引言
近年来,人工智能领域经历了一场由“大模型”引发的寒武纪大爆发。通常我们所讨论的“大模型”,通常指的是大型语言模型(Large Language Model, LLM)和视觉语言模型(Visual Language Model, VLM)。基于这两类模型,研究界衍生出了针对机器人操作(上肢)的VLA(视觉-语言-动作)模型,以及针对移动导航(下肢)的VLN(视觉-语言导航)等系列工作。 在具身智能领域,人们试图通过”大小脑”协同架构,试图基于大模型获取的 Common Sense(常识)来实现真正意义上的智能,企图一举攻克具身智能中“感知、决策、控制、执行”的闭环难题。
【这条路真的无懈可击吗?】我们必须正视一个底层事实:LLM 仅仅是由自然语言数据(文本)训练而来的,其所获得的 Common Sense 本质上是围绕语言符号构建的抽象知识(这里引入一个哲学的思考:人类读懂了大模型生成的语言,所以所谓的Common Sense是来自于大模型还是我们人类自己呢?)。
用多了生成式语言模型(ChatGPT、DeepSeek)的朋友都会发现,它们经常出现“幻觉”——即一本正经地胡说八道。这并非单纯的技术bug,而是训练数据的本质属性决定的。正如“AI教母”李飞飞所言:
大自然中是没有语言存在的,你不会从天空中直接看到文字。
语言是一种纯粹的、人类生成的信号。
【维度压缩的问题/传统大模型与空间智能的本质差异】语言模型(LLM)及当今主流的多模态模型(VLM,MLLM),其底层表示在根本上是一维的。它们操作的是离散 Token 的一维时间序列。 但物理世界是客观存在的,是三维的、连续的。 因此,提取、理解、生成 3D 世界的数据(空间智能),与处理语言问题有着截然不同的底层逻辑。单纯依赖大语言模型来实现物理世界的“真智能”,这条路或许存在本质上的谬误(或者说局限性)。 真正的智能应当是信号感知、物理法则与现实世界深度交互的产物。
【从控制理论视角的降维打击】VLM等多模态大模型虽然引入了视觉,而非纯粹的语言模型,但其局限于“文本-2D图像”的训练与对齐。这里存在一个核心拷问:只看过 2D 平面投影的模型,凭什么具备三维空间的理解能力? 笔者出身于传统机器人流派,如果从控制理论中经典的能控性(Controllability)与能观性(Observability)角度出发,这个问题便一目了然:
- 不可观(Unobservable): 对于三维物理空间而言,2D 图像仅仅是降维的投影。试图仅从 2D 数据全量恢复 3D 状态,在数学上往往是病态(Ill-posed)的。如果不引入 3D 先验或显式的 3D 表征,VLM/LLM 对于三维环境本质上是“不可观”的。
- 不可控(Uncontrollable): 系统若不可观,则自然难以实现精确的闭环控制。即便强行引入 2D 数据,对于三维物理空间的精准感知与交互,依然是力所不能及。
此外,现有的多模态大模型往往采取一种“硬塞”的策略——将视觉、听觉等模态强行压缩进语言模型的一维 Token 序列中。这种由人类语言主导的低维表示,极大概率无法完备地映射高维的物理世界,造成严重的信息熵损失。
【走向 Spatial Intelligence与通用3D基础模型】正因如此,世界模型(World Model)与空间智能(Spatial Intelligence)的概念应运而生。 空间智能的核心挑战,在于如何从真实世界中直接提取、表示并生成三维信息,而非经过语言的转译。
需要厘清的是,虽然技术层面上(如 Transformer 架构、Scaling Law)空间智能可以借鉴语言模型,但从哲学范畴看,两者存在本质差异。大量实验已证明,基于纯语言信号训练的模型在物理世界任务中表现并未达到预期(依赖语言模型的所获得的能力并不等同于具备物理世界的空间智能,更不应是具身智能的目标)。因此,构建能理解物理法则、几何结构的模型,被誉为机器人走向真正智能的关键。
虽然广义的 World Model 也宣称学习空间物理特性,但目前业界的主流方向更多聚焦于“生成式视频”,侧重于视觉上的时序预测。空间智能需要的不仅是视频生成能力,而是对三维空间的精确建模与推理能力(通过整合三维感知、推理与动作控制能力,实现机器人与物理世界的深度交互)。
本博文打算更进一步,聚焦于Spatial Foundation Model(通用 3D 基础模型)。
正如 LLM 彻底改变了 NLP 领域,构建具备 3D 感知、理解与生成能力的通用模型(例如近期的 VGGT 等),正在成为 3D 视觉与具身智能领域的新范式。 为此,本博客将系统梳理这一前沿方向,从 Transformer-based SLAM 到通用的 3D 基础模型,探讨我们如何赋予机器真正的“空间智慧”。
- Transformer-based SLAMPaper List
- Awesome VLAPaper List
- Awesome VLNPaper List
- 论文阅读笔记之《MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors》
- 论文学习及实验笔记之——《VGGT: Visual Geometry Grounded Transformer》
三维视觉新范式:Spatial Foundation Models的崛起与应用
在计算机视觉领域,三维重建技术正经历一场革命性变革。从传统的多视图几何方法到基于深度学习的端到端前馈模型,我们见证了从耗时数小时到实时几秒的性能飞跃。这一转变的核心驱动力是Spatial Foundation Models(SFM,空间基础模型)的兴起,它们通过大规模预训练和几何先验融合,为3D视觉任务提供了一种全新的统一解决方案。正如大型语言模型彻底改变了自然语言处理领域,这些3D基础模型正在重塑我们理解与感知三维世界的方式,为机器人导航、增强现实、自动驾驶等应用开辟了新可能。
SFM定义与重要性
Spatial Foundation Models(SFM)是近年来兴起的一种新型3D视觉模型,它通过在大规模3D标注数据集上进行预训练,获得对三维场景的理解与重建能力。与传统方法不同,SFM采用端到端的前馈网络架构,无需依赖复杂的几何优化后处理,如光束法平差(Bundle Adjustment)或点云配准等步骤。这种设计使模型能够直接从输入图像中推断出完整的3D属性,包括相机参数、深度图、点云和三维点轨迹等,从而大幅提高了重建速度和易用性。
SFM的重要性体现在三个方面:
- 首先,它简化了3D视觉任务的复杂流程。传统三维重建方法通常需要多阶段处理,如特征提取、匹配、三角化、位姿估计和优化等,每个环节都可能引入误差并增加计算负担。而SFM通过单一模型直接预测所有相关3D属性,大大减少了系统复杂性和潜在的误差累积。例如,在处理100张图像时,传统方法需要先提取特征、匹配、三角化、BA优化等多个步骤,总耗时可达数分钟甚至数小时;而SFM模型(如VGGT)仅需一次前馈传播,即可在1秒内完成所有预测,且无需额外优化步骤。
- 其次,SFM具有强大的泛化能力。通过在大量多样的数据集上预训练,这些模型能够适应各种未见过的场景,从室内环境到自然景观,甚至处理极端光照条件或低纹理区域。例如,VGGT在RealEstate10K数据集上的表现优于其他模型,证明了其”看懂”三维世界的通用能力。更重要的是,SFM的泛化能力不仅限于静态场景,还能扩展到动态场景。如VGGT4D框架通过时间窗口聚合和投影梯度优化,实现了动态物体的准确分割与重建,支持500+帧长序列,在TUM RGB-D数据集的
tum-rgbd-ive场景中,分割AJ指标达72.1%,运动轨迹跟踪成功率94.3%,优于CoTracker(AJ 67.4,成功率89.2)。 - 最后,SFM为下游任务提供了统一的特征表示。这些模型提取的3D特征可以作为多种应用的基础,如新视角合成、动态点跟踪、场景理解等,无需为每个任务单独训练模型。这种”一次训练,多任务应用”的特性大大降低了3D视觉应用的开发成本和时间。例如,VGGT的预训练特征可直接用于非刚性点追踪和新视角合成等下游任务,无需额外微调,显著提升了这些任务的性能。
从DUSt3R到VGGT的技术演进
近年来,3D 视觉领域正经历一场从“几何显式约束”到“神经网络端到端回归”的范式转变。这一变革的先锋是由 Naver Labs Europe 开启的 DUSt3R 系列,并由 Oxford VGG 与 Meta 合作推出的 VGGT 推向了新的高度。这一技术路线彻底改变了运动恢复结构(SfM)的传统流程,将复杂的几何求解问题转化为高效的 Transformer 回归问题。
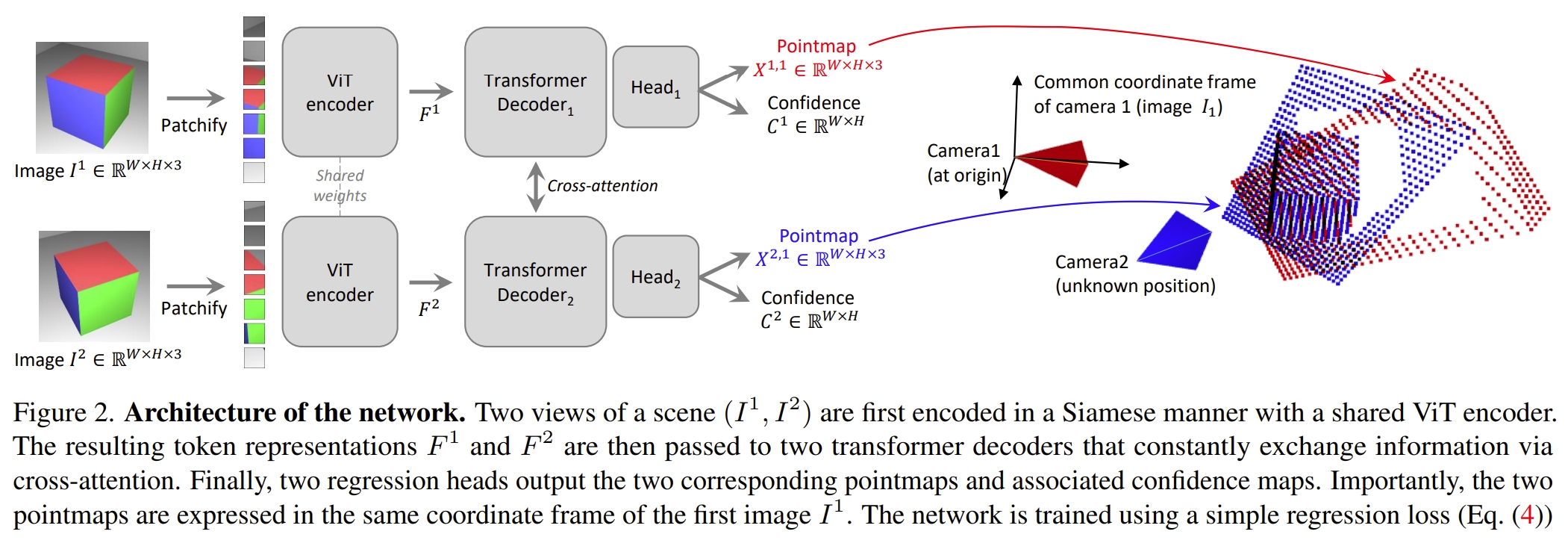
DUSt3R(2024年)作为这一领域的奠基者,它的出现标志着 3D 重建进入“前馈时代”。
- 核心创新:它首次证明了纯前馈 Transformer 可以在完全不依赖相机内参或外参的情况下,仅通过两张图像直接回归出 3D 点图(Pointmaps)。虽然输入不需要提供相机参数,但模型通过隐式学习机制(如点云中心化和尺度估计)间接估计这些参数,实现了端到端的几何推理。
- 技术深度:DUSt3R 将重建任务视为一个图像块(Patch)匹配与空间投影的联合学习过程。其输出不仅包括每张图的 3D 坐标,还包含一个置信度图(Confidence Map),用于在后续的全局对齐过程中过滤噪声。模型采用对称编码器-解码器架构,通过交叉注意力机制交换信息,确保所有点图都统一在第一帧相机坐标系下,为多视图融合奠定基础。
- 局限性:DUSt3R 主要针对双视图(Pairwise),在处理多视图大规模场景时,其内存开销呈平方级增长。此外,它缺乏显式的特征匹配引导,在低纹理区域或大视差场景中重建精度受限。虽然能处理超过两张图像,但需依赖两两配对的全局对齐策略,难以高效扩展。
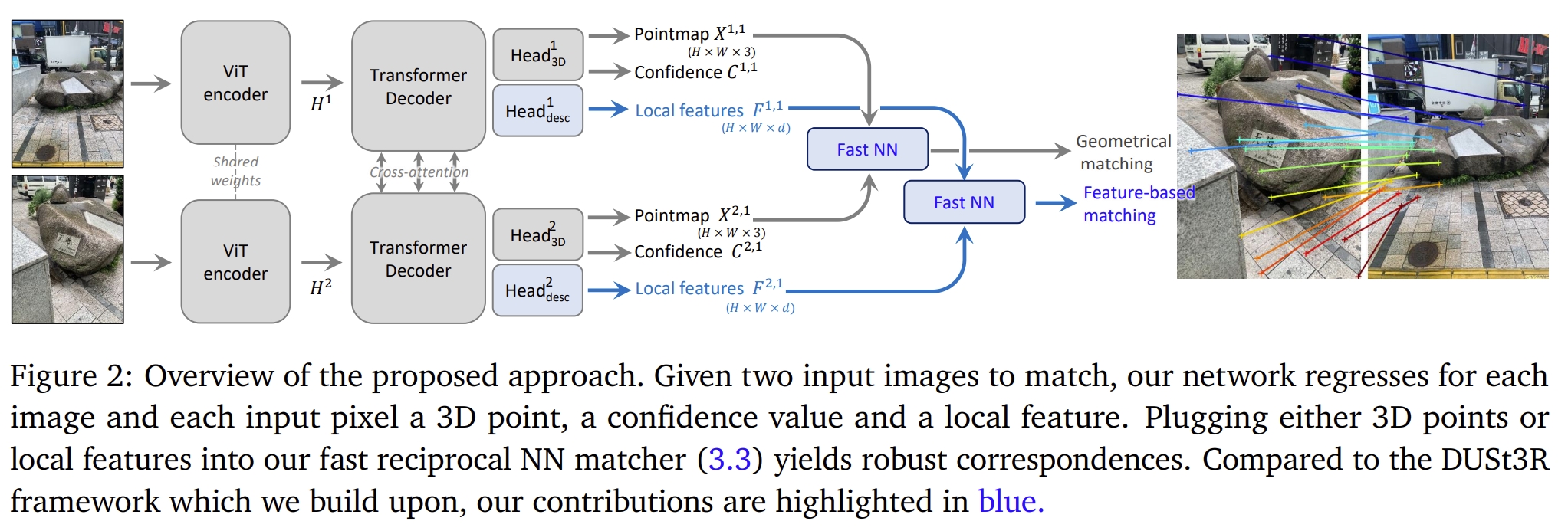
MASt3R(2024年)是对 DUSt3R 的针对性升级,旨在解决多视图一致性与匹配精度问题。
- 核心创新:在 DUSt3R 的基础上引入了特征对齐(Matching)。
- 技术深度:MASt3R 不再仅仅回归坐标,它同时学习具有几何意义的局部描述子。模型在极端视角变化下,其匹配能力远超传统的 SIFT 或 SuperPoint。
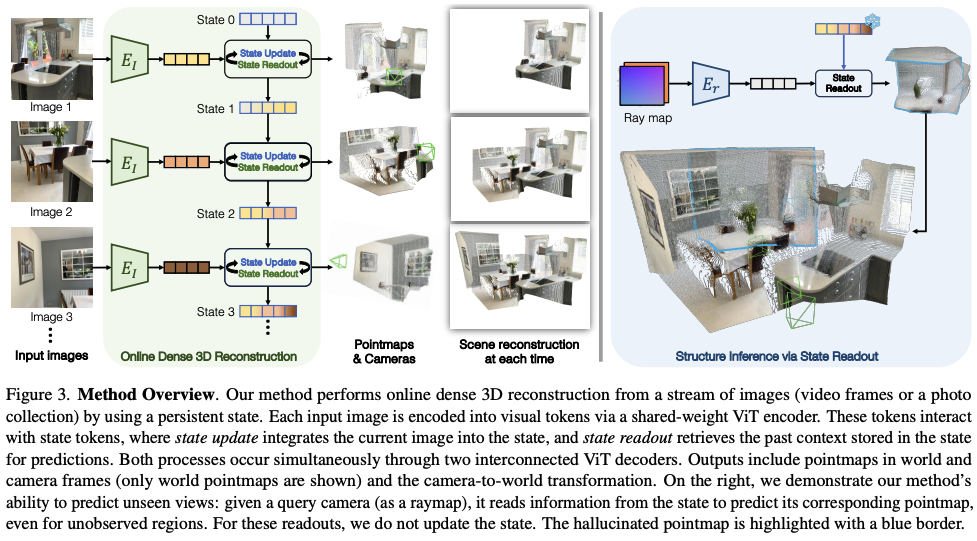
CUT3R(2025年)解决了该系列模型在处理连续视频流时的“遗忘”与“计算冗余”问题。
- 核心创新:将原本静态的 Transformer 架构转变为递归式(stateful recurrent model)架构,通过维护内部3D状态实现增量式更新,无需重新计算整个序列。
- 技术深度:通过引入有状态的 Transformer,CUT3R 能够维持一个内部的 3D 空间表征。当新帧进入时,模型仅需增量式地更新状态,而无需重新计算整个序列。这赋予了 DUSt3R 家族处理 SLAM(实时定位与建图)任务的能力,真正实现了 3D 重建的实时化。
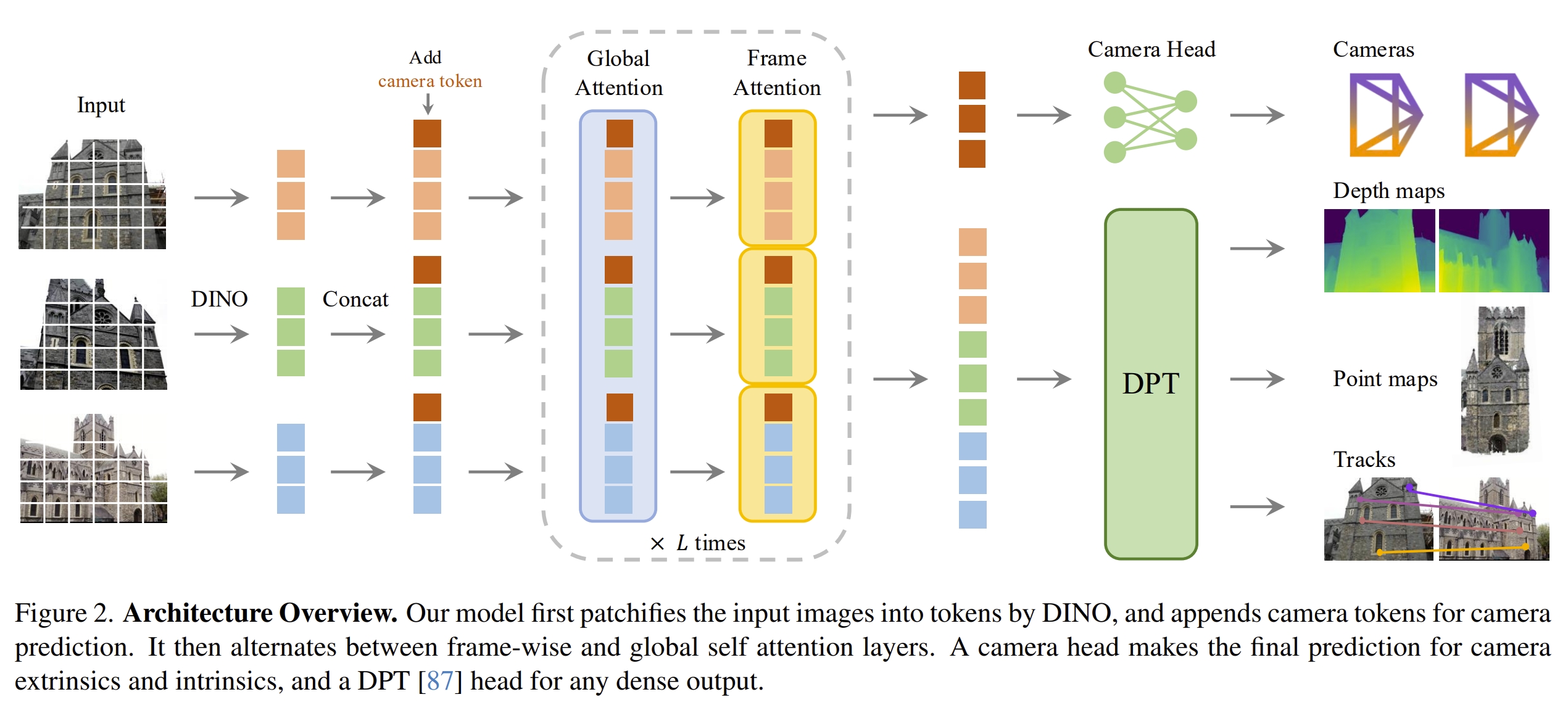
VGGT(2025年)代表了SFM技术路线的最新突破,由牛津大学视觉几何组(VGG)与Meta AI联合开发。作为CVPR 2025的最佳论文,是通往通用视觉几何的大统一。
- 核心创新:引入了交替式注意力(Alternating Attention)机制,实现了处理图像数量从 2 张到数百张的跨越式突破。
- 技术深度:
- 交替注意力机制:通过帧内自注意力(提取单图局部特征)与全局自注意力(跨图建立对应关系)交替处理,逐层降低特征维度,避免显存爆炸。这种设计将内存复杂度从平方级(O(N²))降至线性(O(N)),支持单次处理200+图像。
- 无交叉注意力设计:完全依赖自注意力机制,简化架构设计并提高计算效率。模型为每张图像添加专门的相机token和注册token,第一帧使用特殊可学习token区分参考坐标系,确保统一坐标系下的3D预测。
- 多头预测架构:包含四个独立预测分支(相机头、深度头、点云头和跟踪头),通过冗余预测提升整体精度。实验表明,同时预测深度图和相机参数比仅预测点云头更准确,体现了多任务学习中任务间相互促进的效应。
SFM在SLAM领域的应用前景
笔者投身于机器人感知与SLAM(同步定位与地图构建)领域的研究已近十载。这十年间,我完整见证了行业从经典滤波器(Filter-based)到因子图优化(Factor Graph Optimization),再到如今深度学习框架(Learning-based)的迭代;目睹了感知粒度从稀疏特征点向稠密直接法的演进,以及从单模态视觉/雷达到多模态深度融合(Multi-sensor Fusion)的技术变迁。
然而,Spatial Foundation Model (SFM) 的横空出世,让我们确信 SLAM 领域正处于一场前所未有的范式转移之中。它为 SLAM 带来的不仅仅是性能指标的线性提升,更是一场关于“感知维度”的降维打击与跨越。
SLAM与机器人感知的再定义:从“定位”到“空间认知”
近年来,随着端到端大模型的兴起,业界出现了一种声音,认为“SLAM在具身智能时代的需求将逐渐弱化”,甚至最终会被大模型完全吞噬。对此,我深不以为然。 SLAM 的本质绝不仅仅是绘制一张离线地图或计算一组坐标坐标,它是机器人建立“自我”与“物理世界”关联的唯一数学桥梁,更是实现空间智能(Spatial Intelligence)的底层基座。 我们可以将机器人的感知能力解构为三个核心层级,而在每一个层级中,SLAM 都扮演着不可或缺的角色:
- 环境感知(建图)——静态空间认知。此部分又分为以下几点:
- 几何结构: 涵盖基础的 2D 占据栅格(Occupancy Grid)、2.5D 高程图(Elevation Map)以及 3D 点云或体素地图。它们共同构成了机器人移动的物理边界。
- 语义信息(Semantic SLAM): 赋予几何元素以逻辑意义。它不仅要识别物体,更要划分区域属性(如区分“可通行地毯”与“不可通行玻璃墙”),让机器人实现从“看见”到“看懂”的跨越。
- 纹理信息:高保真三维重建与数字孪生。这为具身智能提供了逼真且符合物理定律的离线训练与仿真环境(Simulation to Real)。
- 自身感知(定位)——机器人状态估计。
- 这并非简单的定位坐标输出,而是对机器人本体状态的全面估计(State Estimation)。它包含了位置、姿态、速度、加速度以及传感器外参的实时标定。从控制理论的角度看,没有高频且精准的自身感知,具身智能的决策与控制便如同空中楼阁,无法实现真正意义上的闭环。
- 物体感知(Object SLAM、Dynamic SLAM)——时空建模。
- 真实世界是动态且演化的。这要求感知系统具备对行人和移动物体的检测、跟踪及运动状态估计(MOT)。通过 4D SLAM 构建动态时空模型,机器人才能在复杂的动态环境中完成避障与交互。
贯通“大小脑”:SFM 是 SLAM 的新一代进化形态
SLAM 本质上是为了解决机器人“在哪里”和“周围有什么”的感知难题,它是实现自主移动与智能决策的先决条件。 SFM本质上是SLAM的一种技术手段,它的出现,给SLAMer解决传统技术所不可及的一些难点。SFM的出现,亦并非要取代传统SLAM,而是作为一种更高级的技术手段,解决了传统几何方法难以攻克的问题。它是SLAMer将机器人感知从“纯几何计算”推向“多模态认知”的关键节点。
如果用人体来做类比:
- VLA(视觉-语言-动作) 旨在训练机器人上肢操作(Manipulation)的灵巧性;
- VLN(视觉-语言导航) 旨在赋予机器人下肢移动(Navigation/locomotion)的逻辑性;
- SLAM 则是贯穿机器人“大小脑”的中枢神经。
传统 SLAM 擅长提供高精度的度量信息,但在语义理解上往往是“文盲”;大模型(LLM、VLM)擅长逻辑与语义,但在空间尺度感上却是“瞎子”。 SFM 的出现,完美填补了“度量”与“语义”之间的鸿沟。它是SLAMer将机器人感知从单纯的“几何计算”推向“多模态认知”的关键节点。 通过SFM,SLAMer可以构建“轻地图,重感知”的新一代导航新范式。在这个意义上,SLAMer的角色正在发生蜕变:SLAMer不再仅仅是优化因子图的工程师,而是空间智能架构师,负责构建连接物理世界(Sensors)与数字认知(Foundation Models)的桥梁。
SFM于SLAM的技术演进
未完待续
未来发展方向与技术挑战
尽管SFM取得了显著进展,但这一领域仍面临诸多挑战,同时也蕴含着丰富的未来发展方向。
- 多模态融合。当前的SFM主要基于RGB图像,无法充分利用深度、激光雷达、IMU等其他传感器提供的信息。未来的多模态SFM应解决以下问题:
- 跨模态对齐:如何将RGB图像与LiDAR点云、IMU数据等进行几何对齐。将不同传感器人的信息逐步注入基础模型,不破坏原有特征空间。
- 信息权重分配:不同模态在不同场景下的贡献率动态变化。例如,在光照不足的场景中,LiDAR的几何信息可能比RGB图像的纹理信息更重要;而在快速运动场景中,IMU的运动信息可能比视觉信息更可靠。
- 联合训练策略:如何在预训练阶段整合多模态数据,使模型能够自动学习模态间的关联关系。
- 轻量化与边缘部署。 轻量化与边缘部署是SFM落地应用的关键瓶颈。VGGT等大型模型需要较高的计算资源,难以在无人机等边缘设备上实现实时运行。未来的轻量化方向包括:
- 模型压缩技术:如HTTM、INT8量化、模型蒸馏等。
- 硬件加速:结合边缘设备的专用硬件(如Jetson AGX Xavier的Tensor Core)优化计算效率。
- 分布式推理:将大规模重建任务分配到多个计算节点,实现并行处理。
- 动态场景处理。尽管VGGT4D等模型在动态场景重建方面取得了进展,但复杂动态环境下的3D感知仍然不够准确。未来的动态场景处理方向包括:
- 运动线索挖掘:通过更精细的时序分析,捕捉物体运动模式。
- 物理引擎整合:引入物理规律约束,如运动学、动力学等,提升动态场景的重建鲁棒性。
- 非刚性形变建模:处理如人体、布料等非刚性物体的形变,扩展SFM的应用范围。
- 几何先验的显式编码。当前的SFM主要通过数据驱动隐式学习几何约束,而显式编码几何先验可能进一步提升模型的准确性和鲁棒性。未来的几何先验编码方向包括:
- 对极几何约束:在Transformer架构中引入极线几何约束,强制模型遵循物理几何规律。
- 三角化原理:将多视图三角化原理融入模型设计,提升深度估计的准确性。
- 投影一致性损失:设计投影一致性损失函数,强制模型输出的3D点在不同视图下的投影与输入图像一致。
结论与展望
SFM代表了3D视觉领域的最新范式,它们通过端到端的前馈网络架构和大规模预训练,实现了从传统几何方法到深度学习模型的范式转变。VGGT等模型不仅在重建速度上取得了质的飞跃,还在重建精度和泛化能力上达到了新的高度,为SLAM、机器人操作、4D重建等应用提供了强大的基础。
然而,SFM的发展仍处于初级阶段,面临着多模态融合、轻量化部署、动态场景处理等技术挑战。未来,随着模型架构的优化、训练数据的丰富和应用场景的拓展,SFM有望成为3D视觉领域的通用基础模型,为各种应用提供统一的3D感知能力。
在实际应用中,SFM与传统方法的结合可能是最佳路径。例如,SFM的前馈预测可以作为传统SLAM的初始化步骤,而与传统几何优化/图优化等方法结合可以进一步提升精度或泛化能力。这种策略,或许是SFM的边端部署的最优解。
总之,SFM正在重塑我们理解与感知三维世界的方式,为机器人导航、增强现实、自动驾驶等应用开辟了新可能。随着技术的不断进步,未来的空间智能基础模型将能够像人类一样,自然地理解并作用于三维环境,推动人工智能向更高级的通用智能迈进。
空间基础模型的崛起,将彻底改变我们理解与感知三维世界的方式,为人工智能的未来发展开辟新的可能性。