当前基于learning的机器人控制算法中,十亿参数级别的视觉-语言-动作(VLA)模型虽具备出色的泛化能力,但推理延迟过高成为瓶颈——传统VLA模型,无法满足动态任务(如抓取运动物体)的实时性需求。
此前博客曾对高效VLA做过调研,包括Efficient-VLA对一篇高效VLA的survey paper进行阅读,而NanoVLA也对基于orin上的高效VLA做分析。
本博文对Dexmal发布的实时VLA模型进行解读,该工作在消费级显卡(RTX4090)上完成pi0模型:30HZ推理与480HZ动作生成。并且在抓落笔任务(grasping a falling pen task)成功率达到100%
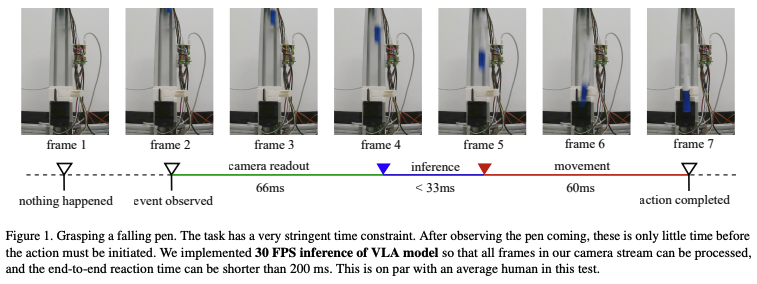
PS: 捉取落笔任务确实比较难,甚至连人类都难以做到😂
而其中的480HZ是指最大可达到的,这也是实时力控制的阈值
引言
实时运行的关键阈值是33ms以内的推理时间:这一指标能确保处理30 FPS的RGB视频流时不丢帧;本文提出了实时运行的VLA方案,在单块消费级RTX 4090 GPU上,实现π₀级多视图VLA模型的实时推理——30Hz帧率(图像处理)与最高480Hz轨迹频率(动作生成),并通过真实世界实验验证其有效性(如抓取下落的笔)。
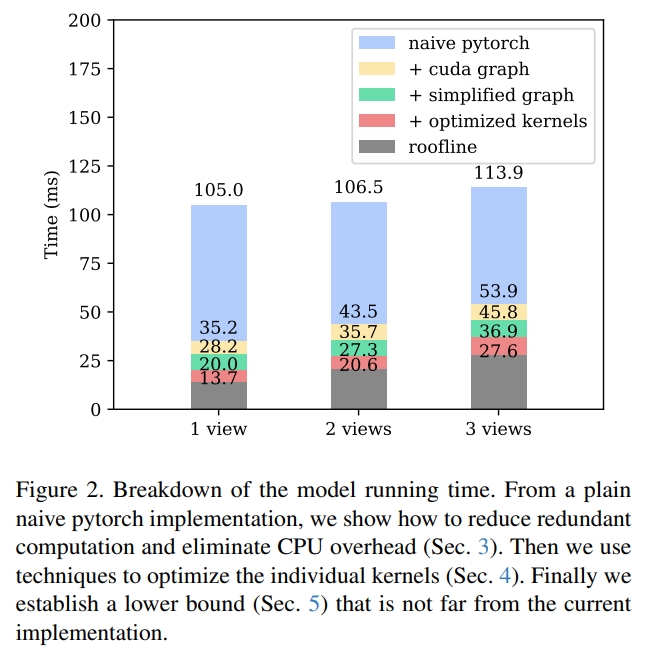
如下图所示,对于两输入视角(two input views),延时大约是27.3ms,而对于π₀原工作有较大的提升(106.5ms, 2 views, 单个RTX4090)。这一性能的增益主要是得益于推理pipeline的工程性实现。
为了实现实时推理,本文的核心优化策略为:从消除开销到内核深度调优。 主要包含四步:
1. 消除基础开销(Eliminating the Overheads):
这部分主要是工程性实现,分为以下几点:
- (cuda graph)采用CUDA Graph来去除CPU内核启动开销(CPU overheads)
- (simplified graph)通过变换计算图(computational graph),减少总的MAC工作量或者启动内核的数目
- (optimized kernels)重新分配在单个内核内的内存及tensor的操作,更好地利用并行性 通过这些策略的设计将推理时间推进到30FPS甚至更高。
PI0基于PyTorch的朴素实现(naive torch)推理时间超100ms,因此,首要优化是消除CPU与计算图的冗余开销。
- 【CUDA Graph】采用CUDA Graph来去除CPU内核启动开销:VLA模型(如π₀)单次推理需启动上千个CUDA内核,而Python代码驱动内核时会产生显著开销。
- 通过CUDA Graph机制,先记录一次推理过程中的所有内核流(record the stream of launched kernels during model inference),后续推理直接重放。在replay过程中,内核由GPU和驱动直接启动,完全消除Python执行开销。
- CUDA图方法需要确保所有内核代码和缓冲区指针在运行过程中保持不变。(是否意味着向量的长度要固定不变?如果是的话,那对于文本部分就不适用了)
- 如上图2(2 views)所示,CUDA Graph这一步就将推理时间直接减半,naive pytorch的106.5ms降低到43.5ms。
PS:关于CUDA Graph更多介绍:
CUDA Graphs能够将一系列 CUDA 内核定义并封装为一个单一的操作图,而不是逐个启动操作。这种机制通过一个 CPU 操作启动多个 GPU 操作,从而减少 GPU 任务的启动开销。
传统GPU编程:每当需要让 GPU 执行任务时,CPU 都必须发送指令,并等待 GPU 完成任务后再发送下一条指令。这种 “逐个发送” 的方式效率较低,因为每个 GPU 操作(例如内核调用或内存复制)所花费的时间以微秒为单位,而提交每个操作给 GPU 也会产生微秒级的开销。因此 CPU 和 GPU 之间频繁的通信导致了时间浪费,这在实际应用中变得越来越显著。
CUDA Graphs 的核心优势在于能有效减少这种通信开销。
在启动 GPU 任务时,CPU 需要进行一系列的设置和初始化操作。而 CUDA Graphs 通过将多个任务组合成一个图结构,一次性提交给 GPU,使其能够自行安排任务的执行顺序,而不需每次都等待 CPU 的指令,从而大幅提高效率。
1. 减少 CPU 和 GPU 的通信开销:传统 CUDA 编程模型需要 CPU 逐个提交 GPU 任务,而 CUDA Graphs 允许将多个任务组成一个图结构并一次性提交;CUDA Graphs 减少了通信开销,提高了执行效率
2. 提高并行性:传统模型需要开发者手动管理任务的依赖关系和执行顺序;而 CUDA Graphs 通过图结构清晰地表达了计算逻辑,减少了潜在的错误和性能瓶颈,GPU 可以并行处理多个没有依赖关系的任务,进一步提高效率
3. 优化长时间运行的任务:对于需要重复执行的任务,CUDA Graphs 可以将其录制为图并反复运行,避免每次都重新提交的开销
- 【简化计算图/Simplifying the Graph】通过等价变换重构计算图,去除冗余计算。如上图2(2 views)所示,将推理时间从53.9ms降低到45.8ms。包含三类变换:
- RMS归一化权重折叠/Folding RMS norm weight:RMS归一化的affine参数与后续线性层均为线性操作,利用结合律(associativity law)修改线性层权重,将两步合并为一步;
- 动作-时间嵌入层折叠/action-time embedding:将action value进行up-projected到1024维,然后通过一个projected的时间步编码向量concatenated到一起。结果进一步fed到另一个linear layer:对于 action value分支,将两个连续线性层(无非线性)合并为一个内核;对于时间分支,因推理时仅10个时间步,预计算线性层结果并融合至SiLU前的偏置向量,减少算子与MAC;
- QKV融合/QKV fusion:将注意力机制中Q、K、V的三个独立矩阵,合并为一个大矩阵,计算后通过张量切片拆分结果,减少内核启动次数并提升并行度;同时将RoPE操作融合进矩阵乘法,预计算RoPE权重。
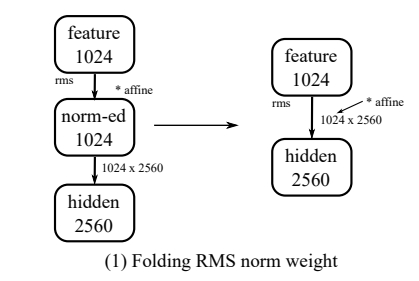 Absorbing RMS affine parameters to the next linear layer
Absorbing RMS affine parameters to the next linear layer
|
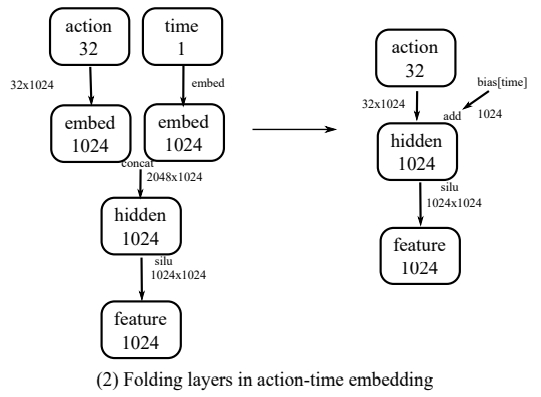 Folding linear layers in action-time embedding
Folding linear layers in action-time embedding
|
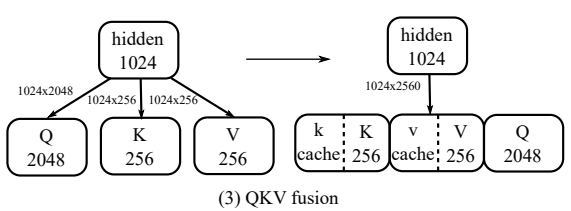 Fusing QKV as one weight matrix.
Fusing QKV as one weight matrix.
|
- 其他系统级开销优化
- 图像缩放/image resizing:选择与模型输入(224×224)接近的相机输出分辨率(如240×320),避免过度缩放;手动实现缩放代码(JAX默认实现非最优),将缩放时间压至60μs以下(x86 CPU),且不计入推理时间;
- 内存与数据传输:使用固定内存(pinned memory)优化CPU-GPU数据传输;静态化CPU缓冲区减少抖动;采用零拷贝(zero-copy)处理相机帧,降低延迟。
2. 内核深度优化/In-Depth Optimization of the Kernels
在第一步的消除基础开销后,针对模型中24个GEMM类操作及关联标量算子,进行底层优化。如下图所示(这部分是涉及到硬件底层内核,看不太懂)
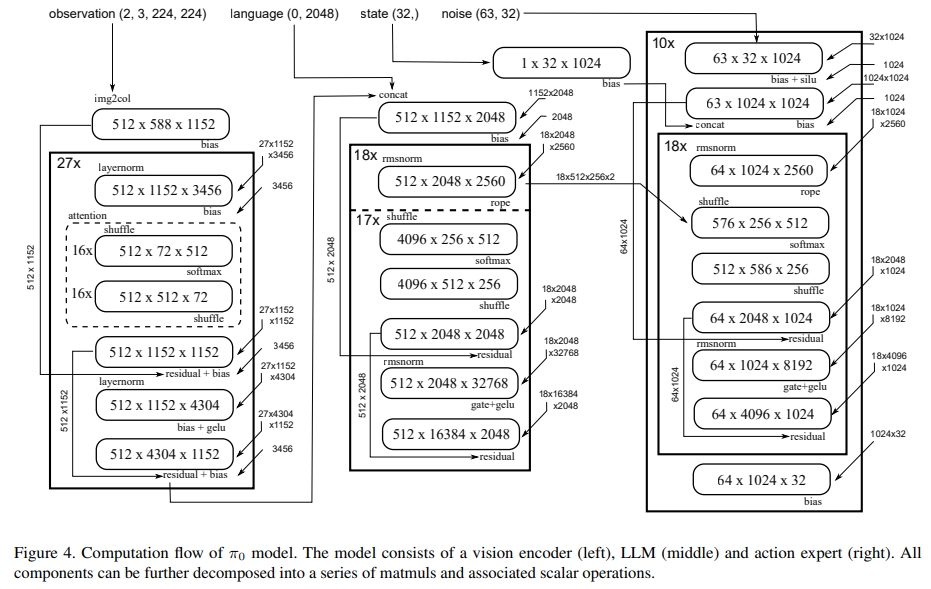
- GEMM Tile参数调优/Tuning Tile Parameters of GEMM:默认PyTorch的matmul依赖cuBLAS,但部分尺寸的GEMM未获得最优配置。通过Triton框架手动调整tile大小,匹配RTX 4090的硬件特性(128个SM)。
- 27次512×1152×3456的GEMM操作:cuBLAS耗时0.984ms,Triton(64,64,32 tile)优化至0.870ms;
- 整体通过Triton调优,累计减少1.5ms推理时间。
- 门控线性层融合/Fusing Gated Linear Layers:模型Transformer的FFN采用门控上投影结构。优化思路是:
- 并行执行两个FC层的计算,加载一次输入tile后,同步加载两个权重tile;
- 计算完成后仅写入合并结果,减少全局内存的读写操作,进一步降低延迟。这一步优化额外减少1.7ms。
- Partial Split-k优化:针对特殊尺寸GEMM(512×1152×1152):若使用64×64 tile,会生成144个块(非RTX 4090的128个SM的整数倍),导致负载不均。优化方案是:
- 将GEMM拆分为两部分:512×1152×1024(64×64 tile,适配128 SM)与512×1152×128(32×32 tile + K维度split-2);
- 两部分在单个内核中执行(无依赖),虽仅减少0.1ms,但为非对称GEMM优化提供了思路。
- 标量操作融合/Fusing the Scalar Operations:将偏置(bias)、残差连接(residual)、激活函数(如GELU、SiLU)等标量操作,直接融合进GEMM内核:
- 对RMS归一化:先计算token级统计量存入独立缓冲区,在GEMM完成后统一应用归一化因子,避免中间内存读写;
- 这一步优化减少内存占用,累计降低约4ms推理时间(Figure 2中“roofline + optimized kernels”阶段)。
3. 计算性能下界
为判断当前实现是否接近理论最优,通过“roofline模型”与“同步开销”计算性能下界:
- Roofline模型计算理论最低时间:Roofline模型通过内存带宽(RTX 4090为1.01 TB/s)和计算能力(BF16精度91.4 TMAC/s),取“内存操作时间”与“计算操作时间”的最大值作为单算子下界。
- 估算的roofline值如下所示。
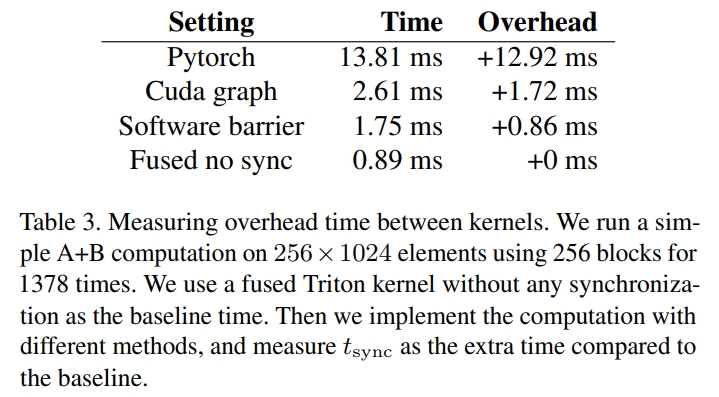
- 同步开销/Synchronization Overhead:模型包含1378个matmul算子,内核间同步会产生额外开销。通过对比实验
- 朴素PyTorch同步开销12.92ms;
- CUDA Graph同步开销1.72ms;
- 软件屏障(software barrier)同步开销0.86ms(需匹配网格大小,但代码复杂度高)。
- 最终下界与实际性能差距:叠加Roofline时间与同步开销(取0.86ms),如下图中的2views的理论下界为20.6ms,而论文实现的推理时间为27.3ms,差距仅30%,说明优化已接近硬件理论极限。

4. 全流推理框架(Full Streaming Inference)
为满足更高频率的机器人控制需求,研究提出全流推理框架(Full Streaming Inference),核心是通过“内核重叠执行”与“AE(action expert)角色重构”,实现多频率反馈环(如下图所示)。
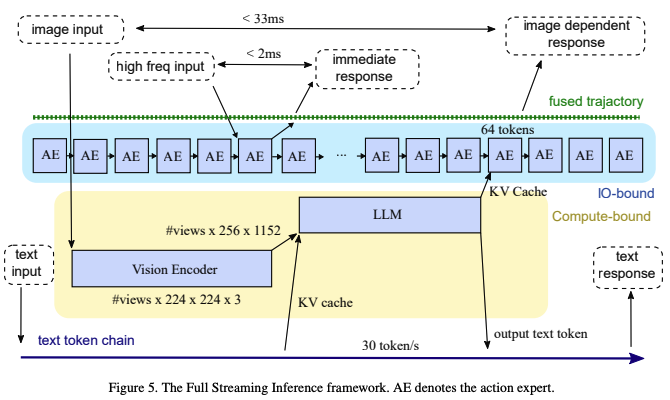
- VLM与AE的并发执行:VLM(视觉-语言模型)是计算密集型模块,AE(动作专家)是IO密集型模块,二者并发执行可最大化GPU资源利用率。
- 实验数据(如下图所示):顺序执行VLM + 10个AE需27.3ms,并发执行仅需26.3ms;
- 扩展潜力:1秒内可并行运行30个VLM(30Hz)与480个AE(480Hz),实现480Hz的轨迹生成频率(但这并不是实测的,则是理论能达到的);

- AE角色重构( Re-thinking Action Expert):从“批量输出”到“逐步生成”。传统AE需完成10步去噪流程才输出完整动作序列,无法满足高频控制。优化后:
- 借鉴实时分块(RTC)算法思路,将AE改为“逐步生成”模式:每一步生成部分动作,类似自回归解码;
- 高频传感器(力传感器2KHz+、电机电流1KHz+)数据通过独立CUDA流实时更新GPU内存,AE读取最新数据后立即调整动作,无需等待完整去噪流程;
- 输出端维护480Hz轨迹缓冲区,AE仅更新“未提交”的动作节点,“已提交”节点异步发送至执行器,确保低延迟。
- 三层反馈环设计:框架实现三个频率梯度的反馈环,覆盖不同控制需求
- 480Hz力环:AE处理高频传感器信号,响应时间低至2ms,用于紧急停止、力控制等快速反应场景;
- 30Hz视觉环:VLM每33ms处理一帧图像,生成KV缓存供AE使用,实现图像驱动的动作调整;
- <1Hz文本环:VLM加载权重时“顺带”执行LLM文本推理(30 token/s,远超人类说话速度3.3 token/s),用于任务规划、人机交互等低速智能场景。