引言
之前博客对Transformer进行了基本的学习(从NLP到CV),鉴于Transformer强大的数据(时间与空间维度)关联能力,个人感觉其在SLAM问题上应该是有不少的应用空间的,为此写下本博文,记录本人调研收集的Transformer-based SLAM,visual odometry, mapping(depth estimation)以及optical estimation
本博文仅供本人学习记录用~
- 引言
- Paper List
- Paper Reading
- Causal Transformer for Fusion and Pose Estimation in Deep Visual Inertial Odometry
- Transformer-based model for monocular visual odometry: a video understanding approach
- DUSt3R与MASt3R系列
- MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors
- Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass
- VGGT: Visual Geometry Grounded Transformer
- SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
- Dynamic Point Maps: A Versatile Representation for Dynamic 3D Reconstruction
- MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
其他相关链接:
Paper List
- 注意,此处非最新版,仅仅是写此博客的时候的记录
- Keep update the paper list in: Awesome-Transformer-based-SLAM
Transformer-based SLAM
| Year | Venue | Paper Title | Repository | Note |
|---|---|---|---|---|
| 2025 | CVPR |
MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors |  |
Website Test |
| 2022 | ICARM |
Tlcd: A transformer based loop closure detection for robotic visual slam | — | just transformer for feature detection |
| 2022 | ECCV |
Jperceiver: Joint perception network for depth, pose and layout estimation in driving scenes |  |
CCT Module is very similar to Transformer |
Transformer-based Pose Tracking
Transformer-based Pose Tracking




Transformer-based Optical Flow
| Year | Venue | Paper Title | Repository | Note |
|---|---|---|---|---|
| 2023 | arXiv |
Win-win: Training high-resolution vision transformers from two windows | — | — |
| 2023 | arXiv |
Flowformer: A transformer architecture and its masked cost volume autoencoding for optical flow | — | — |
| 2023 | CVPR |
FlowFormer++: Masked Cost Volume Autoencoding for Pretraining Optical Flow Estimation |  |
— |
| 2023 | CVPR |
Transflow: Transformer as flow learner | — | — |
| 2022 | CVPR |
Craft: Cross-attentional flow transformer for robust optical flow |  |
— |
| 2022 | CVPR |
Learning optical flow with kernel patch attention |  |
— |
| 2022 | CVPR |
Global Matching with Overlapping Attention for Optical Flow Estimation |  |
— |
| 2022 | CVPR |
Flowformer: A transformer architecture for optical flow |  |
— |
Transformer-based Mapping

















Other Resources
- Awesome-Transformer-Attention
- Dense-Prediction-Transformer-Based-Visual-Odometry
- Visual SLAM with Vision Transformers(ViT)
- Awesome-Learning-based-VO-VIO
- Some basic paper in ViT:
| Year | Venue | Paper Title | Repository | Note |
|---|---|---|---|---|
| 2021 | ICML |
Is space-time attention all you need for video understanding? |  |
ViT+CNN,TimeSformer |
| 2021 | ICCV |
Vivit: A video vision transformer |  |
— |
| 2020 | CoLR |
An image is worth 16x16 words: Transformers for image recognition at scale |  |
ViT |
Paper Reading
接下来重点阅读几篇论文
Causal Transformer for Fusion and Pose Estimation in Deep Visual Inertial Odometry
见上面表格`Transformer-based Pose Tracking`
很多的相关工作其实都是用transformer来进行多传感器融合(比如多个camera,camera与imu,camera与depth/lidar)
当前大部分的基于learning的VIO都是采用RNN来对时序进行建模。而Transformer对时序信号的强大的建模能力,可以作为RNN的替代来进一步提升VIO的精度和鲁棒性。
如下图所示,先通过两个网络将图像和IMU投影成Latent Vector,而Transformer来实现两个数据的融合以及位姿的估计。
而采用的Transformer结构就是采用ViT《An image is worth 16x16 words: Transformers for image recognition at scale》的结构(没有分类的token以及不以图像patch的形式)
至于监督,从图上来看似乎是监督rotation,然后用RPMG来进行梯度的反向传播。
所谓的RPMG应该就是论文中提到的Riemannian manifold optimization,不采用欧拉角或者四元数来监督,而是采用Riemannian manifold optimization来让网络更好的学习rotation
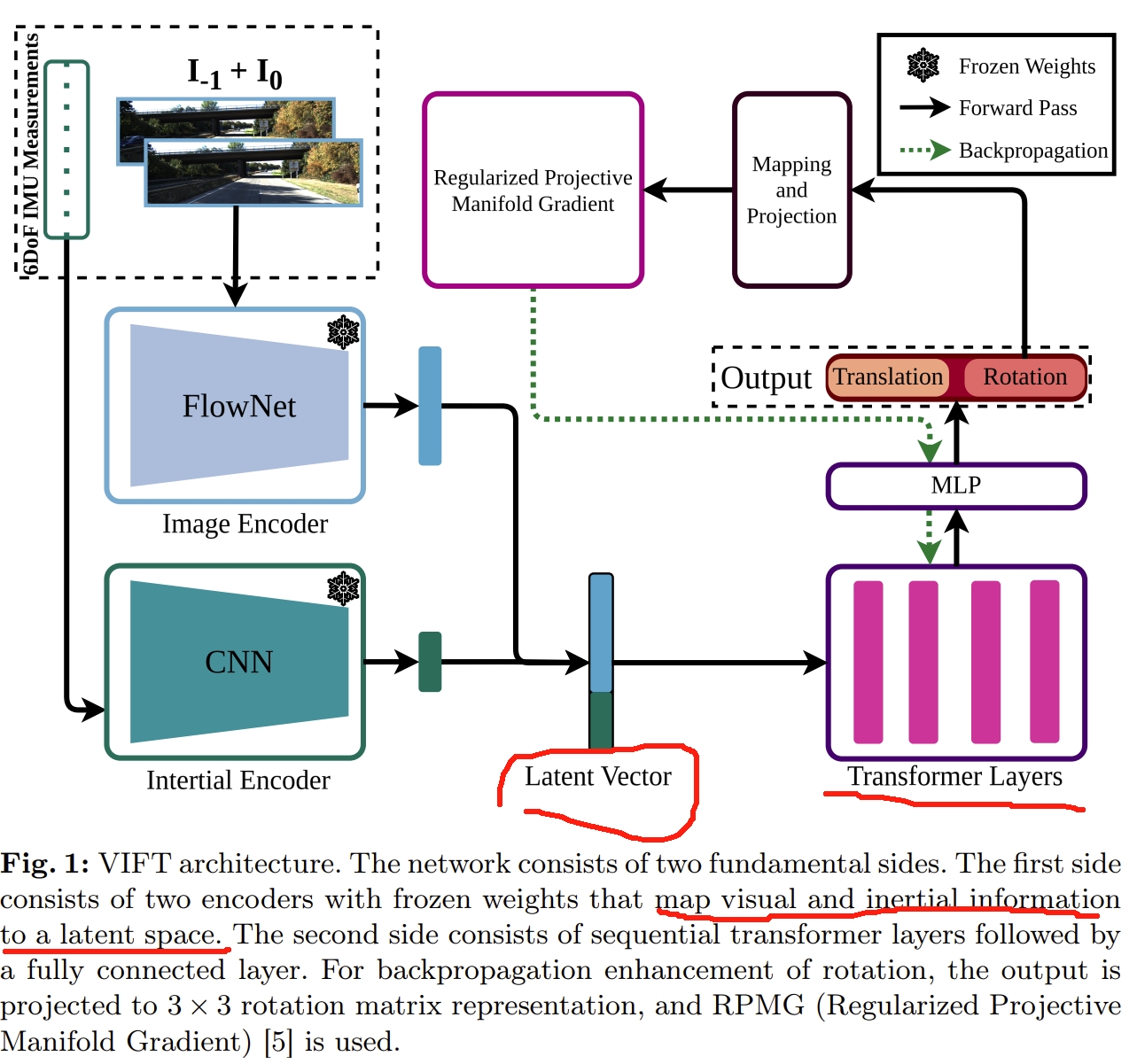
- 更正,后续loss function可以看到,监督是同时监督rotation和translation的,只是对于rotation用的是旋转矩阵,而不是欧拉角或者四元数

这篇工作采用的结构与思路其实跟ECCV2022的Efficient deep visual and inertial odometry with adaptive visual modality selection很类似,如下图所示。该工作采用的是LSTM进行融合,此处改为Transformer,当然Visual-Selective-VIO的监督loss是考虑了translation和rotation的.
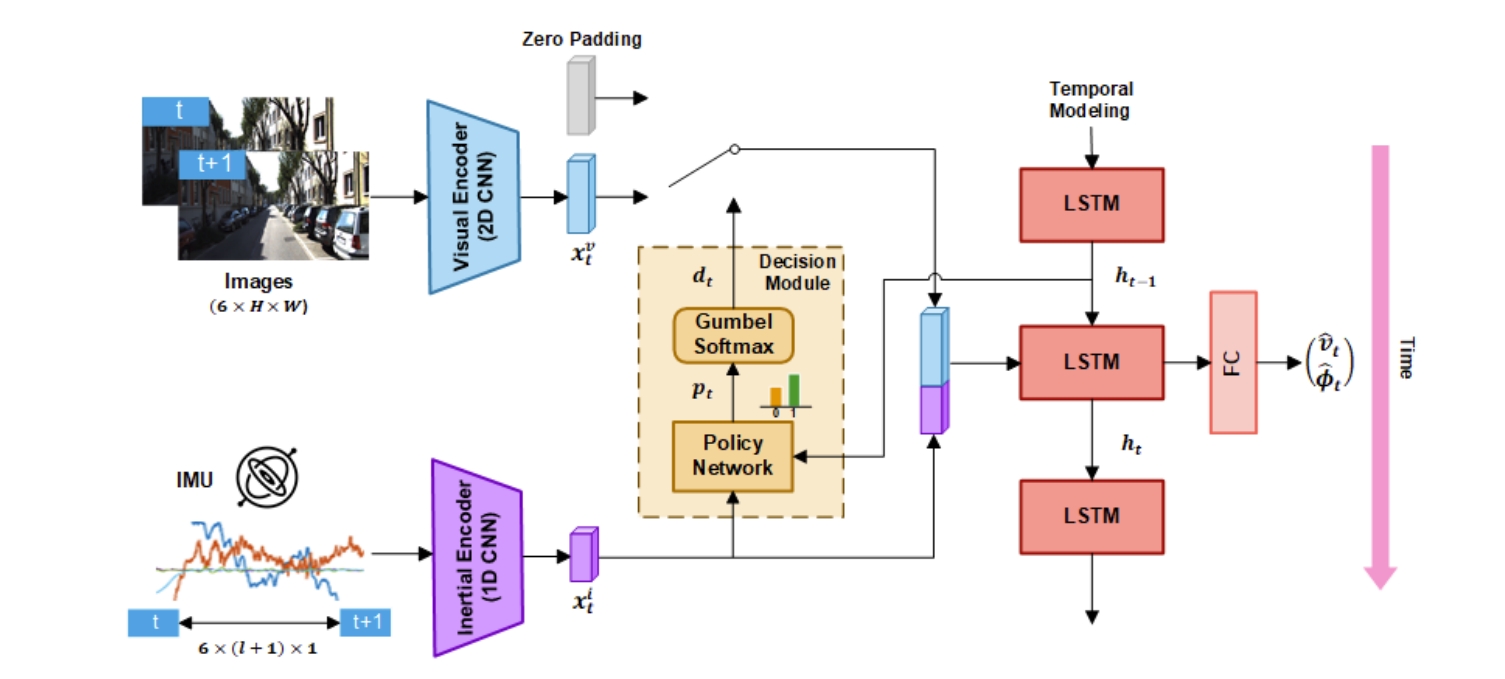
而本文的imu的encoder也是采用该工作网络结构与训练权重的,image则是采用Flownet及其预训练权重。这两者在训练过程都是fix住的,没有重新训练(不过github写的是We use pretrained image and IMU encoders of Visual-Selective-VIO model)
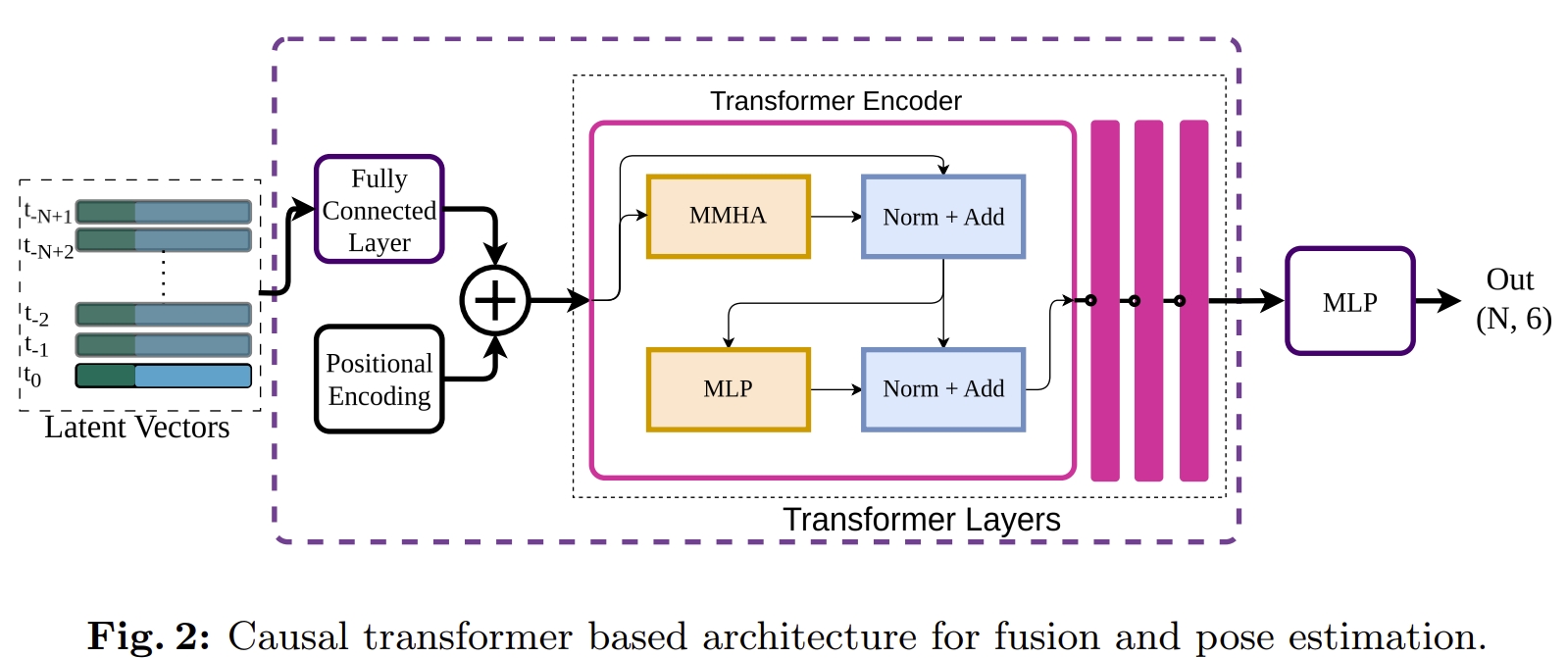
本文所谓的Causal Transformer如下图所示。跟ViT的结构差不多,最后通过两层的MLP来输出pose(6个自由度,N+1张图片对应N组姿态结果)
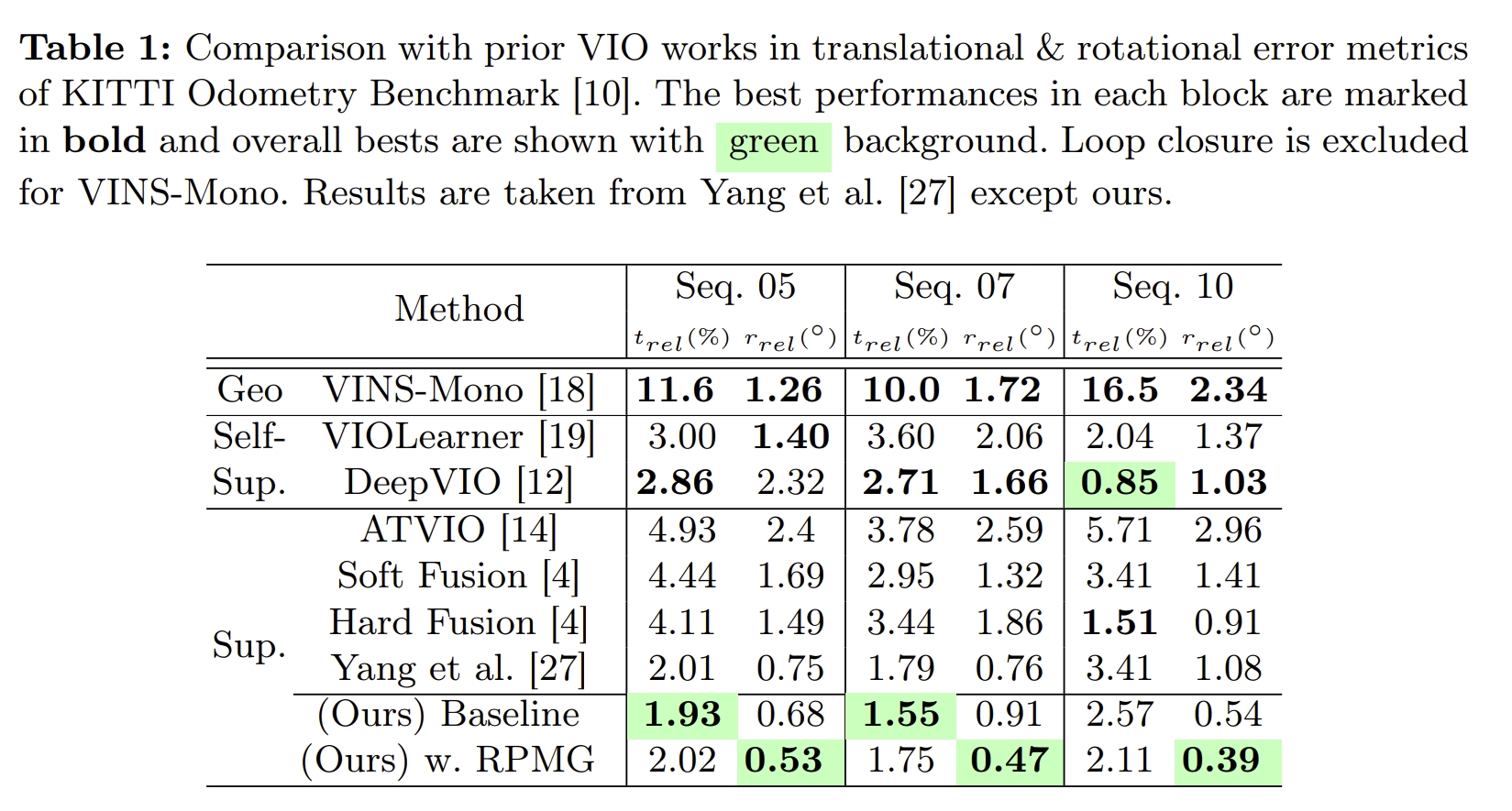
训练采用的是KITTI odometry数据集(验证也是KITTI,无泛化其他数据集的验证)。 实验对比效果如下图所示
Transformer-based model for monocular visual odometry: a video understanding approach
这篇论文以及论文《End-to-End Learned Visual Odometry Based on Vision Transformer》本质上都是直接用ViT 来做 VO任务,也是真正意义上的image input到transformer然后输出pose的工作。而此前的,Transformer VO除了只是做sensor fusion就是要其他光流、深度估计网络结合用的~
因此虽然这篇论文是Access,但是还是值得看看的
这篇论文的思路就是visual odometry as a video understanding problem因此直接从输入的序列图片中获取6D pose.
而采用的framework则是TimeSformer,来自于《Is space-time attention all you need for video understanding?》然后重新设计MSE loss来实现对姿态估计的回归而不是分类任务。 而所谓的MSE loss就是跟GT求误差啦~

其framework如下图所示,跟基本的ViT是差不多的,把输入的图片分割为$N=H*W/p^2$个patch,然后通过CNN(2D卷积)来转换为token输入,而transformer的结构则是用TimeSformer
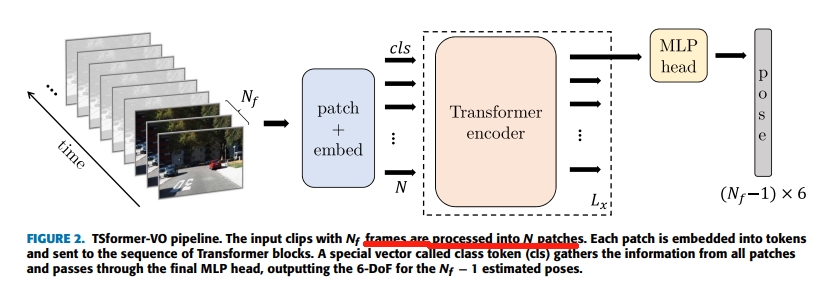
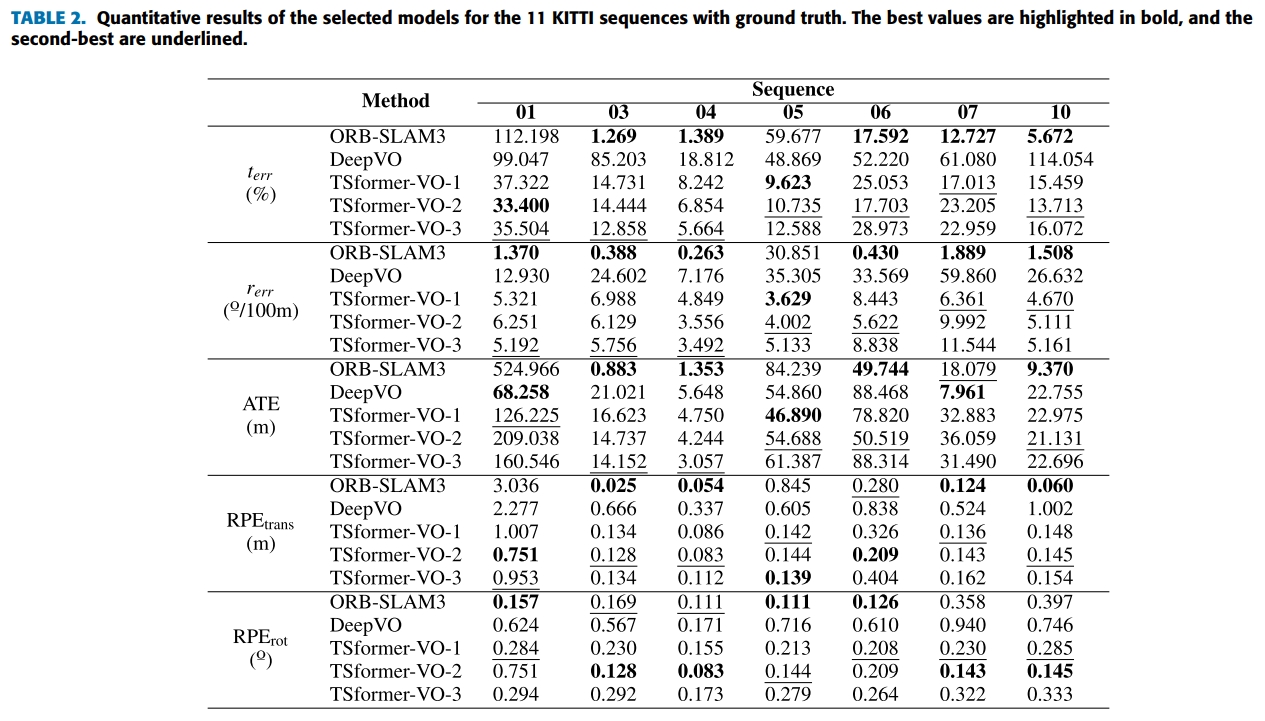
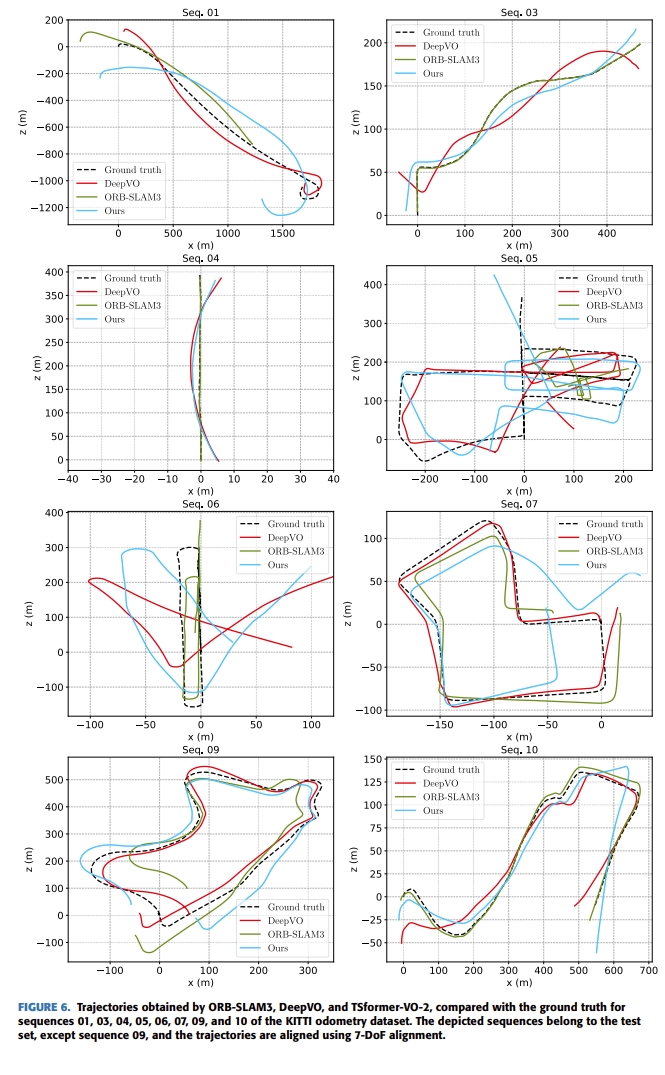
最终结果如下图所示(所谓的TSformer-VO1、2、3就是multi head self attention的head数目分别为2、3、4)
DUSt3R与MASt3R系列
请见博客:
Croco
MASt3R系列的一个核心观点就是3D数据的关联。其起源于DUSt3R,而DUSt3R则是起源于《Croco: Self-supervised pre-training for 3d vision tasks by cross-view completion》和《Croco v2: Improved cross-view completion pre-training for stereo matching and optical flow》
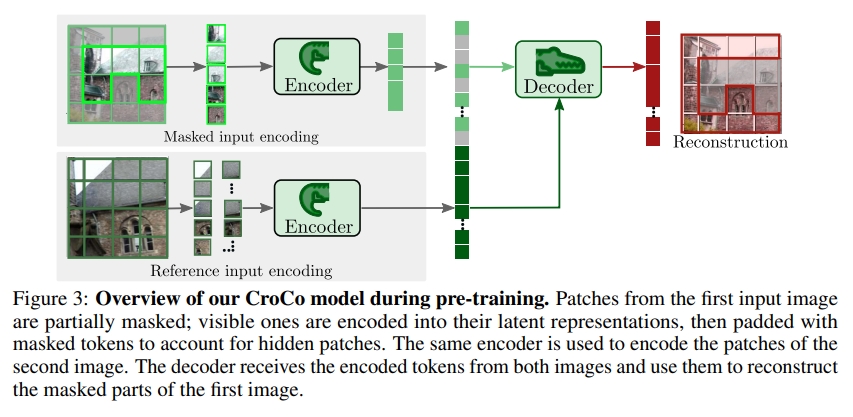
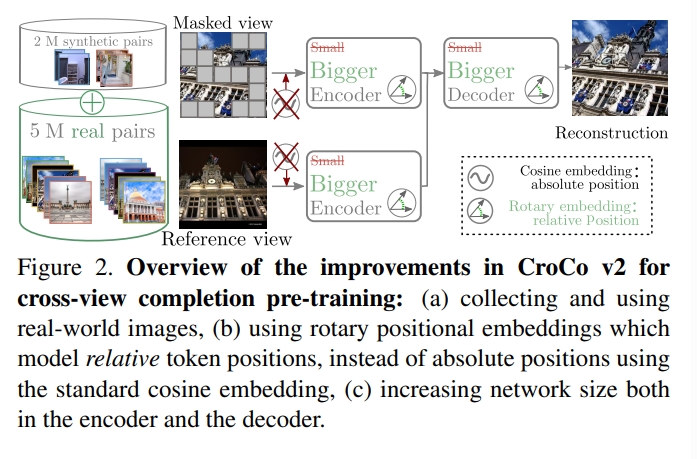
Croco这两个工作最开始针对的任务是Mask image modeling(MIM)个人理解是有点类似于图像补全,通过输入同一个场景下的两个视角的对应的两张图,对于第一张图片打mask,然后输入两个ViT的encoder中,而decoder重构出第一张图片打mask前的样式,并且采用self-supervise的形式来监督学习(也就是输入打mask前的图片与预测的图片之间的MSE)
而Croco在针对这一任务发现,网络实际上学习了空间的数据关联。因此在光流和深度估计等下游任务都有不错的提升。因此在Croco V2中针对光流和双目匹配(其实也就是深度估计了)这两个任务,采用了更大的encoder和decoder网络、大型真实+仿真数据(Croco用仿真数据)、位置编码从绝对位置改为相对位置,最终发现这一预训练模型比起RAFT、Gmflow这种task-specific网络还要强.
换句话说,对于深度估计和光流两个任务,Croco V2采用一样的结构,并且用self-supervised的方式来训练,最终可以直接finetuned到目标任务(而采用的transformer框架并不包含correlation或cost volume)paving the way towards universal vision models
对于位置编码,learned以及cosine embeddings都是包含绝对的位置信息的,而论文提出采用的相对位置则是用RoPE《Roformer: Enhanced transformer with rotary position embedding》
|
|
如上图所示,通过利用来自图2的信息可以恢复图1中被masked的区域,这能让模型隐式学习到场景的几何结构以及两个视角的空间关系,而这也使得该模型非常适用于基于几何(geometric)的task。
如下图所示,对于stereo matching 以及optical flow两个task,则是用预训练好的模型,输入为两张图片(此时图1不再mask),然后decoder中间层输出的结果通过DPT《Vision transformers for dense prediction》来输出最终的结果
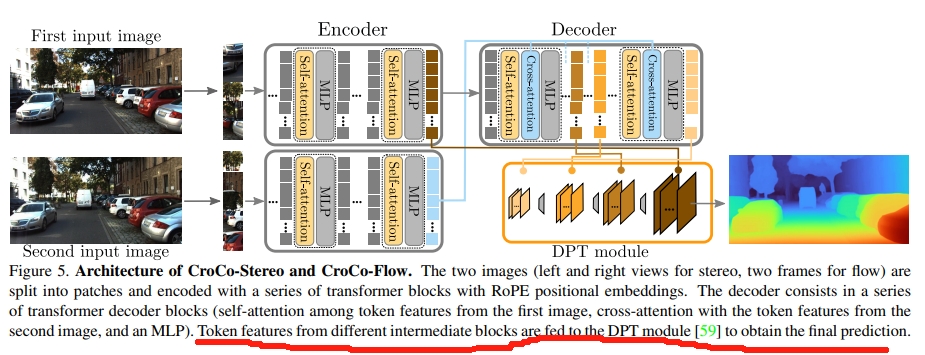
而finetune则是用真值的target disparity通过Laplacian distribution来求
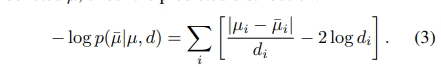
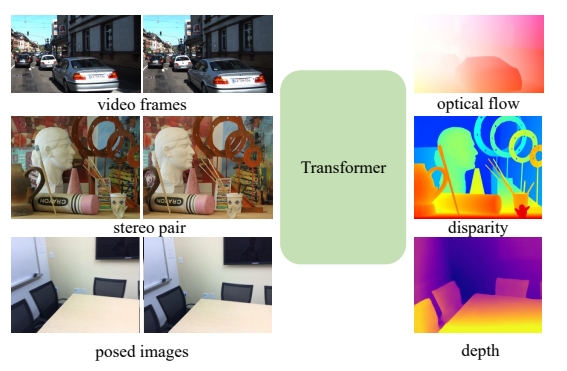
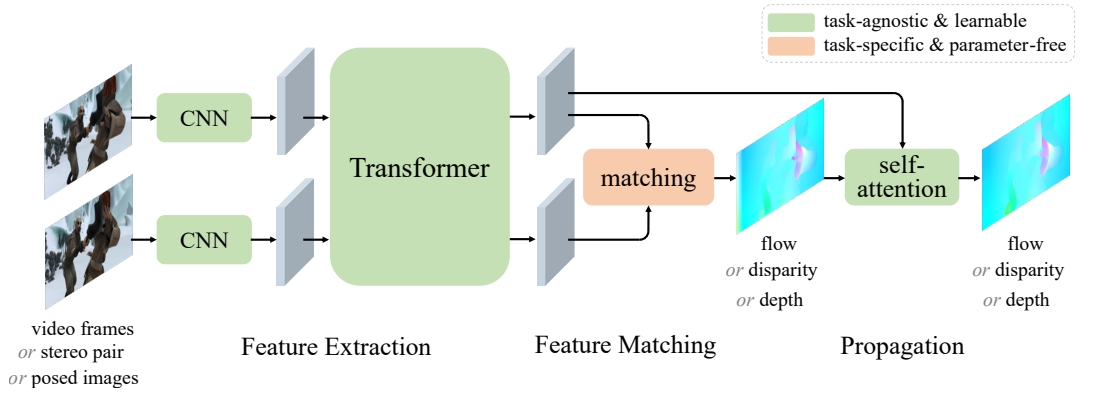
而关于单个transformer模型来解决多个问题,其实早在《Unifying flow, stereo and depth estimation》中就已经有single unified model to solve three dense perception tasks: optical flow, rectified stereo matching and unrectified stereo depth estimation
值得一提的是,该工作应该是首次(作者的上一篇论文《Gmflow: Learning optical flow via global matching》)实现用transformer并且摒弃掉correlation等CNN网络(注意在feature embedding还是要CNN的)以及针对光流等具体任务的cost单元
而做到这一切靠的就是Transformer的cross-attention mechanism来实现通过特征之间的对比进而显示的构建稠密的数据关联(这一数据关联还是时间与空间维度的)
Our key insight is that these tasks can be unified in an explicit dense correspondence matching formulation, where they can be solved by directly comparing feature similarities. Thus the task is reduced to learning strong task agnostic feature representations for matching, for which we use a Transformer, in particular the cross-attention mechanism to achieve this.
简而言之就是Transformer可以建立很好的dense correspondence,而dense correspondence则可以很好的应对光流、双目匹配以及深度估计这三个任务~
|
|
注意,该framework是no task-specific learnable parameters的,也就是不需要针对具体任务进一步学习。 但是,上图中的matching layers设计的时候还是需要考虑不同任务的约束(个人理解就是对应三个任务的三个loss),因此还是算task-specific,不过matching layer只是比较feature的相似度,因此三种任务都可以用同一个学习的参数,因此可以cross-task transfer.
MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors
- 解读及测试请见博客:Link
Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass
- 解读及测试请见博客:Link
VGGT: Visual Geometry Grounded Transformer
- 解读及测试请见博客:Link
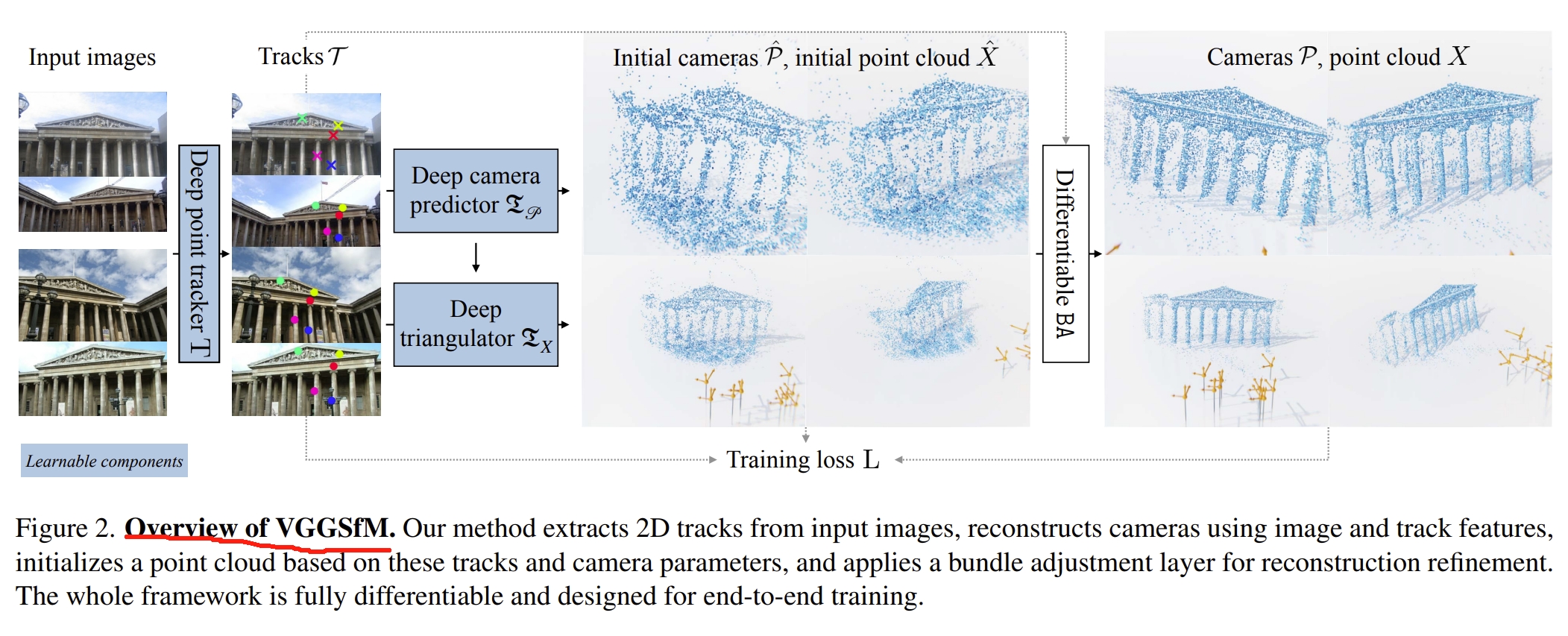
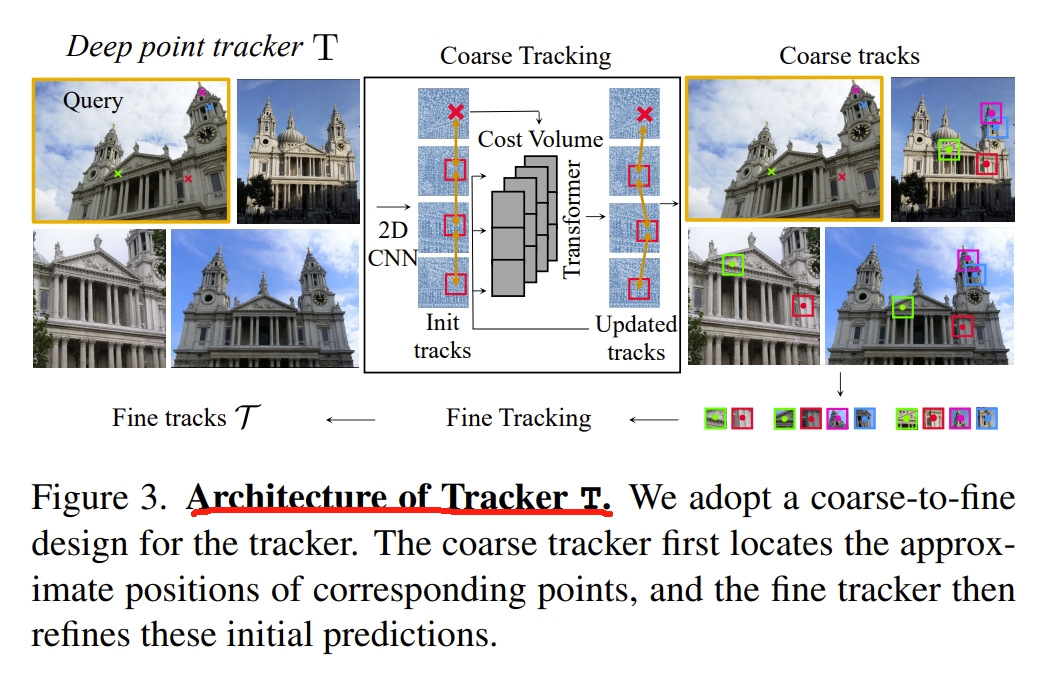
其中《VGGSfM: Visual Geometry Grounded Deep Structure From Motion》应该算是其前作了,就是用transfomer-based的网络拟合end-to-end的sfm。感觉跟 MASt3R-SfM有些像,只不过 MASt3R-SfM是基于3D匹配的概念的,VGGSfM则还是2D匹配的概念。其架构如下图所示
|
|
SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
- 解读及测试请见博客:Link
Dynamic Point Maps: A Versatile Representation for Dynamic 3D Reconstruction
将pointmap添加时间维度为DPM来喂给DUSt3R,因此可以实现dynamic DUSt3R,进而应对video depth prediction, dynamic point cloud reconstruction, 3D scene flow 和 object pose tracking等任务。 不过代码还没开源,后续测试的时候在深入介绍一下~
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
- 解读及测试请见博客:Link