引言
动作视觉语言(Vision-Language-Action,VLA)模型正成为机器人理解环境与执行任务的核心框架。 然而,主流VLA系统通常依赖体量庞大的视觉与语言模型。 这些模型普遍依赖大规模的视觉编码器和语言模型,导致推理过程计算复杂度高、延迟大、内存占用高。同时,动作输出的连续性与平滑性问题也直接影响任务执行的可靠性。这些瓶颈严重制约了VLA模型在实时、资源受限场景下的应用。 因此,本博文,对survey paper——Efficient Vision-Language-Action Models for Embodied Manipulation: A Systematic Survey进行阅读,并记录阅读过程的一些心得想法。
本博文仅供本人学习记录用,其他与VLA相关的调研请见博客:
- Paper Survey之——Awesome Vision-Language-Action (VLA)
- 论文阅读笔记之——《Vision-language-action models: Concepts, progress, applications and challenges》
对于高效的VLA架构,代表性工作的发展时间节点如下图所示:
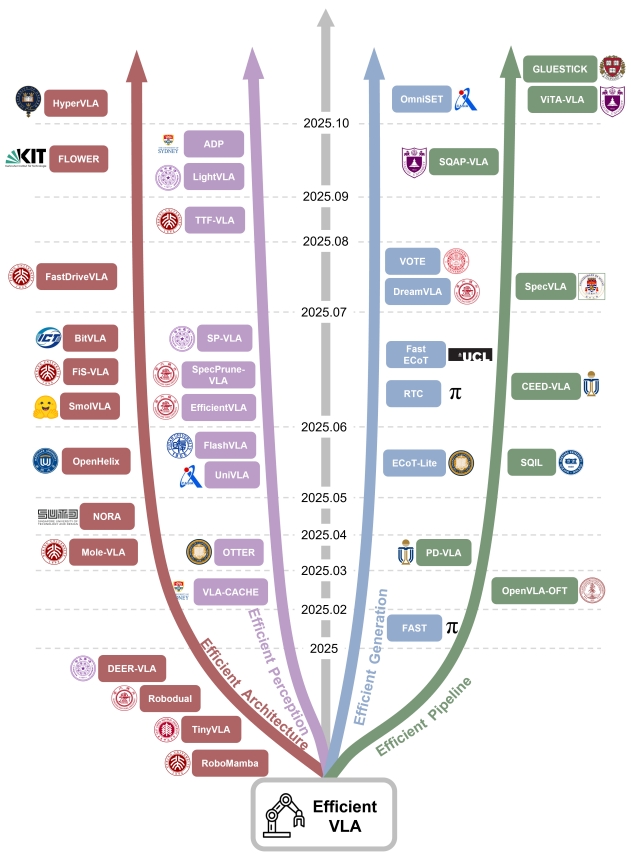
对于提升VLA”效率”,该论文从下几个维度展开:
1. 高效模型架构设计(model architecture)
在维持模型性能上限的同时,最小化平均推理开销。
- 压缩骨干模型(Static Backbone Selection):使用参数量更小的预训练模型,或设计轻量化的序列模型来替代超大规模的骨干网络。此类策略直接减少了参数量与内存占用,实现简单,但存在压缩模型性能上限的风险。
- RoboMamba:引入Mamba状态空间模型架构作为序列模型,参数量约为2.7B,相比基于Transformer的LLM,能更高效地进行时间建模和并行推理,从而减少延迟。
- Tiny VLA:使用Pythia-1.3B等小型LLM,在保持核心任务能力的同时压缩整体模型,使边缘部署更可行。
- SmolVLA:采用SmolVLM-2(参数量为0.24B、0.45B、2.25B),并通过剪枝最终的Transformer层进一步减少计算。
- NORA:将骨干网络替换为Qwen-2.5-VL-3B,以实现更小的占用空间但同时保留强大的性能。
- 动态计算路径(Dynamic Computation Pathways):在训练阶段保留大型骨干网络,但在推理阶段引入动态路径选择,以在不完全牺牲能力的情况下提高效率。模型保留大型架构的表达能力,同时在特定任务上下文中丢弃冗余计算。
此类方法能在保障复杂样本处理能力的同时,显著降低平均计算成本,但代价是增加了路由机制和训练的复杂度。
- SmolVLA:采用简单的层剪枝策略,永久移除语言模型中固定数量的最终层(final layers)。
- FLOWER:基于LLM的可解释性发现,剪枝冗余的顶层(如编码器-解码器VLM中的解码器或仅解码器模型中的最后几层),以平衡上下文表达能力和计算效率。
- DEER-VLA:引入早期退出机制(early-exit mechanism),在语言模型不同中间层放置轻量级策略头( lightweight policy heads),通过输出相似性指标(output-similarity metric)决定是否提前退出。退出阈值通过平衡平均/峰值FLOPs和GPU内存使用的约束目标进行优化。
- MoLE-VLA:将语言模型的每一层视为潜在专家,采用Mixture-of-Experts (MoE) 框架,通过门控机制(gating mechanism)动态选择参与计算的层。为稳定训练,还应用了自蒸馏(self-distillation),完整/未剪枝的网络用于指导如何减少计算的path。
- Efficient-VLA (采用similarity-based skipping):通过测量层输入和输出特征向量之间的余弦相似度来评估每层的贡献,如果相似度超过阈值,则在推理时跳过该层。
- 双系统架构设计(Dual-System Design):受认知科学双系统理论启发,将模型分为一个用于复杂推理和长期规划的“慢系统”和一个用于快速、直观响应的“快系统”。两个子系统协同工作,处理复杂的、高层次任务,同时确保简单场景下的低延迟推理。通常采用异构模型架构:慢系统依赖大型多模态语言模型(MMLM)进行语义理解和推理,快系统采用轻量级模型快速响应感知输入。两个系统通过潜在Token或嵌入交换信息。
- LCB:使用LLaVA作为慢系统生成语言描述和动作提示,然后指导3D Diffuser Actor作为快系统通过可学习的
<ACT>Token生成最终动作。 - HiRT:采用InstructBLIP作为慢系统生成表示,然后由EfficientNet-B3作为快系统通过MAP池化进行高效控制。
- RoboDual:结合OpenVLA作为慢系统和DiT作为快系统。慢系统输出潜在表示,快系统通过Perceiver Resampler进行细化以重建简化的动作输出。
- OpenHelix:提供主流双系统框架的系统回顾和评估,并提出了优化的模块化配置。具体来说,LLaVA-7B作为慢系统,3D Diffuser Actor作为快系统,通过可学习的
<ACT>Token进行通信。 - FiS将“快”和“慢”两种处理模式融入一个统一的神经网络结构中,而不是分离成两个独立的模型。它通过网络内部不同层次的功能划分来实现这种“隐式”的双系统。浅层(Shallow layers)负责处理输入信息,构建出中间的语义表示.最终层(Final layer)利用这些语义表示来预测最终的动作。这可以看作是“快系统”的一部分,基于已有的语义信息快速做出决策。
- Hume引入了一种级联双系统结构。慢系统在多个噪声尺度下生成候选动作块,而一个可学习的聚合 token 输入到一个 value query head,该query head对候选动作进行评分。最有希望的动作块随后由快系统进一步分解和去噪,以产生最终的动作序列。训练是联合进行的:policy head和快系统通过flow matching进行优化,并且policy head使用离线强化学习在带有奖励标注的数据集上进行训练。
- HyperVLA虽然不是传统的双系统的架构,但也是two-stage framework,HyperNetwork根据语言指令和视觉输入动态生成任务特定的基础策略(Base Policy)参数。而Base Policy接下来利用视觉特征以及可学习的action token生成单步动作。从而消除了对语言指令的需求,并降低了自回归(autoregressive)或基于diffusion的解码的计算成本。HyperVLA可以被视为一种参数传输的双系统VLA:超网络(系统2)将感知编码到基础策略(系统1)的参数中,从而实现高效且语义一致的动作生成。
- SP-VLA根据末端执行器速度区分直观(intuitive)动作和深思熟虑(deliberate)动作。直观动作由轻量级模型处理,而深思熟虑动作则由主要的VLA模型处理。轻量级路径仅在需要完整VLA级别处理的动作比例超过预定义阈值时才被激活,从而确保了响应性和可靠性。
- LCB:使用LLaVA作为慢系统生成语言描述和动作提示,然后指导3D Diffuser Actor作为快系统通过可学习的
2. 感知特征压缩(Efficient Perception Feature)
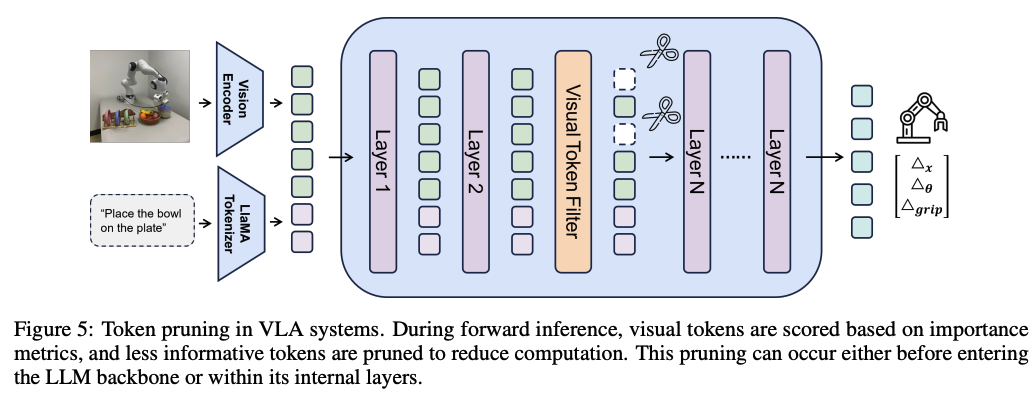
VLA一般上多模态输入,包括了视觉感知、文本描述以及机器人本体的感知。 视觉模态输入通常构成最长的Token序列,是VLA模型最主要的计算开销来源。 然而,并非所有的视觉信息都跟决策的过程相关。 在许多任务中,输入图像的很大一部分,如背景区域、与任务无关的物体或时间上不变的内容,并不会显著影响动作选择。 这些冗余区域会产生不必要的计算,尤其是在高分辨率输入和长周期(long-horizon)任务中,从而降低推理效率。
|
|
- 单帧特征选择性处理(Selective Processing of Single-Frame Perception),即在信息到达下游策略网络之前,进行,修剪、压缩或转换冗余信息。
通过基于注意力分数或特征相似度等指标,筛选并保留任务相关的视觉token,或通过token压缩机制将可变长度的长序列映射为固定长度的紧凑表示。
- 基于注意力分数的剪枝 (Attention-Score Based Pruning):在推理过程中直接修剪视觉Token。
- FastV:计算每个视觉Token在LLM中间层从所有Token接收到的平均注意力(average attention),并根据这些重要性分数进行Top-K剪枝。
- EfficientVLA:进一步量化视觉Token与任务指令之间的交互,选择捕捉语义相关性的关键Token,并通过高注意力和多样性驱动的token(task-driven tokens of high attention and diversity-driven tokens)来增强它们,以确保表征的丰富性。
- SP-VLA:强调Token的剪枝应保留空间结构,除了通过注意力捕获的语义重要性外,还通过边缘检测测量轮廓线索的空间相关性,保留满足前面任一标准的Token,确保场景完整性。SP-VLA还引入了自适应剪枝,根据运动动态调整剪枝的aggressiveness程度,在任务要求变化时权衡效率和保真度。
- 基于特征的替代方法 (Feature-Based Alternatives):不直接依赖注意力分数,而是通过其他特征分析方法来评估Token的重要性。
- FlashVLA:通过对注意力输出矩阵应用奇异值分解(SVD)来推导信息贡献分数(ICS),该分数衡量每个Token在主奇异方向上的投影。
- 动态和上下文感知的剪枝策略 (Dynamic and Context-Aware Pruning Strategies):将语言指令和动作信息整合到剪枝过程中,使剪枝更加智能和适应性强。
- LightVLA:针对视觉编码器生成的视觉Token,而不是在LLM内部操作。它采用查询驱动的Token(query-driven token)选择机制,通过跨模态注意力动态生成查询,识别最具信息量的视觉Token。选择过程通过Gumbel-Softmax结合直通估计器实现可微分,从而实现端到端训练,同时保留空间位置编码,无需手动预定义保留多少Token。
- ADP:引入two-stage机制:首先,任务驱动的静态剪枝计算文本查询和跨模态注意力,评估每个视觉Token的全局重要性,保留与指令最相关的Token;其次,动态的、动作感知的开关(dynamic, action-aware switch)根据最近的末端执行器运动调整剪枝,使用滞后机制(hysteresis mechanism)在粗略运动期间平衡压缩,在精确操作期间平衡感知保真度。
- FASTDriveVLA:类似地将动作感知集成到Token剪枝中,但在训练期间添加了前景-背景对抗重建(foreground-background adversarial reconstruction),确保模型能够区分关键前景信息和冗余背景信息。Token分数通过一个轻量级评分器计算,该评分器结合了Token特征和通过Hadamard融合的可学习查询,并在推理期间应用Top-K选择,同时保留位置信息。
- SpecPrune-VLA:一种无训练的剪枝(training-free pruning)方法,通过启发式控制(heuristic control)执行两级Token减少。在动作级别,静态剪枝评估先前动作的全局Token冗余和当前动作的局部Token相关性,在生成之前减少视觉Token。在层级别,动态剪枝利用Token和模型层之间的相关性,根据层特定的重要性剪枝Token。一个轻量级的、动作感知的控制器根据当前动作的粒度进一步调整剪枝:粗粒度动作允许更多剪枝,而细粒度动作需要更高的保真度。
- SQAP-VLA:通过空间和量化感知的Token剪枝框架来保证在低精度量化下保持鲁棒性并确保空间覆盖。它采用了三个互补机制:在量化(quantization)下保留任务关键Token,保护机器人末端执行器附近的Token,以及采样Token以保持空间覆盖。这些策略共同确保最终保留的Token集平衡效率、稳定性和覆盖范围,从而实现可靠的低位推理(low-bit inference)。
- 表示转换 (Representation Transformation):通过压缩或统一表示来减少信息量或简化多模态集成。
- OTTER:受Perceiver框架启发,提出了一种交叉注意力池化(cross-attention pooling)机制。在文本指令的引导下,该模块将视觉和文本Token压缩成固定长度的紧凑表示。这种侧重于压缩而非丢弃的方法为处理长输入序列提供了新的范式。
- UniVLA:旨在通过将所有输入转换为来自共享词汇表的离散Token来统一视觉、文本和动作模态。这种同质表示实现了模态间的无缝集成,并简化了下游任务(如感知接地、世界建模和策略学习)的训练,从而改善了多模态集成。虽然Token化降低了视觉粒度,但它可以显著缩短序列长度并简化多任务训练。
- 基于注意力分数的剪枝 (Attention-Score Based Pruning):在推理过程中直接修剪视觉Token。
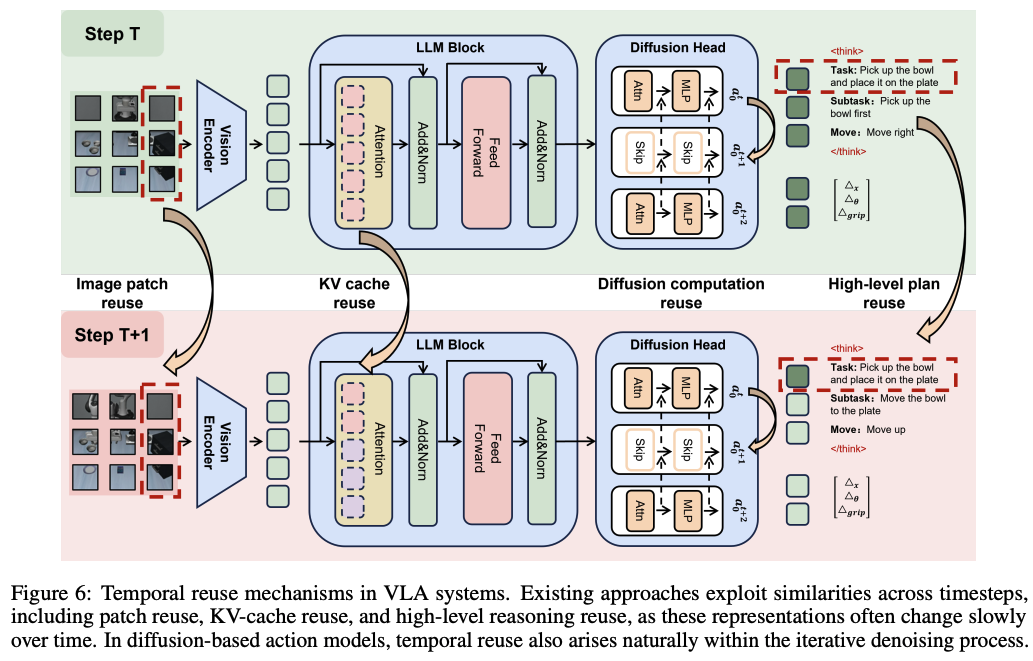
- 跨时序特征复用(Temporal Sharing and Reuse)
即利用帧间相似性,避免对静态或缓慢变化的特征进行重复计算。
利用机器人观测数据在时间上的高度连续性,复用帧间不变或缓变的特征。时序复用能显著降低连续帧之间的重复计算,但必须引入有效的缓存刷新机制来判断复用的安全性,以避免信息漂移或性能退化。- VLA-cache:通过重用基于Transformer架构中静态图像块的键值(KV)缓存来解决连续帧之间的冗余。这些KV缓存存储Transformer的键值向量,允许模型跳过对未更改块的重新计算。VLA-cache会估计跨帧的图像块级相似性(patch-level similarity),并对被视为静态的patches重用KV缓存.为了避免性能下降,高度任务相关的token会被排除在重用之外,并重新计算。此外,VLA-cache引入了注意力熵(attention entropy)作为置信度度量,动态调整跨层的重用比例,以平衡精度和效率.
- TTF-VLA: 通过选择性地融合连续帧的视觉token来利用时间冗余,而不是重用Transformer状态。它维护一个图像块token的历史记录,并通过一个binary importance mask来更新这些token,该掩码识别出具有显著视觉或语义变化的区域。这个掩码来源于像素级差异和基于注意力的相关性,确保只有动态或任务关键的图像块被重新计算。周期性的关键帧更新(periodic keyframe update)进一步防止了长期漂移。
- FlashVLA观察到,在许多场景中,特别是当环境保持稳定时,指导动作选择的内部表征(internal representations)随时间变化很小。因此,它引入了一个轻量级触发器,它可以检测连续感知驱动状态的相似性以及所选视觉token的重叠。当满足这些条件时,模型会重用先前计算的表示,避免冗余计算并确保一致性。
- EfficientVLA:针对扩散模型(如DiT)通过重复去噪生成多步动作表示的特点,EfficientVLA采用固定间隔缓存策略。由于迭代之间的中间特征通常保持相似,它每N步重新计算一次特征,并在其间重用缓存的表示。
- Fast ECoT:ECoT模型通过让视觉-语言模型首先生成自然语言子任务计划,然后才生成任务动作,这虽然提高了可解释性,但也增加了推理延迟。Fast ECoT发现,高级推理模块(特别是规划)演变缓慢并表现出很强的时间局部性。它提出了模块级缓存,如果未检测到显著变化,系统会重用先前的基于文本的计划。
3.动作生成加速 (Efficient Action Generation)
动作是模型与物理世界之间闭环交互的接口,它将高级语义推理转化为低级控制指令。因此,动作表示和生成策略的选择直接影响了长周期复杂任务中的控制精度、响应延迟和整体执行效率。 VLA模型的动作生成策略主要分为两大类:原始动作生成(Raw Action Generation)和推理感知动作生成(Reasoning-Aware Action Generation)
- 原始动作生成(Raw Action Generation):在主流VLA系统中,原始动作生成通常直接输出一个7维向量形式的原始动作,包括3D平移偏移、3D旋转偏移和一个二值抓手状态(binary gripper state)。直接输出低维连续动作向量可以实现最低延迟,但逐步预测在长时序任务中会产生累积误差。改进手段包括动作块化(一次生成多步并做时间平滑)和动作序列压缩(频域变换与量化编码)。这些方法兼顾吞吐量与平滑性。
- 动作块 (Action Chunk):在一次推理步骤中生成连续的动作块。它应用时间集成技术(temporal-ensemble techniques),如平滑或时间平均,以减少每步方差 。这可以减少了误差累积,提高了有效控制吞吐量,有利于高频操作。但是,在块边界(chunk boundaries)处仍可能出现不连续或异常运动(anomalous motions)。
- 实时分块 (Real-Time Chunking, RTC):通过将块生成重新定义为序列修复问题(sequence inpainting problem)来解决块边界的不连续性。它冻结每个新块已执行的前缀(already-executed prefix),并在重叠区域应用软掩码方案(soft-masking scheme),以强制实现跨块一致性,同时仍结合更新的观测结果。RTC基于 diffusion或 flow matching等迭代去噪框架,可在块之间提供平滑的策略转换,同时保持鲁棒的实时控制。
- FAST:在推理前压缩离散的动作序列。它应用离散余弦变换(DCT)将序列转换到频域,保留主要的低频系数,然后应用字节对编码(BPE)来减少token长度。
- OmniSAT:引入统一的action tokenizer,将连续轨迹转换为压缩的离散token。它首先执行B-spline-based时间对齐以获得固定长度的控制点表示(fixed-length control-point representations),然后应用残差向量量化(residual vector quantization,RVQ)将其离散化为多层码本索引,并按位置、旋转和抓手维度进一步分组。生成短而语义结构化的token序列,在保持轨迹保真度的同时,实现了跨不同具身的高效自回归建模。
- VOTE:引入一个特殊的token
<ACT>来表示整个动作块,然后通过轻量级MLP映射到连续动作。显著减少了生成的token数量和解码步骤,实现了更快的推理和更低的训练成本,同时保持了强大的任务性能。在推理过程中,VOTE通过集成投票机制(voting mechanism)进一步增强鲁棒性,其中来自先前步骤的候选动作形成一个委员会,其加权投票决定最终输出。 - SpatialVLA:结合了动作离散化和动作token压缩,将平移向量转换为极坐标以解耦方向和距离,同时保留欧拉角用于旋转并离散化抓手状态。
动作生成策略从直接预测原始动作,发展到通过分块平滑输出,再到压缩和重构动作token。这些方法相互补充,以满足高频控制需求,减少延迟,并缓解误差累积/
- 推理感知动作生成 (Reasoning-Aware Action Generation):
上面侧重于直接生成原始动作的纯动作VLA系统。这种方法具有推理管道短、延迟低、端到端训练优化目标统一等优点,从而实现高计算效率和部署简单性,并在高频控制设置中保持流畅执行。然而,它面临一些局限性:解释性有限、跨任务泛化能力弱,以及与原始VLM预训练目标存在显著的任务差距,导致模型潜力未充分利用。
因此,在动作前引入显式推理,包括语言层面的任务分解和视觉层面的子目标预测。此类方法提升可解释性与跨场景泛化,但显著增加序列长度与推理延迟。实践中常采用选择性推理或对高层推理结果实施缓存以减少频繁调用成本。
- 基于语言的推理 (Language-based reasoning):将复杂任务指令分解为细粒度的子任务描述,以便分阶段执行。
- 具身思维链推理 (Embodied Chain-of-Thought Reasoning, ECoT):在生成原始动作序列之前,应用思维链提示将指令分解为结构化字段(例如,TASK, PLAN, SUBTASK, MOVE, GRIPPER, OBJECTS)。这提供了清晰的任务分解,但显著增加了序列长度(例如,OpenVLA中每步7个token增加到ECoT中每步350个token),从而增加了推理的延迟。
- Fast ECoT:通过重用变化缓慢的高级计划(slowly-changing high-level plans)并采用连续批处理来缓解可变长度序列带来的效率问题,进一步减少了运行时。
- ECoT-Lite:在训练时共同预测推理和动作,但在测试时使用reasoning-dropout,省略推理token,只输出动作以减少延迟。
- 基于视觉的推理 (Vision-based reasoning):从视觉输入中提取空间语义线索,例如可供性、关键点、边界框或目标状态,以指导动作选择。
- UniPi:训练一个用于视频预测的diffusion model作为视觉骨干,首先预测一系列目标状态帧,然后应用预训练的逆动力学模型(pretrained inverse dynamics model)生成动作。使模型能够从大规模、无动作的人类视频数据集中学习。
- SuSIE:为了降低完整视频生成的高昂成本,SuSIE将输出简化为单个子目标图像,然后通过逆动力学模型将其转换为动作,从而减少了推理延迟。
- VPP:通过从预训练的稳定视频扩散模型(Stable Video Diffusion mode)的上采样层中提取多尺度特征,在分辨率上对齐它们,通过VideoFormer融合,并将其传递给扩散策略(diffusion policy)进行动作生成。尽管单步去噪产生的输出更模糊,但它捕获了足以进行规划的未来轨迹趋势。大多数此类方法采用两阶段管道——单独预训练视频生成模型,然后将其与逆动力学模型结合,但这可能会限制跨场景泛化。
- CoT-VLA:将子目标图像token和动作token统一到一个自回归模型(autoregressive model)中,实现端到端视觉思维链推理(visual chain-of-thought reasoning)。虽然这增加了感知和控制之间的耦合,但除了动作之外还需要预测256个图像token,这使推理速度减慢了约7倍。
- DreamVLA:通过动态基于区域的预测(dynamic region-based forecasting)来解决这个问题,使用光流检测与末端执行器或物体运动相关的图像区域,并仅预测这些动态区域。在大大减少计算量的同时,保留了任务相关信息。
- 基于语言的推理 (Language-based reasoning):将复杂任务指令分解为细粒度的子任务描述,以便分阶段执行。
4. 训练推理优化(training/inference strategies)
VLA模型效率优化不仅依赖于模型架构设计、感知表示和动作生成,还需关注训练和推理过程的效率提升,以实现大规模部署。
- 训练端的重点在于降低模型在新任务和新环境下的适配成本。常用策略包括参数高效微调、知识蒸馏、结构化剪枝与量化感知训练。前两者通过少量可学习参数或教师–学生迁移实现快速适配,后两者则在压缩模型规模的同时保持控制精度,整体提升了模型的部署效率与可扩展性。
- 参数高效微调 (Parameter-efficient fine-tuning, PEFT):
- Tiny-VLA表明,大型预训练模型昂贵的完全参数适配是不必要的。
- Low-Rank Adaptation (LoRA):冻结原始权重,并插入少量可训练的低秩矩阵(low-rank matrices)来近似更新。这可以将可训练参数的数量和内存使用量减少几个数量级。因此,模型可以通过小规模、领域特定的数据集进行适配,甚至可以部署在边缘设备或数据受限的环境中。
- 知识蒸馏 (Knowledge Distillation):将大型、复杂的教师模型的知识转移到小型、高效的学生模型中,从而在保持性能的同时降低模型复杂度。虽然蒸馏本身不减少训练成本,但它允许蒸馏后的模型在参数少得多的情况下实现与教师模型几乎相同的能力。
通用蒸馏方法:可以将预训练的大型VLM作为教师模型,指导训练一个更小的、针对具身任务优化的VLA模型。- CEED-VLA:使用一致性蒸馏来稳定非自回归(non-autoregressive)推理。
- MoLE-VLA:在训练过程中应用自蒸馏来传递语义以及控制知识。
- VITA-VLA:将蒸馏表述为跨模型动作对齐:它将预训练的小型动作模型的运动控制专业知识转移到大型视觉-语言骨干(VITA-1.5-7B)中。这个过程从轻量级对齐开始,其中VLA中可学习动作token的隐藏表示(hidden representations)通过MSE损失与专家模型的隐藏表示(hidden representations)匹配,从而实现专家预训练动作解码器的重用。随后的端到端微调阶段在动作和抓手损失的监督下进一步完善多模态融合。通过这种两阶段蒸馏(two-stage distillation),VITA-VLA以最小的额外参数有效地整合了视觉-语言推理(visual-linguistic reasoning)和精确控制。
- 剪枝 (Pruning):移除模型中不重要或冗余的连接、神经元或层,以减小模型大小和计算量。但单纯的修剪往往会导致任务成功率和安全性急剧下降。这是因为VLA权重将重要信息分布在许多方向上,因此即使删除小幅度的权重也会丢弃关键的子空间。
- GLUESTICK:通过事后、无训练恢复来解决这个问题:它计算原始权重和剪枝权重之间的差异,从这个差异中提取主导方向,并在推理过程中将其注入到剪枝模型中。这种低秩校正(low-rank correction)恢复了剪枝丢失的最重要信息,同时保持了效率,并在内存开销和恢复保真度之间提供了可调的权衡。
- 量化 (Quantization):将模型参数和激活从高精度浮点数(如FP32)转换为低精度表示(如INT8、FP16),以减少内存占用和计算需求,同时加速推理。但直接的训练后量化(post-training quantization,PTQ),尤其是在低位宽下,通常会导致动作输出的严重偏差,从而可能导致整个任务失败。
- SQIL:引入了一种由状态重要性分数(state-importance score,SIS)指导的量化感知训练(quantization-aware training,QAT)方法,该分数衡量策略对每个状态扰动的敏感程度。在训练期间,具有较高SIS值的状态会获得更大的蒸馏权重,从而允许量化模型在关键决策状态中保持精度,同时保持整体效率。
- BitVLA:通过对骨干网络应用超低位(ultra-low-bit)QAT进一步提高了量化效率。通过BitNet和SigLIP的渐进式蒸馏(progressive distillation),它实现了显著的压缩,将OpenVLA的内存使用量从约15.1 GB减少到约1.4 GB,同时保持了强大的性能。
-
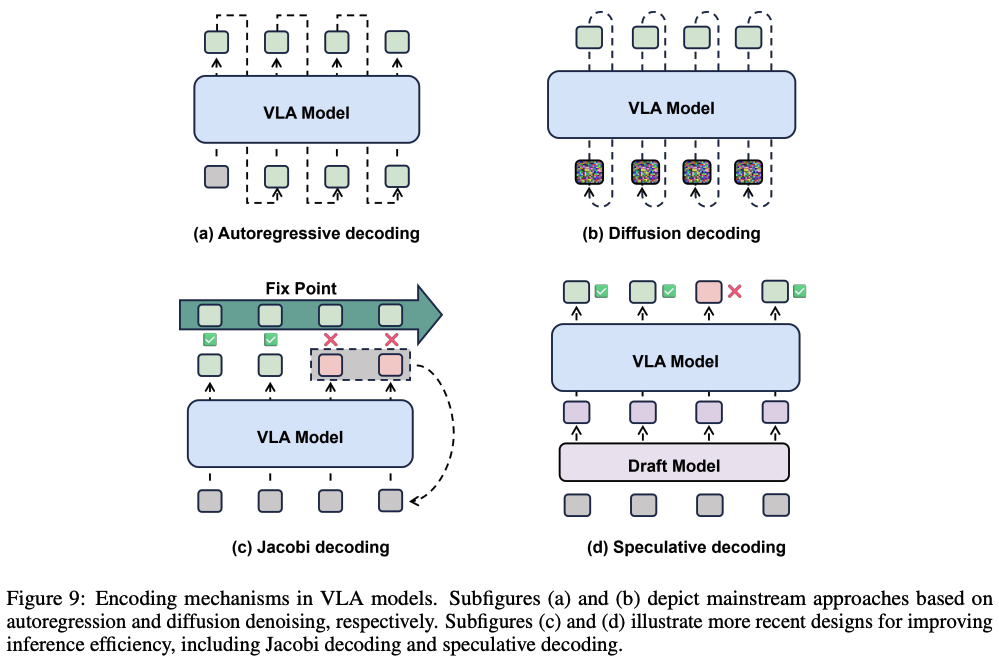
推理端聚焦于突破自回归瓶颈,实现并行化或混合解码。传统的VLA模型通常采用自回归(autoregressive,AR)解码范式,按顺序生成输出token。这种方法实现简单且训练高效,但固有的顺序依赖性引入了主要的计算瓶颈。在对延迟敏感(latency-sensitive)的应用中,例如高频人机交互或实时机器人控制,缺乏并行性严重限制了响应速度。除了AR解码,另一种新兴范式是基于diffusion的解码,它通过多步去噪过程生成输出。然而, diffusion methods也因需要许多迭代去噪步骤而导致推理缓慢,使其不适用于实时使用。为了解决这个限制,最近的工作探索了非自回归(non-autoregressive,NAR)或并行解码范式(如下图9所示)。这些方法旨在通过实现并行计算来减少推理延迟,同时采用特定的训练策略来保持性能。
- openvla-oft:用双向注意力(bidirectional attention)取代因果注意力(causal attention),允许模型在编码过程中利用过去和未来的上下文。这种架构改变使模型能够在一个并行步骤中预测整个动作序列。此外,它将动作表示从离散token序列重新表述为连续回归,并将训练目标从下一个token的交叉熵转移到L1回归损失;
- 投机式解码 (Speculative decoding):
- Spec-VLA框架将这种范式应用于VLA系统,引入了两阶段过程。一个轻量级draft model首先并行生成候选动作序列,然后,完整的主模型一次性验证draft。这种方法将昂贵的步进式生成重构为快速并行草稿生成,然后进行一次性验证。为了平衡速度和准确性,Spec-VLA放宽了验证标准,接受行为有效但与主模型精确输出不同的草稿(drafts);
- 迭代细化 (Iterative refinement):并行解码也可以通过迭代细化实现。
- PD-VLA:从Jacobi迭代中汲取灵感,并行预测所有动作,并通过多次迭代进行细化,直到收敛;但是,训练通常依赖于标准的自回归监督,这不会使模型暴露在并行解码过程中产生的噪声环境中。此外,在复杂场景中可能需要多次迭代才能收敛,从而降低效率增益。
- CEED-VLA:通过一致性蒸馏(consistency distillation)解决了这些挑战。在训练期间,它使用高质量教师模型在Jacobi解码下生成的轨迹作为监督,使学生模型能够学习从不完美状态中自我纠正并可靠地收敛。辅助的自回归损失进一步确保学生模型的输出分布与教师模型保持一致。为了提高效率,CEED-VLA还引入了提前退出机制,一旦更新低于预定义阈值,就停止细化。这使得模型对于更简单的任务只需几次迭代即可完成解码
总结
- 补充说明:
对于Efficient VLA的设计有四个维度:
1. 高效的模型架构设计。
* 压缩网络/模型,但同时带来性能压缩的风险。那进一步的,采用大模型(教师模型)的特征进行知识蒸馏,或许可以改善和提升压缩后的小模型(学生模型)的性能(这部分其实在第四点有体现)。
* 训练时保留模型的全部能力,推理时根据输入复杂度动态选择计算路径。
* 快慢双系统的设计本身就属于解耦模型的推理与反应功能。“慢系统”负责理解和规划,“快系统”负责以较高频率生成动作以及部分动作可能可以复用。
2. 感知特征压缩————保留必要空间与时间信息的同时,显著降低计算负担,实现高效决策
* 通过注意力分数或特征相似度等指标,筛选有效token,或者对token进行压缩等紧凑表示。
* 复用帧间不变或缓变的特征
3. 动作生成的加速
* 一次性输出多步动作块(并做时间平滑),或者对动作序列进行token化或频域变换
4. 训练与推理的优化
* 训练部分包括:参数微调、知识蒸馏、结构化剪枝与量化感知训练。
* 推理部分包括:并行化或混合解码。
VLA成功率与实时性整理
下面表格总结了一些VLA算法的成功率,及其在边端设备的实时性。
| 年份 | 单位 | 模型 | 成功率 | 边端设备实时性 | 说明 |
|---|---|---|---|---|---|
| 2025 | 极佳科技 | SwiftVLA | 真机0.76(π0 0.48);LIBERO成功率为95.1% | NVIDIA Jetson Ori,推理时间0.167s=5.98HZ | 4D transformer(StreamVGGT)实现从2D图像提取4D特征(2D+4D输入),以此来增强VLM(SmolVLM-0.5B)的特征,真机实验比7倍更大的VLA模型(π0)性能相当,在边端设备(NVIDIA Jetson Orin)上快18倍,内存消耗少12倍 |
| 2025 | Dexmal | Realtime-VLA | 捉取落笔任务成功率100% | RTX 4090 GPU上pi0实现30HZ推理及480HZ轨迹生成 | — |
| 2025 | University of British Columbia | NanoVLA | 简单抓取任务 92%~96% 柔性物体90% 未见过物体84% |
Jetson Orin Nano (8GB)上实时性可达41.6FPS | 视觉-语言解耦(后期融合+特征缓存)+长短动作分块+自适应选择骨干网络;首次实现在边缘设备(Jetson Orin Nano)上高效运行VLA |
| 2025 | Sorbonne University | Smolvla | LIBERO-Goal上约为85% | Jetson Orin Nano (8GB)上>25FPS | 该结果为NanoVLA测试的 |
| 2024 | Stanford University | OpenVLA | BridgeData V2平均为70.6% 在Google robot平均为85% 用于新的机器人上平均为63.8% |
6HZ, RTX4090 GPU 1.2~3HZ A5000 GPU |
网页显示对于Jetson AGX Orin 64GB,FPS在1.1~2.9FPS左右,成功率可达85% |
此外,关于在NVIDIA Jetson AGX Orin上运行大型视觉语言模型(VLM)的刷新率,有开发者论坛的帖子提到,对于llava-v1.5-7b模型,刷新率约为0.2 FPS;对于VILA1.5-3b模型,刷新率约为0.8 FPS。VLA模型与VLM在结构和计算量上具有相似性,因此这个数据可以作为VLA抓取算法在Orin上可能达到的推理速度的一个粗略参考。
更多NVIDIA 上AI推理时间可参考:表格
根据Realtime-VLA中提到,实时运行的关键阈值是33ms以内的推理时间:这一指标能确保处理30 FPS的RGB视频流时不丢帧;若超过34ms,连续运行中必然出现帧丢失,若关键事件恰好发生在丢失帧,延迟会额外增加一帧时间(约33ms)。