好。
而基于learning的特征检测(SuperPoint),FPGA的实现比GPU在实时性以及能效上要提升3.1倍和1.4倍。
但精度层面,GPU加速的普遍要比FPGA的要高。
3. cuVSLAM: CUDA accelerated visual odometry and mapping
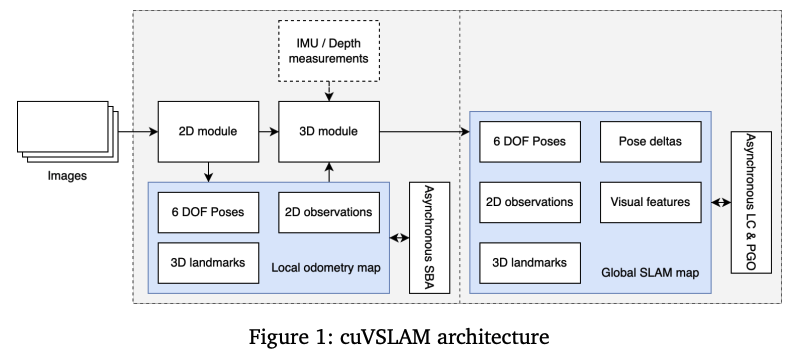
cvVSLAM是NVIDIA设计的SLAM系统,支持单目、双目(甚至高达32个相机),深度、IMU等,通过CUDA实现来在边缘设备上实现实时性。本质上就是用CUDA加速整个传统SLAM的特征提取、跟踪、局部建图,bundle adjustment等。
- 特征提取部分,将图像分为N*M网格,并行处理,通过Good Features to Track提取特征点。通过CUDA实现LK光流;
- 对于跟踪的特征点,先通过三角化恢复landmark,然后执行异步稀疏BA(asynchronous local sparse bundle adjustment (SBA))来进行优化。而SBA的实现过程都是用CUDA
- 回环检测部分,通过kd-tree来进行搜索而非词袋法;
cuVSLAM在KITTI里成绩数据集下平均轨迹误差小于1%,在EuRoC数据集下位置误差小于5cm,在NVIDIA Jeson平台上实时处理图像帧。
CPU和GPU的利用率及实时性测试如下:
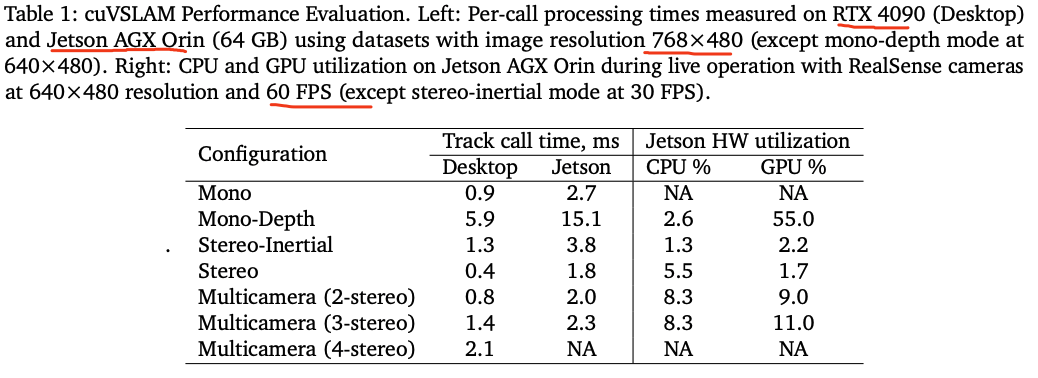
精度效果,本质上是没有进行算法的改进,只是把算法每个模块通过CUDA实现,从原理上跟VINS-Mono非常像,采用的是特征点法+光流跟踪。