引言
本博文对RSS2025的VLN工作进行复现。
- 本博文复现过程采用的代码及代码注释(如有):My github repository
- website
- github
- Paper List for VLN: Link
- Paper List for VLA: Link
理论解读
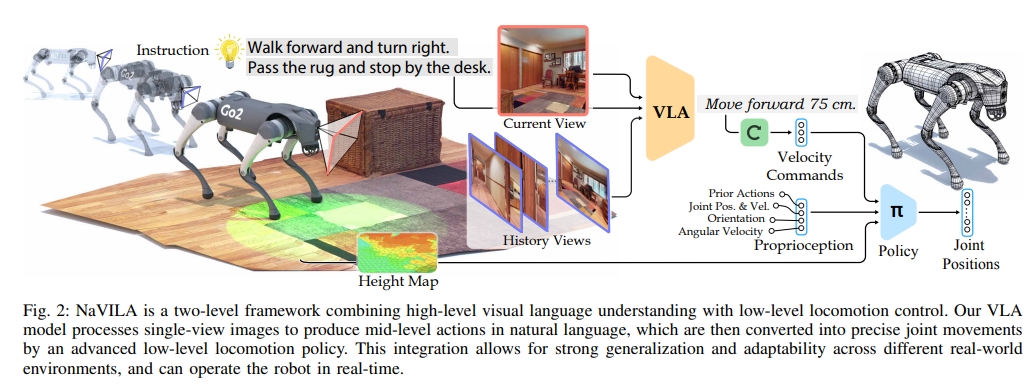
NaVIL采用的是两级框架(也就是类似双系统架构):VLA+locomotion policy。
对于VLA并不是直接生成底层动作,而是以语言的形式生成mid-level的动作(比如“向前移动75cm”),而这个语言形式的action指令会进一步的输入visual locomotion RL policy(基于视觉与强化学习的RL policy)来执行。
本文主要解决腿式机器人(如四足机器狗或类人机器人)的视觉语言导航(Vision-and-Language Navigation, VLN)问题。本文是用VLA的思路来解决VLN问题。
对于VLA,现有做法一般是用large-scale机器人操作数据来微调通用的VLM模型,模型最终输出底层action。
虽然用单个模型中统一推理和执行是fascinating的,并也有不错的结果,但作者还是进一步提出了一个问题:除了量化的底层命令之外,还有更好的方法来表示动作吗?想LLM、VLM都是用自然语言训练的,直击将其推理输出为精确的、非言语的action或许不是最优的。因此作者就提出了mid-level actions with spatial information in the form of language也就是VLA模型输出的还是语言,这个语言定义为mid-level action,用来描述动作(包含了位置和方向信息),而非具体的动作控制commond。
NaVILA的两级系统:
- VLA:将VLM微调为输出mid-level action的VLA。更进一步说,是一个focus on navigation的VLM,但同时可以用通用的视频-语言数据集(比如真实的YouTube视频)进行训练
- low-level visual locomotion policy:该policy被训练跟随mid-level action指令,实现执行。对于locomotion skill的训练,作者先采用LiDAR点云生成高程图(引入一定随机性来减少sim-to-real gap)。而控制器最终也会将VLA输出的语言作为输入,并转换为速度指令,
这样的设计优势有:
- 将底层执行与VLA相解偶,因此相同的VLA模型可以用在不同的机器人(秩序改变low-level policy)
- VLA的输出仅仅是mid-level language instructions,那么就可以在更diversity的数据下进行训练,网络再也不是拟合具体机器人的底层命令,这可以让模型专注于推理;(因此,在这点上,认为其实就是双系统的规划,只是将规划变为所谓的mid-level action或者语言)
- 分级的系统能实现:VLA相对低频运行,而locomotion policy则是可以实时运行,进而保证了机器人避障等实时导航需求(处理连续环境)。
NaVILA结合了视觉-语言-动作模型(VLA)与运动控制(locomotion)的两级系统来实现VLN,以提高腿式机器人的导航能力。使用视觉语言模型(VILA)处理单视图图像,生成自然语言形式的中间动作指令(mid-level action)。
本质上应该算是VLA,只不过进一步到导航层面,故此为VLN。
将VLM训练为VLN
对于VLN是要将视频输入作为观测的,而一般的做法是通过video encoder加入到VLM中。 但是目前VLM基本都是用图-文数据进行训练的,虽然通过video encoder可以从一定程度上解决,但是缺少高质量的视频数据仍然限制了其预训练
PS:虽然说视频可以采样为图片,但是连续的图片跟图片不是一个概念,因为连续的会存在时间维度的信息。也就是说,单纯图-文训练的VLM或许不具备时间维度的映射能力,而对于导航或者三维重建来说,时间、空间两个维度的信息,同样重要。
作者采用image-based vision-language models(VILA),而VILA的预训练已被证明对多图像推理特别有效,使其特别适用于理解顺序图像关系至关重要的VLN任务。
VILA由三个主要组件组成:
- vision encoder:视觉编码器将输入图像转换为视觉标记序列(visual tokens)
- projector:视觉tokens通过下(均匀)采样,然后再通过多层感知机(MLP)投影器映射到language domain。
- 大型语言模型(LLM):而投影后的tokens与text tokens一起被发送到LLM进行自回归生成(auto-regressive generation)。
VILA采用三阶段训练:
- 预训练frozen LLM 以及 vision backbones之间的connector
- 通过text-image交织的语料库来训练connector和LLM
- 最后fine-tune全部模块(vision encoder, connector,LLM)
对于VLA/VILA的训练,作者提出了几个策略:
- 整合VLN中历史的内容与当前的观测到VLM框架中
- 为VLN任务量身定制的专用导航提示(Navigation Prompts)
- 利用来自YouTube中人类 touring(巡演)的真实环境视频来提高agent在连续空间的导航能力。
- 引入了一个数据集来提升VLN的泛化能力
这些策略将通用的基于image的VLM fine-tune为以导航为目标的agent,同时通过在通用的视觉-语言数据集的训练来保证其强大的泛化能力。the first work to show that direct training on human videos improves navigation in continuous environments
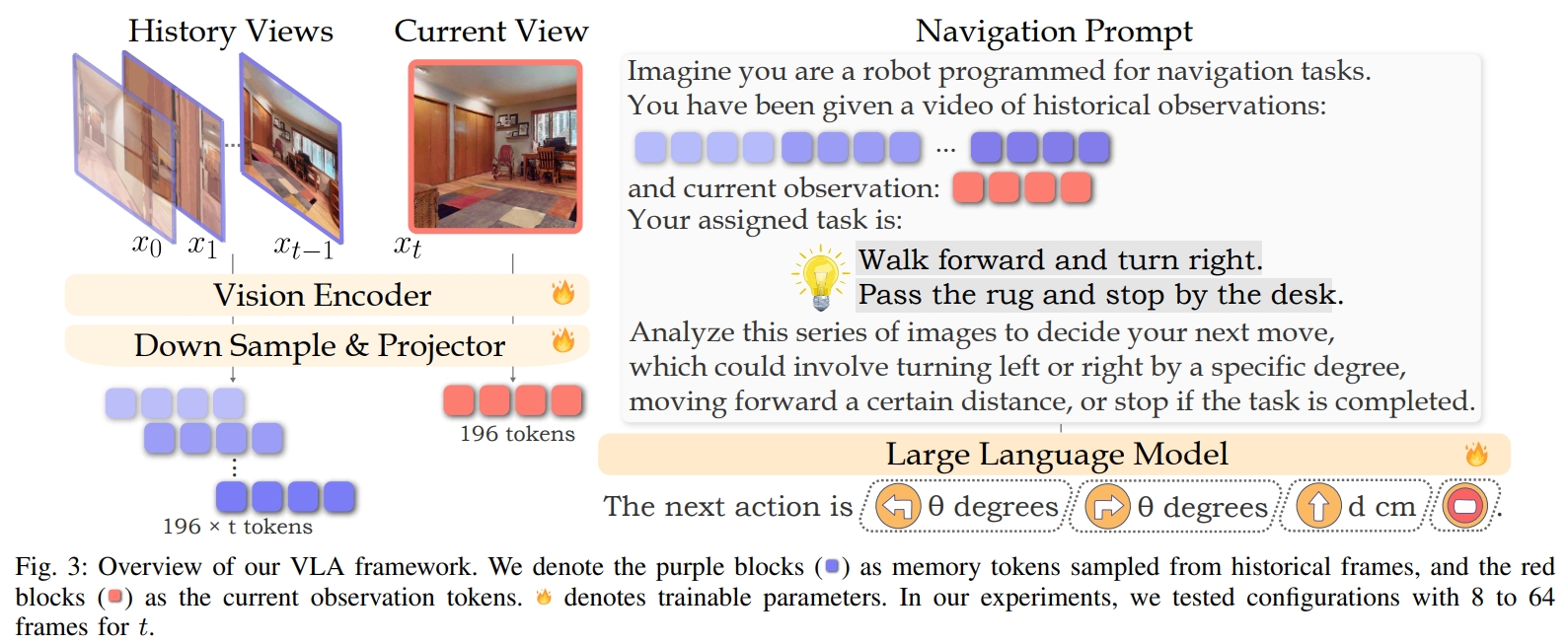
导航提示(Navigation Prompts): 对于VLN任务中,不同时间的图像具有不同的作用。当前时间的图像用于立即决策,而之前的帧作为记忆库帮助智能体追踪整体进度。 而VILA均匀的采样并不能区分两种表达的区别。 为了更好地处理这两种表示,论文使用导航任务提示(Navigation Prompts)方法,通过区分当前观察和历史帧,并使用文本线索(textual cues)来构建导航任务提示。
- 首先,提取最近的t帧作为当前观测。
- 然后从前面的t-1帧中均匀采样(确保第一帧总被涵盖)
- 对于文本线索(textual cues)可以理解为给不同的观测加不同的token(如上面图2所示)
- “a video of historical observations”: for memory frames
- “current observation”: for the latest frame
从人类视频中学习: 对于来自YouTebe的2K个 2K egocentric touring 视频数据(如下图所示)。 首先,基于熵的采样(entropy-based sampling)将其分为20K个代表性的轨迹。 然后,通过MASt3R来从视频中估算出camera pose,这个camera pose进一步提取为step-by-step action,并且采用LLM 重新表述与基于VLM的字幕生成来生成自然语言指令。这样就可以实现利用人类的视频来作为连续导航的数据。

Supervised Fine-tuning Data Blend(监督微调数据混合): NaVILA的灵活框架使得SFT数据可以从以下四个维度设计:
- 真实视频中的可导航数据(如上一节提到的);
- 仿真环境的可导航数据;比如现有的VLN数据集,基于Habitat 仿真器的R2R-CE,RxR-CE等。
- 辅助(Auxiliary)导航数据;这部分就是使用EnvDrop的增强指令,并引入了导航轨迹摘要的辅助任务(auxiliary task)。给定一个轨迹视频(trajectory video),我们通过保留第一帧并统一选择历史帧来对帧进行采样,使用带注释的指令作为标签。然后,LLM的任务是根据这些帧描述机器人的轨迹。
- 通用的VQA数据集(由于VILA输出也是语言文字,因此视频问答数据都可以用于训练),而这个数据集可以提供一个补偿来增强NaVILA的泛化能力。
基于视觉的locomotion policy
对于locomotion的训练,采用single-stage approach来学习基于视觉的运动控制策略。通过原始的LiDAR点云来构建高度图(height map),同时通过引入一些随机性来减少sim-to-real的gap。 控制器通过VLA模型的输出作为输入,将其转换为速度等控制指令,进而控制关节。
- 采用Isaac Sim simulator来端到端训练基于视觉的control policy
- 下图为仿真环境及真实环境下的Go2机械狗。
- 采用PPO算法来进行policy的训练;
- 控制策略的action space是关节的位置,而observation space则包括本体感知、速度指令、以及机器人附近地形的高度(高程图)

论文实验效果
对于实验,作者也采用了不同的机器人平台(如下图所示,包括Unitree Go2, Unitree H1,Booster T1)等进行测试。而project website上更是有大量的样例视频。

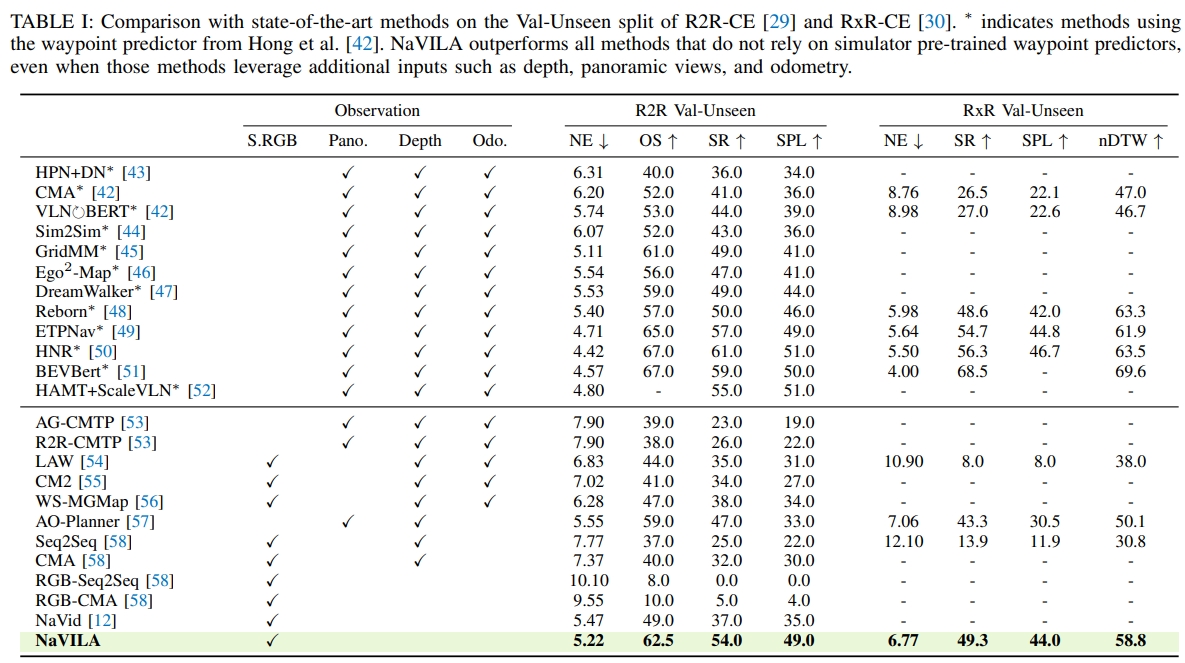
而作者更是通过实验发现,所采用的VLA与运动控制(locomotion)的两级系统来实现VLN比起经典的VLN框架要提升17%的成功率。但从结果来看SR也就是50%左右的级别
实验配置
安装配置
本配置成功在4090以及H200上实现
- 创建conda环境
conda create -n navila-eval python=3.10
conda activate navila-eval
- 构建Habitat-Sim & Lab (v0.1.7)
# 安装Habitat-Sim 0.1.7,但下面只支持python3.6~3.9,用的3.10需要源码安装
# conda install -c aihabitat -c conda-forge habitat-sim=0.1.7 headless
# 安装Habitat-Lab(需重新拉取,不然可能有habitat相关错误)
git clone --branch v0.1.7 git@github.com:facebookresearch/habitat-lab.git
cd habitat-lab
# installs both habitat and habitat_baselines
python -m pip install -r requirements.txt
python -m pip install -r habitat_baselines/rl/requirements.txt
# 注意,其中的tensorflow==1.13.1似乎已经不支持安装了,改为tensorflow>=2.8.0
python -m pip install -r habitat_baselines/rl/ddppo/requirements.txt
python setup.py develop --all
# #验证
# conda activate navila-eval
# CUDA_VISIBLE_DEVICES=1 python examples/example.py --scene /data/scene_datasets/habitat-test-scenes/skokloster-castle.glb
- 对于Habitat-sim的源码安装,参考Link
git clone git@github.com:facebookresearch/habitat-sim.git #(默认就是v0.1.7)
cd habitat-sim
git submodule update --init --recursive
git checkout v0.1.7
git submodule update --init --recursive #注意切换分支后可能导致部分submodule无效
conda activate navila-eval
# 为了解决NumPy的问题,运行下面:
python ../evaluation/scripts/habitat_sim_autofix.py # 更改habitat-sim/habitat_sim/utils/common.py
pip install -r requirements.txt
# 如果出现路径问题编译不成功,可能因为之前编译过了,进入到habitat-sim目录删除build(rm -rf build)
pip install cmake
sudo apt-get update || true
sudo apt-get install -y --no-install-recommends \
libjpeg-dev libglm-dev libgl1-mesa-glx libegl1-mesa-dev mesa-utils xorg-dev freeglut3-dev
# 对于H200可能安装libgl1-mesa-glx会不成功
# sudo apt-get install libgl1-mesa-dev
# sudo apt-get install libegl1-mesa-dev
pip install --upgrade pybind11
# 注意,编译要采用headless模式
# rm -rf build
python setup.py install --headless --cmake-args="-DCMAKE_POLICY_VERSION_MINIMUM=3.5 -DCMAKE_CXX_STANDARD=11"
- 更新版本的common.py
- Habitat-Sim的源码编译参考
- (4090编译时没遇到,但H200编译会遇到)若遇到
error: ‘uint16_t’ in namespace ‘std’ does not name a type; did you mean ‘wint_t’?报错,请在对应的文件添加:
#include <cstdint> // 确保包含uint16_t定义
这个错误是由于 std::uint16_t 类型无法识别导致的。这通常是因为 C++ 标准库头文件包含问题或者编译器配置问题。最直接的方法是在编译时添加 cstdint 头文件:
python setup.py install --headless --cmake-args="-DCMAKE_POLICY_VERSION_MINIMUM=3.5 -DCMAKE_CXX_STANDARD=11 -DCMAKE_CXX_FLAGS=-include\ cstdint"
安装后用命令查看是否都是0.1.7: pip list | grep habitat
- 安装VLN-CE依赖
pip install -r evaluation/requirements.txt
- 安装VILA依赖(注意要回到根目录)
# Install FlashAttention2
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.5.8/flash_attn-2.5.8+cu122torch2.3cxx11abiFALSE-cp310-cp310-linux_x86_64.whl
# 如果尝试多次都不行可以试试增加超时时间
# pip --default-timeout=1000 install https://github.com/Dao-AILab/flash-attention/releases/download/v2.5.8/flash_attn-2.5.8+cu122torch2.3cxx11abiFALSE-cp310-cp310-linux_x86_64.whl --retries 10
# Install VILA (assum in root dir)
pip install -e .
pip install -e ".[train]"
pip install -e ".[eval]"
# Install HF's Transformers
pip install git+https://github.com/huggingface/transformers@v4.37.2
site_pkg_path=$(python -c 'import site; print(site.getsitepackages()[0])')
cp -rv ./llava/train/transformers_replace/* $site_pkg_path/transformers/
cp -rv ./llava/train/deepspeed_replace/* $site_pkg_path/deepspeed/
- 修改VLN-CE的WebDataset版本
pip install webdataset==0.1.103
- Hugging Face下载模型
- 模型地址a8cheng/navila-llama3-8b-8f
- 安装库
conda activate navila-eval
pip install huggingface_hub
- 到网站,获取token
- 运行脚本
python download_huggingface.py,创建python脚本如下所示
from huggingface_hub import snapshot_download
local_dir = snapshot_download(
repo_id="a8cheng/navila-llama3-8b-8f",
local_dir="/home/guanweipeng/NaVILA/navila-llama3-8b-8f",
cache_dir="/home/guanweipeng/NaVILA/navila-llama3-8b-8f/cache",
token="hf_******", # ✅ 在这里传 token
endpoint="https://hf-mirror.com" # 如果需要走镜像
)
print("模型下载到本地路径:", local_dir)
- 若遇到需要科学上网,可在运行py文件前:
# export HF_ENDPOINT=https://hf-mirror.com
export https_proxy=222.29.98.100:20172
python download_huggingface.py
- 数据集下载
conda activate navila-eval
pip install bypy
bypy info
# 将命令行提示的链接复制到浏览器,并复制浏览器中的授权码,粘贴到终端并回车(注意是粘贴到终端)
# 查看网盘文件
bypy list
# 下载文件或目录
bypy download [remotepath] [localpath]
# 上传文件或目录
bypy upload [localpath] [remotepath]
cd evaluation/data/datasets
- 然后下载Matterport3D (MP3D) ,通过网站获取download_mp.py
conda create -n mp3d python=2.7
conda activate mp3d
python download_mp.py --task habitat -o ~/NaVILA/evaluation/data/scene_datasets/mp3d --id 17DRP5sb8fy
# python download_mp.py --task habitat -o DATA_PATCH/mp3d --id ID_NAME
注意,数据格式应该如下:
data/datasets
├─ RxR_VLNCE_v0
| ├─ train
| | ├─ train_guide.json.gz
| | ├─ ...
| ├─ val_unseen
| | ├─ val_unseen_guide.json.gz
| | ├─ ...
| ├─ ...
├─ R2R_VLNCE_v1-3_preprocessed
| ├─ train
| | ├─ train.json.gz
| | ├─ ...
| ├─ val_unseen
| | ├─ val_unseen.json.gz
| | ├─ ...
data/scene_datasets
├─ mp3d
| ├─ 17DRP5sb8fy
| | ├─ 17DRP5sb8fy.glb
| | ├─ ...
| ├─ ...
debug过程
本节记录的是debug的过程,稍微有点乱,可直接跳过~
验证R2R:
cd evaluation
conda activate navila-eval
# bash scripts/eval/r2r.sh CKPT_PATH NUM_CHUNKS CHUNK_START_IDX "GPU_IDS"
bash scripts/eval/r2r.sh /home/guanweipeng/NaVILA/navila-llama3-8b-8f 1 0 "0"
# bash scripts/eval/r2r.sh /home/guanweipeng/NaVILA/navila-llama3-8b-8f 2 0 "1,2"
若报错ImportError: /home/guanweipeng/anaconda3/envs/navila-eval/bin/../lib/libstdc++.so.6: version GLIBCXX_3.4.32 not found (required by /home/guanweipeng/anaconda3/envs/navila-eval/lib/python3.10/site-packages/_magnum.cpython-310-x86_64-linux-gnu.so),先查看环境中的libstdc++.so.6是否包含GLIBCXX_3.4.32
strings /home/guanweipeng/anaconda3/envs/navila-eval/lib/libstdc++.so.6 | grep GLIBCXX_3.4.
#执行安装
conda install -c conda-forge libstdcxx-ng
- 对于无显示器情况,或者GPU不能跑图形的情况
unable to find EGL device for cuDA device 0:
#安装 OpenGL 开发库
sudo apt install libgl1-mesa-dev
#安装 GLFW 库
sudo apt install libglfw3-dev
# 安装 GLEW 库
sudo apt install libglew-dev
#查看安装的pyopengl版本
pip install --upgrade PyOpenGL PyOpenGL_accelerate
#检查EGL版本
ldconfig -p | grep EGL
ldconfig -N -v | grep libEGL
# 最终通过重新安装habitat-sim不为headlee版本似乎可以解决~
python setup.py install --cmake-args="-DCMAKE_POLICY_VERSION_MINIMUM=3.5 -DCMAKE_CXX_STANDARD=11"
- 对于报错跟数据集相关的,比如找不到mp3d或者Navmesh都需要重新确保mp3d数据的下载
# 注意下载数据的方式需要如下,这样下载的数据会额外包含tasks文件夹
python download_mp.py --task habitat -o DATA_PATCH/mp3d --id ID_NAME

对于下面报错:
Platform::WindowlessEglApplication::tryCreateContext(): unable to find EGL device for CUDA device 0
WindowlessContext: Unable to create windowless context
- 换用4090后,报错
cannot get default EGL display: EGL_BAD_PARAMETER
WindowlessContext: Unable to create windowless context
应该是没有对应驱动的原因,接下来安装驱动:
# 添加NVIDIA官方PPA
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
sudo apt install nvidia-driver-550
sudo reboot
- 检查
__GLX_VENDOR_LIBRARY_NAME=nvidia glxinfo | grep -i "opengl"会发现有NVIDIA了:
OpenGL vendor string: NVIDIA Corporation
OpenGL renderer string: NVIDIA GeForce RTX 4090/PCIe/SSE2
OpenGL core profile version string: 4.6.0 NVIDIA 550.144.03
OpenGL core profile shading language version string: 4.60 NVIDIA
OpenGL core profile context flags: (none)
OpenGL core profile profile mask: core profile
OpenGL core profile extensions:
OpenGL version string: 4.6.0 NVIDIA 550.144.03
OpenGL shading language version string: 4.60 NVIDIA
OpenGL context flags: (none)
OpenGL profile mask: (none)
OpenGL extensions:
OpenGL ES profile version string: OpenGL ES 3.2 NVIDIA 550.144.03
OpenGL ES profile shading language version string: OpenGL ES GLSL ES 3.20
OpenGL ES profile extensions:
__GLX_VENDOR_LIBRARY_NAME=nvidia glxinfo | grep "OpenGL renderer"测试OPENGL
OpenGL renderer string: NVIDIA GeForce RTX 4090/PCIe/SSE2
可视化的视频存放在:./eval_out/CKPT_NAME/VLN-CE-v1/val_unseen/videos
而在终端会实时可视化action指令:

实验效果
- 运行下面代码,对应的在
eval_out文件下会生成大量的视频
cd evaluation
conda activate navila-eval
# bash scripts/eval/r2r.sh CKPT_PATH NUM_CHUNKS CHUNK_START_IDX "GPU_IDS"
bash scripts/eval/r2r.sh ~/NaVILA/navila-llama3-8b-8f 1 0 "0"
# bash scripts/eval/r2r.sh /home/guanweipeng/NaVILA/navila-llama3-8b-8f 2 0 "1,2"
# 汇总结果以及查看分数
# python scripts/eval_jsons.py ./eval_out/CKPT_NAME/VLN-CE-v1/val_unseen NUM_CHUNKS
实验结果是通过R2R数据集/MP3D模拟器来验证的,指令信息在视频的左下方。
首先先看下面三组视频对应的SPL分别为0.48,0.91,0.96.可以看到episode=1虽然最终能走到终点,但是一开始走的路径并不对,所以对应SPL值较小。
PS:
基于路径加权的成功率(Success weighted by Path Length,SPL):SPL同时考虑了成功率(SR)和路径长度(PL),并对过长的(即效率低)路径进行惩罚
而下面三个例子则是三次测试都没找到路,因此SPL都为0: