引言
由Meta和University of Michigan发表的CVPR2025工作《Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass》实现1000多幅图像的3D重建。基于DUSt3R的多视图泛化,通过并行处理多个视图实现高效且可扩展的3D重建,速度高达 250 FPS(DUSt3R是0.78 FPS,Spann3R是65.49 FPS),并可在一次前向传递中处理 1000+ 张图像。 为此本博文对该工作进行学习并且复现,本博文仅供本人学习记录用~
理论学习
Fast3R应该是在DUSt3R上的改进,所提出的基于Transformer的结构可以在单次前向递推的时候同时处理N张图片,进而不需要迭代对齐(iterative alignment),那么既然是基于DUSt3R的改进,那么应该就是以三维重建为主,同时可估算相机的pose,并且不需要已知的相机的内参和外参(pose)。
DUSt3R是直接从RGB图像预测3D结构(无需图像的内参与外参),它把成对的重建(pairwise reconstruction)问题看成是对pointmaps的回归,并不需要相机投射投影模型。但同时,DUSt3R从原理上显示了它需要两张图像输入,而对于多张图片输入的情况,DUSt3R应该是对每对的pointmaps进行金酸然后再运行global alignment的优化处理,从而导致计算量极大。
PS:测试DUSt3R的时候会发现,比如输入10张图像,要进行90次推理运算(应该是90对图片),推理运算后,在执行全局优化。
而Fast3R则是:processes multiple images in parallel, allowing N images to be reconstructed in a single forward pass.
Spann3R应该也是有点类似的思路,增量式构建环境利用一对滑动窗口网络(sliding window network),但是对于窗口以外的是不能联合优化,进而会存在累积误差。而Fast3R all in的策略,不管输入的image多少,一起处理了
Fast3R的结构如下所示。整个模块分为image encoding,fusion transformer以及pointmap decoding。
- image encoding跟DUSt3R一样,采用CroCo ViT
- fusion transformer是计算量最大的一部分,采用12层的transformer, takes the concatenated encoded image patches from all views and performs all-to-all self-attention.
- pointmap decoding将所有的tokens映射到各自的local 和global pointmaps上
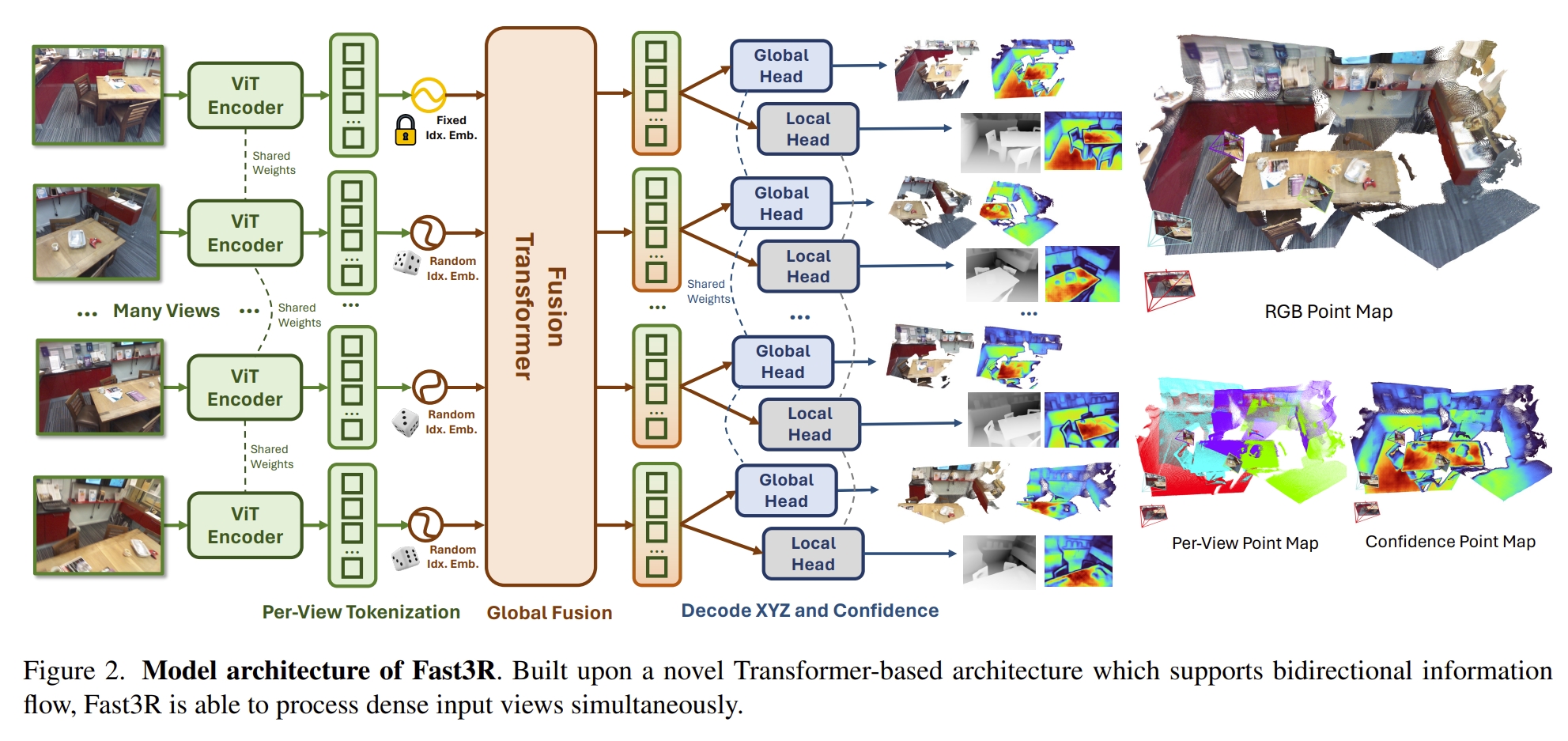
Fast3R是预测pointmap,所谓的pointmaps其实就是一张图片的每个pixel的3D位置,而预测的pointmap包括局部以及global的,同时还有对应的confidence maps

其loss如下:

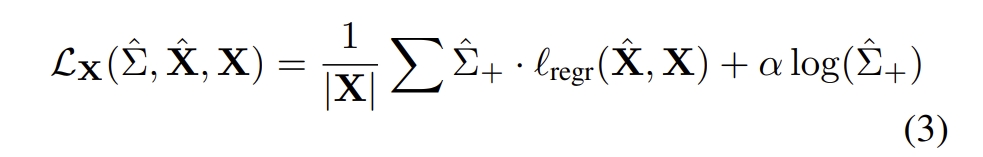
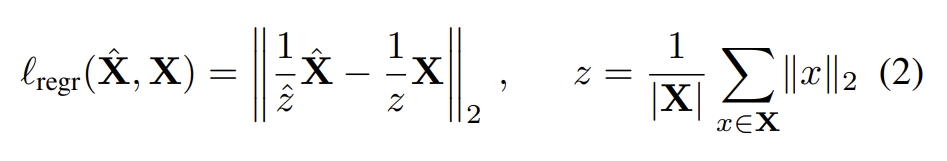
采用真实场景中扫描到的laser scan point作为真值
复现效果
作者做了个网页的demo可以实现上传图片后实时可视化三维重建的效果,下面是操作流程:

|

|
此外,还提供了比如可视化heatmap,逐帧处理以及渲染成GIF等功能

而作者在网页上也提供了一系列的样例,
用样例测试的效果如下:

|
.gif)
|
.gif)
|
.gif)
|
.gif)
此外,也尝试了用自采的数据进行测试。 首先采用一张图

接下来分别用下面两种双视角的情况测试
|

|
重建的效果如下:

|

|
接下来采用多张图片看看效果


下面是视频可视化整个操作流程
不过也尝试了下室外大场景,用的train数据集,但是效果就不如上面的测试序列了~

DUSt3R VS. Fast3R
下面对比一下单张图片输入的情况下,DUSt3R与Fast3R的效果(相同的输入)
两张图片,视角相差较小:
两张图片,视角相差较大:
在大场景下的对比