引言
本博文对于 2025 CVPR的event-based 3DGS工作进行复现,测试效果。 本博文仅供本人学习记录用~
- paper
- code
- 基于3DGS的SLAM工作调研:paper list
- 本博文复现过程采用的代码及代码注释(如有):My github repository
理论解读
IncEventGS是一个基于单目事件相机的增量式3DGS重建算法(无需pose先验)。tracker首先基于重构的3DGS场景表达估算一个初始的相机运动,而mapper联合refine3D场景以及tracker估计的运动轨迹。 而初始化阶段,则是采用一个预训练的深度估算网络来从渲染的图片中估算深度。
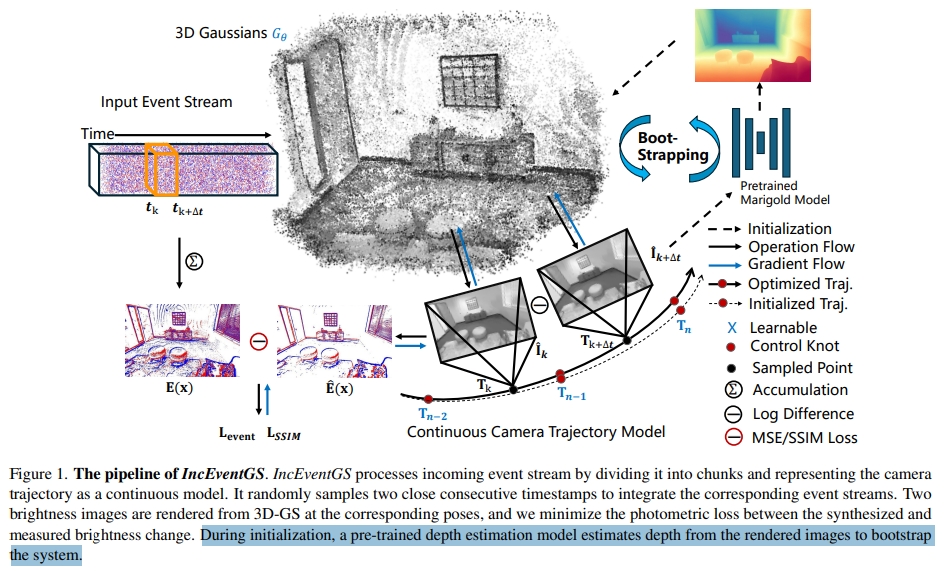
 相机运动轨迹模型
相机运动轨迹模型
|
 增量式tracking与maping联合优化
增量式tracking与maping联合优化
|
对于初始化,一般的3DGS都是采用COLMAP,但是对于事件相机,这并不容易获取。因此,对于限定的bounding box随机初始化一系列3D高斯采样点。 而相机的pose则是初始化为近单位矩阵。 而为了进一步提升性能,采用一个基于diffusion的深度估算网络,来对渲染后的图像进行估算深度。然后用该深度来重新初始化3D高斯点。
论文的实验效果
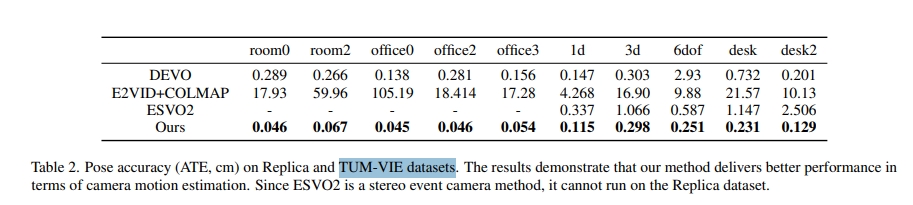
首先是pose的精度,比DEVO还要好一些。不过这里汇报的精度似乎跟DEVO原文的不一样,应该是自己重跑的。但是ESVO2却竟然能跑通(不过结果也跟原文不一样),故此推理应该只是采样了一小段序列而非完整序列来验证吧。
真实数据集下的渲染效果如下:

从恢复的效果可见,虽然不像E-3DGS那样可以渲染彩色视觉,但还是具有丰富的纹理细节的
也有在虚拟数据上跟MONOGS以及SplatTAM对比。不过这里宣称是fast motion似乎就是有所误导了😂

总的来说本文并没有在挑战性场景中验证性能(HDR,fast motion)定位评价序列似乎也不是full sequence
代码复现
配置测试
git clone https://github.com/ERGlab/IncEventGS.git --recursive
# rm -rf .git
conda create -n iegs python=3.10
conda activate iegs
# conda remove --name iegs --all
conda install -c "nvidia/label/cuda-12.2" cuda-toolkit # install CUDA toolkit
# Install the pytorch first (Please check the cuda version)
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
pip install -r requirements.txt
pip install ninja git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
pip install h5py hdf5plugin scikit-learn jaxtyping kornia
pip install -U "huggingface-hub<0.26.0"
pip install pytorch_msssim
pip install tyro
pip install diffusers==0.27.1
pip install accelerate
pip install -U "transformers<=4.48.1"
# pip install gsplat
实验测试
- 注意需要更改yaml中模型的路径以及数据的路径
cd IncEventGS
conda activate iegs
CUDA_VISIBLE_DEVICES=3 python main.py --config configs/TUM_VIE/mocap-1d-trans.yaml
首次运行的时候需要加载gsplat

gsplat应该是一个cuda加速的3dgs库,加载成功后可以看到渲染计算的过程

而结果输出在output/final/tumvie/mocap-1d-trans/demo路径:

大概4500代左右就完成初始化

- 下面可视化初始化过程的变换差异
 iter_0_vis
iter_0_vis
|
 iter_500_vis
iter_500_vis
|
 iter_1000_vis
iter_1000_vis
|
 iter_1500_vis
iter_1500_vis
|
 iter_2000_vis
iter_2000_vis
|
 iter_2500_vis
iter_2500_vis
|
 iter_3000_vis
iter_3000_vis
|
 iter_3500_vis
iter_3500_vis
|
 iter_4000_vis
iter_4000_vis
|
 iter_4500_vis
iter_4500_vis
|
然后通过sfm等初始化开始进行增量式mapping与tracking

跑了大概6个小时还没跑完😂就不跑了,把中间结果show一下吧~
 BA_f020_0000_img
BA_f020_0000_img
|
 BA_f020_2400_img
BA_f020_2400_img
|