引言
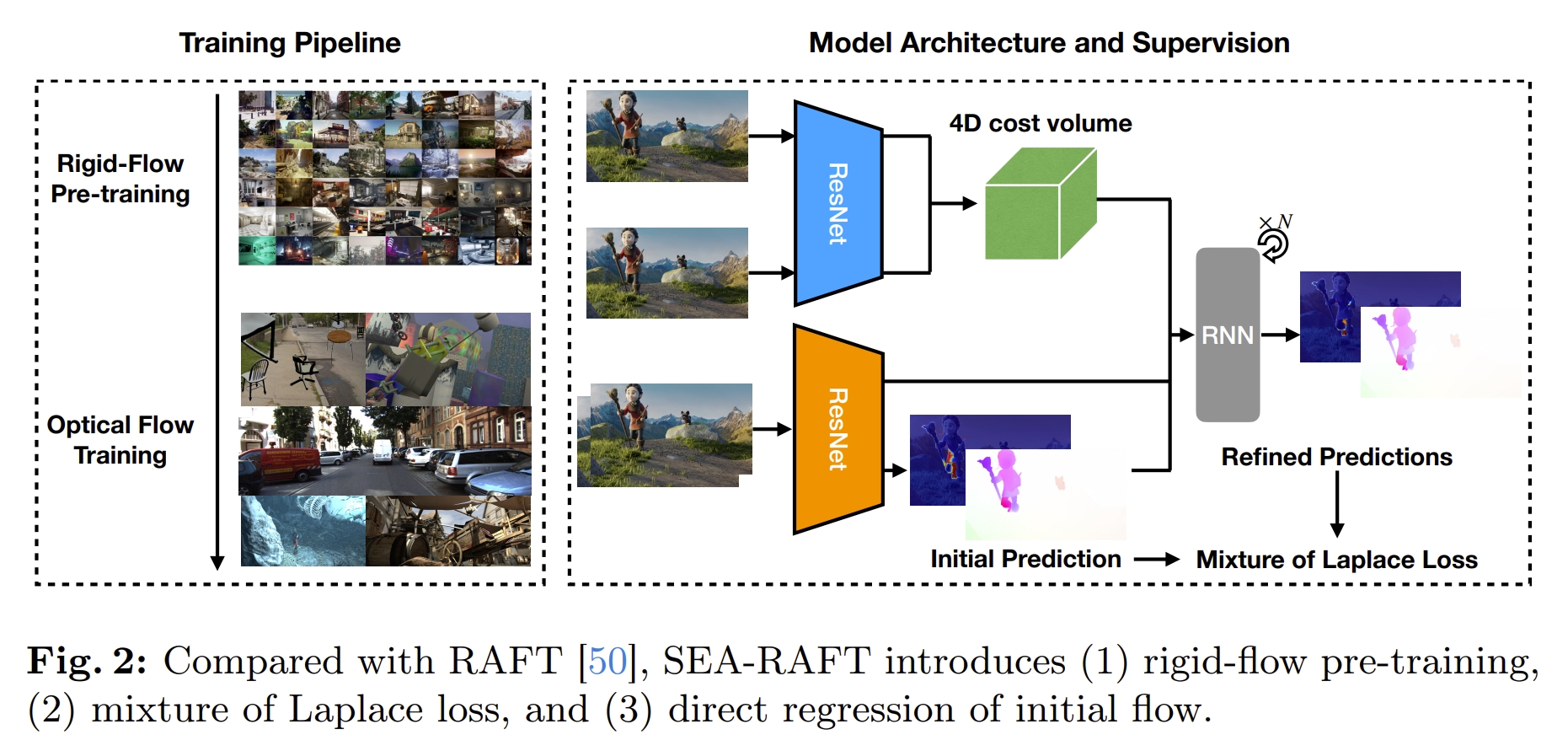
SEA-RAFT是一种比RAFT更简单、有效、准确率高的光流算法。相比起RAFT,SEA-RAFT训练时用了一种新的loss,即拉普拉斯混合(mixture of Laplace),可以让iterative refinements的时候收敛速度更快。 此外,引入刚体运动(rigid-motion)作为预训练来让系统泛化性更好。
本博客仅供本人学习记录用~
@inproceedings{wang2024sea,
title={Sea-raft: Simple, efficient, accurate raft for optical flow},
author={Wang, Yihan and Lipson, Lahav and Deng, Jia},
booktitle={European Conference on Computer Vision},
pages={36--54},
year={2024},
organization={Springer}
}
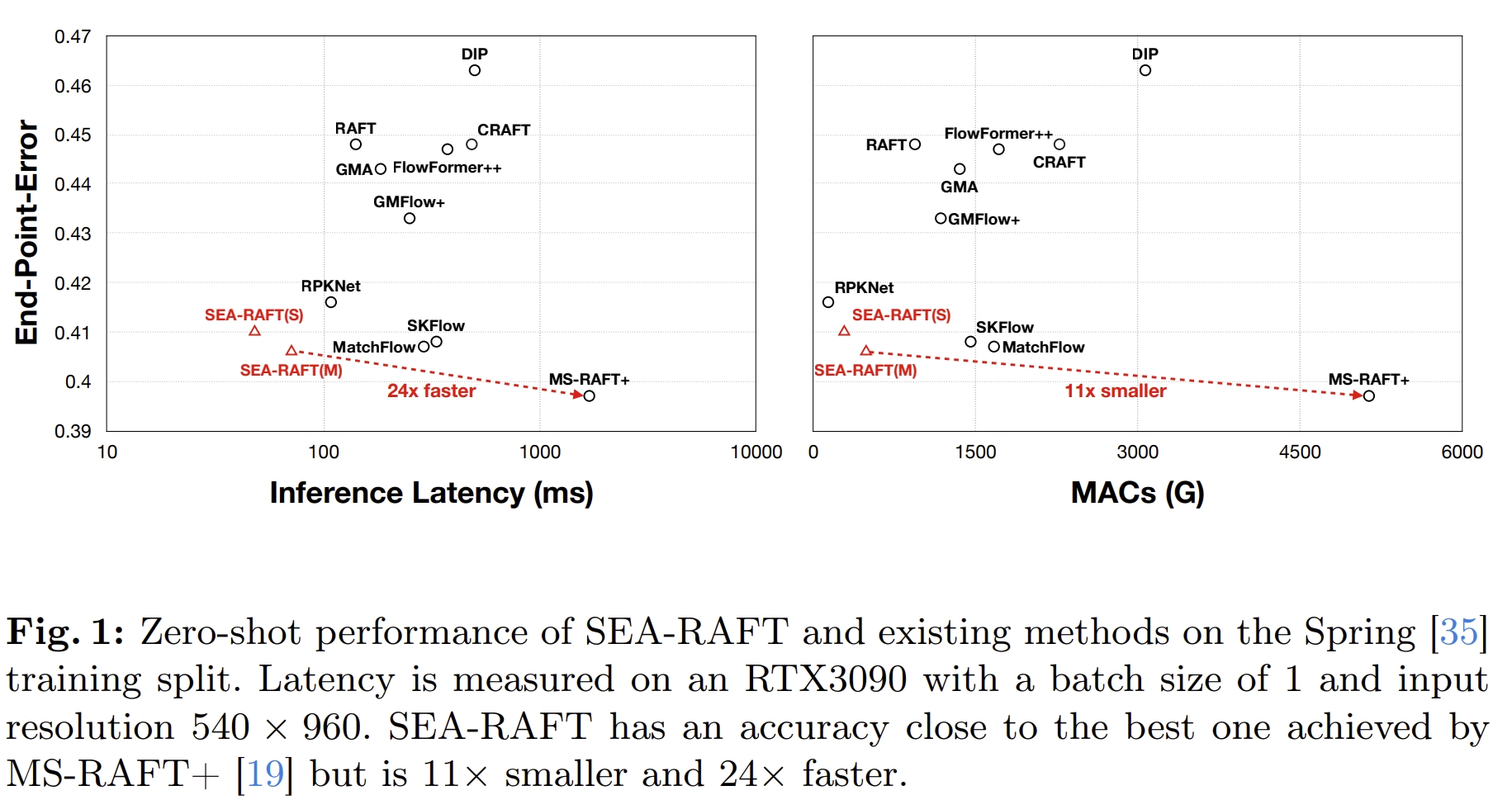
PS:RAFT(ECCV20)也是来自于Princeton Vision & Learning Lab的,是非常经典的工作了,基于该工作,该团队也相继发表了DROID-SLAM(NIPUS21),DPVO(NIPUS24),DPV-SLAM(ECCV24)等系列优秀的工作。而SEA-RAFT则是RAFT的变种,实现更高的效率和准确度。在1080p分辨率下实现21fps的帧率(RTX3090),比RAFT快三倍。
理论学习
SEA-RAFT相比起主要的贡献点如下:
- Mixture of Laplace Loss。不再实用标准的L1 loss,SEA-RAFT通过训练网络来估算mixture of Laplace的参数分布,进而最大化真值光流的似然估计。这个新的loss的引入可以减少过拟合以及提升泛化能力.
- Directly Regressed Initial Flow。原版的RAFT中,在iterative refinement时是把光流初始化为0的,而SEA-RAFT则是通过重用现有的 context encoder并向其提供堆叠的输入帧来预测初始光流,进而实现降低迭代的代数并且提升效率。
- Rigid-Flow Pre-Training。实际上就是在TartanAir上进行pre-training. 此外,原版的RAFT在feature encoder and context encoder分别采用不同的 normalization layers (如下图所示)以实现稳定的训练,而在SEA-RAFT中均采用标准的ResNet(用ImageNet预训练的ResNets)。
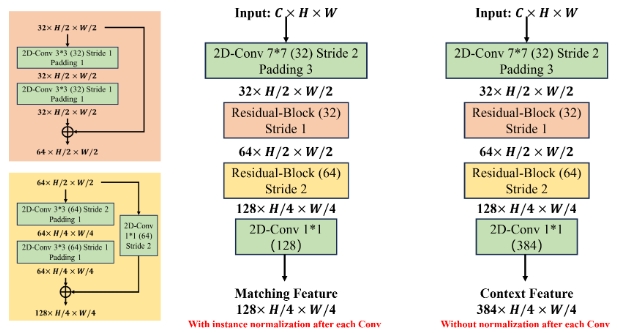
而对于原版的convolutional GRU也代替为RNN,这也使得SEA-RAFT容易通过增加模块来适用于更大的数据集。
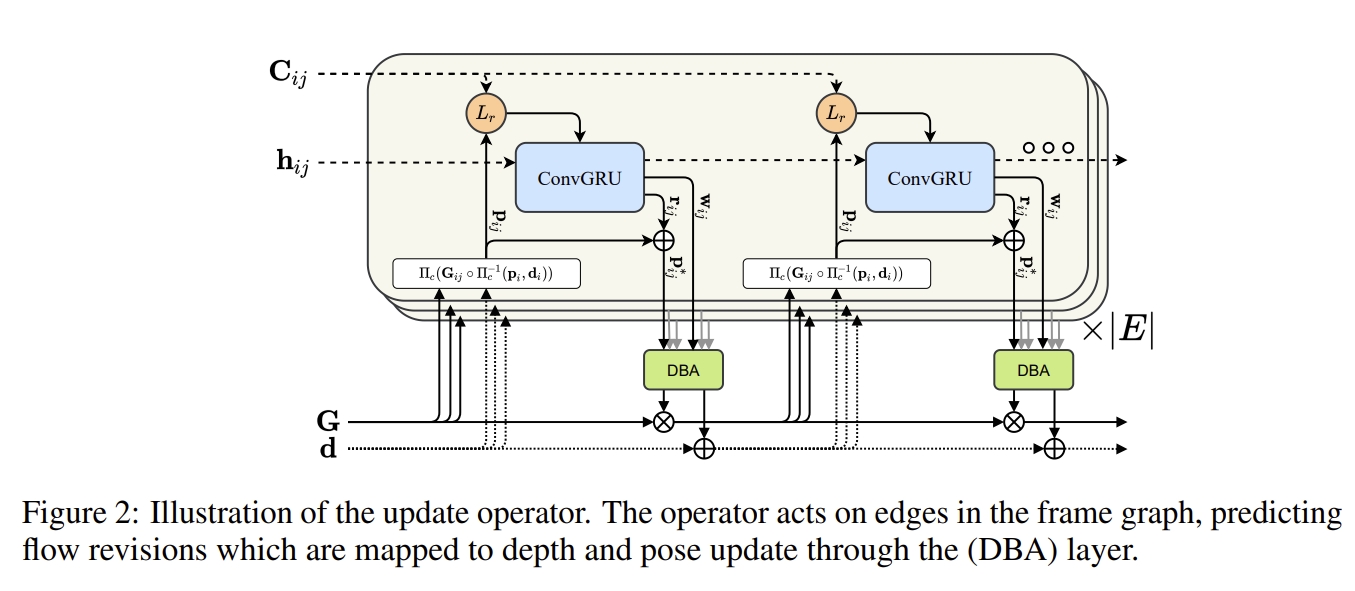
update operator的改进
所谓的GRU应该是DROID-SLAM中的update operator中的convGRU模块
而DPVO中则没有GRU这个概念,对应的update operator替换为下面红色画出的模块,其中的Transition 可以理解为简单的GRU~
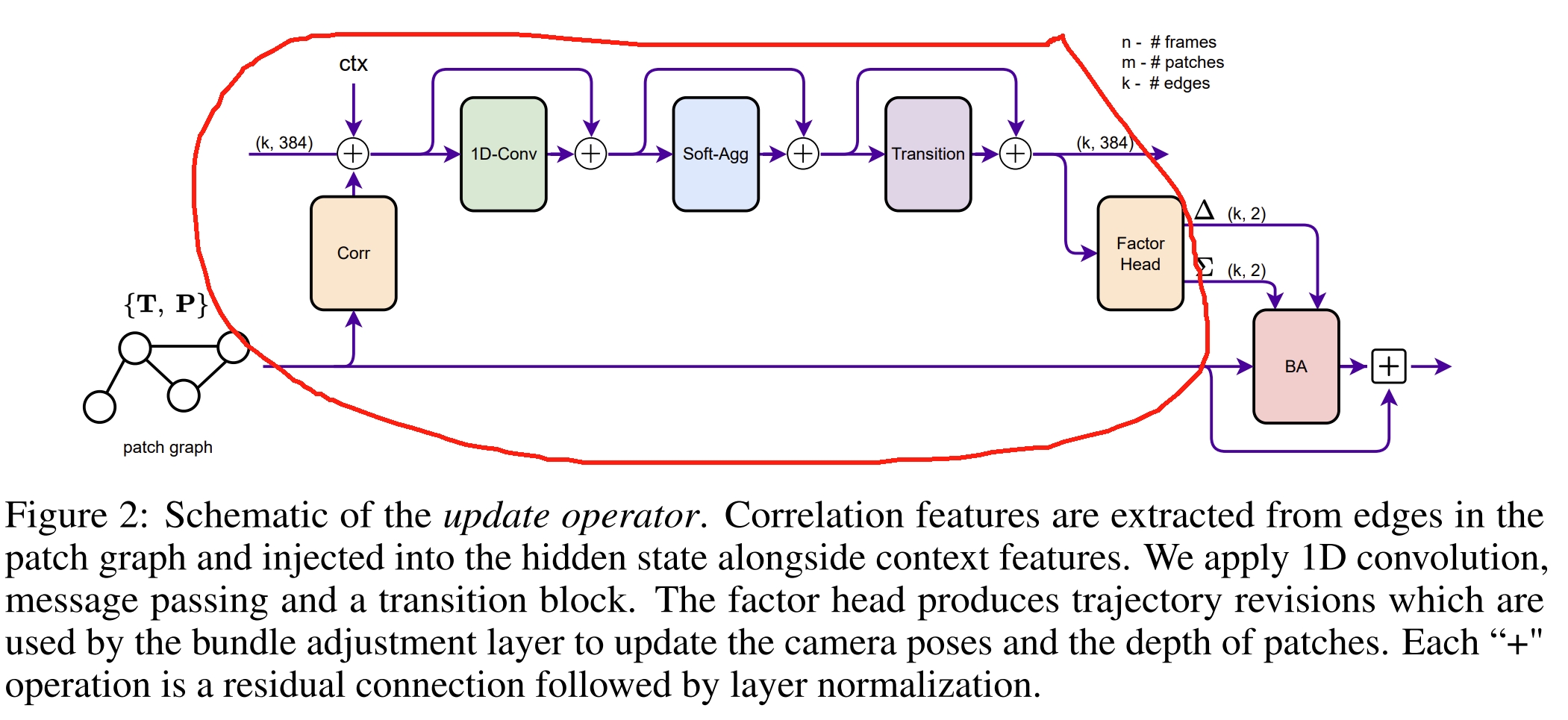
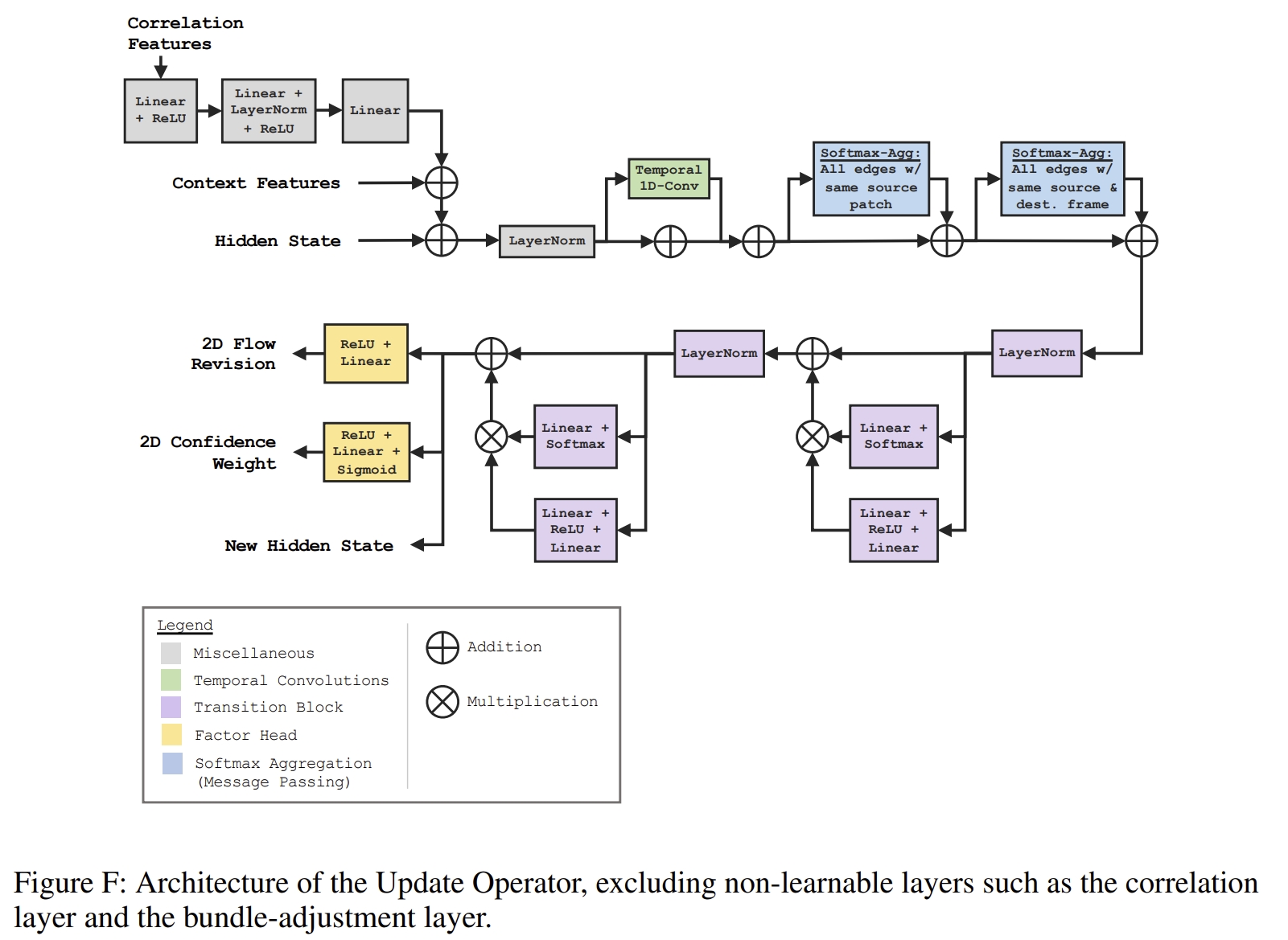
对于RAFT-based的方法,iterative refinement一般是运行12次(训练的时候),推断的时候则是32次.而改进后通过引入RNN结构,则training时只需要4次,而推断时只需要12次。
PS:在DPVO似乎只有初始化的时候iterations是8~12次,其余都是1次,而droid-SLAM则是初始化的时候10次,其余是6~8次左右。看似此改进对于光流有效,但是对于SLAM而言,性能效果可能是有限的。 当然反推回来也就是原本SLAM中减少了更新操作的次数是会对性能有影响的,换了结构后可能还是有提升,当然一切还得以实验为说服~
Mixture-of-Laplace Loss
对于用所有pixel的endpoint-error loss会引起歧义。如下图所示。


Laplace Loss在光流中表现并不好,因此改为如下

Direct Regression of Initial Flow
由网络预估一个光流的初值(通过 context encoder)比初始化设置为0需要的迭代代数更少。
其他
SEA-RAFT的结构如下图所示
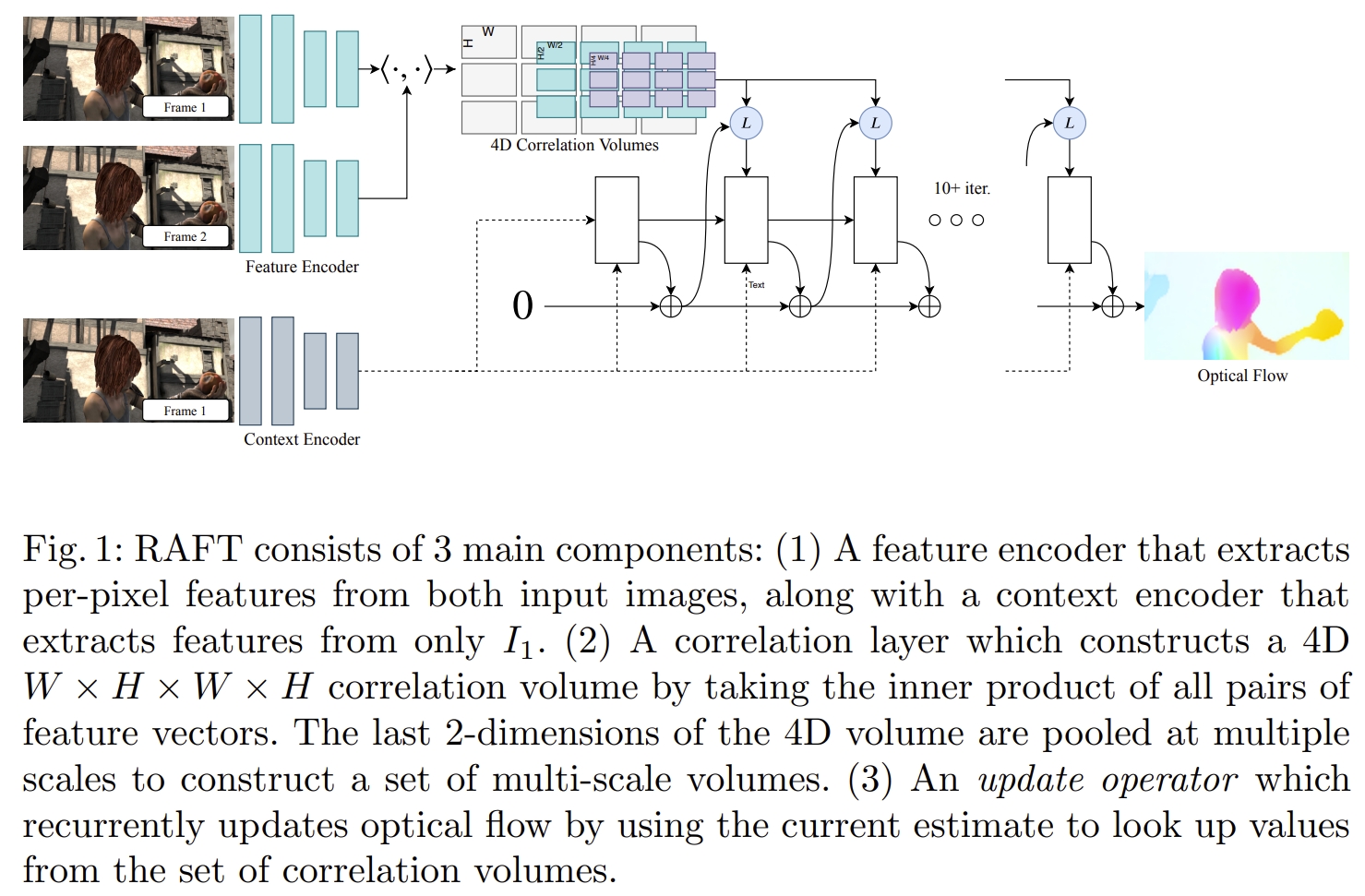
RAFT的结构如下图所示
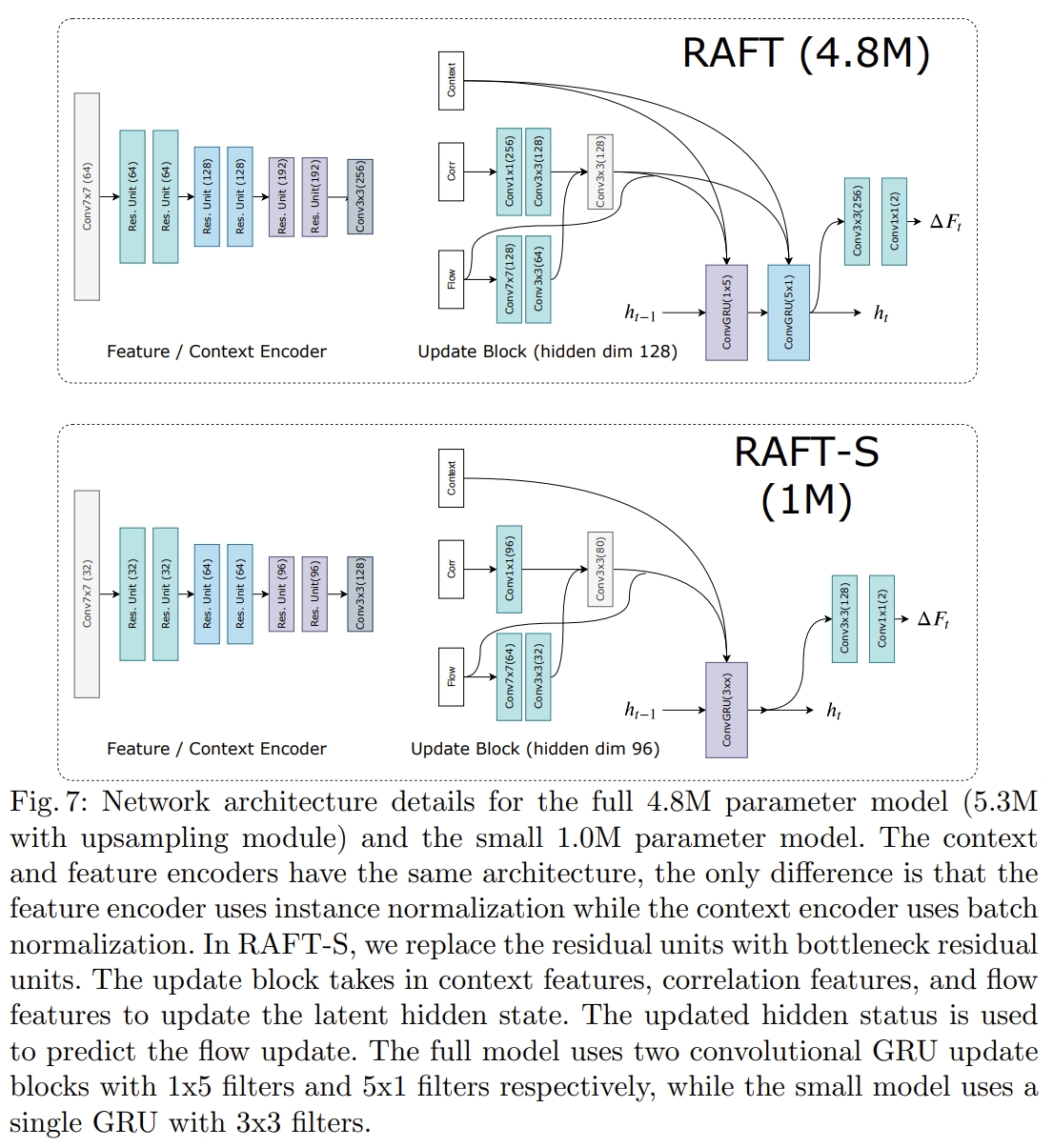
论文效果、代码复现及解读
实验中,有SEA-RAFT(S/M/L)三种结构:
- SEA-RAFT(S) uses the first 6 layers of ResNet-18 as the feature/context encoder (keep the number of iterations N = 4 in both training and inference);
- SEA-RAFT(M) uses the first 13 layers of ResNet-34 (keep the number of iterations N = 4 in both training and inference);
- SEA-RAFT(L) can be regarded as an extension based on SEA-RAFT(M): they share the same weights, but SEA-RAFT(L) uses N = 12 iterations in inference;
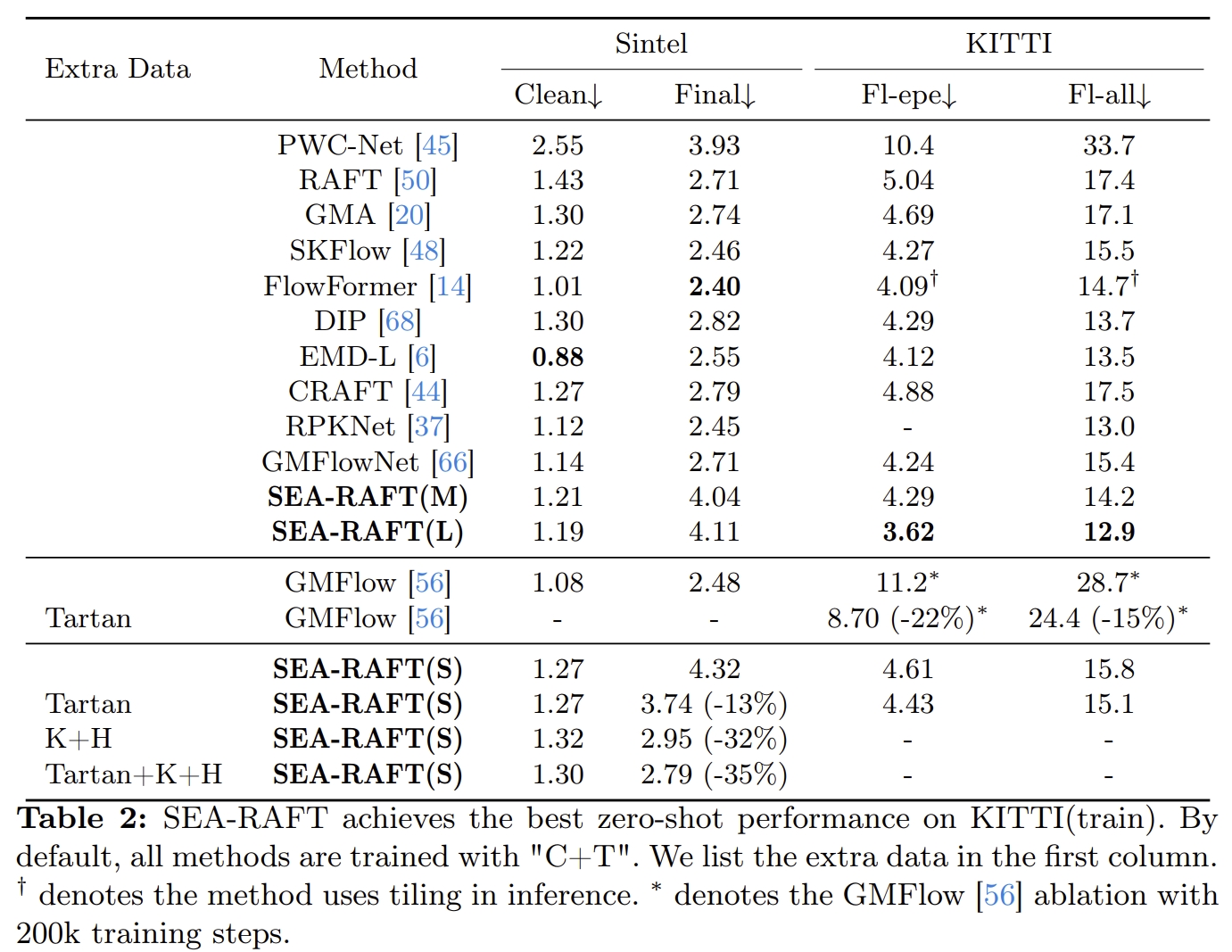
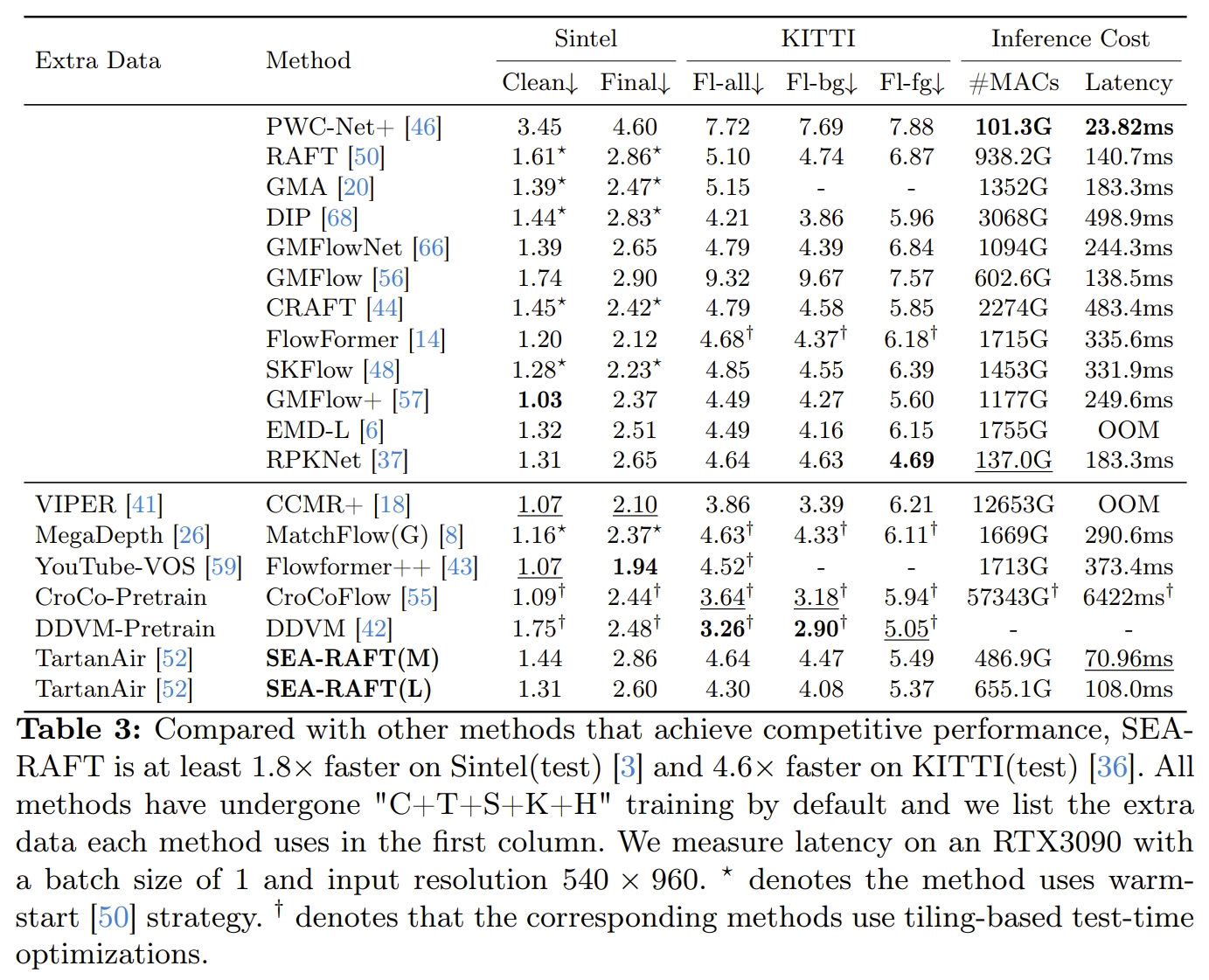
下图通过消融实验来分析各个模块对系统性能带来的提升~
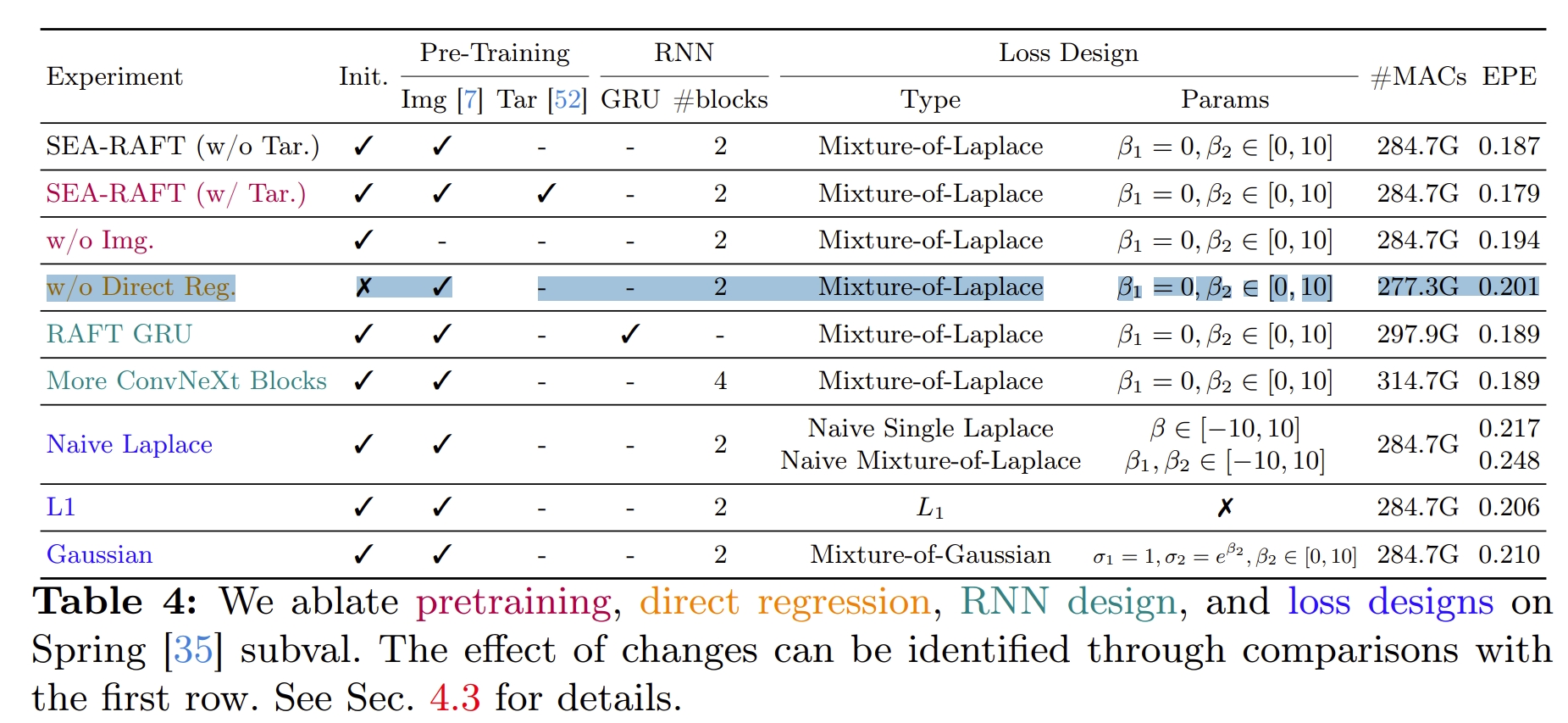
代码复现

|

|

|

|