之前博客对VLN做了个初步的调研,但是还是有点囫囵吞枣,本博文对2024年在Transactions on Machine Learning Research发表的VLN综述做个深入的阅读,希望能对其有更深入的理解~
- Paper list in: Awesome-VLN and Blog
- github
基于本文的总结思路如下:

引言
本文致力于对利用基础模型(foundation models)应对VLN任务的survey,也就是大模型赋能下的VLN。
今年来,基础模型比如BERT,large language models (LLMs),和vision language models (VLMs)在多模态理解(multimodal comprehension)、推理和跨领域泛化方面表现出了出色的能力。 这些模型都是通过大量的数据训练,比如文本、图像、声音、视频,并且可以进一步泛化到不同的具身智能AI task。而这些基础模型也进一步可以用到VLN领域。这也是本文的motivation,关注基础模型在VLN领域的应用,而并非像其他survey那样关注benchmark或者传统的方法。
此外,作者还引入了基于LAW(论文:Language models, agent models, and world models: The law for machine reasoning and planning)框架的系统框架,用于组织和理解VLN中的多模态推理和规划任务,强调了基础模型在构建世界模型和智能体模型中的作用。 作者,从world model、human model和VLN agent三个角度对VLN的挑战进行了分类,并提供了相应的解决方案。
如下图所示,VLN中的world model就是agent所维护的,可以用于理解周围环境及其action可以改变世界状态,的一个抽象。
human model就是人类partner给的指令
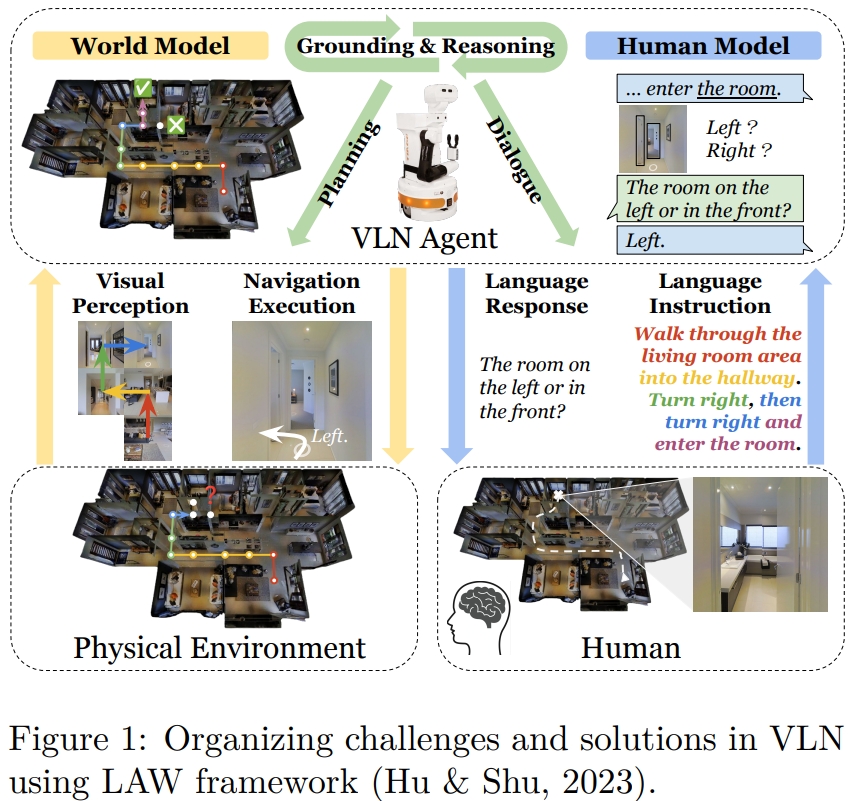
因此,对于VLN任务,可以分为三个方面:
- 学习world model来更好的表征视觉环境,并且可以泛化到没见过的环境
- 学习human model进而根据的人类的指令,有效地理解意图
- 学习VLN agent,利用world model和human model来理解语言、交流、推理和规划,使其能够按照指示在环境中导航
下图分析了基于基础模型时代的挑战、解决方案及未来发展方向。

背景
VLN的定义:VLN被定义为一个需要智能体遵循人类指令、探索三维环境并在各种形式的歧义下进行情境交流的多模态和协作任务。这个任务要求智能体能够理解和执行自然语言指令,同时处理视觉信息。 按照语言指示,agent的需要在一系列离散视图(discrete views)或较低级别的action和控制上生成轨迹以到达目标位置(一般认为到目标3米内)。 此外,在导航过程中agent可能还需要跟人类做信息的交互(请求帮助或进行自由形式的语言交流)。并且还有一部分需要做操作或者目标检测等任务。
VLN包含了大量的benchmarks以及任务,如下表1所示:
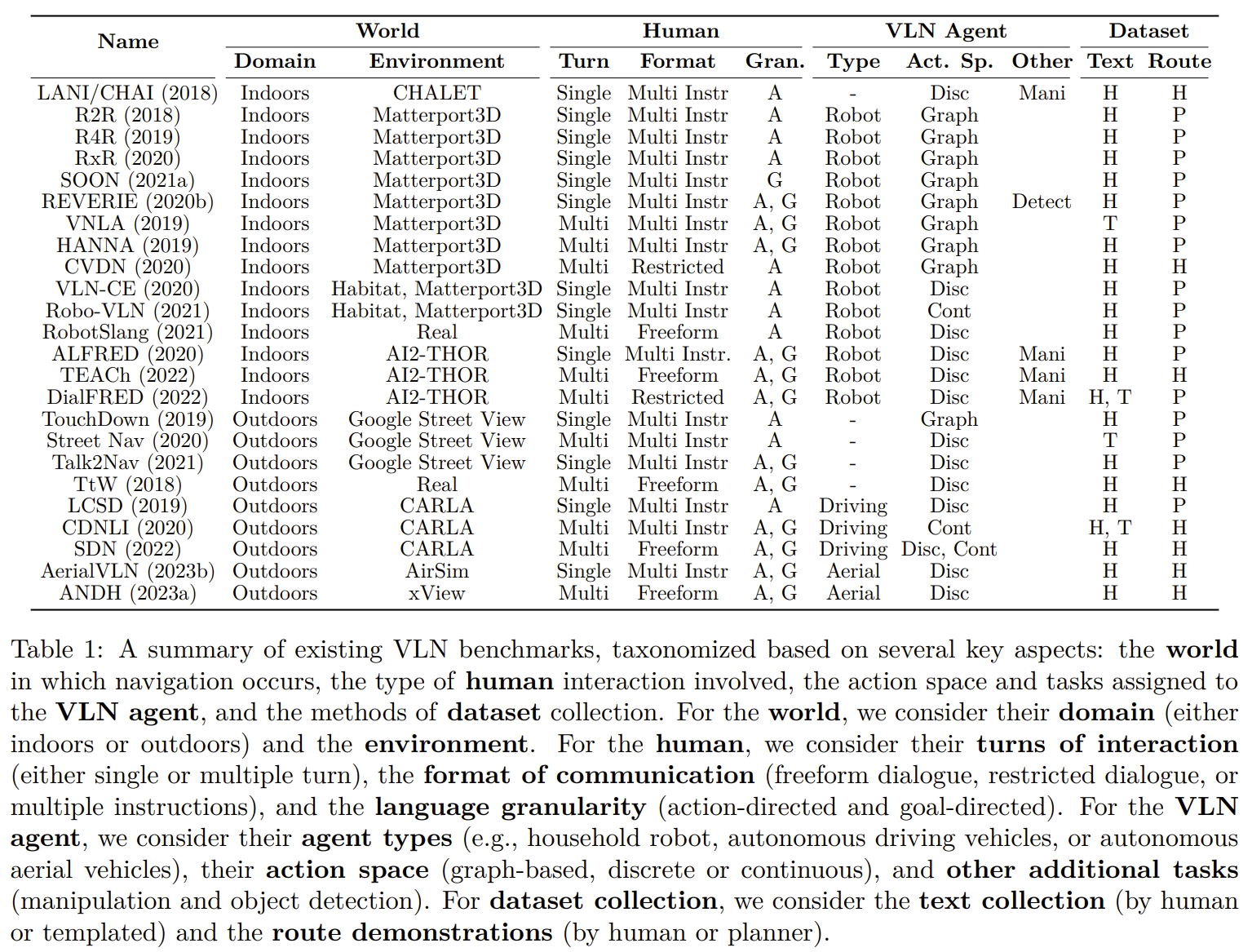
从LAW的角度来分析,VLN的基准目前包含以下几个方面:
- world: 导航的场景,室内、室外、空中场景。仿真环境抑或真实环境。
- human:人类指令的类型,包括交互轮数(单个或多个)、通信格式(自由对话、受限对话或多个指令)和语言粒度(动作导向或目标导向,甚至是需求导向)
- VLN agent:包括了其类型(如,家用机器人、自动驾驶车辆或自动飞行器)、动作空间(基于图形、离散或连续)和附加任务(操作或物体检测)。
- 数据收集:包括文本收集(text collection)方法(人工生成或模板化)和路线演示(人工执行或planner-generated)。
至于Foundation models则是有很多种,都是通过大型数据集训练的,在大量下游任务中都展示了较好的泛化能力。
- 纯文本的基础模型,比如BERT, GPT-3等在文本生成、翻译、理解等都展示出色的性能
- vision-language (VL) foundation models,比如LXMERT,CLIP,GPT-4则是展示了强大的多模态学习能力(integrating both visual and textual data)
world model:学习及表征视觉环境
world model帮助VLN agent了解其周围环境,预测其行为将如何改变世界状态,并使其感知和行为与语言指令保持一致。它存在两点挑战:
- 编码历史的视觉观测量,相当于就是让模型有记忆
- 对于没见过的环境的泛化能力
History and Memory
对于VLN任务而言,其历史的观测量不仅要包括过去的视觉观测,还应该包括过去执行的actions,来为当前要执行的action做决策。 在采用基础模型之前,LSTM采用隐含层来作为隐式的memory以此支持agent做导航决策。学者们也研究了不同的attention机制或者auxiliary tasks(辅助任务)来提升历史与指令之间的对齐。
History Encoding
通过基础模型将历史信息编码的做法有以下几类:
- 将导航历史编码到定期更新的状态 tokens中
- 将历史导航信息通过multi-modal Transformer编码成序列
- 而基于LLM的方法有倾向于将视觉环境转换为文字描述。同时导航历史也编码这些图片的描述。
Graph-based History
也有一部分方法是通过图信息来增强导航历史建模的。
- 利用Transformer encoder来捕获环境的几何线索
- 除了拓扑图以外,也有用grid map,语义地图、local metrics map以及 local neighborhood map来编码导航过程中的历史信息。
不同环境下的泛化能力
VLN中的一个难点则是从有限的环境中学习信息并且泛化到新的以及没见过的环境
预训练的视觉表征
- 早期大部分获取视觉表征都是通过ImageNet预训练的ResNet
- 在大模型时代,则是用CLIP的visual encoder来代替ResNet。由于CLIP通过图像-文本对的对比损失进行预训练,自然更好地对齐图像和指令。
- 更进一步的有采用从video数据中学习视觉表征,这类工作认为从视频中学到的时间信息是非常重要的。
环境的数据增广
通过大量的数据训练也可以增强模型的泛化能力
- 在基础模型之前,一般都是通过自动收集新的环境来fine-tune 基于LSTM的agent
- 通过自动生成的合成数据来做数据增广
- 不同环境的数据拼接(mix up),改变环境的外观、风格或者提取高频feature,甚至还有根据当前的观测来合成将来的环境。
- 而直接调用预训练好的LLM模型可以大大增强模型的能力。当然in-domain的pre-trained会更有效
human model
除了学习以及对世界进行建模,VLN agent还需要human model来根据具体情况理解人类提供的自然语言指令,以完成导航任务。 对于human model也有两个挑战点:解决不同视觉环境中接地指令(grounded instructions)的歧义和泛化问题。
指令的歧义
在单论指令任务中,agent需要跟从初始指令,而没有进一步的与人交互来做澄清,因此容易陷入歧义。 此外,指令可能包含在当前视角下不可见的landmarks或从多个视图中可见的无法区分的landmarks。 这些问题在基础模型之前基本没有得到解决。虽然也有通过聚合多条指令,从不同角度描述同一轨迹,但仍然依赖于人类标注。 而来自于基础模型的综合感知语境以及commonsense knowledge可以很好的解决指令的歧义
感知语境与常识
大尺度跨模态预训练模型(比如CLIP)可以较好的匹配视觉语义与文本,这使得VLN agent可以利用视觉对象的信息及其在当前感知中的状态来解决歧义(特别是单轮导航场景)。 此外,LLM的常识推理能力可用于澄清或纠正指令中模糊的landmarks,并将指令分解为可操作的items。
主动寻求信息
虽然模糊的指令可以根据视觉感知和情境来解决,但另一种更直接的方法是向沟通partner寻求帮助。而这类型的工作由分为三个关键挑战:
- 决定什么时候请求帮助
- 生成信息寻求的问题,比如下一个行动、目标、方向
- 开发一个提供查询信息的oracle,也可以是真人,规则与模板,或者神经网络 LLM和VLM可以在这个框架中扮演两个角色,要么作为信息寻求模型(解决when以及what to ask),要么作为人类助手或信息提供模型的代理。
指令的理解与泛化
导航数据的规模和多样性有限,影响了智能体理解和遵循各种语言表达的能力,特别是在未见导航环境中。 虽然,语言风格本身在见过或没见过的场景都有较好的泛化能力,但是如何将指令与看不见的环境联系起来可能是一项艰巨的任务。
预训练的文本表征
在基础大模型处理之前,大部分的工作都是依赖于LSTM来做文本编码。 而基础模型出来后(比如PRESS,BERT),基于预训练的语言模型来fine-tune获取的文本表达可以有更好的泛化能力; 接下来就是多模态的Transformers(比如VLN-BERT,pre-training on large-scale text-image pairs form web)可以更好的获取视觉-语言表征
指令合成
通过指令合成可以提升agent的泛化能力。比如通过使用人类注释的指令轨迹对训练离线说话者(指令生成器),然后由它来生成基于全景图与轨迹的指令(训练离线指令生成器)。
VLN agent
VLN agent则是负责具身推理和规划。 world与human模型是负责增强视觉和语言理解能力,而agent则是负责学习推理以及规划的
对齐和推理
VLN需要对空间以及时间维度的指令、环境都要理解,特别是agent需要考虑之前的action,识别当前要执行的子指令,将文本与视觉环境对齐来执行action。
显示的语义理解
之前的工作通过通过显式的语义建模来增强智能体的对齐(grounding)能力,包括:在视觉和语言模态中对运动和地标进行建模,利用指令中的句法信息以及空间关系。 然而,使用基础模型的研究较少探索在VLN智能体中进行显式对齐。
预训练VLN基础模型
除了显式的语义建模外,之前的研究还通过辅助推理任务来增强智能体的对齐能力(grounding ability)。 但对于基于大模型的VLN agent较少有这方面的研究,因为预训练的模型已经让agent有较好的空间及时间维度的语义先验。
规划
动态规划使VLN智能体能够适应环境变化并实时改进导航策略。 除了基于图的规划器(graph-based planners)利用全局图信息来增强局部动作空间外,基础模型特别是大语言模型(LLMs)的兴起也带来了基于LLM的规划器进入VLN领域。
基于图的规划器
最近的研究强调了通过全局图信息来增强导航智能体的规划能力:
- 通过从访问节点的图前沿(graph frontiers of visited nodes)获取全局action step来增强局部导航动作空间,以实现更好的全局规划。
- 通过区域选择和选择节点来进行高层次的规划,以增强导航决策。
- 通过为图前沿(graph-frontier)增加网格级动作来丰富全局和局部动作空间,以实现更准确的动作预测。
- 采用分层规划方法,通过从预测的局部可导航图中选择局部路点来替代低层次的规划。
- 通过在局部地图内对对齐指令来实现轨迹规划
- 构建全局拓扑图或网格地图,以促进基于地图的全局规划
- 使用视频预测模型或神经辐射表示模型预测多个未来路点,以根据候选路点的长期效果计划最佳动作。
基于LLM的规划器
利用LLMs的常识知识生成基于文本的规划。
- 创建详细的计划,由子目标组成,并根据检测到的对象动态调整这些计划
- 专注于将导航任务分解为详细的文本指令,从静态和动态角度生成分步计划。
- 使用思维链推理生成缺失的动作,与交互对象一起使用。
- 将导航指令分解为代码格式的序列化、目标相关函数,并使用代码编写的大语言模型来指导这些目标的执行。
- 构建一个3D场景图作为输入到LLMs,以生成可行且上下文适当的高层次计划。
基于基础模型的VLN智能体
随着基础模型的出现,VLN智能体的架构经历了显著的变化。 最初由Anderson et al. (2018) 概念化的VLN智能体是在Seq2Seq框架内构建的,使用LSTM和注意力机制来模拟视觉和语言模态之间的交互。 随着基础模型的出现,智能体的后端从LSTM过渡到Transformer,最近则转向这些大规模预训练系统。
采用VLMs作为agent
每一轮输入语言、视觉和historical tokens。它通过对这些跨模态token进行self-attention来捕捉文本-视觉对应关系,然后用于推断action的概率。
采用LLMs作为agent
由于LLMs具有强大的推理能力和世界的语义抽象能力,并且在未知的大规模环境中表现出强大的泛化能力,最近的研究开始直接使用LLMs作为智能体来完成导航任务。通常,视觉观察被转换为文本描述并与指令一起输入到LLM中,然后执行动作预测。
paper list
最后附上对本文对应的github的paper list的重塑
World Model
A world model helps the VLN agent to understand their surrounding environments, predict how their actions would change the world state, and align their perception and actions with language instructions.















Human Model
The human model comprehends human-provided natural language instructions per situation to complete navigation tasks.













VLN Agent









VLN-CE Agent





LLM/VLM-based VLN Agent
Zero-shot





Fine-tuning
| Year | Venue | Paper Title | Repository | Note |
|---|---|---|---|---|
| 2025 | Arxiv | EvolveNav: Self-Improving Embodied Reasoning for LLM-Based Vision-Language Navigation |  |
- |
| 2024 | NACCL Findings | LangNav: Language as a Perceptual Representation for Navigation |  |
- |
| 2024 | - | NavCoT: Boosting LLM-Based Vision-and-Language Navigation via Learning Disentangled Reasoning |  |
- |
| 2024 | CVPR | Towards Learning a Generalist Model for Embodied Navigation |  |
- |
| 2024 | ECCV | NavGPT-2: Unleashing Navigational Reasoning Capability for Large Vision-Language Models |  |
- |
| 2024 | RSS | NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation | |
- |
Behavior Analysis of the VLN Agent
| Year | Venue | Paper Title | Repository | Note |
|---|---|---|---|---|
| 2025 | CVPR | Do Visual Imaginations Improve Vision-and-Language Navigation Agents? | - | - |
| 2024 | EMNLP Findings | Navigating the Nuances: A Fine-grained Evaluation of Vision-Language Navigation |  |
- |
| 2023 | CVPR | Behavioral Analysis of Vision-and-Language Navigation Agents |  |
- |
| 2022 | NACCL | Diagnosing Vision-and-Language Navigation: What Really Matters |  |
- |