引言
近年来,基于learning的VO可以说是非常火热的,从用learning来代替VO中某个模块(如Superpoint,SuperGlue)等,到end-to-end的learning framework,再到learning建立相邻帧的data association(如RAFT,Droid-SLAM,DPVO),再到基于两视觉的三维匹配(如MASt3R-SLAM)。
最近,一个基于Reinforcement Learning的VO实现了RL首次在SLAM问题的应用,其本质应该是,将VO问题重新定义为连续决策任务,然后用强化学习(Reinforcement Learning,RL)来动态调整VO的流程。
minimizing the reliance on heuristic design choices while increasing the generalizability across diverse scenes and motions
个人感觉是非常有意思且具备突破性的,本博客为本人学习记录用~
理论解读
通过设计一个神经网络(作为VO的agent)来对keyframe以及grid-size等选择来进行决策。 同时利用pose error、运行时间以及其他指标来作为reward function,从而使得VO的设计更少的用到经验是的启发式设计(heuristic design)。 RL framework把VO系统以及图像序列都看成是环境,agent通过关键点、地图统计信息(size of the map)、先验姿态来作为对环境的观测。
比如下图所示。图像输入到VO模块中得到估算的pose,估算的pose与真值求误差作为奖励函数给到agent。同时agent还以关键点(特征点?)和地图统计信息等作为观测量。agent输出keyframe以及grid-size的选择来指导VO模块。 当然理论上说,除了关键帧的选择以外,所有的超参都可以有agent来指导(比如论文《Efficient Camera Exposure Control for Visual Odometry via Deep Reinforcement Learning (RAL2024)》则是对图像曝光度进行控制)
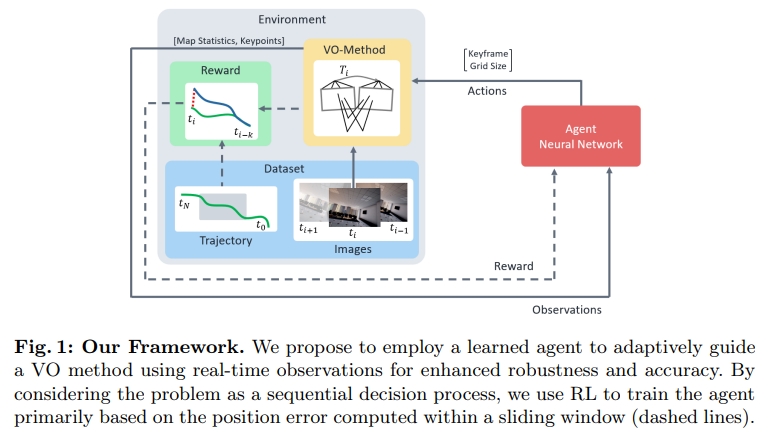
agent对VO模块的action:selecting keyframes and adapting the keypoint distribution by setting the grid size constraint (a grid is fitted to the image, and maximum one keypoint per grid cell is selected)也就是关键帧的选择以及grid-size的选择。至于所谓的grid-size选择应该就是控制特征点的均匀化了~
而基于这些action,VO继续处理图片并估算对应的pose。
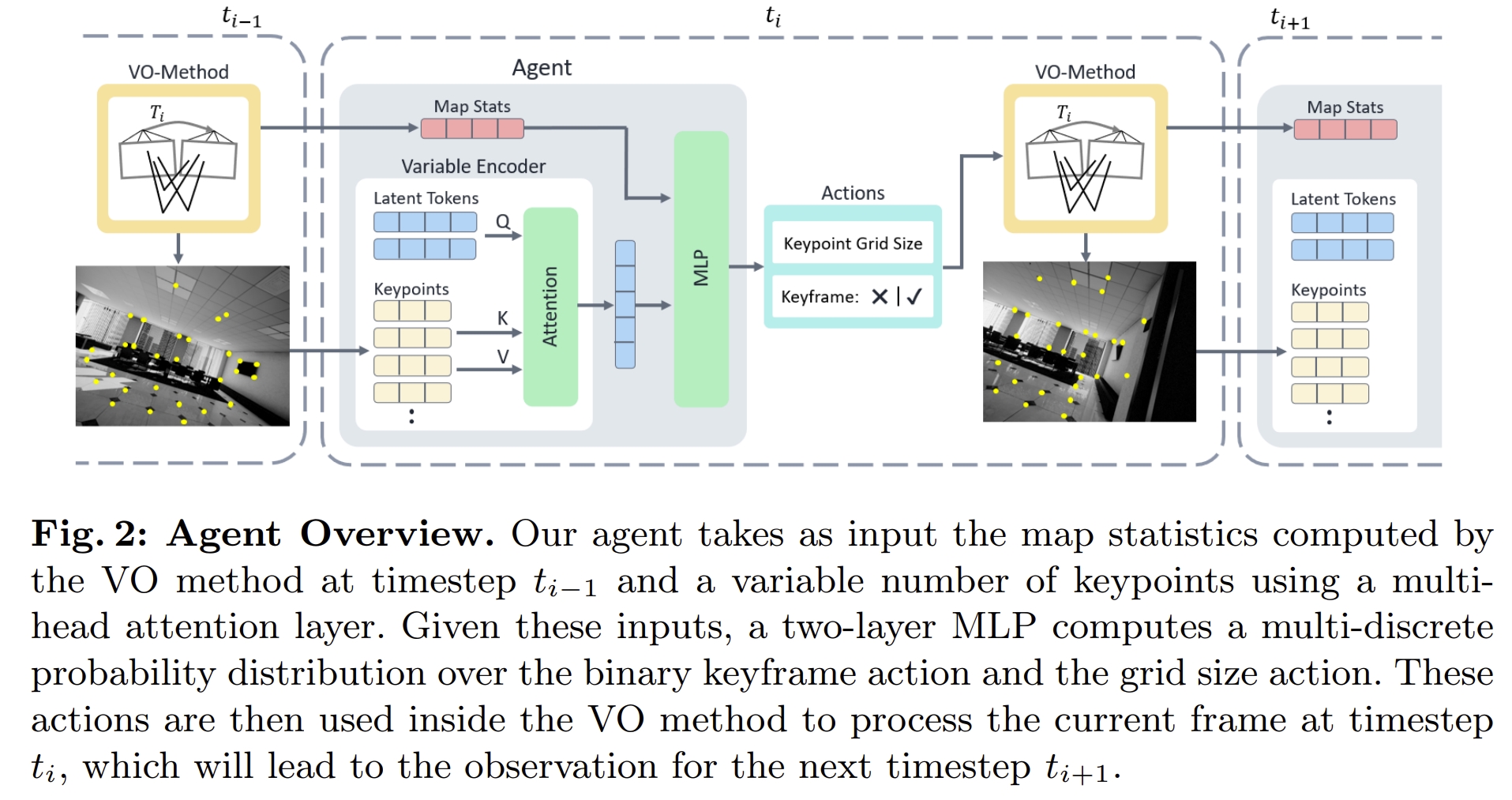
agent的结构如下图所示。通过multi-head attention layer来将keypoint下投影成一系列的feature然后放到两层的MLP中。 训练过程采用on-policy RL algorithm Proximal Policy Optimization (PPO)以及privileged critic network来让训练更加稳定
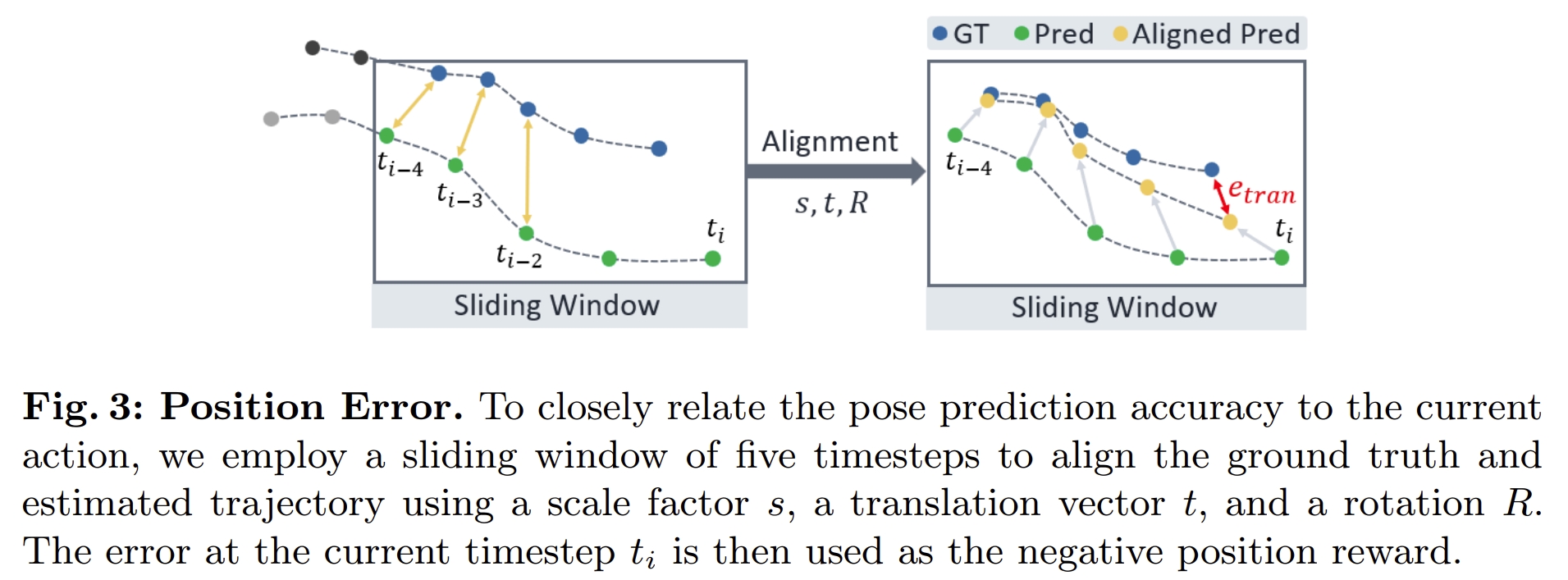
至于reward function,主要就是pose error,但由于单目的VO是没有尺度的,因此需要将预测的姿态与GT进行尺度对齐,因此,作者采用一个基于滑动窗口的Umeyama方法,如下图所示
此外通过添加keyframe action作为惩罚项来实现integrate non-differentiable performance feedback into the reward system
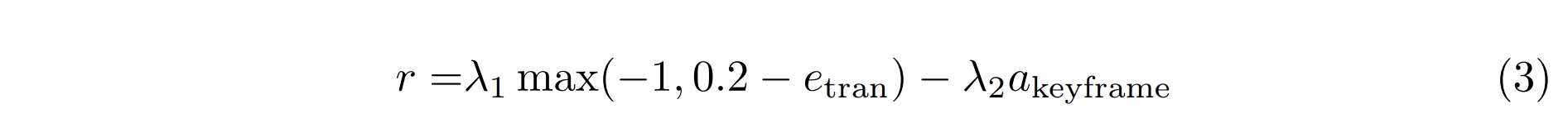
至于VO系统,论文中分别采用了SVO,DSO和ORB-SLAM3
训练也是采用TartanAir,而测试的训练是真实数据,因此泛化能力应该还是不错的~
实验效果
首先VO的初始化是要用ground truth pose的
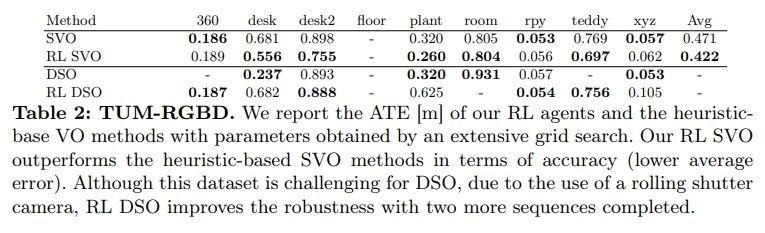
下图可以看到分别跟baseline(SVO和DSO)以及DPVO、DROID-VO等方法的对比效果
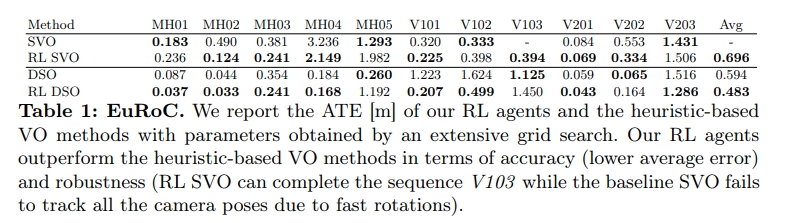
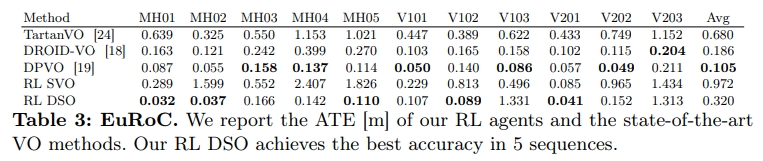
而在tum数据集效果上应该是不如droid-vo以及dpvo的
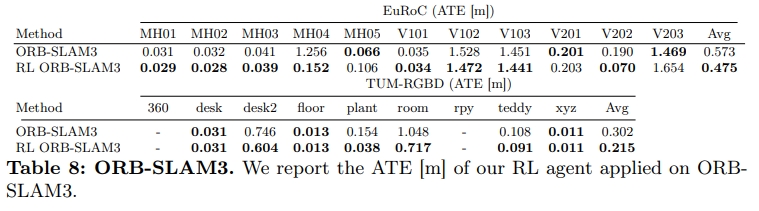
作者也尝试了用ORB-SLAM3作为VO baseline来对比
至于youtube视频中展示的FPV数据集也是没有测试的,应该是跑不起来,只能测试比较简单的euroc和tum序列

局限性
作者在论文对局限性也进行了分析~
首先是需要VO模块能够较好的工作,例如VO是不能failed的,不然就没法给RL好的reward。
这大概就是作者说的difficulty of the TartanAir sequences used for training,有些太难的序列SVO或者DSO可能本身就failed掉了,这就没法提供一个好的reward,都是差的reward
此外对于训练数据中没有出现过的运行patterns也没法handle,甚至连静止都是不行的。