引言
留形科技开源的Odin Navigation Stack 是一个基于ROS1 Noetic的四足机器人(Unitree Go2)自主导航系统。系统集成了高精度SLAM、语义目标检测、神经网络规划器和视觉语言模型,提供完整的室内外导航解决方案。
- 原github
- Website
- 代码注释(如有):My github repository
系统概述
一些关键点的Mark:
- 基于模块式(Modular)及ROS1架构
- 导航框架主要是依赖于ros navigation
- 动态避障with smooth motion(完全开源)
- 语义导航:通过语言或者键盘指令实现物体的检测、定位与导航(e.g., “Go to the left of the chair” 完全开源)
- 采用多模态AI实现对环境的描述
核心模块
- 感知层 (Perception Layer)
- YOLO 物体检测: 实时识别环境中的椅子、人、桌子等语义目标。
- 3D 视觉定位: 结合深度图信息,将检测到的 2D 目标映射到 3D 空间坐标。
- 语义指令解析: 支持自然语言指令(如“走到那个红色的椅子旁边”),通过语义查询节点转化为具体的导航目标。
- 规划层 (Planning Layer)
- A* 全局规划: 在栅格地图上寻找从当前位置到目标的全局最优路径。
- DWA (Dynamic Window Approach): 默认局部避障算法,通过速度采样和轨迹模拟,实现动态避障。
- NeuPAN (神经网络规划): 实验性端到端局部规划方案,具有极高的规划频率(50Hz+)和更平滑的避障表现。
- 局部代价地图 (Local Costmap): 维护一个随机器人滚动的实时障碍物地图,支持“记忆衰减”机制,能有效处理动态障碍。
- 控制层 (Control Layer)
- Unitree 运动控制器: 将速度指令 (
/cmd_vel) 转发给四足机器人底盘,驱动电机执行具体步态。
- Unitree 运动控制器: 将速度指令 (


1. 感知层 Perception Layer
1.1 odin_ros_driver
功能: Odin1传感器驱动程序
输入: Odin1硬件数据
输出:
/odin1/camera_0/image_raw- RGB图像/odin1/camera_0/depth- 深度图/odin1/cloud- 点云数据/odin1/imu- IMU数据/tf(map → odom → odin1_base_link) - 坐标变换
关键特性:
- SLAM定位和建图(内部算法,未开源)
- 实时重定位
- 多传感器同步
1.2 fish2pinhole
功能: 鱼眼相机图像矫正
输入: 鱼眼畸变的RGB和深度图
输出: 针孔相机模型的矫正图像
算法: FishPoly鱼眼投影模型
1.3 yolo_ros
功能: 基于YOLOv5的目标检测与3D定位
主要文件: yolo_detector.py
输入:
- 矫正后的RGB图像
- 深度图
- 相机标定参数
输出:
- 检测到的物体类别和3D位置
- 语音/文本导航指令解析
核心功能:
- 目标检测: YOLOv5模型推理
- 3D定位: 深度图反投影 + 坐标变换
- 语义导航: “移动到椅子左侧”等自然语言指令
- 语音识别: 基于Vosk的中文语音输入
2. 规划层 Planning Layer
2.1 map_planner
功能: 基于栅格地图的全局路径规划
主要文件: map_planner.cpp
算法: A*路径搜索 + 障碍物膨胀
核心流程:
- 接收栅格地图(从pcd2pgm生成)
- 障碍物膨胀处理(安全边界)
- A*算法搜索最优路径
- 发布全局路径
/initial_path
2.2 局部规划器 - DWA (默认使用)
功能: 动态窗口法局部避障
实现方案:
方案A - ROS标准DWA (navigation_planner.launch):
- 使用
move_base+dwa_local_planner/DWAPlannerROS - 配置文件:
dwa_local_planner_params.yaml
方案B - 自定义DWA (model_planner.launch):
- 自实现的DWA规划器:
dwa_planner.cpp - 配置文件:
local_planner.yaml
DWA核心算法:
- 在速度空间采样候选轨迹
- 前向模拟机器人运动
- 评估轨迹代价(障碍物距离、路径偏差、速度)
- 选择最优轨迹执行
2.3 NeuPAN (实验性备选方案)
功能: 端到端神经网络局部规划器
主要文件: neupan_ros.py
论文: NeuPAN (IEEE)
注意: NeuPAN是独立的Python包,不在默认launch文件中启动。若要使用NeuPAN替代DWA,需手动运行
python neupan_ros.py。
特点:
- 高效避障: 50Hz实时规划
- 动态障碍: 适应动态环境
- 平滑轨迹: 神经网络优化的运动轨迹
输入:
- 机器人状态 (x, y, θ)
- 激光扫描点云(障碍物)
- 全局路径(参考轨迹)
输出:
- 速度指令 (vx, vy, ω)
- 优化后的轨迹
核心算法:
- DUNE采样: 神经网络引导的障碍物采样
- NRMP优化: 近似风险最小化路径
- MPC跟踪: 模型预测控制
2.4 model_planner
功能: 可自定义的规划器框架
用途: 用户可以实现自己的规划算法
2.5 navigation_planner
功能: ROS标准导航栈封装
包含: move_base + DWA局部规划器
3. 控制层 Control Layer
3.1 unitree_control
功能: Unitree Go2速度指令转发
主要文件: unitree_vel_controller.cpp
核心任务:
- 接收ROS
/cmd_vel指令 - 转发给Unitree Go2 SDK
- 安全关闭处理(SIGINT信号)
速度映射:
linear.x→ 前后速度 (m/s)linear.y→ 左右速度 (m/s)angular.z→ 旋转角速度 (rad/s)
行走模式:
- AI Walk (FreeWalk): 自主导航推荐
- Classic Walk: 经典四足步态
4. 工具层 Utility Layer
4.1 pcd2pgm
功能: 点云地图转换为栅格地图
输入: .pcd 点云文件
输出: .pgm + .yaml 栅格地图
4.2 pointcloud_saver
功能: 保存SLAM构建的点云地图
4.3 odin_vlm_terminal
功能: 视觉语言模型场景理解
模型: SmolVLM / Qwen2-VL
应用: 场景描述、环境问答
关于人员/物体跟随的梳理
- 感知层:看到物体 (yolo_detector.py)
- 检测: 订阅RGB图像,YOLOv5识别物体(如 Person, Chair)。
- 3D定位: 结合深度图,使用 FishPoly 模型将图像像素坐标 $(u,v)$ 反投影为相机坐标系下的3D坐标 $(x,y,z)$。
- 发布: 将带有3D位置的检测结果发布到 /yolo_detections_3d。
- 决策层:理解与计算 (object_query_node.py
此文件的逻辑需要重点关注)- 接收指令: 通过 interactive_mode 接收用户输入(如 “Move to the right of the person”)。
- 解析 (parse_navigation_command): 提取出动作(Move)、目标(Person)、方位(Right)和索引(第1个)。
【这部分应该是要依赖于自然语言指令解析以及语义导航】 - 查找 (find_object): 在检测结果中找到匹配的物体。
- 坐标计算 (calculate_target_position):
- 获取物体在Map坐标系下的位置(通过TF变换)。
- 根据“右边1米”等指令,计算出机器人应该去的最终目标点坐标。 * 发送目标 (send_navigation_goal): 将计算出的坐标封装为 PoseStamped 消息,发布给导航系统(话题:/move_base_simple/goal)。
- 调度层:状态管理 (goal_state_machine.cpp)
- 监听: 监听 /move_base_simple/goal。
- 触发: 收到新目标后,或者在 arriveCallback 中发现距离目标还有距离。
- 服务调用: 向 map_planner 发起路径规划请求 (plan_client_.call)。
- 规划层:生成路径 (map_planner.cpp)
- 全局规划: A* 算法根据静态栅格地图,计算出一条从当前位置到目标点的无碰撞最优路径。
- 发布: 将路径发布给局部规划器。
- 控制层:避障与运动 (neupan_ros.py & unitree_vel_controller.cpp)
- 局部规划 (NeuPAN): 接收全局路径,结合实时激光雷达/深度图数据,使用神经网络模型进行动态避障,输出速度指令 /cmd_vel。
- 执行 (Unitree): 接收速度指令,调用机器狗底层 SDK 执行运动。
- 关于持续跟随:
yolo_detector.py中的simple_avoidance_control函数,该函数实现了基于视觉伺服的简单避障和目标跟随逻辑,但该实现并不安全
关于局部避障
局部路径规划可以选择DWA(navigation_planner.launch和model_planner.launch)和NeuPAN(whole.launch)两种局部规划器。
关于model_planner中的dwa是自实现的,有以下优势:
- 引入了“障碍物衰减记忆机制” (Obstacle Decay)
- 原版 DWA:标准的 ROS costmap_2d 只有两种状态(通过传感器清除或添加)。如果激光雷达有噪点或者是由于遮挡没能扫到之前的障碍物,地图可能会残留“鬼影”。
- 改进:在 local_costmap.cpp 中引入了 decay_factor_(衰减因子)。每一帧更新前都会让旧代价值乘以 0.95。
- 优势:这让地图具有了“渐进式遗忘”的能力。能够非常优雅地处理动态障碍物(如走开的行人)留下的残影,且即便传感器有轻微噪点,也会迅速被衰减掉,不会让机器人莫名其妙地被困住。
- 航向对齐增强逻辑 (Heading Alignment Boost)
- 原版 DWA:评分函数主要考虑距离路径的远近。当机器人朝向与主路径大幅偏离时,原版 DWA 有时会因为低速采样的评分不高而出现旋转极其缓慢或“原地打转”的现象。
- 改进:在 dwa_planner.cpp 的评分函数中加入了 heading_boost_ 和 heading_align_thresh_。
- 优势:当检测到机器人朝向与目标点夹角过大时,系统会大幅提升“航向得分”的分量。这强迫机器人优先进行原地旋转快速对齐路径。这种“性格”的调整使得机器人在狭窄空间转向或调头时动作更利索。
- 轻量化与高性能设计
- 原版 DWA:其架构为了兼容多层地图(Layered Costmap)和多态足迹(Polygon Footprint),代码量庞大且 TF 转换非常频繁,在嵌入式设备(如机载计算模块)上会有明显的 CPU 占用。
- 本作改进:它抛弃了臃肿的 costmap_2d 依赖,直接在 LocalCostmap 类中手写了 Bresenham 线段清理算法 和 线性代值膨胀。
- 优势:这种“直接操作栅格内存”的方式效率极高。对于四足机器人(如 Unitree Go2)这种需要高频率指令更新的场景,它能保证在较低的算力消耗下维持 20Hz+ 的指令输出稳定性。
- 故障恢复逻辑的无缝集成
- 原版 DWA:规划失败后需要通过 move_base 的状态机跳转到 RotateRecovery
- 本作改进:在 plan 函数末尾直接集成了 enable_rotate_recovery_ 判断。
- 优势:它不是靠状态机跳转,而是直接在“找不到路径”的瞬间,原地计算一个指向路径分支的最优转角速度。这种“瞬时响应”让机器人的动态表现更加连贯,不会有明显的停顿。
关于语义指令解析
系统支持自然语言转化为机器人运动指令,其核心在于 object_query_node.py。
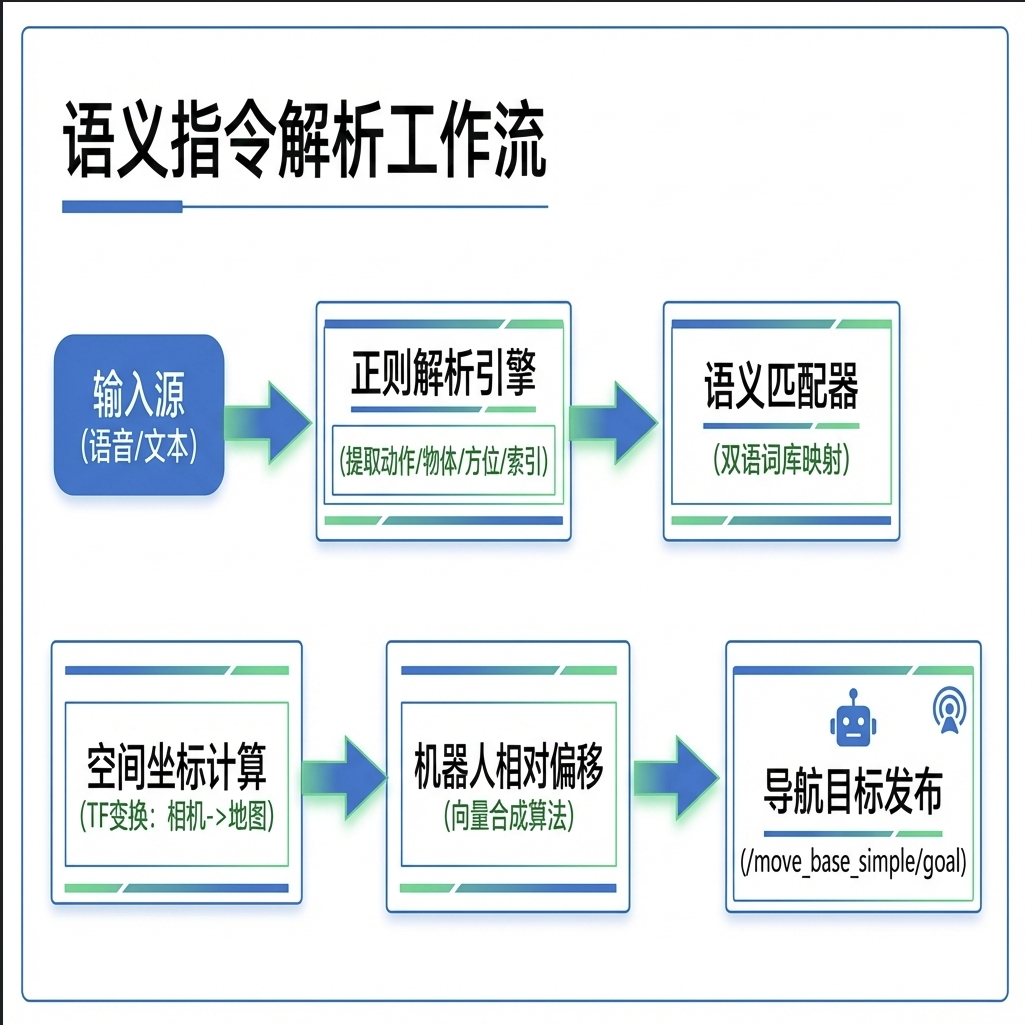
“语义匹配器”采用的是一种基于规则与关键词映射的启发式匹配方法(Rule-based & Keyword-mapping),而非重型的深度学习语义模型(如 BERT 或 Word2Vec)。 这样做主要是为了保证在嵌入式或实时机器人系统上的极低延迟和确定性。具体实现逻辑可以拆解为以下几个层面:
- 结构化正则解析 (Regex Structural Parsing)
它首先使用正则表达式从原始字符串(语音转文字后的文本)中提取出指令的“骨架”。
- 动作提取:识别“走到”、“去”、“move to”等动词。
- 量词与索引提取:捕获“第2个”、“3rd”、“#1”等,用于在多目标环境下定位具体对象。
- 方位提取:捕获“左边”、“behind”等,确定相对于目标的偏移方向。
- 双语关键词映射 (Bilingual Keyword Mapping)
为了解决中英文混杂和同义词问题,代码中内置了一个硬编码的多语种映射字典 (cn_obj_map):
- 它将“人”、“people”、“person”统一映射到内部标准的 YOLO 类别名 person。
- 它包含了一套 COCO 数据集的常见物体同义词表,确保即便 YOLO 的类别名是英文,用户用中文指令也能触发。
- 长词优先匹配算法 (Longest-Match-First)
在一个句子中可能有多个词匹配到已知类别(例如“那台笔记本电脑在桌子上”),匹配器会:
- 将所有已知的类别名按字符长度降序排列。
- 优先匹配较长的词组(如 wine glass 而非 glass),以防止短词产生的语义误触发,提高匹配精度。
- 模糊字符串包含匹配 (Fuzzy Inclusion Match)
在最后锁定目标阶段,它不要求 100% 精确匹配,而是使用了基础的字符串包含逻辑:
- if object_name_lower in class_name_str.lower():
- 这种方法允许用户输入“椅子”也能匹配到探测器输出的“office chair”。
- 坐标系下的“空间语义”合成
这是该节点最聪明的地方:它不仅仅是“匹配文字”,而是通过 TF 变换和旋转矩阵 将文字中的方位词(如“右边”)转化为空间向量。
- 它根据机器人当前的朝向,计算出一个相对于物体的位移向量,从而实现“走到它右边”这种具有空间语义的行为,而不仅仅是简单的目标追踪。
关键流程如下:
- 多模态输入: 支持终端文本输入与基于 Vosk 的离线语音识别(带静音自动端点检测)。
- 正则解析引擎: 使用多重正则表达式捕获诸如“第N个”、“左边/右边”等量词与方位词。
- 坐标变换数学原理:
- 相机 -> 地图: 利用 TF 变换将深度相机探测到的 3D 点云重心投影到全局地图。
- 机器人相对偏移: 算法并不是直接导航到物体中心点(防止碰撞),而是提取机器人当前
base_link的旋转矩阵 $R$,通过向量合成计算出物体侧方的安全着陆点。
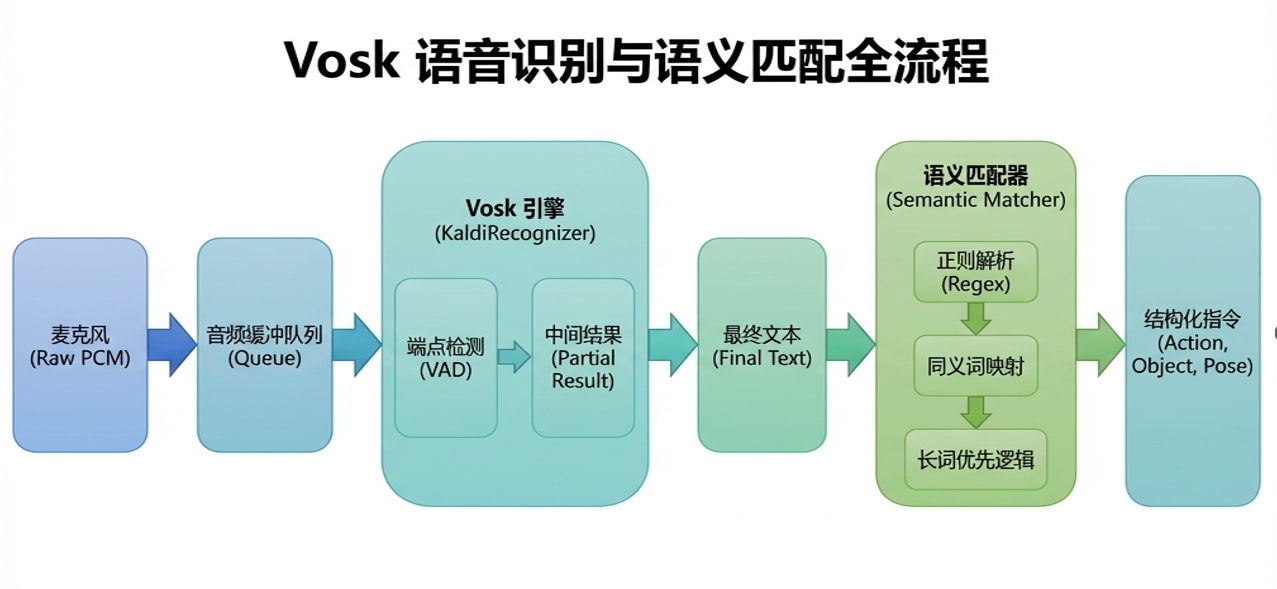
- 关于Vosk:
Vosk 被用作系统的“耳朵”,负责将原始音频流实时转换为机器可理解的文本。它的实现重点在于本地化识别(不联网)和状态机驱动的语音切割。
Vosk 无需联网,隐私性极高且零延迟。
Vosk 的 Python 封装非常精简,适合在嵌入式主板(如 Jetson Orin)上运行。
只需要更换模型文件夹,即可实现中英文无缝切换。