
引言
在 《NVIDIA Jetson Thor》 完成 Thor 的基础安装与配置后,本文记录在该平台上使用 vLLM 部署 Qwen3.5-122B-A10B 模型的完整过程。该模型总参数量 122B,每次推理激活约 10B 参数,是 Qwen3.5 系列中体量最大的 MoE 多模态模型之一。部署过程中也顺带测试了 Qwen3.5 其他参数量版本以及 Gemma-4 系列模型,因此资源占用部分会一并列出,供参考对比。
Qwen 3.5有以下几个亮点:
- 统一视觉语言基础(Unified Vision-Language Foundation) Qwen3.5 采用早期融合训练(Early Fusion),将视觉 token 和文本 token 统一训练,不再是”文字模型 + 外挂视觉模块”的拼接方案。在推理、编程、Agent 任务和视觉理解等基准测试上,整体性能对齐甚至超越上一代专门的视觉模型 Qwen3-VL。
- 高效混合架构(Gated Delta Network + MoE) Qwen3.5 引入 Gated Delta Networks 与稀疏 Mixture-of-Experts(MoE) 的组合架构。以 35B-A3B 为例,总参数量 350 亿,每次推理仅激活约 30 亿参数,实现了高吞吐、低延迟、低成本的三重平衡——这正是”用中等规模做出旗舰效果”的核心秘密。
- 百万 Agent 规模的强化学习 训练过程中,RL 框架在数百万个 Agent 环境中并行运行,通过递进式任务分布持续提升模型的真实世界泛化能力,使模型在复杂多步 Agent 任务中的鲁棒性大幅提升。
- 201 种语言覆盖 Qwen3.5 将多语言支持扩展至 201 种语言与方言,包含对中文、粤语等多种方言的细粒度理解能力。
关于 Qwen3.5-122B-A10B
架构
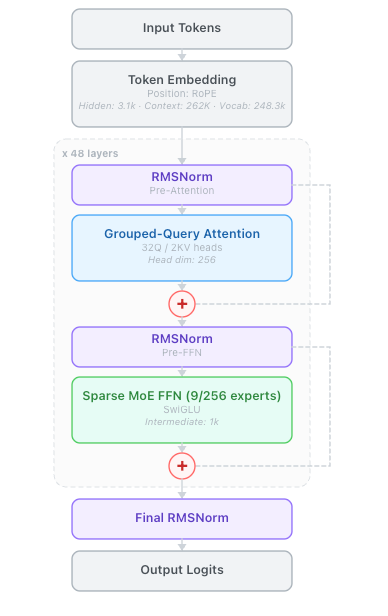
根据 Hugging Face 官方模型卡,Qwen3.5-122B-A10B 的核心架构如下:
- 模型类型:带视觉编码器的因果语言模型(Causal Language Model with Vision Encoder)
- 训练阶段:预训练 + 后训练(Pre-training & Post-training)
- 语言模型
- 总参数量 / 激活参数量:122B / 10B(稀疏 MoE 架构)
- 隐藏层维度:3072
- 词表大小:248,320(Padded)
- 层数:48
- 隐藏层布局:
12 × (3 × (Gated DeltaNet → MoE) → 1 × (Gated Attention → MoE)) - Gated DeltaNet
- 线性注意力头数:V 为 64,QK 为 16
- 头维度:128
- Gated Attention
- 注意力头数:Q 为 32,KV 为 2
- 头维度:256
- RoPE 维度:64
- Mixture of Experts(MoE)
- 专家总数:256
- 每次激活专家数:8 个路由专家 + 1 个共享专家
- 专家中间层维度:1024
- 输出层:248,320(Padded)
- MTP:支持多步预测(Multi-Token Prediction)
- 上下文长度:原生支持 262,144 tokens,可扩展至 1,010,000 tokens
本文实际部署使用的是 FP4 量化版本(Sehyo--Qwen3.5-122B-A10B-NVFP4),与官方 FP8 版本在架构上一致,量化精度不同。
官方并没有完整的Qwen3.5 架构图,分别从网站、Qwen3.7-Max、DeepSeek专家模式问到的架构如下:
 deepseek
deepseek
|
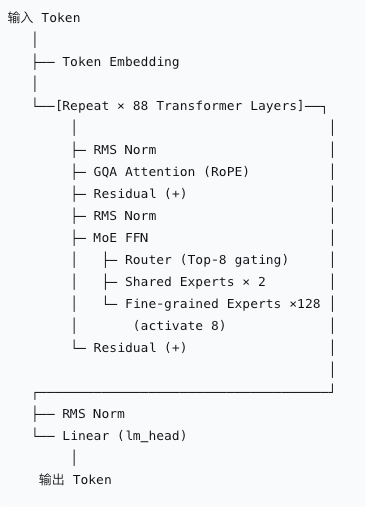 deepseek
deepseek
|
 Qwen3.7
Qwen3.7
|
官方宣称特性
Qwen 团队在 Qwen3.5 Highlights 中,对 Qwen3.5 系列(含 122B-A10B)宣称了以下核心特性:
- 统一视觉-语言基座(Unified Vision-Language Foundation):通过多模态 token 的早期融合训练,在推理、编程、Agent 和视觉理解等基准上达到与 Qwen3 同代水平,并超越 Qwen3-VL 系列。
- 高效混合架构(Efficient Hybrid Architecture):Gated Delta Networks 与稀疏 MoE 相结合,在保持低延迟的同时实现高吞吐推理,成本开销较小。
- 可扩展强化学习泛化(Scalable RL Generalization):在百万级 Agent 环境中扩展强化学习,通过逐步复杂的任务分布训练,提升真实场景适应能力。
- 全球语言覆盖(Global Linguistic Coverage):支持 201 种语言与方言,面向全球化部署,具备更细粒度的文化与地域理解能力。
- 下一代训练基础设施(Next-Generation Training Infrastructure):多模态训练效率接近纯文本训练(近 100%),并配备异步 RL 框架,支持大规模 Agent 脚手架与环境编排。
此外,官方 FP8 版本采用 block size 为 128 的细粒度 FP8 量化,宣称性能指标与原始模型几乎一致。模型默认处于思考模式(Thinking Mode),会在最终回复前先生成思考内容;也支持通过 API 参数关闭思考,直接输出回复。官方推荐使用 vLLM、SGLang 等推理框架部署,原生上下文长度为 262K,复杂长文本任务可借助 YaRN 等技术扩展至约 1M tokens。
部署过程
- 下载大模型
pip install modelscope
modelscope download --model Qwen/Qwen3-VL-8B-Instruct --local_dir ./dir
- 创建环境
conda create -n uv python=3.12
conda activate uv
- 安装 torch、torchvision、torchaudio
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu130
- 安装部分依赖
pip install xgrammar triton flashinfer-python --prerelease=allow
- 下载 vLLM 源代码
git clone --recursive https://github.com/vllm-project/vllm.git
cd vllm
- 编译 vLLM 前的环境安装、配置
python3 use_existing_torch.py
pip install -r requirements/build.txt
- 安装 vLLM
pip install --no-build-isolation -e .

- 查看 Jetson AGX Thor 架构
nvidia-smi --query-gpu=name,compute_cap --format=csv

- 配置架构
export TORCH_CUDA_ARCH_LIST=11.0a
export TRITON_PTXAS_PATH=/usr/local/cuda/bin/ptxas
- 下载用于 tokenizer 的文件并配置环境变量
mkdir tiktoken_encodings
wget -O tiktoken_encodings/o200k_base.tiktoken "https://openaipublic.blob.core.windows.net/encodings/o200k_base.tiktoken"
wget -O tiktoken_encodings/cl100k_base.tiktoken "https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken"
export TIKTOKEN_ENCODINGS_BASE=${PWD}/tiktoken_encodings
- 启动 vLLM
以 Qwen3.5-9B 为例:
vllm serve \
/home/sunjing/projects/VLM/models/Qwen3.5-9B \
--async-scheduling \
--port 8000 \
--host 0.0.0.0 \
--trust-remote-code \
--swap-space 16 \
--max-model-len 32768 \
--tensor-parallel-size 1 \
--max-num-seqs 256 \
--gpu-memory-utilization 0.7 \
--enable-prefix-caching \
--allowed-local-media-path /home
- 可能出现的问题
ptxas-blackwell fatal: Value ‘sm_110a’ is not defined for option ‘gpu-name’
export TRITON_PTXAS_BLACKWELL_PATH=/usr/local/cuda/bin/ptxas
ValueError: Free memory on device cuda:0 (18.7/122.82 GiB) on startup is less than desired GPU memory utilization (0.2, 24.56 GiB).
降低 gpu-memory-utilization 的数值即可。
AssertionError: Error in memory profiling.
export VLLM_SKIP_MEMORY_PROFILER=1
- 测试可用
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/home/sunjing/projects/VLM/models/Qwen3-VL-8B-Instruct",
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": "描述图片中都有什么"},
{"type": "image_url", "image_url": {"url": "https://inews.gtimg.com/om_bt/OuP9OfpazXjI8MOLob6kDLosfdDJbm1thq-J4wOhEGyxkAA/1000"}}
]
}
],
"max_tokens": 100
}'

启动新服务
每次运行需要重新配置的环境变量(可以选择写死在 bashrc 里):
export TORCH_CUDA_ARCH_LIST=11.0a
export TRITON_PTXAS_PATH=/usr/local/cuda/bin/ptxas
export TIKTOKEN_ENCODINGS_BASE=${PWD}/tiktoken_encodings
export TRITON_PTXAS_BLACKWELL_PATH=/usr/local/cuda/bin/ptxas
- 显存释放
运行后退出,显存无法正常释放时,可执行:
sudo sh -c "echo 3 > /proc/sys/vm/drop_caches"
- 启动 122B 大模型
启动 122B 等较大参数量的模型,在启动过程中容易被 kill。理论上,122B-FP4 的模型只需要占据 61GB + KV cache,但是在启动的时候需要更多(可能是权重文件分割太大)。
vllm serve ./Sehyo--Qwen3.5-122B-A10B-NVFP4 \
--quantization compressed-tensors \
--reasoning-parser qwen3 \
--language-model-only \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.65 \
--max-model-len 2048 \
--max-num-seqs 1 \
--enforce-eager \
--mm-processor-cache-gb 0 \
--trust-remote-code
资源占用及速度
本节除 122B-A10B 外,还记录了 Qwen3.5 其他参数量版本及 Gemma-4 系列模型的测试数据,便于横向对比。
-
Token 计算说明
- 输入 Token 数:由图片输入 + 提示词(prompt)输入组成。
- Qwen3.5 图片输入:1 个 token 对应输入分辨率 32×32 的图片,例如分辨率为 1280×720 的图片输入约占 1280×720/32/32 = 900 tokens。
- Gemma-4 图片输入:1 个 token 对应输入分辨率 60×60 的图片,例如分辨率为 1280×720 的图片输入约占 1280×720/60/60 = 256 tokens。
- 1 个字约等于 0.5~1 token(反过来,1 Token 约等于 1~1.8 汉字)。
- 生成回复/输出 token:每个颜色块代表 1 个 token,以下截图约为 100 tokens。

- 对比:
| 参数量 | 精度 | 显存占用 | 输入处理速度(首次) | 输入处理速度(后续) | 首 token 耗时(首次) | 首 token 耗时(后续) | 生成速度 | 100 tokens 总耗时 |
|---|---|---|---|---|---|---|---|---|
| Qwen3.5 122B-A10B | FP4 | 86G | 233 tokens/s | 765 tokens/s | 3s | 1.2s | 12 tokens/s | 8.3s |
| Qwen3.5 122B-A10B | INT4 | 86G | 245 tokens/s | 838 tokens/s | 3.9s | 1.1s | 26 tokens/s | 3.7s |
| Qwen3.5 9B | FP16 | 24G | 56.67 tokens/s | 1726.80 tokens/s | 16s | 0.55s | 10 tokens/s | 10.64s |
| Qwen3.5 4B | FP16 | 13G | 57.74 tokens/s | 2775 tokens/s | 16.6s | 0.34s | 15 tokens/s | 6.8s |
| Qwen3.5 2B | FP16 | 10G | 58.19 tokens/s | 3369.59 tokens/s | 16.5s | 0.28s | 42.12 tokens/s | 2.55s |
| Qwen3.5 0.8B | FP16 | 7G | 58.49 tokens/s | 3500.61 tokens/s | 16.4s | 0.27s | 85 tokens/s | 1.39s |
| Gemma-4-E2B | FP16 | 10.083G | — | 3108.33 tokens/s | — | 0.226s | 16.22 tokens/s | 6.325s |
| Gemma-4-E4B | FP16 | 15.427G | — | 3032.52 tokens/s | — | 0.273s | 10.58 tokens/s | 9.452s |
| Qwen3 30B-A3B | FP4 | 30G | 1079 tokens/s | 3536 tokens/s | 0.8 s | 0.2 s | 52 tokens/s | 1.9 s |
| Qwen3.6 35B-A3B | FP8 | 50G | 366 tokens/s | 1094 tokens/s | 2.6s | 0.87 s | 41 tokens/s | 2.4 s |
| Qwen3.6 27B | FP16 | 60G | 257 tokens/s | 1524 tokens/s | 3.7 s | 0.6 s | 4 tokens/s | 23 s |
| Qwen3.6 27B | FP8 | 43 G | 618 tokens/s | 2169 tokens/s | 1.5 s | 0.4 s | 8 tokens/s | 12 s |
| Qwen3.6 27B | FP4 | 36 G | 598 tokens/s | 2356 tokens/s | 1.6 s | 0.4 s | 9 tokens/s | — |
- 测试条件:大部分采用多模态推理(图片 + 文字 prompt),1280×720 图片输入 + 约 100 token 的 prompt,约 100 tokens 的回复。
- 对于 Qwen3.5 122B-A10B,采用的是纯文字推理,为了能启动起来,关闭了很多优化选项,会对速度造成影响。
参考资料
- Thor 安装与配置博客:《NVIDIA Jetson Thor》
- Huggingface Qwen : Huggingface Qwen3.5-122B-A10B-FP8
- Qwen3.5:迈向原生多模态智能体
致谢
- 本博客特别致谢 @haijing1995 提供的技术支持。