之前博客对VLN进行调研。但VLN领域工作实在太多了,NLP、CV、Robotics领域的学者们纷纷加入,只能介绍小量代表性工作。 本博文针对VLN领域带有机器人实操的几篇工作进行调研,跟之前博客为了了解整个领域不同的是:本博文希望调研业内(学术界)VLN落地的方案及做法。
- Paper List for VLN
- Blog for VLN
- 论文阅读笔记之——《Vision-and-language navigation today and tomorrow: A survey in the era of foundation models》
- Paper Survey——CLIP on VLN
1. Zero-shot Object-Centric Instruction Following: Integrating Foundation Models with Traditional Navigation
本文是波士顿动力24年arvix的工作,关注Instruction Following,通过LLM大模型与传统的SLAM导航相结合的方式让具身导航智能体学会指令跟随。
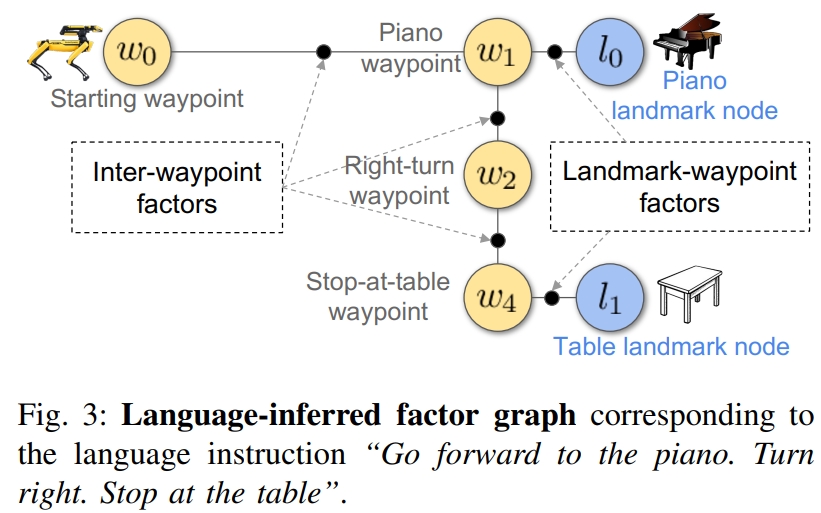
2. SLAM-Free Visual Navigation with Hierarchical Vision-Language Perception and Coarse-to-Fine Semantic Topological Planning
上一篇是VLN跟SLAM结合的,这篇则是要去除SLAM,两篇的观点正好相关hh
理论部分
本文提出了一个纯视觉,切不依赖于SLAM的导航框架。通过轻量的拓扑地图(topological representations)来代替稠密几何的语义推理。
通过分层视觉语言感知模块将场景级上下文(scene-level context)与对象级线索(object-level cues)融合在一起,以实现鲁棒的语义推理。
这部分是通过VLM来实现场景以及物体级别的语义推理的,进而构建semantic-probabilistic topological map。
接下来,基于大语言模型(LLM)的全局推理实现子目标的选择,而基于视觉的局部规划实现障碍物躲避。
最后再通过强化学习来实现腿式机器人的运动控制。
之所以要强调SLAM-free是因为机器人不仅需要定位自身,还需要理解环境哪里是值得下一步去探索的、哪个目标是跟任务相关的,还有就是在不确定的情况下,如何去规划。用传统的架构难以handle,其实这也是用VLN代替传统定位导航pipeline主要的motivation。
下面是framework的架构:
场景的推理采用了Qwen,物体的检测采用Grounding DINO;两者的结果进行融合以及构建semantic-probabilistic topological map;
而推理获得的这些信息只是给一个粗略的环境理解,生成导航的目标决策,而具体执行还需局部的障碍物规划。
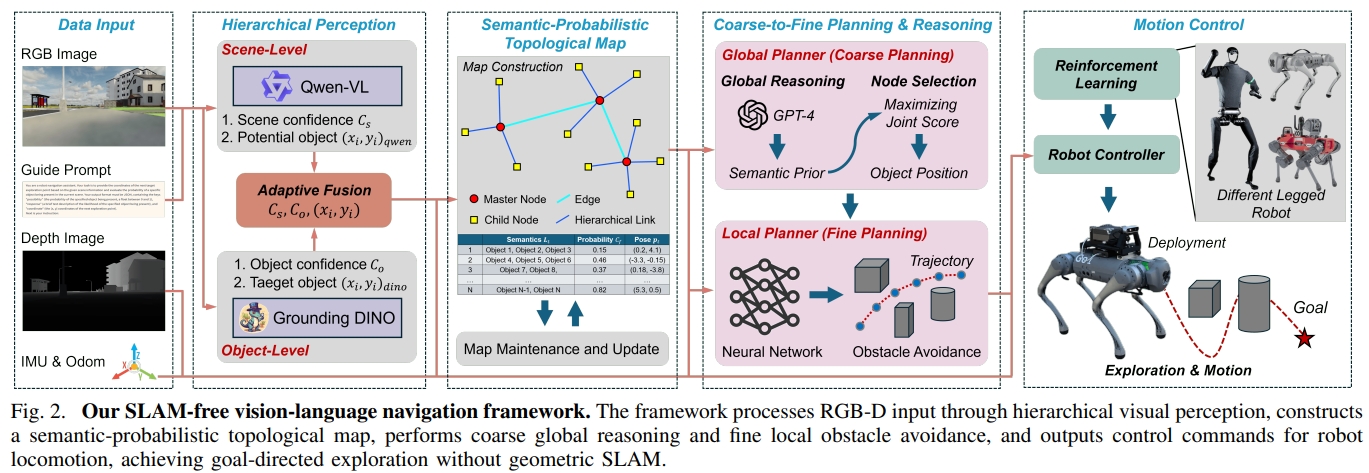
对于规划的过程又分为两个互补的level:
- coarse global reasoning layer:从语言拓扑图中选择最佳的探索子目标;这分布采用GPT-4来做规划
- fine local planning layer:动态生成可以安全到达子目标的轨迹;这部分作者采用了Viplanner(一个端到端的视觉局部规划器,通过深度相机的输入以及子目标的2D投影,输出线速度与角速度的指令)
最后再基于速度指令到机器人规划和控制策略,这部分采用的就是RL运动控制了。
实验部分
- 仿真是采用一张NVIDIA RTX4090 GPU来做的。
- 真机实验中,工作站负责Grounding DINO以及其他大模型的API回调;Jetson AGX Orin实现规划与控制。两个系统通过无线网络及ROS来交换信息;
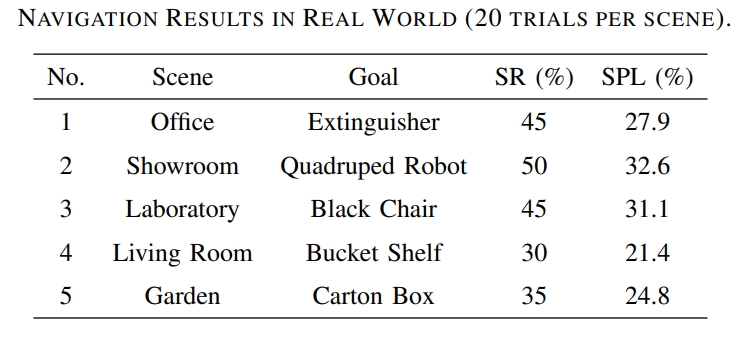
实机环境中采用Unitree Go1+RealSense D435i,验证了五个场景

|

|
从下表可以看到,在20此实验中,成功率基本都是50%以下。
3. JanusVLN: Decoupling Semantics and Spatiality with Dual Implicit Memory for Vision-Language Navigation
文字描述很难准确反映物体的空间关系及方位。 同时,导航是一个3D物理空间的交互,而现有的VLA模型中的视觉编码器大多数都是继承自2D图像-文本对上预先训练的CLIP范式,这使得这些视觉编码器虽然可以较好的提取高层语义,但是难以理解3D几何结构以及空间信息。 而人类对于2D静态图像的观测,一般是会恢复深度以及理解空间布局。但现有的VLN方法都忽视了这一点。
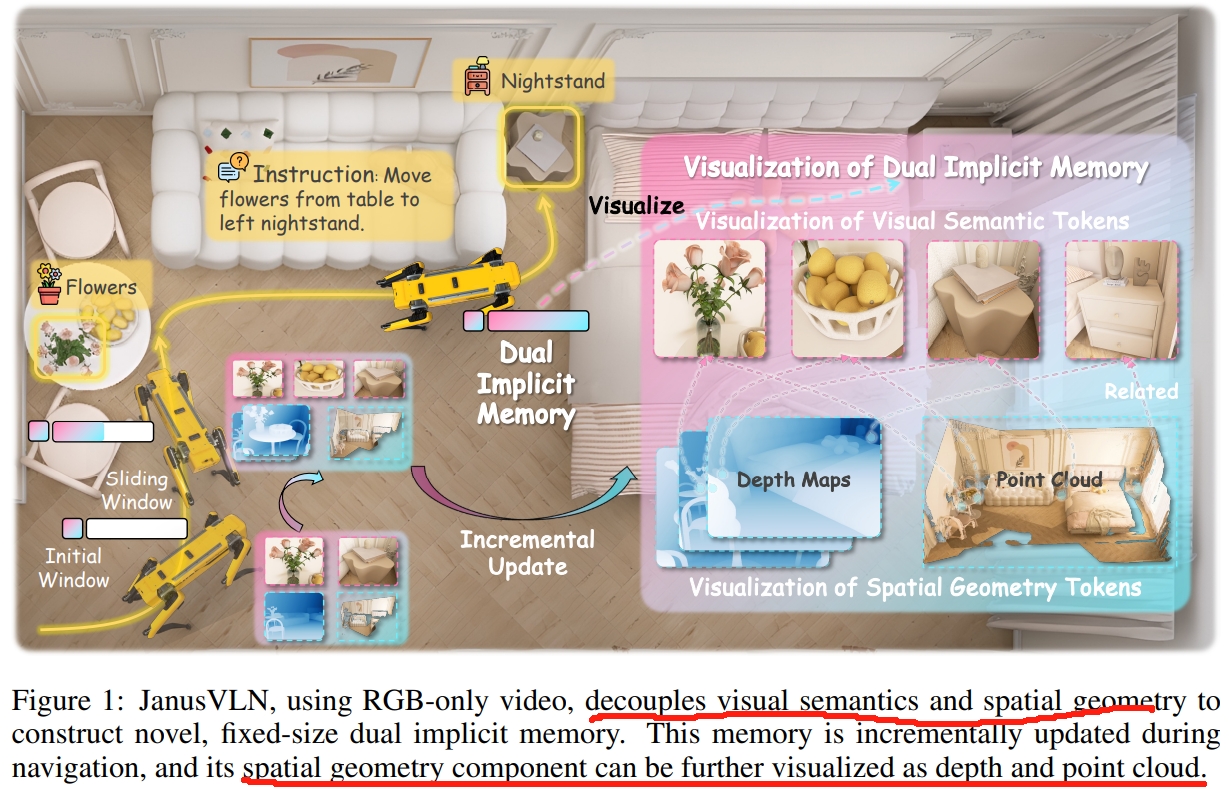
本文受到人类导航时隐式的场景表达的启发(“左脑的语义理解和右脑的空间认知”)。 作者提出了一个新的VLN框架:双隐式神经网络记忆(dual implicit neural memory),将空间几何和视觉语义记忆建模为独立、紧凑和固定大小的特征表达。
理论部分
主要的贡献点:
- 通过一个3D视觉基础模型(feed-forward 3D visual geometry foundation model)来扩展MLLM(Multimodal Large Language Models),实现从空间几何编码器中获取3D先验知识(用3D数据预训练),进而增强模型的空间理解能力(spatial reasoning capabilities,仅依赖于RGB输入)。
- 而双隐式记忆(空间几何与视觉语义记忆)的历史键值对(caching historical key-value,KV)则是通过3D空间几何编码器(3D spatial geometry encoder)和MLLM的语义视觉编码器(semantic visual encoder)来分别提取。
- 这个双隐式记忆( dual implicit memory)通过初始窗口以及滑动窗口进行动态及增量式更新。能够逐步整合每个新帧的历史信息,而无需重新计算过去的帧(memory不会跟随着轨迹而增长)
为了保证模型对3D空间的理解能力,MLLM的visual encoders是通过pixel-3D point cloud pairs来训练,而非2D image-text data。因此嵌入了3D感知的先验。
对于3D空间几何编码器采用的的是VGGT(Paper,用VGGT的预训练编码器和融合解码器)来编码场景的先验,实现从多视角图像中直接预测3D结构。
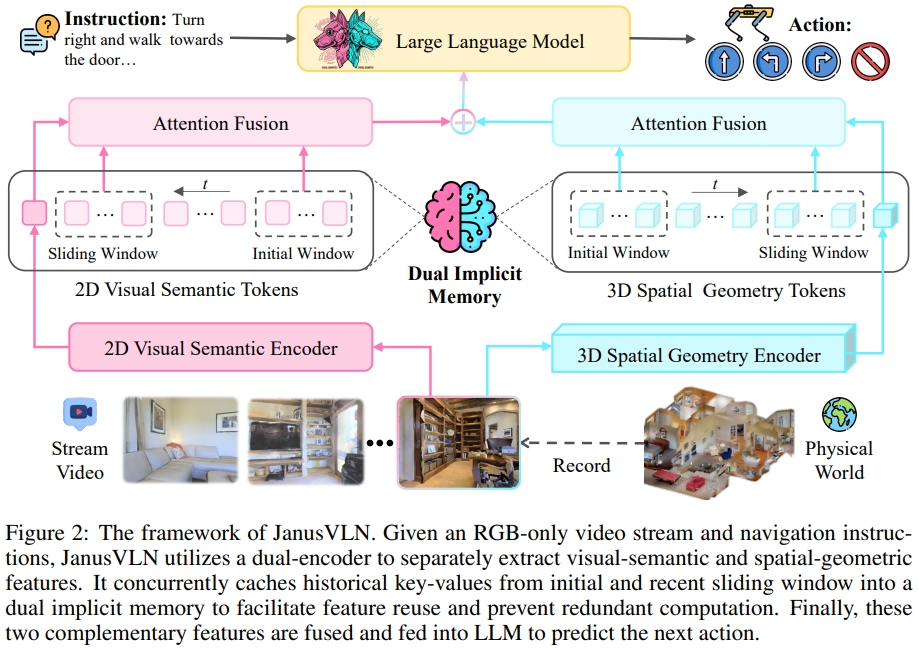
对于缓存历史的键值对(由attention模块输出的),构成高层语义的抽象以及过去环境的结构表达。这也就是所谓的Implicit neural representation.
而对于这个双隐式记忆,作者采用了两种混合的更新方式(Hybrid incremental update)而并非缓存所有的历史键值对。
更新的策略分为两部分:
- 一个滑动窗口队列,,存储了n帧并遵循着first-in, first-out的方式。
- 永久保留开始的几帧。模型对这些初始帧表现出持续的高attention权重。这些权重为整个导航提供关键的全局锚点(anchors)。
对于每一个新加入的帧,都计算其image token以及隐式memory的 cross-attention来直接检索历史信息,从而避免了对过去帧的冗余的特征提取。
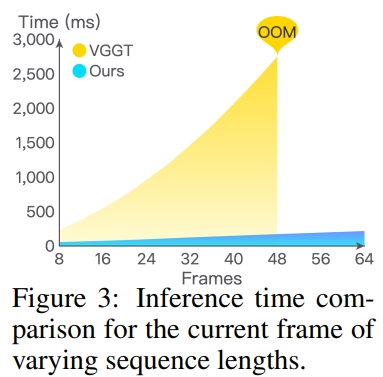
如下图所示。VGGT的推理时间随着帧数呈指数式上升,而本文提出的更新方式可以避免重新处理历史帧,进而实现推理时间仅略有增加,从而显示出卓越的效率。
对于2D语义编码器采用的是Qwen2.5-VL的原始的视觉编码器,3D空间几何编码器采用的的是VGGT预训练编码器和融合解码器。 执行了fine-tune
实验部分
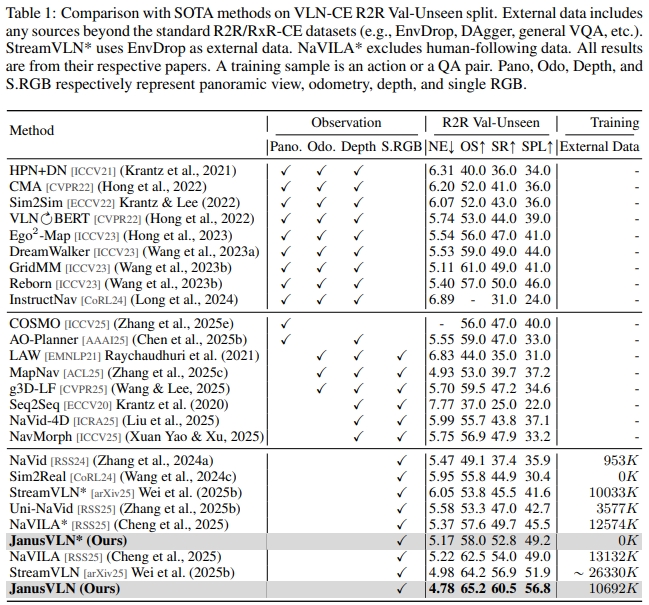
实现宣称超越了20中SOTA方法。当采用多数据输入时,成功率可以提升10.5~35.5; 而采用更多的RGB训练数据可以带来3.6~10.8的性能提升。 这里的confuse是需要更多的RGB训练数据才可以带来性能提升?这样的话对比是否公平呢?
原文:
Extensive experiments demonstrate that JanusVLN outperforms over 20 recent methods to achieve SOTA performance.
For example, the success rate improves by 10.5-35.5 compared to methods using multiple data types as input and by 3.6-10.8 compared to methods using more RGB training data.
对于模拟器下测试,以连续环境的R2R为例(对于跟20多种SOTA对比),SR达到了60左右~
对于实机实验,采用的是Unitree Go2,Insta360 X5相机捕获RGB,而JanusVLN运行在远程的一张A10 GPU上(处理RGB以及指令)返回推理结果给机器人执行。

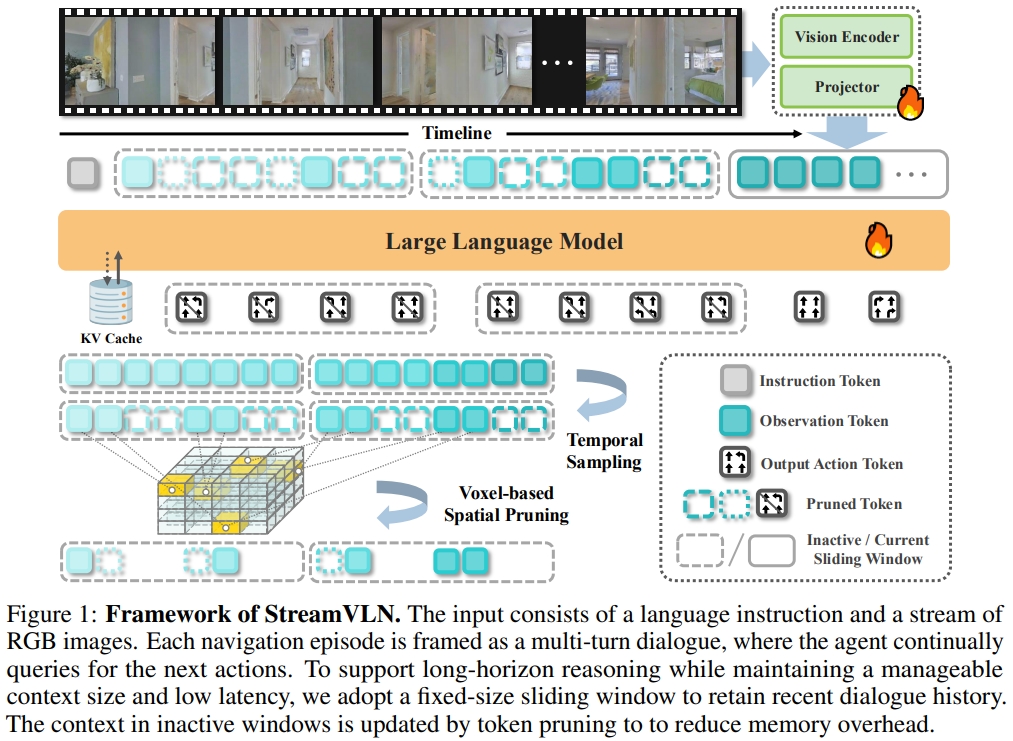
4. StreamVLN: Streaming Vision-and-Language Navigation via SlowFast Context Modeling
PS:上一篇论文的滑动窗口部分应该是受到本文的启发~
理论部分
对于VLN而言,保留长时间的信息(long-term context)以及实时相应都是很重要的。现有的做法有以下几种:
- 采样视频数据,但是降低了时间分辨率会导致预测low-level action不准确,并且对于需要精确的时间变化场景也满足不了。
- 将视觉token压缩为稀疏memory,但这会牺牲时间和视觉细节
并且这些方法一般需要在每个action step更新LLM的对话文本,这也会导致训练与推理的计算冗余。
本文提出了实现低延时的action 生成的StreamVLN框架。将Video-LLM(LLaVA-Video模型,采用的是Qwen2-7B)扩展为交错的视觉-语言-动作模型,进而实现多轮对话下与视频的连续交互。
为了应对长期上下文管理和计算效率的挑战,StreamVLN采用混合的慢速-快速上下文建模策略(hybrid slow-fast context modeling strategy):
- 快速流式对话部分(fast-streaming dialogue context with a sliding-window KV cache)通过活动对话的滑动窗口促进响应式动作生成
- 缓慢更新的内存部分(slow-updating memory context via token pruning)使用3D感知Token来修剪策略以及压缩历史视觉状态。这部分使得StreamVLN可以通过键值对的缓存重用,实现连贯的多回合对话( coherent multi-turn dialogue)
StreamVLN采用滑动窗口机制在固定数量的对话回合上缓存token的键/值状态(KV),以实现高度响应的动作解码。 通过利用过去窗口的视觉语境(visual context)来增强长时间的推理。
而为了控制内存的增量,StreamVLN采用temporal sampling以及剪枝策略(基于3D空间的相似性来减少token的冗余)
实验部分
下面是在连续环境下的R2R和RxR的对比效果:
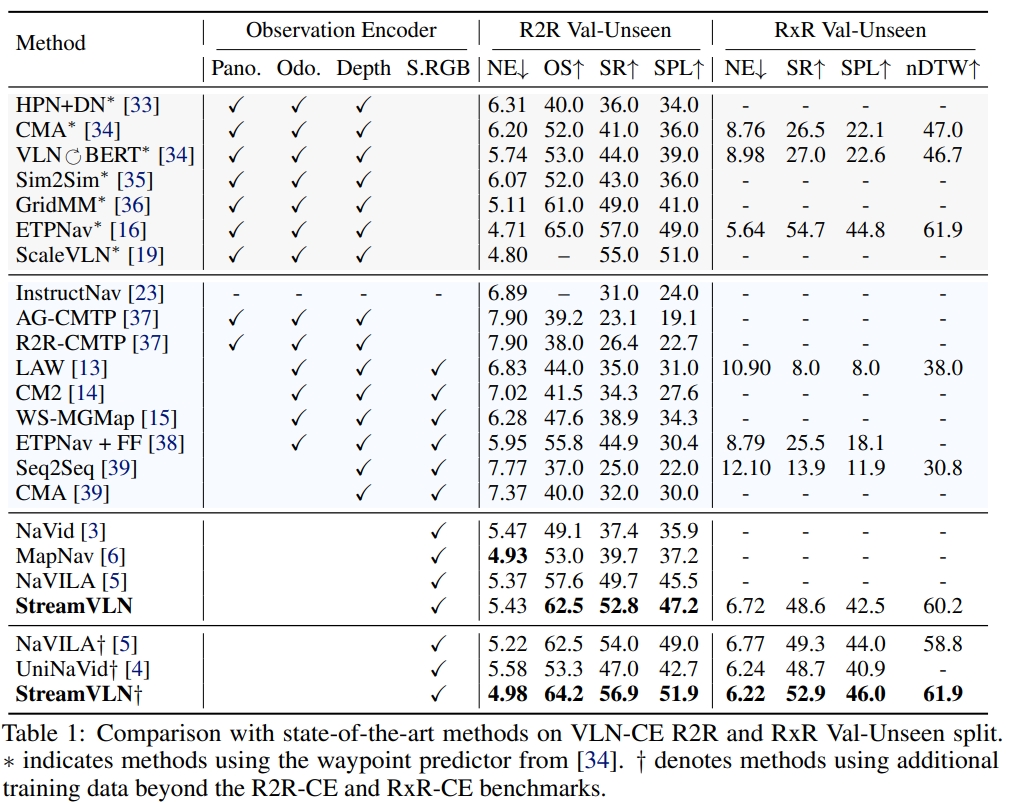
采用的实验平台为Unitree Go2 robotic,输入为Intel® RealSense™ D455的RGB-D数据。 StreamVLN在单张RTX4090 GPU的远程工作站上运行。 至于在真实机器人上的效果此处就不截图了,网站和论文都有~
5. Navila: Legged robot vision-language-action model for navigation
- 代码已经开源;
- 阅读及复现过程请见博客
6. VLN-Zero: Rapid Exploration and Cache-Enabled Neurosymbolic Vision-Language Planning for Zero-Shot Transfer in Robot Navigation
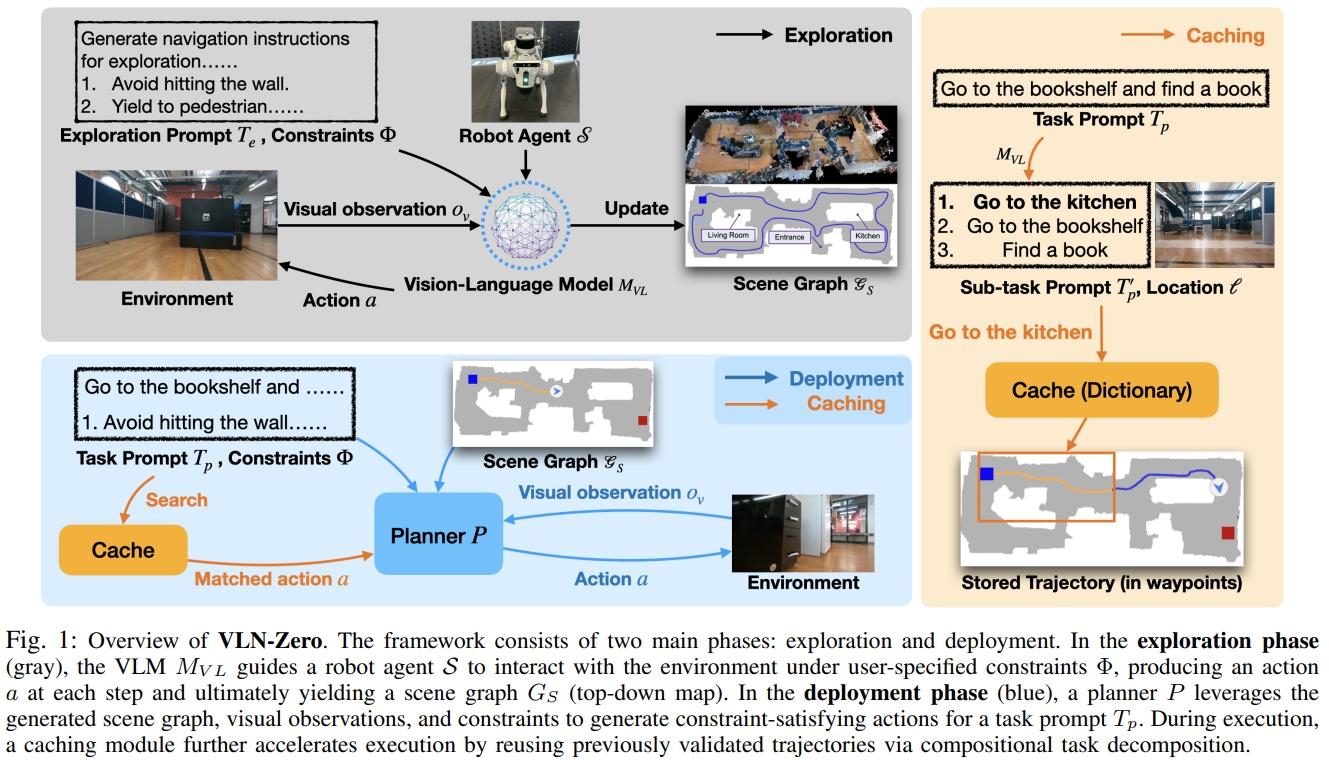
VLN-Zero通过VLM构建symbolic scene graphs(符号场景图),进而可以实现zero-shot的neurosymbolic navigation(神经符号导航)。 其架构如下图所示,分为两步:
- exploration phase(指导机器人在用户指定的约束下与环境交互):基于结构的提示词指导VLM寻找有信息以及diverse轨迹,并且压缩场景图的表达。
- 所谓的探索,其实就是通过提示词,让VLM可以探索环境,生成场景图
- deployment phase:neurosymbolic planner(神经符号规划器)根据整个场景以及环境的观测来推理及生成执行动作。并且还有一个cache-enabled execution
module(缓存的执行模块)通过重用此前计算的task-location轨迹来加速adaptation。
- 所谓的部署阶段,就是构建了一个规划器,使其能够根据场景图、视觉观测、任务提示来生成满足约束的动作
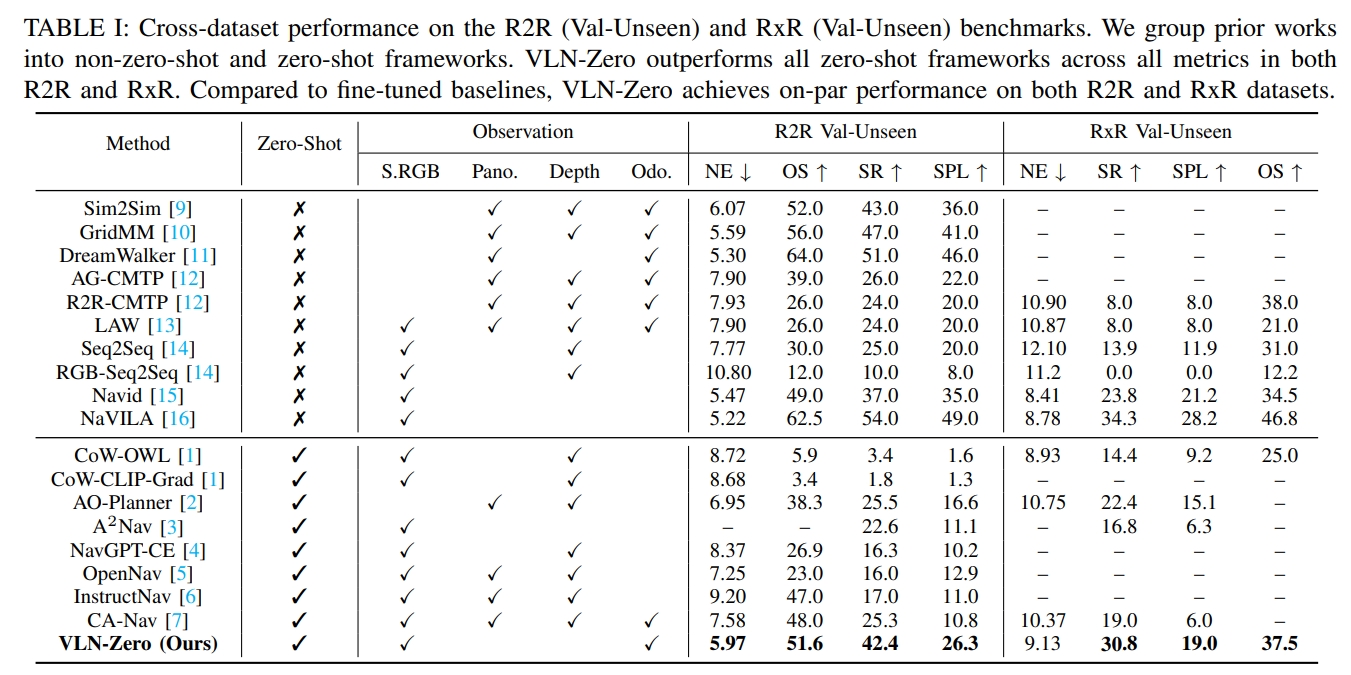
至于实验效果的看上去效果还是不错的,比如在unseen场景下,跟其他SOTA对比:
7. InternVLA-N1: An Open Dual-System Vision-Language Navigation Foundation Model with Learned Latent Plans
InternVLA-N1是首个开源的基于双系统VLN模型。 主要贡献点如下:
- 首个开源的基于快慢双系统的VLN基础模型。System 2 用于执行多轮的基于语言指令、观测(视角感知)的精确规划。而System1则是负责在真实世界环境下,执行System2输出的规划。其中,学习到的latent plans作为中间表示,来实现两个系统之间的交互;
- System2 (pixel goal planner),利用多模态LLM(一个7B的VLM,Qwen-VL-2.5)作为骨架,利用其commonsense知识以及多模态感知能力;VLM预测的微image space的pixel坐标。
- System1则是一个轻量级的,基于diffusion的视觉导航policy;该policy设计用于实时避障与路径规划,预测包括导航轨迹以及对应轨迹的安全分数(safety score)。输入可以是latent plan也可以支持输入显式的目标。训练的时候以image-goal and pixel-goal embeddings作为输入,采用point-goal作为label监督训练。
- 两个系统先进行预训练,然后通过fine-tuning phase来实现异步推理,增强两个系统之间中间目标接口(intermediate goal interface)的空间表示(spatial representation );
- 【此部分只是一个拓展】此外,为了增强以及验证latent representation,作者训练的一个基于latent plan的世界模型来预测后续的观测序列(subsequent egocentric observation sequences);
- InternData-N1,大型的导航数据集,包含了超过3000个场景的50 million的图像,一共4,839公里的机器人导航。分为VLN-N1(large-scale open-source 3D assets)、VLN-CE(一些现有的VLN-CE数据集)、VLN-PE(收集physics-based simulation数据);
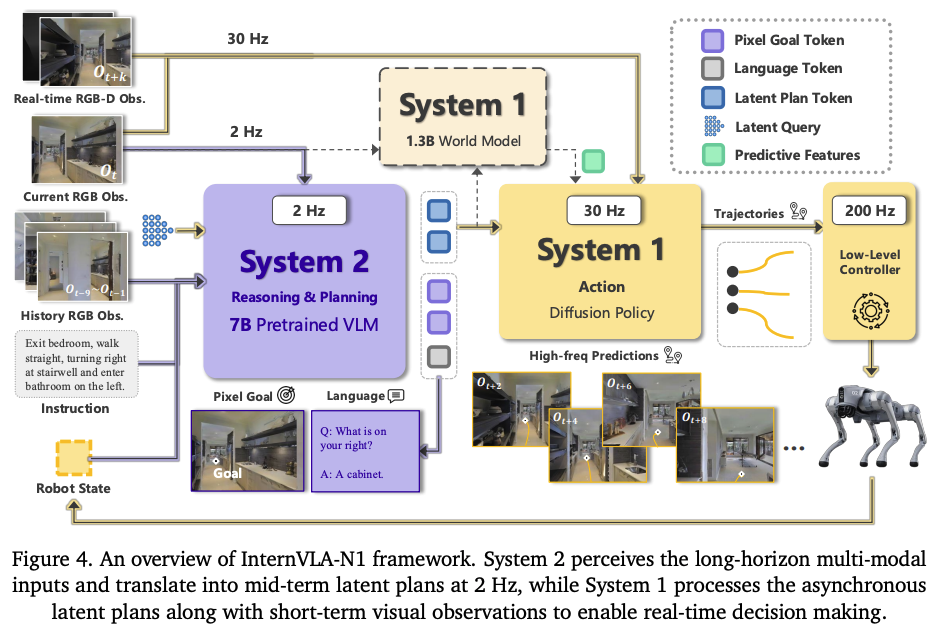
此外实验还验证了,InternVLA-N1(仅仅用仿真数据训练)在轮式、足式、双足人形上的zero-shot泛化性。实现超过150m的长程规划,以及实时的决策(>30HZ)。
总结
PS个人观点:对于VLN任务而言。language输入重要性略低,只是为了交互。更重要或者说更难的是“轻地图,重感知”的实现。
此外,得益于DeepSeek,ChatGPT等基础通用大模型的强大,LLM或者VLM具备一定的common sense,往往只需要fine-tune,甚至zero-shot也可以。所以这也“language”这个词的主要作用。但本质整个感知的pipeline,似乎“language”的位置越高的工作往往只能仿真,而“视觉感知”、“控制policy”等比重越大的工作往往可部署于实际机器人中