本文是波士顿动力24年arvix的工作,关注Instruction Following,通过LLM大模型与传统的SLAM导航相结合的方式让具身导航智能体学会指令跟随。 本博文为论文阅读笔记,仅供本人学习记录用~
相关博客/资源list:
引言
本文主要是实现自然语言指令与机器人中广泛使用的基于地标的地图之间的对齐,以及自然语言导航指令。
对于大规模场景,如多层住宅,可以通过因子图中与机器人姿态联合优化,实现3D landmark或者地图的估计,这对传统SLAM技术而言基本是solved problem了。
因此本文希望能做到的是如何将基于语义指令的导航与Landmark-based mapping and navigation systems相结合,也就是grounding natural language instructions to landmarks and robot poses in a factor graph。
论文的主要contributions如下:
- 本文提出了一个用于指令跟随的语言推理因子图(LanguageInferred Factor Graph for Instruction Following,LIFGIF),实现基于构建好的三维下,基于语言指令的导航。
- 以目标为主的语言导航指令数据集:Object-Centric VLN (OC-VLN)
- 实现在真实波士顿狗子上的zero-shot指令跟随
但注意,本框架是in a novel environment while the map is constructed以及unseen unexplored environments
应该就是首先是针对unseen-environment的,其次通过在探索的同时,通过传统的SLAM/导航来构建因子图与估算姿态,通过将自然语言指令与因子图中的地标和机器人姿态联系起来,实现VLN任务。
这样就可以利用成熟的SLAM框架,避免了其他VLN方法在真实物理环境下泛化能力差的问题。
此外,所采用的视觉与语言基础模型也不需要task-specific training。
目前代码还没开源,但网站上给出了链接及一些dmeo样例。
OC-VLN数据集
数据集仅仅包含以对象为地标的指令(object-centric instructions),要求机器人根据对象中心的指令导航至目标位置。
比如:“向前走到沙发上,然后走到你面前的长椅上,停在地毯上”也就是都是以物体的描述为主的。
使用来自HM3DSem的真实世界3D扫描在Habitat模拟器中生成episode。使用GPT-4生成细粒度的对象中心指令。
利用HM3DSem和Goat-Bench数据集,通过两阶段方法生成OC-VLN任务的导航指令:
- 利用HM3D Sem数据集中的3D扫描在Habitat模拟器中创建虚拟环境,生成episode,保存RGB图像。
- 利用GPT-4模型结合图像和轨迹信息来生成指令。首先提取关键对象,然后生成基于对象的详细导航指令。
OC-VLN包含多个episode,平均路径长度约7米,支持连续环境和2DoF动作空间,指令为开放词汇,平均包含29个单词、8个子指令和8个对象。 与VLN-CE相比,OC-VLN的路径较短,但指令更长,反映了更丰富的对象中心信息。
理论方法
语言指令不仅仅可以指导机器人导航,还编码了重要的空间信息(关于环境的布局的)。
即使在还没任何感知之前,指令都可以给机器人提供关于环境地图的初步了解(尽管会有一定的不确定性)。
比如move forward until you see a chair这就意味着在机器人当前的位置的前方(X轴)会有一张椅子,尽管不知道具体的距离。那么通过将这一空间的信息编码成一个因子图,那么这一先验就可以植入到传统的基于因子图的SLAM系统中。
那么当机器人观察到指令中提到的地标时,这些地标对应的不确定性就大大降低,从而帮助机器人在导航过程中,根据指令的上下文中来定位。
这个过程就很好的将语言的引导(linguistic guidance)及空间的感知(spatial awareness)相结合:
从语言指令推断地图先验
将语言指令转换为language-inferred graph,也就是通过语言的输入推理环境地图,并通过因子图的形式来编码地图的先验分布(prior distribution)。 这个graph包含了两种节点:
- Waypoint节点表示机器人应导航到的航点,
- Landmark节点表示机器人预期沿路径观察到的目标(unknown positions)。
如下图所示。对于指令“go forward to the piano. turn right. stop at the table”.可以推导出四个Waypoint节点:起点、piano waypoint、右转的waypoint,以及最终停止在table处的waypoint。 此外还有两个Landmark节点:Piano和Table
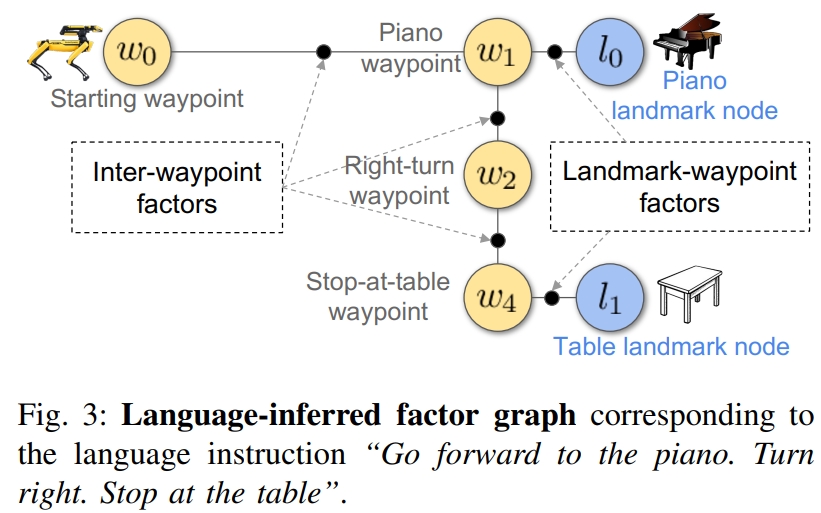
在给定指令中描述的几何关系下,推断出的graph表示了waypoints和landmarks联合分布:

Inter-waypoint factors捕获了连续waypoints基于action的几何信息,而Landmark-waypoint factors则是代表了waypoint和物体的空间关系。
作者采用LLM(GPT-4)来实现将任意格式的文本指令转换为language-inferred graph,通过如下提示词实现:
You are an expert in guiding a home navigation robot. The robot wants to follow a detailed language instruction to reach a target destination. To successfully complete this task, you will break down the input ‘instruction’ to output a list of ‘waypoint’, ‘landmark’, ‘waypoint-to-waypoint transition actions’ and ‘waypoint-to-landmark spatial relationship’
此外,还提供一个样本来让LLM知道应该怎么转换:

SLAM与推断地图先验的集成
将语言推断的地图先验(language-inferred map prior)整合到传统的基于物体的SLAM导航系统中。 当然,对于语言推理的先验地图初始化的时候具有极高的不确定性(由于语言描述的ambiguity以及缺乏直接的传感器信息)。 随着机器人导航,它会同时定位自己在不确定地图上的位置,同时通过观测量来refine地图,逐渐将模糊的指令描述转换为精确的空间表达。
基本的目标的找到最大后验(MAP)来估算机器人pose X、观测的landmark O、语言推导的waypoint W、landmark L、所有的传感器感知Z的分布、语言描述waypoint以及landmark的关系R。

那么进而将VLN任务分为SLAM+语义推断的graph结合的形式。并且inferred graph也可以通过landmark-observation factors增强后用SLAM因子图的包(比如GTSAM)来进行优化。
推断地标与观测的数据关联
为了姚构建landmark-observation factors,需要进行在推测的landmarks以及观测数据之间建立数据关联。 一个landmark可以有多个候选的观测匹配,而一个观测也可能可以匹配多个landmarks。本文则是采用CLIP来通过余弦相似度来选取最好的匹配。

导航策略
通过在language-inferred graph中定位机器人,使机器人能够通过顺序移动到推断的航点、在每个航点0.5米内游走并在最后一个航点停止来实现导航。 通过下面策略来旋转导航点:

实验效果
在实验中机器人每个时间步下都可以获取RGB、深度图以及完整的语言指令。而输出则是四个离散的action:前进、左转、右转、停止。 评价标准也是VLN的metrics。
对于物体的识别采用RAM、物体的grounding采用DINO预测bounding box,最后再通过SAM来获取分割语义。
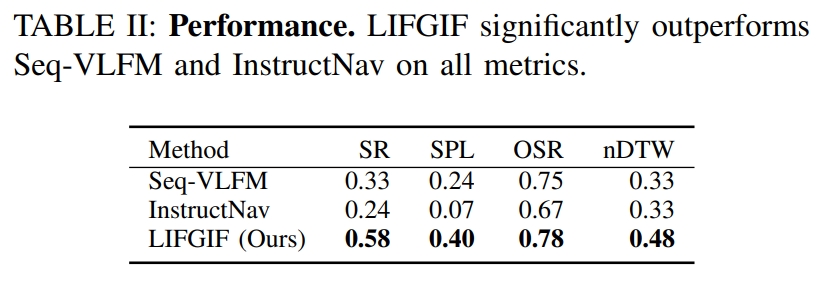
在 OC-VLN数据集上的定量对比:
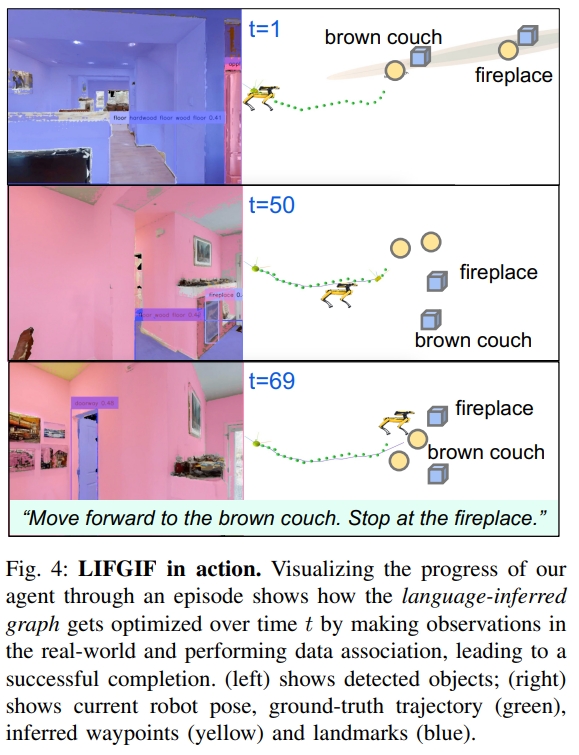
下图则是定性分析的效果: