引言
之前博客在对Transformer-based SLAM进行调研的时候,无意中发现竟然还要基于Diffusion的SLAM相关的工作,为此针对其进行调研,看看Diffusion在SLAM、光流、深度估计、数据关联、姿态估计等相关任务上表现如何~
本博文仅供本人学习记录用~
Paper List
- 注意,此处非最新版,仅仅是写此博客的时候的记录
- Keep update the paper list in: Awesome-Diffusion-based-SLAM
Matching
or data association, or correspondence
| Year | Venue | Paper Title | Repository | Note |
|---|---|---|---|---|
| 2025 | arXiv |
MATCHA: Towards Matching Anything | — | SD+DINOv2 |
| 2024 | CVPR |
Sd4match: Learning to prompt stable diffusion model for semantic matching |  |
website |
| 2023 | NIPS |
Emergent correspondence from image diffusion |  |
website DIFT |
| 2023 | NIPS |
A tale of two features: Stable diffusion complements dino for zero-shot semantic correspondence |  |
website SD+DINO |
| 2023 | NIPS |
Diffusion hyperfeatures: Searching through time and space for semantic correspondence |  |
website DHF |
Depth Estimation
or 3D reconstruction
| Year | Venue | Paper Title | Repository | Note |
|---|---|---|---|---|
| 2025 | arXiv |
Bolt3D: Generating 3D Scenes in Seconds | — | website |
| 2025 | arXiv |
Stable Virtual Camera: Generative View Synthesis with Diffusion Models |  |
— |
| 2025 | CVPR |
Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models | — | website |
| 2025 | CVPR |
Multi-view Reconstruction via SfM-guided Monocular Depth Estimation |  |
website |
| 2025 | CVPR |
Align3r: Aligned monocular depth estimation for dynamic videos |  |
— |
| 2024 | NIPS |
Cat3d: Create anything in 3d with multi-view diffusion models | — | website |
| 2024 | ECCV |
Diffusiondepth: Diffusion denoising approach for monocular depth estimation |  |
website |
| 2023 | NIPS |
The surprising effectiveness of diffusion models for optical flow and monocular depth estimation | — | website |
| 2023 | arXiv |
Monocular depth estimation using diffusion models | — | website |
| 2023 | arXiv |
Mvdream: Multi-view diffusion for 3d generation |  |
website |
Pose Estimation
| Year | Venue | Paper Title | Repository | Note |
|---|---|---|---|---|
| 2023 | ICCV |
Posediffusion: Solving pose estimation via diffusion-aided bundle adjustment |  |
website |
Other Resource
- What is Diffusion?
- Survey for Learning-based VO,VIO,IO:Paper List and Blog
- Survey for Transformer-based SLAM:Paper List and Blog
- Survey for NeRF-based SLAM:Blog
- Survey for 3DGS-based SLAM: Blog
- Awesome-Diffusion-Models
- Some basic paper for Diffusion Model:
| Year | Venue | Paper Title | Repository | Note |
|---|---|---|---|---|
| 2022 | CVPR |
High-resolution image synthesis with latent diffusion models |  |
stable diffusion |
| 2021 | NIPS |
Diffusion models beat gans on image synthesis | — | Ablated Diffusion Model(ADM) |
| 2020 | ICLR |
Denoising diffusion implicit models | — | DDIM |
| 2020 | NIPS |
Denoising diffusion probabilistic models |  |
DDPM |
Paper Reading
接下来重点阅读几篇论文
MATCHA: Towards Matching Anything
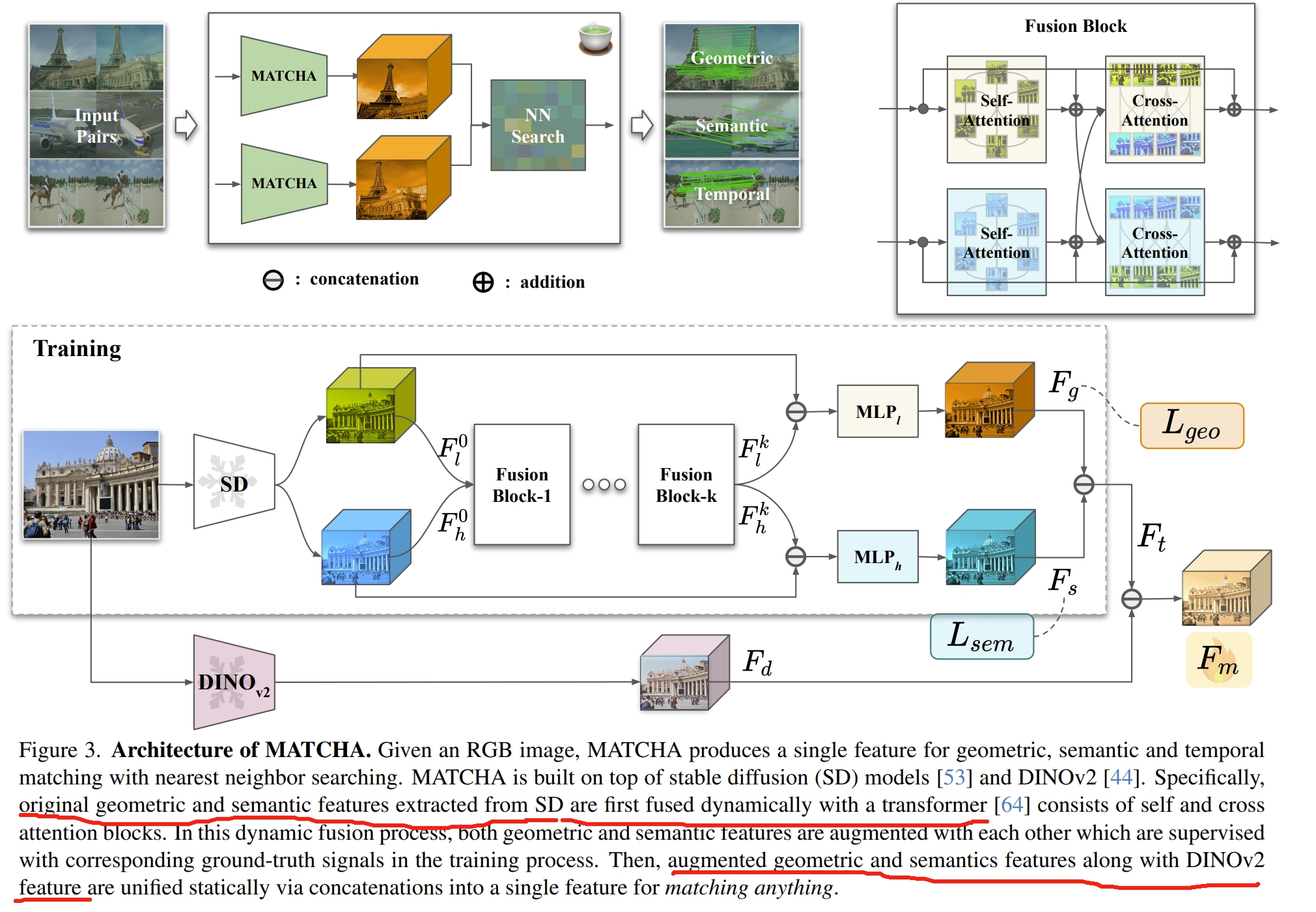
建立于insights:diffusion model features can encode multiple correspondence types,作者提出基于diffusion model 的MATCHA,并进一步通过基于注意力的动态融合高级语义和低级几何特征,进而获取具有代表性的、通用的以及强鲁棒性的特征。
这里所谓的特征匹配包括了几何( geometric)、语义(semantic)、时间(temporal)等多个维度的特征匹配,也就是同一个框架,只需要学习单个特征的描述子即可完成这三个任务下的特征匹配

MATCHA整合了来自于DINO V2(《Dinov2: Learning robust visual features without supervision》)的特征来进一步增强泛化能力。 关于这点,应该是由于缺乏来自语义以及几何的足够的真实数据,因此作者直接用了预训练的transformer模型来增强泛化能力。如下图所示

DINO V2提供的应该是 semantic knowledge, DIFT提供的semantic和geometric信息,在图例上具有互补性,而MATCHA则是利用了这三种基本的特征来提供更可靠的特征匹配。
其框架如下图所示。首先通过stable diffusion来分别提取语义以及几何特征,并通过transformer来融合一起,再通过对应的真值来分别训练。
然后把来自于DINOv2的特征与stable diffusion的语义及几何特征concatenate到一起,作为matching anything的特征.
说实话,这个框架感觉有点大力出奇迹的意味,stable diffusion+transformer+DINOv2全部柔到一块,而其中的stable diffusion+transformer则是DIFT,因此算是DIFT+DINOv2
下面看看实验效果
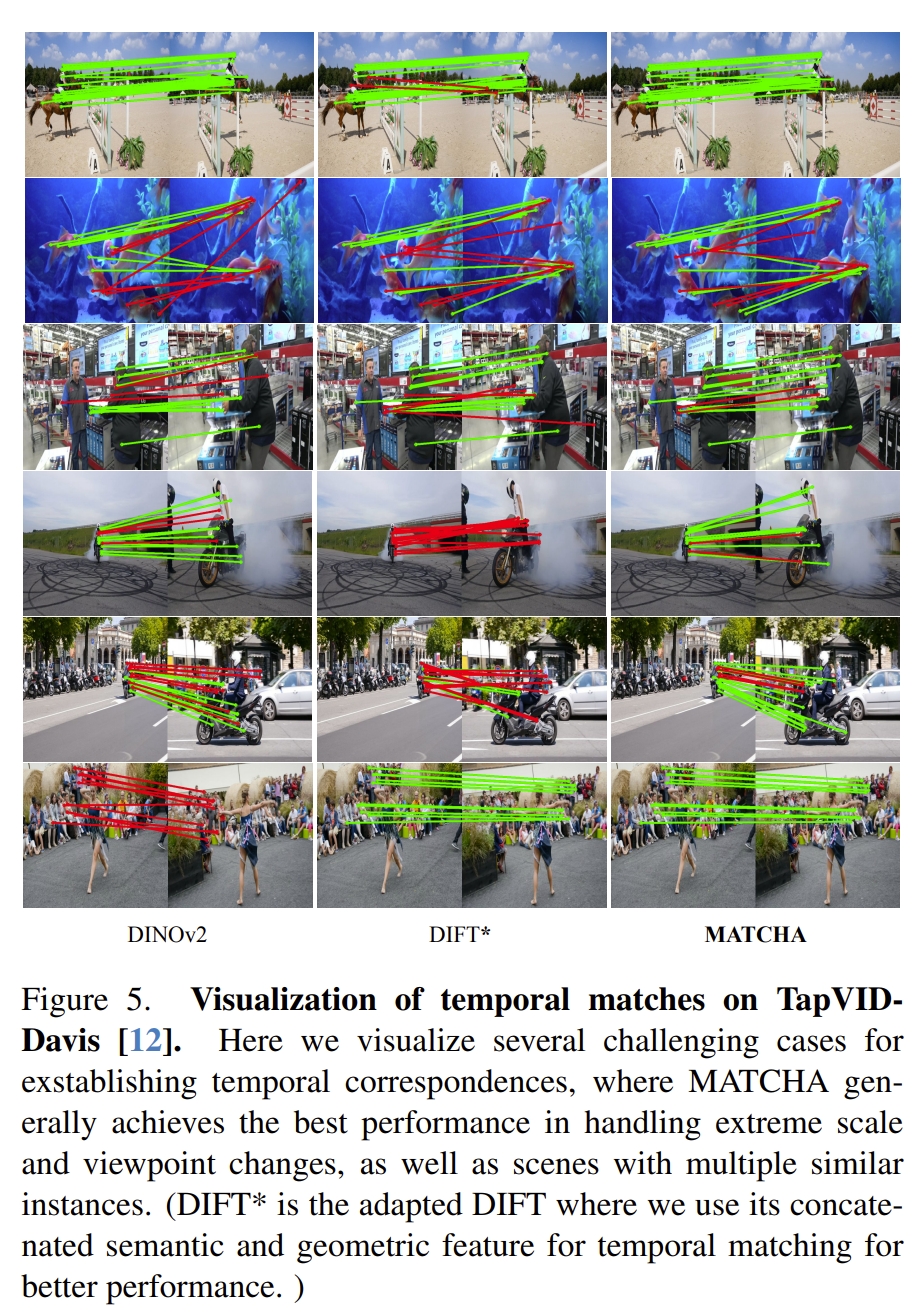
红色应该是误匹配的,但是哪怕是六张图,感觉上也就只有两张MATCHA没有误匹配,其他对比效果个人觉得不太明显。毕竟考虑到是把前两者融合到一起的大模型😂
当然,作者也有跟MASt3R等SOTA对比的几何、语义、跟踪等匹配的效果(太多了,就随机列出一些,更多的请见原文~)。 下图的结果都是RANSAC输出的inliers
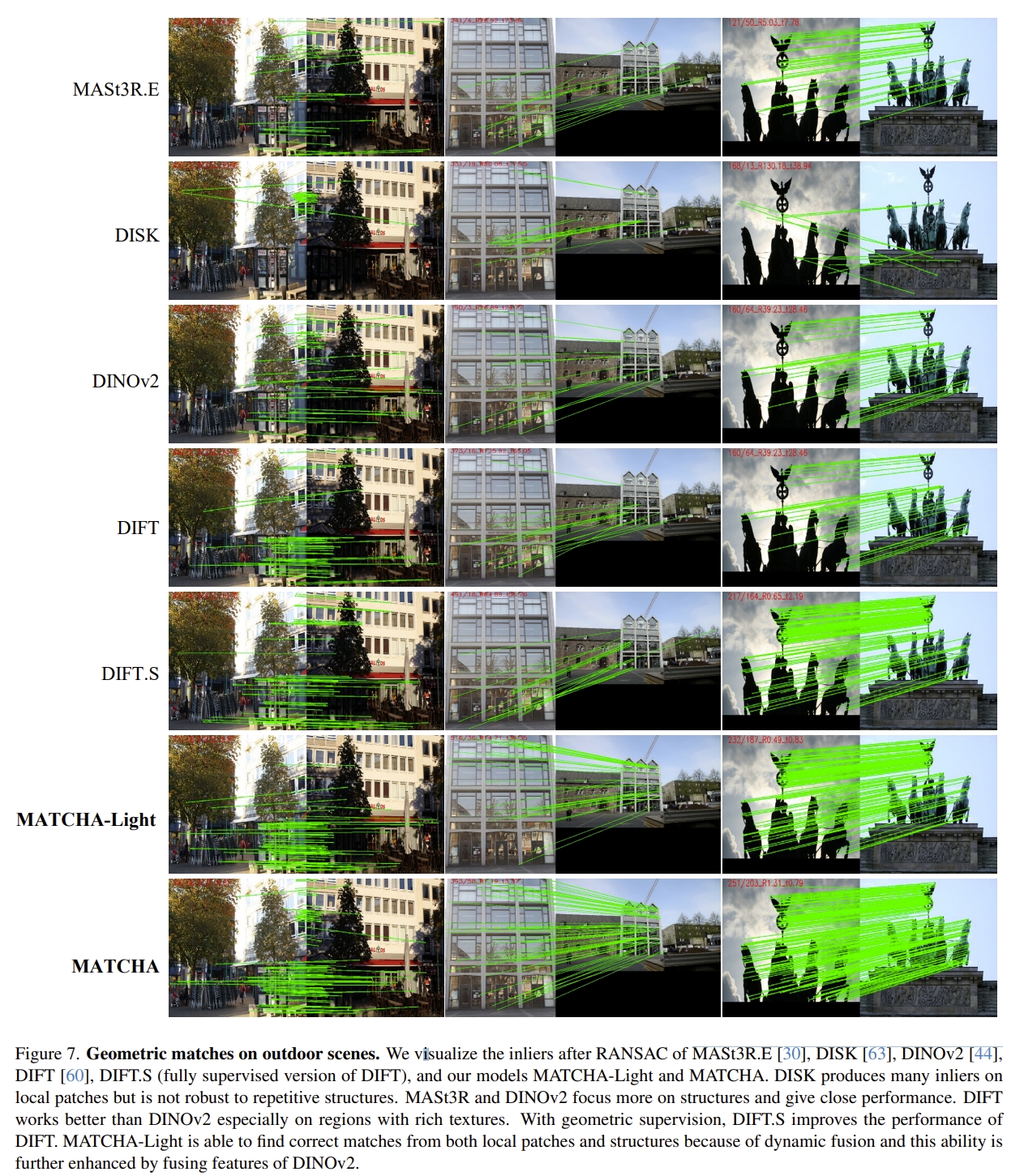
|

|
语义匹配的效果

|

|
Emergent correspondence from image diffusion
这篇论文就是DIFT(DIffusion FeaTures),也就是利用diffusion model来获取图像之间的correspondence,同样地,也是针对semantic, geometric, 和 temporal数据关联,并且不需要用task-specif数据来进行监督或者fine tuning。
diffusion model一般是用于做图像生成的,那么最关键的observation就是它在 image-to-image translation以及image editing上有好的表现(如下图所示)。而这个过程实际上就是隐式的将两张图片的数据关联对应起来,因此diffusion model应该也可以用于做图像之间的数据关联

如下图所示,所谓的semantic correspondence也就是指定了位置(比如鸭子的熊的耳朵),那么在各种不同但相似的图像上也可以把耳朵的特征点关联出来

Diffusion models是一种生成模型,将正态分布转换为任意的数据分布的形式。而在训练的过程中,带有不同幅度的高斯噪声会被加到数据点上(clean data point)以获取带噪声的data point,如下公式所示

而一个神经网络$f_{\theta}$则会用于学习以图像$x_{t}$和时间$t$为输入,预测噪声$\varepsilon$. 在图像生成领域,网络$f_{\theta}$一般是U-Net,而经过训练后,$f_{\theta}$可以用来逆转diffusion的过程(”diffusion backward process”): 从一个来自于正态分布采样的纯噪声$x_{T}$,$f_{\theta}$可以迭代估算来自于噪声图片$x_{t}$的噪声$\varepsilon$,然后去掉这个噪声来获取更清晰的数据$x_{t-1}$,最终获取一个原数据分布下的$x_{0}$
那么针对上面图像生成的过程,通过提取backward process中,特征时间$t$的中间层的feature map,然后用其来建立两张不同生成图片之间的correspondence,如下公式所示

而对于到底应该拿哪一个$t$对应的网络,作者发现越大的$t$以及越前的网络层就有更多可识别的语义特征,而越小的$t$以及越后的层则会更多的low-level细节。作者通过消融实验来验证了这部分(具体请见原文)
PS:个人感觉就是作者假设Diffusion models是可以获取两张图像之间的关联的,然后就确实从Diffusion models中的一层获得的feature map作为描述子,而这又确实可以用。然后再从理论反推的~~~
语义以及temporal tracking可能不是SLAM中关注的,这里看看它几何匹配的效果


PS:对于diffusion-based feature matching的看法: 感觉这一系列的diffusion-based matching的论文首先都是以语义匹配为主的,毕竟diffusion本身就是图像生成或者translation等相关的,因此可以做到语义转换后仍然可以实现较好的匹配。而对于geometric 和 temporal的特征匹配其实就是在语义的基础上的降维打击了hhh,毕竟语义都能匹配上,更何况只是几何的角度不一样呢。
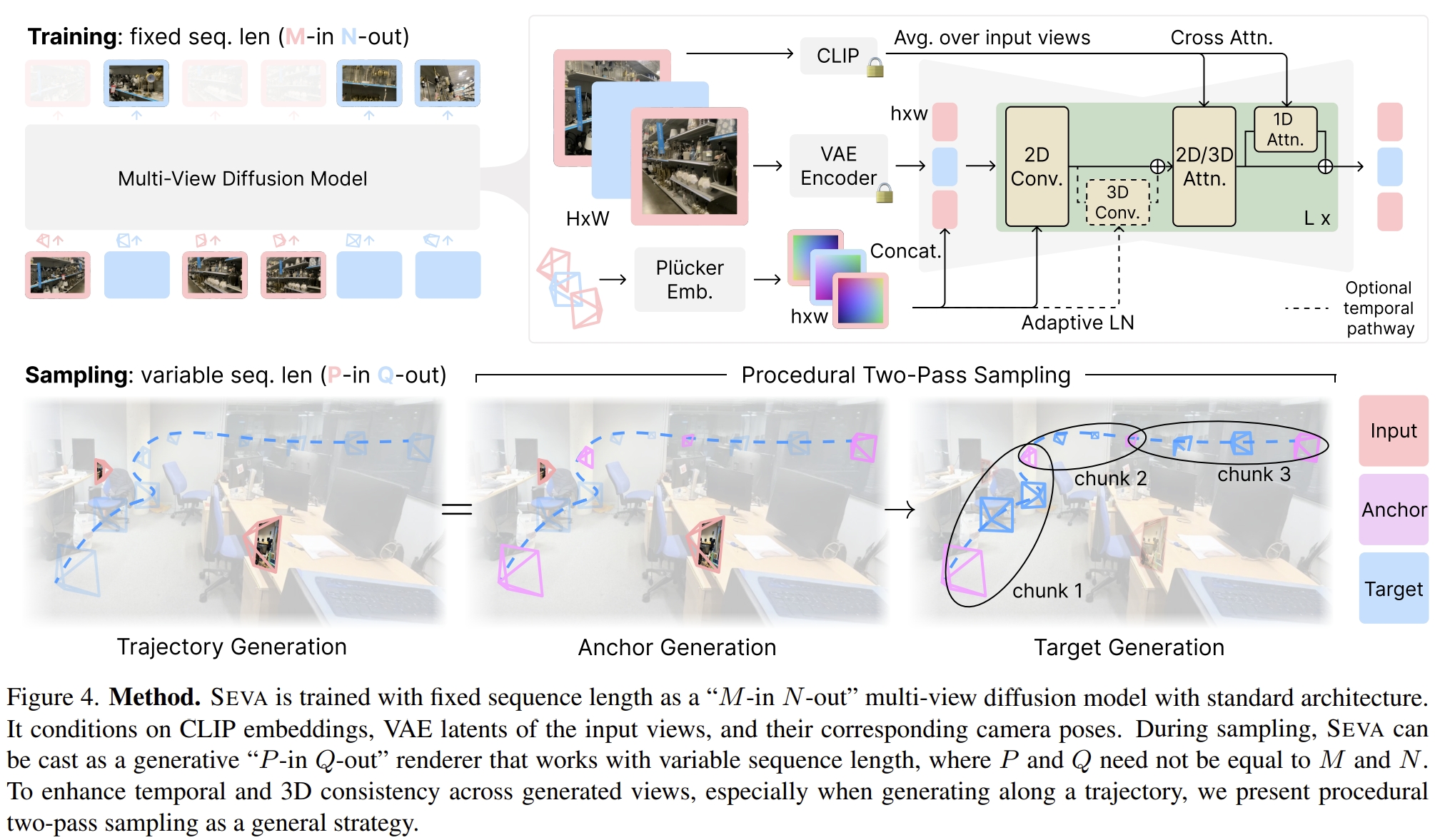
STABLE VIRTUAL CAMERA: Generative View Synthesis with Diffusion Models
STABLE VIRTUAL CAMERA (SEVA),就是输入视角以及相机pose等信息,可以获得场景的新视觉。但是跟其他新视觉合成的工作不一样,不依赖于固定的输入,比如像NeRF之类的,需要360度全方位覆盖,视角间的位移不能太大。具体见nerf系列的工作就知道😂,相邻两个视角基本上是肉眼分不出区别的小位移,不然效果就非常差。而这篇工作应该就是利用了Diffusion Models可以弥补这些缺陷为motivation的:
- 可以handle大视点变化建模与时间平滑
- 应对任意长度的相机轨迹(也就是任意输入视角)
- 在新视觉合成任务上,具有泛化能力

SEVA解决的是新视觉合成(Novel view synthesis,NVS)的问题。其结构如下,采用的是Stable Diffusion的结构,并且结合了self-attention
Bolt3D: Generating 3D Scenes in Seconds
这篇论文则是属于三维重建领域的, 用单个GPU,在7秒内获取3维场景。 采用的是2D diffusion network来预测出一致性强的3D场景 而为了训练这个模型,作者构建了一个大尺度的3D数据集。
当前的diffusion model在图像以及视频的生成都有不少的工作,但是都是基于2D图像的,并不是3D图像的(比如上一篇,只是新视觉合成,那么也只是2D图像层面的)。 而之所以用diffusion model生成3D这么具有挑战性,主要是由于以下两个原因:
- 表示和构造3D数据以能够训练以高分辨率生成完整场景的扩散模型是一个未解决的问题。(也就是数据集的问题)
- 真值3D场景也是稀缺的(比起生成模型的2D数据集),那么也就是数据集的问题。
而这也导致大多数的3D生成模型只能局限于合成物体、新视觉、部分“forward-facing”的场景。而要真正合成3D场景,需要进一步的通过NeRF或者3DGS,虽然这可以产生高质量的3D数据,但是不现实。
那么其实读到这里,就很显然的,本文就是通过构建了一个好的、大的3D数据集可以喂给existing 2D diffusion network,以及可以leveraging powerful and scalable existing 2D diffusion network。而在这篇论文之前的diffusion-based 的3D重建的工作基本都是有局限的“伪3D”
不过即使作者前面这样说,但是本文实际上又还是将3D场景表达为一系列的存在多个2D网格下的3D Gaussians,其结构如下图所示
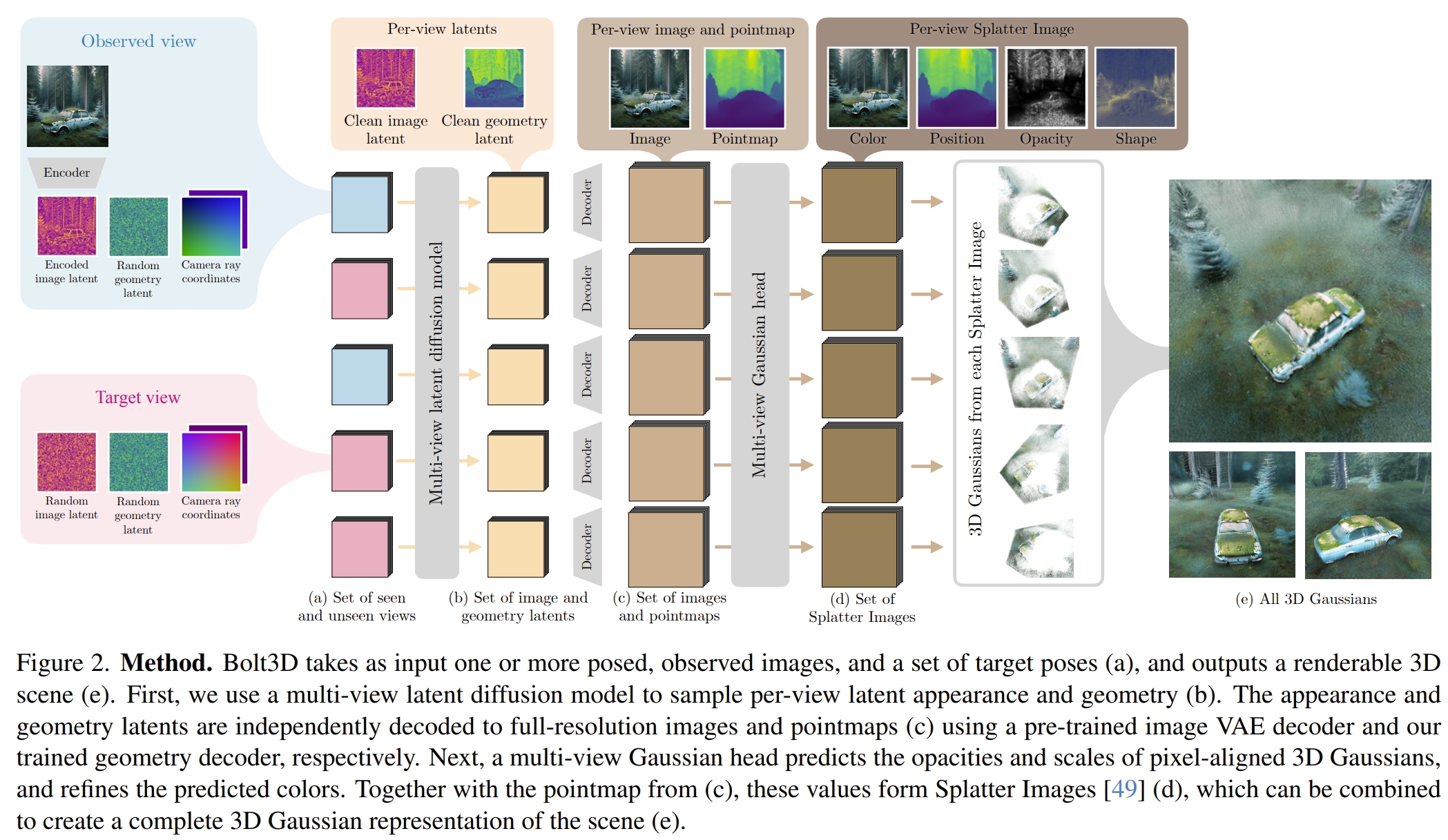
生成的过程主要分为两部分:
- “denoising” 每个高斯的color 以及position
- 回归每个高斯的透明度(opacity)以及形状(应该就是旋转和尺度等高斯球的属性了~)
输入一系列的image以及对应的pose,模型可以预测场景的外观(pixel color)以及场景点的3D坐标,然后通过训练一个 Geometry Variational Auto-Encoder(VAE)来获取高精度的每个pixel的3D几何信息。 而所构建的数据集实际上是通过MAST3R生成的,然后用这个数据集来训练diffusion以及VAE
PS:那么也就是用了Diffusion+VAE+3DGS最终拟合出类似MAST3R的效果?如果是这样的话,那么至少感觉diffusion在3D reconstruction这个任务上是远不如Transformer的,至少本文和上一篇论文读下来连解析为什么用diffusion都没有。而Transformer则是从概念层面上很好的进行了时空之间的关联,而diffusion似乎更加适用于生成方面的任务。而从论文网页的一些demo效果来看,感觉生成的3D模型比较一般~~~
Posediffusion: Solving pose estimation via diffusion-aided bundle adjustment
这篇论文提出的就是将sfm问题用probabilistic diffusion framework来构建。其实基于以下的motivation的:
- diffusion framework相当于bundle adjustment的迭代处理的过程(diffusion framework迭代加噪或者去噪可以等同于迭代的BA)
- 将diffusion framework formulate成BA的过程可以很好的从对极几何中引入几何约束
- 在稀疏视角下有好的表现(应该就是利用了diffusion生成、推理的能力)
- 对于任意数目的图像可以预测其内参和外参。
其框架如下图所示。感觉跟DDPM模型很像,只是把估算噪声改为了估算相机的内外参。
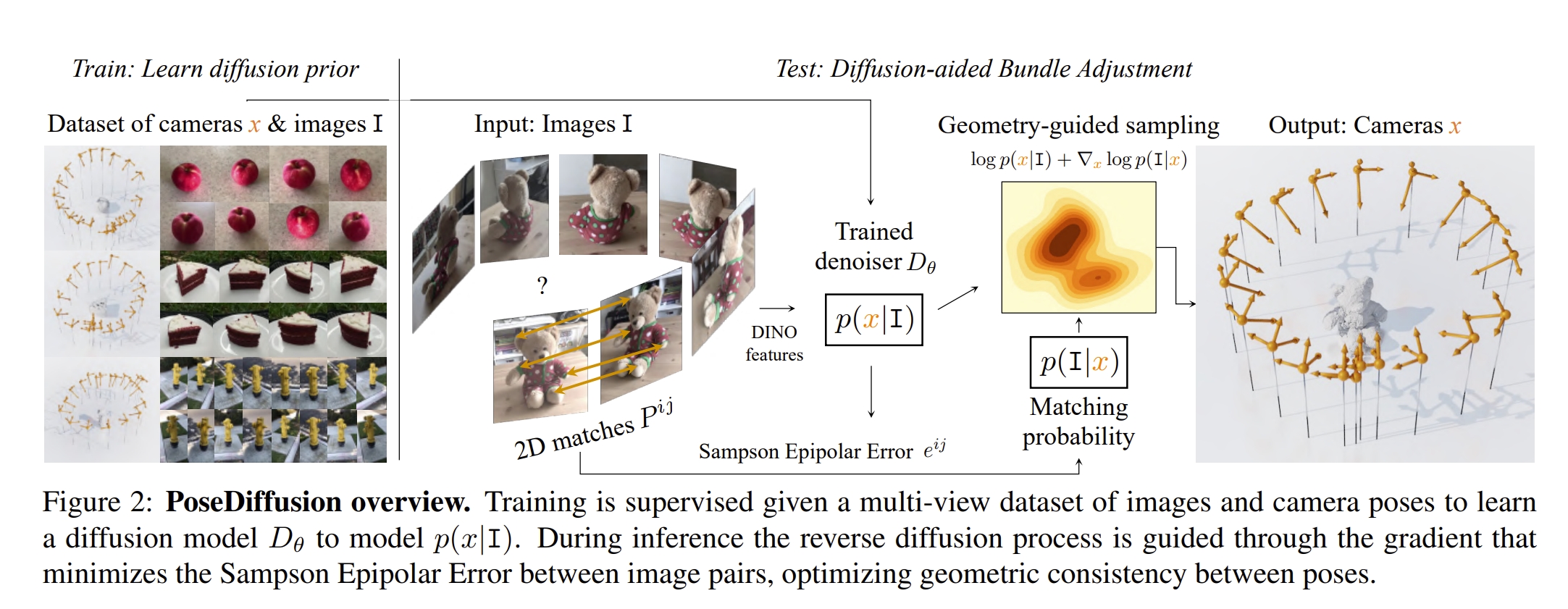
| 其中建模的$P(x | I)$可以理解为对于图片$I$其相机的参数$x$的概率分布。而从图片估算相机参数的模型则是用Transformer来训练的 |

|
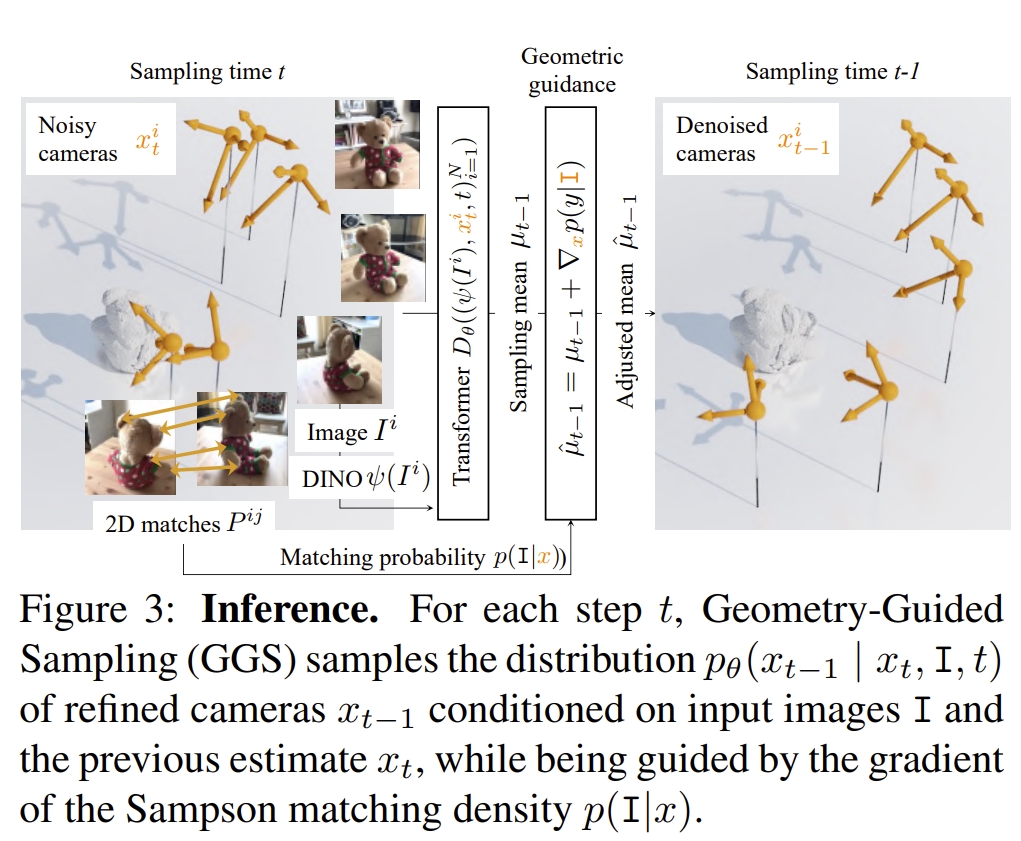
|
PS:本质上就是Transformer直接可以解决的问题,要改到diffusion迭代处理,用类似逐步加高斯去噪的过程来求pose
至于实验关于定位精度方面的验证基本是跟sfm对比,没有跟传统的SLAM方法对比,而且验证的序列也是非常少的
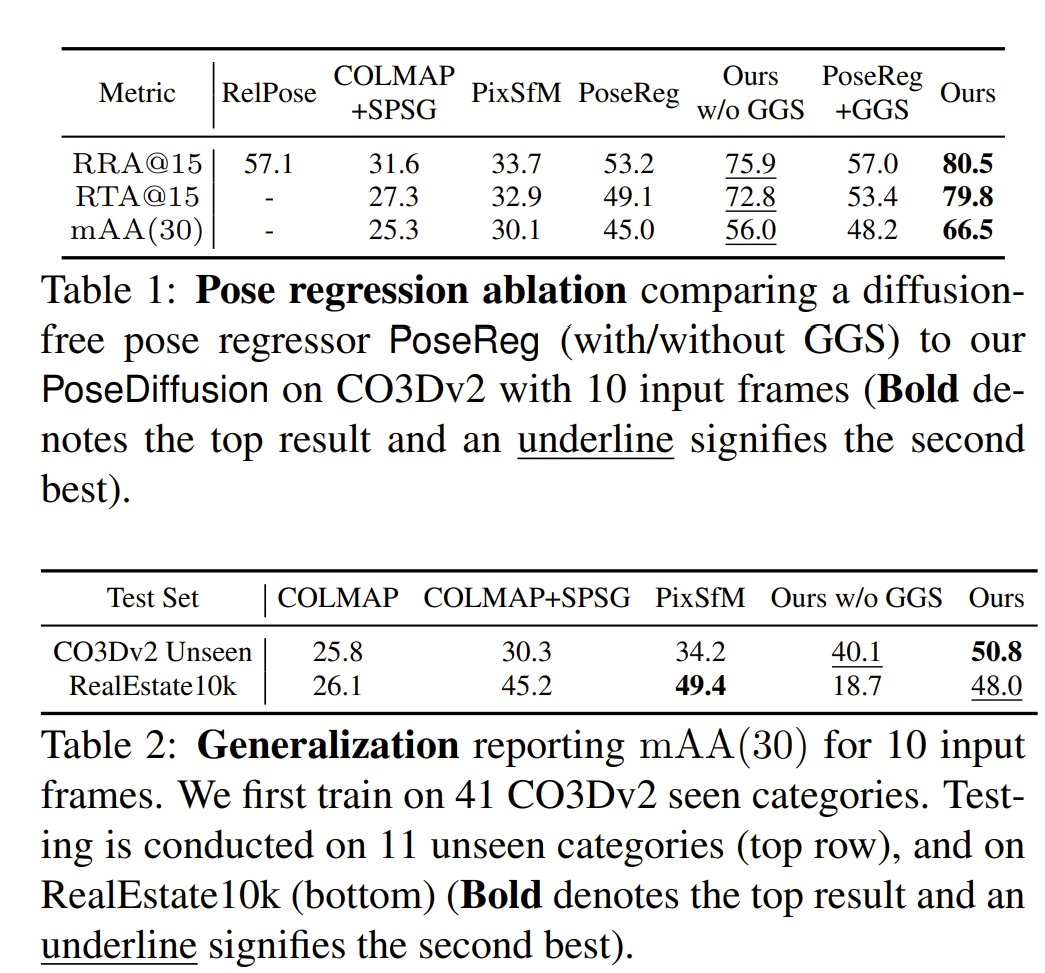
总结这几篇工作
目前这几篇diffusion的工作,除了做feature matching是比较make sense以外,其他基本是硬要把别的可以独立完成task的框架改成diffusion来做。比如最经典的就是上面的Posediffusion。不过也是提供了解决问题的额外的新思路。期待后续有更加make sense的diffusion-based SLAM工作吧~